A consistency model based Singing Voice Conversion system is composed, which is inspired by CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model.
This is an implemention of the paper CoMoSVC.
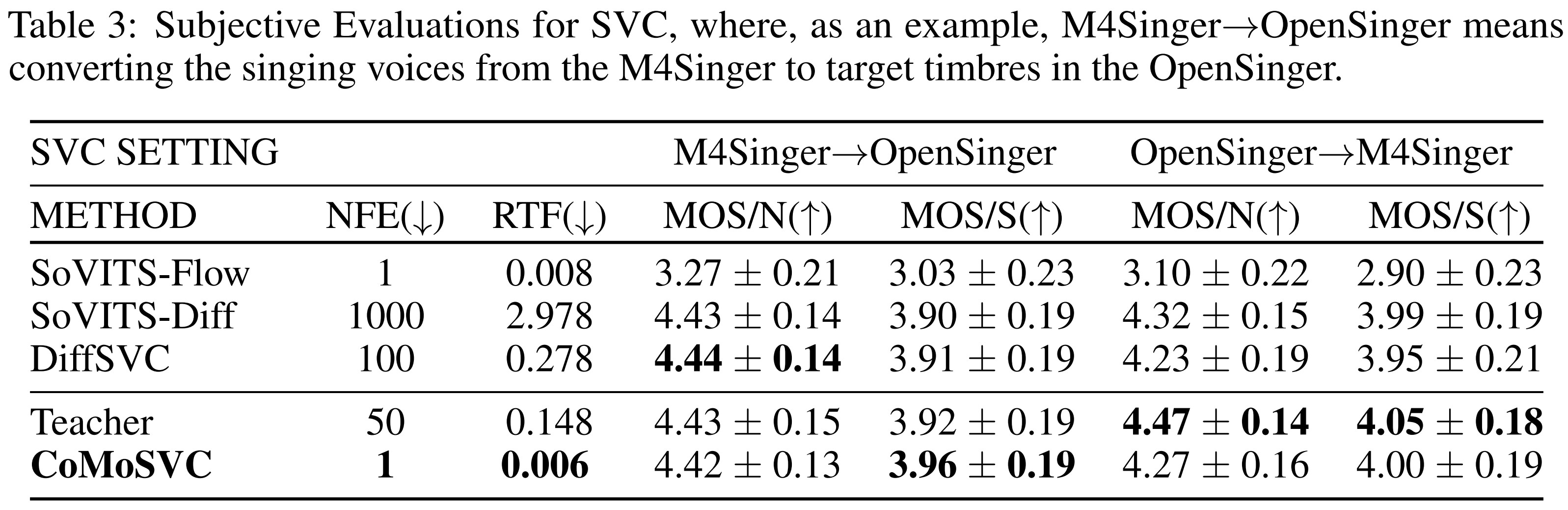
The subjective evaluations are illustrated through the table below.
We have tested the code and it runs successfully on Python 3.8, so you can set up your Conda environment using the following command:
conda create -n Your_Conda_Environment_Name python=3.8Then after activating your conda environment, you can install the required packages under it by:
pip install -r requirements.txtYou should first download m4singer_hifigan and then unzip the zip file by
unzip m4singer_hifigan.zipThe checkpoints of the vocoder will be in the m4singer_hifigan directory
You should download the checkpoint ContentVec and the put it in the Content directory to extract the content feature.
You should download the pitch_extractor checkpoint of the m4singer_pe and then unzip the zip file by
unzip m4singer_pe.zipYou should first create the folders by
mkdir dataset_raw
mkdir datasetYou can refer to different preparation methods based on your needs.
Preparation With Slicing can help you remove the silent parts and slice the audio for stable training.
Please place your original dataset in the dataset_slice directory.
The original audios can be in any waveformat which should be specified in the command line. You can designate the length of slices you want, the unit of slice_size is milliseconds. The default wavformat and slice_size is mp3 and 10000 respectively.
python preparation_slice.py -w your_wavformat -s slice_sizeYou can just place the dataset in the dataset_raw directory with the following file structure:
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
python preprocessing1_resample.py -n num_processnum_process is the number of processes, the default num_process is 5.
python preprocessing2_flist.pypython preprocessing3_feature.py -c your_config_file -n num_processes python train.pyThe checkpoints will be saved in the logs/teacher directory
If you want to adjust the config file, you can duplicate a new config file and modify some parameters.
python train.py -t -c Your_new_configfile_path -p The_teacher_model_checkpoint_path You should put the audios you want to convert under the raw directory firstly.
python inference_main.py -ts 50 -tm "logs/teacher/model_800000.pt" -tc "logs/teacher/config.yaml" -n "src.wav" -k 0 -s "target_singer"-ts refers to the total number of iterative steps during inference for the teacher model
-tm refers to the teacher_model_path
-tc refers to the teacher_config_path
-n refers to the source audio
-k refers to the pitch shift, it can be positive and negative (semitone) values
-s refers to the target singer
python inference_main.py -ts 1 -cm "logs/como/model_800000.pt" -cc "logs/como/config.yaml" -n "src.wav" -k 0 -s "target_singer" -t-ts refers to the total number of iterative steps during inference for the student model
-cm refers to the como_model_path
-cc refers to the como_config_path
-t means it is not the teacher model and you don't need to specify anything after it