Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation




The results of the paper came from the Tensorflow code
U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
Abstract We propose a novel method for unsupervised image-to-image translation, which incorporates a new attention module and a new learnable normalization function in an end-to-end manner. The attention module guides our model to focus on more important regions distinguishing between source and target domains based on the attention map obtained by the auxiliary classifier. Unlike previous attention-based methods which cannot handle the geometric changes between domains, our model can translate both images requiring holistic changes and images requiring large shape changes. Moreover, our new AdaLIN (Adaptive Layer-Instance Normalization) function helps our attention-guided model to flexibly control the amount of change in shape and texture by learned parameters depending on datasets. Experimental results show the superiority of the proposed method compared to the existing state-of-the-art models with a fixed network architecture and hyper-parameters.
├── dataset
└── YOUR_DATASET_NAME
├── trainA
├── xxx.jpg (name, format doesn't matter)
├── yyy.png
└── ...
├── trainB
├── zzz.jpg
├── www.png
└── ...
├── testA
├── aaa.jpg
├── bbb.png
└── ...
└── testB
├── ccc.jpg
├── ddd.png
└── ...
Attention: if you train the light model, you have to use --light True for all the next step,such as Train Resume Train Test create
I use selfie2anime dataset for example, the dataset has been placed in data directory, you can unzip it and create a dataset directory just like the above
> python main.py --dataset selfie2anime
- If the memory of gpu is not sufficient, set
--lightto True
> python main.py --dataset selfie2anime --resume True --start_iter XXX
- If you save the 200000 steps model,so you can use the command line
python main.py --dataset selfie2anime --resume True --start_iter 200001for Resume Train - If the memory of gpu is not sufficient, set
--lightto True
> python main.py --dataset selfie2anime --phase test
- The test image will contain the attention map
> python main.py --dataset selfie2anime --phase create
- The create image just contain target image
➢实现无监督图像到图像翻译任务,主要解决两个图像域间纹理和图像差异很大导致图像到图像翻译任务效果不好的问题 ➢实现了相同网络结构和超参数同时需要保持图像中目标shape(马到斑马,horse2zebra)的图像翻译任务和需要改变图像shape(猫到狗,cat2dog)的图像任务
无监督图像跨域转换模型,学习两个不同域内映射图像的功能➢提出新的归一化模块和新的归一化函数AdaLIN构成一种新的无监督图像到图像的转换方法 ➢增加注意力机制Attention模块,增强生成器的生成能力,更好的区分源域和目标域。增强判别器的判别能力,更好的区分生成图像与原始图像
引入新的可学习的归一化方法AdaLIN➢LayerNorm更多的考虑输入特征通道之间的相关性,LN比IN风格转换更彻底,但是语义信息保存不足 ➢InstanceNorm更多考虑单个特征通道的内容,IN比LN更好的保存原图像的语义信息,但是风格转换不彻底 ➢论文中,通过上诉公式,自适应的调整参数来得到更优化的网络模型
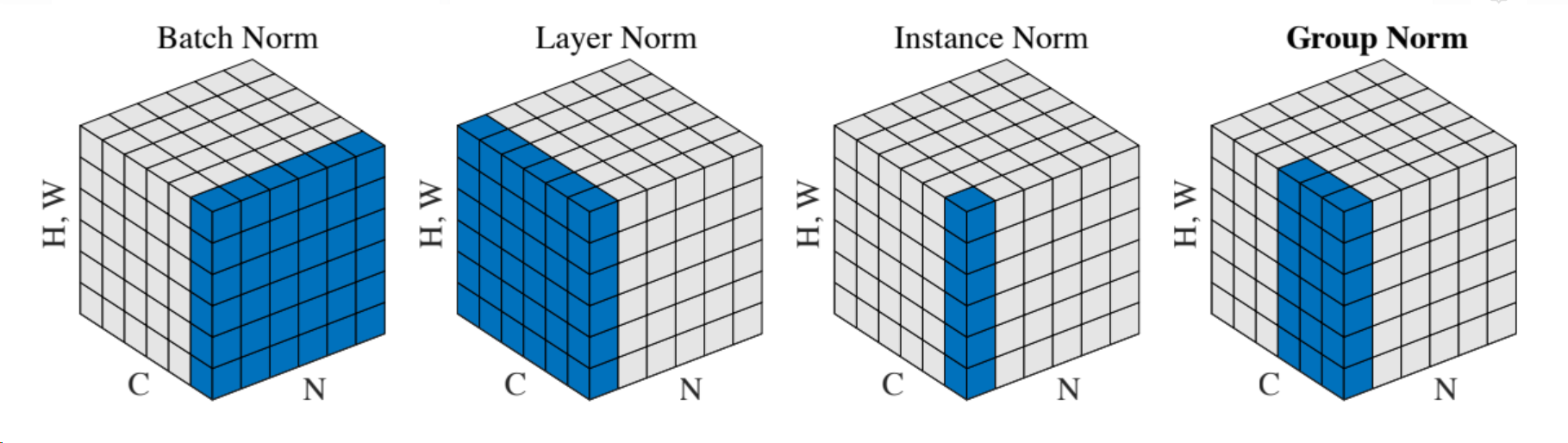
几种归一化方法示例
| 方法 | 作用 |
|---|---|
| BatchNorm | batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布 |
| LayerNorm | channel方向做归一化,算CHW的均值,主要对RNN作用明显 |
| InstanceNorm | 一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立 |
| GroupNorm | 将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束 |
| SwitchableNorm | 是将BatchNorm、LayerNorm、InstanceNorm结合,赋予权重,让网络自己去学习归一化层应该使用什么方法 |

Visual comparisons of the dog2cat with attention features maps. (a) Source images, (b) Attention map of the generation, (c-d) Local and global attention maps of the discriminators, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).

Visual comparisons of the photo2vangogh with attention features maps. (a) Source images, (b) Attention map of the generation, (c-d) Local and global attention maps of the discriminators, respectively, (e) Our results, (f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).

Visual comparisons of the photo2portrait with attention features maps. (a) Source images, (b) Attention map of the generator, (c-d) Local and global attention maps of the discriminators, respectively, (e) Our results,(f) CycleGAN (Zhu et al. (2017)), (g) UNIT (Liu et al. (2017)), (h) MUNIT (Huang et al. (2018)), (i) DRIT (Lee et al. (2018)), (j) AGGAN (Mejjati et al. (2018)).
| 1000000w light selfie2anime | 1000000w light anime2selfie | 1000000w full selfie2anime | 1000000w full anime2selfie |
|---|---|---|---|
| IS: (1.5644363, 0.20113996) | IS: (1.9134496, 0.2261766) | IS: (1.5334812, 0.17733584) | IS: (1.9919112, 0.21848756) |
| FID: 0.8426080322265626 | FID: 1.096984634399414 | FID: 0.8286741638183593 | FID: 1.1184397888183595 |
| KID_mean: 1.2977957725524902 | KID_mean: 1.9370842725038528 | KID_mean: 1.707526482641697 | KID_mean: 1.8982958048582077 |
| KID_stddev: 0.21294353064149618 | KID_stddev: 0.3958268091082573 | KID_stddev: 0.36081753205507994 | KID_stddev: 0.34899383317679167 |
| mean_FID: 1.3748193725585938 | mean_FID: 1.486142600250244 | mean_FID: 1.3621834487915039 | mean_FID: 1.4849468765258789 |
| mean_KID_mean: 11.555835604667664 | mean_KID_mean: 15.389134127646683 | mean_KID_mean: 11.625613445416093 | mean_KID_mean: 15.208403330296278 |
| mean_KID_stddev: 0.40995743009261787 | mean_KID_stddev: 0.4632239909842611 | mean_KID_stddev: 0.34452050761319697 | mean_KID_stddev: 0.4152729648631066 |
- We can see the selfie2anime achieve the paper accuracy
- New added
lr_scheduler.pywill change the learning rate that the paper has mentioned. - Both light mode & full mode have been trained for 1000000steps
You can download by BaiduYun. And then you should put it under the results/lfie2anime/model directory
The Link: https://pan.baidu.com/s/1du0jt3sfoUy7RwkF7BW-gQ ; The Code: mxyp



- All right! She is Scarlett Johansson! From left to right, Original Image, Light Model, Full Model!
- You can see the
requirements.txtto get the right version for all modules - Cause I using the AIStudio environment, I can't determin all the packages needed. If you meet some ModuleNotFoundError, you just use
pip installto install the Module. - Welcome to use AIStudio and PaddlePaddle, just baidu or google
PaddlePaddleorAIStudio. - More about the paper, seeing CSDN blog: DeepHao 【飞桨】GAN:U-GAT-IT【2020 ICLR】论文研读