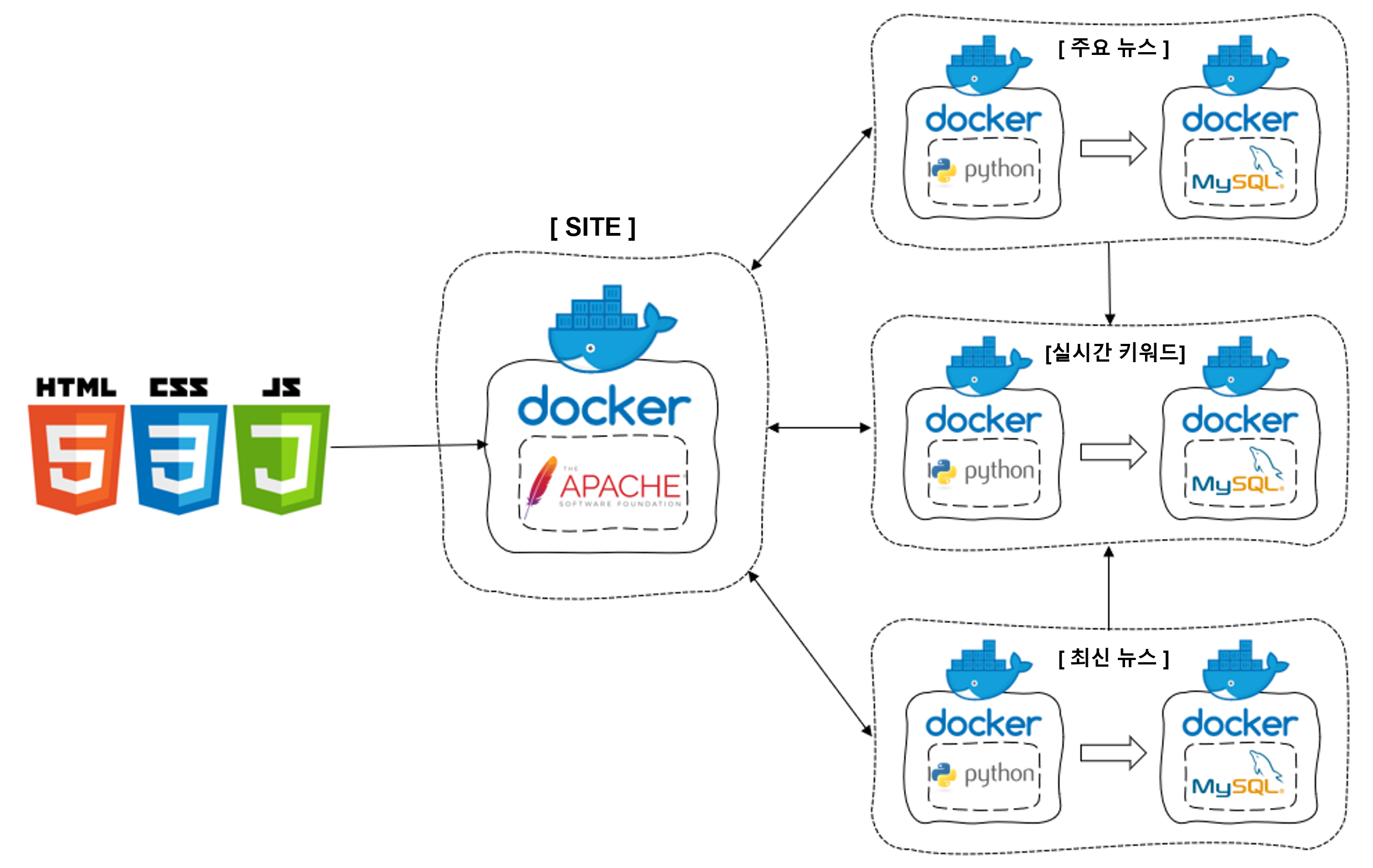
2022 소프트웨어 페스티벌 데이터 분석 부문 실시간 뉴스 모니터링 서비스입니다.
개발 언어: HTML, CSS, JS, PHP, Python
활용 플랫폼: Docker, Ubuntu, MYSQL, APACHE, Naver NEWs Template
활용 라이브러리: TextRank, requests, beautifulsoup4, MySQLdb, scikit-learn, konlpy
실시간 뉴스 모니터링 서비스는 최근 주요 이슈를 보여주는 실시간 뉴스 모니터링 시스템입니다.
최근 카카오, 이태원 사태 등과 같은 최근 주요 이슈를 뉴스 데이터를 통해 신속하게 알 수 있도록 하는 것이 목적입니다.
언론사 중 방송/통신사 8곳, 종합지 4곳을 대상으로 최신 기사 정보 + 주요 기사 내용을 획득하여
웹사이트를 통해 조회수에 따른 주요 뉴스, 시간에 따른 최근 뉴스를 보여줍니다.
또한 각 기사 제목을 TextRank Library를 활용하여 키워드 및 언급도를 분석하고 키워드 언급 순위를 추출하여 실시간 검색어 순위를 구현하였습니다.
개발 환경: alpine linux(Docker), Python 3.8
활용 플랫폼: Docker, Mysql
매체 선정: JTBC, KBS, MBC, SBS, YTN, NEWS1, NEWSIS, 연합뉴스, 조선일보, 국민일보, 경향신문, 한겨레 (방송/통신사 8, 종합지 4)
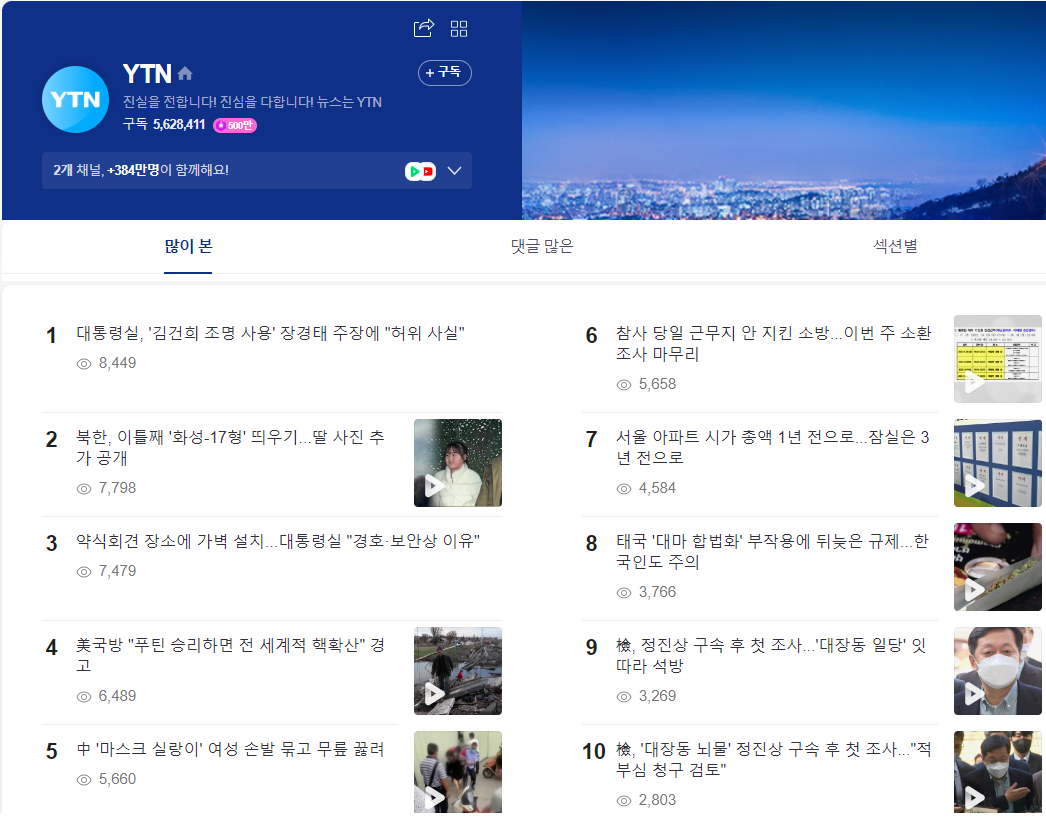
- NAVER 플랫폼을 통해 각 방송사의 많이 시청한 기사 목록을 확인할 수 있음.
- 해당 부분을 이용하여 위의 12곳에 해당하는 매체의 정보를 Crawling.
FROM python:3.8-alpine
RUN apk add --no-cache mariadb-dev build-base
RUN python3 -m pip install --upgrade pip \
&& python3 -m pip install --upgrade requests \
&& python3 -m pip install --upgrade beautifulsoup4 \
&& python3 -m pip install --upgrade mysqlclient
RUN mkdir /home/crawl_main
RUN cd /home/crawl_main
WORKDIR /home/crawl_main
COPY crawling_main.py .
CMD ["python", "crawling_main.py"]
- resource가 많이 필요치 않으므로 alpine linux + python3.8 image를 Pull.
- Moudle import를 위해 필요 libray를 빌드 (build-base(gcc,g++...), mariadb-dev)
- HTTP 통신을 위한 requests, 파싱을 위한 beautifulsoup4, MYSQL DB 접속을 위해 mysqlclient를 설치
Source (crawling_main.py)
def Connect_DB(IP, DB):
while True:
try:
conn = MySQLdb.connect(
user="root",
passwd="test1234",
host=IP,
db=DB,
charset="utf8"
)
break
except:
time.sleep(5)
cursor = conn.cursor()
return conn, cursor- IP, Database Name을 전달받아, 특정 MySQL DB에 접속 후 통신할 수 있는 conn, cursor를 return.
def Crawling(agen, agen_num):
conn, cursor = Connect_DB(IP, DB)
response = requests.get('https://media.naver.com/press/' + agen_num + '/ranking', headers=headers)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
news_titles = soup.select('.list_title') # soup.select('.list_title')[0]
news_urls = soup.select('._es_pc_link') # soup.select('._es_pc_link')[0].get('href')
news_images = soup.select('.list_img') # soup.select('.list_img')[0].img.get('src')
news_views = soup.select('.list_view') # soup.select('.list_view')[0].text.split()[1]
idx = 5
news = []
for i in range(0, idx):
try:
news_title = news_titles[i].text
news_url = news_urls[i].get('href')
news_image = news_images[i].img.get('src')
if news_views != []:
news_view = news_views[i].text.split()[1] + '회'
else:
news_view = "Not info.."
for remove in '''.,'"“”‘’[]?!''':
news_title = news_title.replace(remove, '')
for space in '·…':
news_title = news_title.replace(space, ' ')
news.append([news_title, news_url, news_image, news_view])
except:
idx += 1
continue
i = 1
for n in news:
cursor.execute(f"INSERT INTO {agen} VALUES (\"{i+1}\", \"{n[0]}\", \"{n[1]}\", \"{n[2]}\", \"{n[3]}\") \
ON DUPLICATE KEY UPDATE title=\"{n[0]}\", url=\"{n[1]}\", image=\"{n[2]}\", view=\"{n[3]}\"")
i+=1
conn.commit()
conn.close()- 각 방송사의 많이 시청한 기사 목록에 해당하는 HTML Source를 requests.get을 통해 DATA를 받음
- 기사 제목, 기사 link, 기사 image, 기사 조회수를 BeautifulSoup를 통해 파싱함.
- 5위까지의 data를 배열을 통해 저장시킨뒤, 연결했던 MySQL Connection을 통해 DATA를 Table에 삽입.
cursor.execute(f"INSERT INTO {agen} VALUES (\"{i+1}\", \"{n[0]}\", \"{n[1]}\", \"{n[2]}\", \"{n[3]}\") \ ON DUPLICATE KEY UPDATE title=\"{n[0]}\", url=\"{n[1]}\", image=\"{n[2]}\", view=\"{n[3]}\"")- 해당 QUERY는 Data를 TABLE에 insert할 때 만약 table에 data가 존재하지 않으면 Insert, 존재하지 않다면 UPDATE하는 방식을 사용.
- 만약 table을 삭제한 뒤 insert하는 쿼리를 사용하면 site에서 해당 DB를 접속했을 때 데이터가 없는 경우 Error가 발생하기 때문.
if __name__ == '__main__':
AGENCY = {
"JTBC":"437", "KBS":"056", "MBC":"214", "SBS":"055",
"YTN":"052", "NEWS1":"421", "NEWSIS":"003", "연합뉴스":"001",
"조선일보":"023", "국민일보":"005", "경향신문":"032", "한겨레":"028"
}
ip = socket.gethostbyname(socket.gethostname()).split('.')
ip[-1] = str(2)
ip = '.'.join(ip)
IP = ip
conn, cursor = Connect_DB(IP, DB)
cursor.execute('CREATE DATABASE IF NOT EXISTS crawl_main DEFAULT CHARACTER SET utf8')
conn.close()
DB = 'crawl_main'
conn, cursor = Connect_DB(IP, DB)
for A in AGENCY:
cursor.execute("CREATE TABLE IF NOT EXISTS {} (id int(1), title text, url text, image text, view text)".format(A))
cursor.execute("ALTER TABLE {} ADD UNIQUE (id)".format(A))
conn.close()
while 1:
threads = []
start = time.perf_counter()
for A in AGENCY:
t = Thread(target=Crawling, args=(A, AGENCY[A], ))
t.start()
threads.append(t)
for thread in threads:
thread.join()
finish = time.perf_counter()
t = round(finish-start, 2)
#print(f'Finished in {t} second(s)')
time.sleep(5)- MYSQL Connection 후 Database, Table을 생성.
- 각 1~5순위에 해당하는 data를 구분하고 UPDATE 방식을 사용하기 위해 TABLE에 UNIQUE id ALTER함.
- 추후 각각의 매체의 기사를 차례차례 가져오는 방식은 비효율적이기에 Multi Thread 방식을 사용하여 기사 수집 시간을 단축.
개발 환경: alpine linux(Docker), Python 3.8
활용 플랫폼: Docker, Mysql
매체 선정: JTBC, KBS, MBC, SBS, YTN, NEWS1, NEWSIS, 연합뉴스, 조선일보, 국민일보, 경향신문, 한겨레 (방송/통신사 8, 종합지 4)
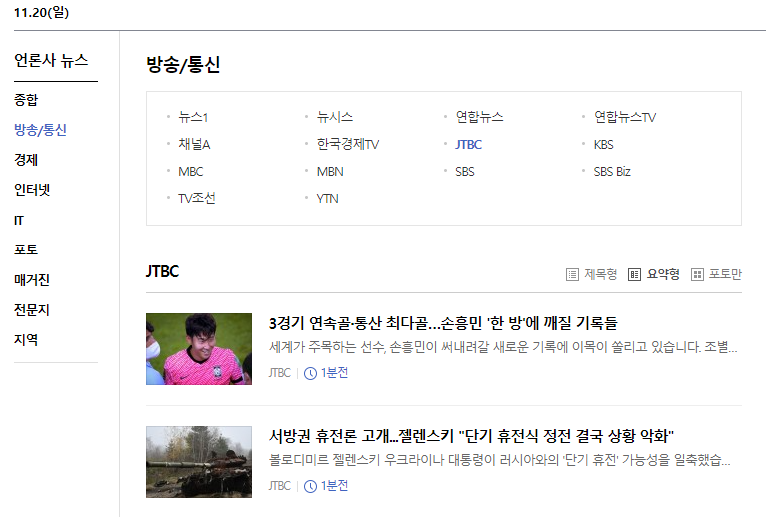
- NAVER 플랫폼을 통해 각 방송사의 최신 기사 목록을 확인할 수 있음.
- 해당 부분을 이용하여 위의 12곳에 해당하는 매체의 정보를 Crawling.
FROM python:3.8-alpine
RUN apk add --no-cache mariadb-dev build-base
RUN python3 -m pip install --upgrade pip \
&& python3 -m pip install --upgrade requests \
&& python3 -m pip install --upgrade beautifulsoup4 \
&& python3 -m pip install --upgrade mysqlclient
RUN mkdir /home/crawl_new
RUN cd /home/crawl_new
WORKDIR /home/crawl_new
COPY crawling_new.py .
CMD ["python", "crawling_new.py"]
Source (crawling_new.py)
def Crawling(agen, agen_num):
conn, cursor = Connect_DB(IP, DB)
response = requests.get('https://news.naver.com/main/list.naver?mode=LPOD&mid=sec&oid=' + agen_num, headers=headers)
if response.status_code == 200:
# time.sleep(0.5)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
news_infos = soup.select('.photo')
news_times = soup.select('.date.is_new') + soup.select('.date.is_outdated')
idx = 5
news = []
for i in range(0, idx):
try:
news_title = news_infos[i].img.get('alt')
news_url = news_infos[i].a.get('href')
news_image = news_infos[i].img.get('src')
news_time = news_times[i].text
for remove in '''.,'"“”‘’[]?!''':
news_title = news_title.replace(remove, '')
for space in '·…':
news_title = news_title.replace(space, ' ')
news.append([news_title, news_url, news_image, news_time])
except:
idx += 1
continue
i = 1
for n in news:
cursor.execute(f"INSERT INTO {agen} VALUES (\"{i+1}\", \"{n[0]}\", \"{n[1]}\", \"{n[2]}\", \"{n[3]}\") \
ON DUPLICATE KEY UPDATE title=\"{n[0]}\", url=\"{n[1]}\", image=\"{n[2]}\", time=\"{n[3]}\"")
i+=1
conn.commit()
conn.close()- 위 crawling_main 부분과 대부분 동일.
- 최신 기사에 해당하는 크롤링 부분만 다름.
- 기사 제목, 기사 link, 기사 image, 기사 업로드 time 파싱.
개발 환경: alpine linux(Docker), Python 3.5
활용 플랫폼: Docker, Mysql, textrank
FROM frolvlad/alpine-python-machinelearning
ENV JAVA_HOME /usr/lib/jvm/java-1.7-openjdk/jre
ENV LD_LIBRARY_PATH=/usr/lib/jvm/java-11-openjdk/lib/server/
RUN apk upgrade --no-cache \
&& apk update \
&& apk add --no-cache \
mariadb-dev \
build-base \
python3-dev \
openjdk11
RUN python -m pip install --upgrade pip \
&& python -m pip install --upgrade requests \
&& python -m pip install --upgrade beautifulsoup4 \
&& python -m pip install --upgrade mysqlclient \
&& python -m pip install --upgrade konlpy
RUN mkdir /home/crawl_keyword \
&& cd /home/crawl_keyword \
&& wget https://github.com/Gyeongje/news-monitoring/raw/main/crawl_keyword/textrank.tar \
&& tar -xvf /home/crawl_keyword/textrank.tar \
&& rm textrank.tar && cd textrank \
&& python3 /home/crawl_keyword/textrank/setup.py build
WORKDIR /home/crawl_keyword/textrank
COPY crawl_keyword.py .
CMD ["python", "crawl_keyword.py"]
- resource가 많이 필요치 않으므로 alpine linux 기반 image를 pull.
- Docker HUB를 통해 frolvlad/alpine-python-machinelearning image를 사용.
- frolvlad/alpine-python-machinelearning: numpy, pandas, scipy, scikit-learn.
- Moudle import를 위해 필요 libray를 빌드. (build-base, mariadb-dev, java)
- HTTP 통신을 위한 requests, 파싱을 위한 beautifulsoup4, MYSQL DB 접속을 위해 mysqlclient를 설치.
- Machine Learning을 Tools인 numpy, pandas, scipy, scikit-learn, konlpy를 설치.
Source (crawl_keyword.py)
start = time.perf_counter()
conn, cursor = Connect_DB(crawl_main_ip,'crawl_main')
conn2, cursor2 = Connect_DB(crawl_new_ip,'crawl_new')
result = ()
for A in AGENCY:
while 1:
try:
cursor.execute(f"select title from {A}")
cursor2.execute(f"select title from {A}")
break
except:
continue
result += (cursor.fetchall() + cursor2.fetchall())
conn2.close()
conn.close()
sents = []
for i in result:
sents.append(i[0])- 주요 + 최신 뉴스의 title 제목을 MySQL DB를 통해 Connection하여 response함.
komoran = Komoran()
def komoran_tokenizer(sent):
words = komoran.pos(sent, join=True)
words = [w for w in words if ('/NN' in w or '/XR' in w or '/VA' in w or '/VV' in w)]
return words
summarizer = KeysentenceSummarizer(
tokenize = komoran_tokenizer,
min_sim = 0.3,
verbose = False
)
summarizer = KeywordSummarizer(tokenize=komoran_tokenizer, min_count=2, min_cooccurrence=1)
keywords = summarizer.summarize(sents, topk=30)
rank = []
count = 1
for k in keywords:
word = k[0].split('/')
if word[1] == "NNP" or word[1] == "NNG":
rank.append([word[0], round(k[1], 6)])
if count >= 20:
break
count += 1
conn, cursor = Connect_DB(crawl_keyword_ip,'crawl_keyword')
i=0
for r in rank:
cursor.execute(f"INSERT INTO KEYWORDS VALUES (\"{i+1}\", \"{r[0]}\", \"{r[1]}\") \
ON DUPLICATE KEY UPDATE keyword=\"{r[0]}\", persent=\"{r[1]}\"")
i+=1
conn.commit()
conn.close()- textrank를 통해 키워드 추출 후, 핵심 단어의 유사도 확률을 활용하여 검색어 키워드 순위를 추출할 수 있음.
- 후에 추출한 키워드를 DB에 삽입.
TextRank 는 키워드 추출 기능과 핵심 문장 추출 기능, 두 가지를 제공합니다. 키워드를 추출하기 위해서 먼저 단어 그래프를 만들어야 합니다. 마디인 단어는 주어진 문서 집합에서 최소 빈도수 min_count 이상 등장한 단어들 입니다. sents 는 list of str 형식의 문장들이며, tokenize 는 str 형식의 문장을 list of str 형식의 단어열로 나누는 토크나이저 입니다.
from collections import Counter
def scan_vocabulary(sents, tokenize, min_count=2):
counter = Counter(w for sent in sents for w in tokenize(sent))
counter = {w:c for w,c in counter.items() if c >= min_count}
idx_to_vocab = [w for w, _ in sorted(counter.items(), key=lambda x:-x[1])]
vocab_to_idx = {vocab:idx for idx, vocab in enumerate(idx_to_vocab)}
return idx_to_vocab, vocab_to_idxTextRank 에서 두 단어 간의 유사도를 정의하기 위해서는 두 단어의 co-occurrence 를 계산해야 합니다. Co-occurrence 는 문장 내에서 두 단어의 간격이 window 인 횟수입니다. 논문에서는 2 ~ 8 사이의 값을 이용하기를 추천하였습니다. 여기에 하나 더하여, 문장 내에 함께 등장한 모든 경우를 co-occurrence 로 정의하기 위하여 window 에 -1 을 입력할 수 있도록 합니다. 또한 그래프가 지나치게 dense 해지는 것을 방지하고 싶다면 min_coocurrence 를 이용하여 그래프를 sparse 하게 만들 수도 있습니다.
from collections import defaultdict
def cooccurrence(tokens, vocab_to_idx, window=2, min_cooccurrence=2):
counter = defaultdict(int)
for s, tokens_i in enumerate(tokens):
vocabs = [vocab_to_idx[w] for w in tokens_i if w in vocab_to_idx]
n = len(vocabs)
for i, v in enumerate(vocabs):
if window <= 0:
b, e = 0, n
else:
b = max(0, i - window)
e = min(i + window, n)
for j in range(b, e):
if i == j:
continue
counter[(v, vocabs[j])] += 1
counter[(vocabs[j], v)] += 1
counter = {k:v for k,v in counter.items() if v >= min_cooccurrence}
n_vocabs = len(vocab_to_idx)
return dict_to_mat(counter, n_vocabs, n_vocabs)dict_to_mat 함수는 dict of dict 형식의 그래프를 scipy 의 sparse matrix 로 변환하는 함수입니다.
from scipy.sparse import csr_matrix
def dict_to_mat(d, n_rows, n_cols):
rows, cols, data = [], [], []
for (i, j), v in d.items():
rows.append(i)
cols.append(j)
data.append(v)
return csr_matrix((data, (rows, cols)), shape=(n_rows, n_cols))TextRank 에서는 명사, 동사, 형용사와 같은 단어만 단어 그래프를 만드는데 이용합니다. 모든 종류의 단어를 이용하면 ‘a’, ‘the’ 와 같은 단어들이 다른 단어들과 압도적인 co-occurrence 를 지니기 때문입니다. 즉, stopwords 를 지정할 필요가 있다면 지정하여 키워드 후보만 그래프에 남겨둬야 한다는 의미입니다. 그러므로 입력되는 tokenize 함수는 불필요한 단어를 모두 걸러내고, 필요한 단어 혹은 품사만 return 하는 함수이어야 합니다.
이 과정을 정리하면 아래와 같은 word_graph 함수를 만들 수 있습니다.
def word_graph(sents, tokenize=None, min_count=2, window=2, min_cooccurrence=2):
idx_to_vocab, vocab_to_idx = scan_vocabulary(sents, tokenize, min_count)
tokens = [tokenize(sent) for sent in sents]
g = cooccurrence(tokens, vocab_to_idx, window, min_cooccurrence, verbose)
return g, idx_to_vocab그 뒤 만들어진 그래프에 PageRank 를 학습하는 함수를 만듭니다. 입력되는 x 는 co-occurrence 그래프일 수 있으니, column sum 이 1 이 되도록 L1 normalization 을 합니다. 이를 A 라 합니다. A * R 은 column j에서 row i로의 랭킹 R(j)의 전달되는 값을 의미합니다. 이 값에 df 를 곱하고, 모든 마디에 1 - df 를 더합니다. 이를 max_iter 만큼 반복합니다.
import numpy as np
from sklearn.preprocessing import normalize
def pagerank(x, df=0.85, max_iter=30):
assert 0 < df < 1
# initialize
A = normalize(x, axis=0, norm='l1')
R = np.ones(A.shape[0]).reshape(-1,1)
bias = (1 - df) * np.ones(A.shape[0]).reshape(-1,1)
# iteration
for _ in range(max_iter):
R = df * (A * R) + bias
return R이 과정을 정리하면 아래와 같은 textrank_keyword 함수를 만들 수 있습니다.
def textrank_keyword(sents, tokenize, min_count, window, min_cooccurrence, df=0.85, max_iter=30, topk=30):
g, idx_to_vocab = word_graph(sents, tokenize, min_count, window, min_cooccurrence)
R = pagerank(g, df, max_iter).reshape(-1)
idxs = R.argsort()[-topk:]
keywords = [(idx_to_vocab[idx], R[idx]) for idx in reversed(idxs)]
return keywordsTextRank 를 이용하여 핵심 문장을 추출하기 위해서는 문장 그래프를 만들어야 합니다. 각 문장이 마디가 되며, edge weight 는 문장 간 유사도 입니다. 일반적으로 문서 간 혹은 문장 간 유사도를 측정하기 위하여 Cosine similarity 가 이용되는데, TextRank 는 아래와 같은 문장 간 유사도 척도를 제안했습니다. 두 문장에 공통으로 등장한 단어의 개수를 각 문장의 단어 개수의 log 값의 합으로 나눈 것 입니다.
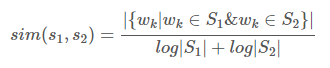
위의 이야기를 아래의 함수로 구현합니다. 실험을 위하여 문장 간 유사도를 Cosine similarity 와 TextRank 의 유사도 모두 구현합니다.
또한 min_sim 이라는 argument 를 추가하였습니다. 문장 간 그래프의 sparsity 가 클수록 PageRank 의 계산이 빠릅니다. 이를 위하여 문장 간 유사도가 0.3 보다 작은 경우에는 edge 를 연결하지 않습니다.
from collections import Counter
from scipy.sparse import csr_matrix
import math
def sent_graph(sents, tokenize, similarity, min_count=2, min_sim=0.3):
_, vocab_to_idx = scan_vocabulary(sents, tokenize, min_count)
tokens = [[w for w in tokenize(sent) if w in vocab_to_idx] for sent in sents]
rows, cols, data = [], [], []
n_sents = len(tokens)
for i, tokens_i in enumerate(tokens):
for j, tokens_j in enumerate(tokens):
if i >= j:
continue
sim = similarity(tokens_i, tokens_j)
if sim < min_sim:
continue
rows.append(i)
cols.append(j)
data.append(sim)
return csr_matrix((data, (rows, cols)), shape=(n_sents, n_sents))
def textrank_sent_sim(s1, s2):
n1 = len(s1)
n2 = len(s2)
if (n1 <= 1) or (n2 <= 1):
return 0
common = len(set(s1).intersection(set(s2)))
base = math.log(n1) + math.log(n2)
return common / base
def cosine_sent_sim(s1, s2):
if (not s1) or (not s2):
return 0
s1 = Counter(s1)
s2 = Counter(s2)
norm1 = math.sqrt(sum(v ** 2 for v in s1.values()))
norm2 = math.sqrt(sum(v ** 2 for v in s2.values()))
prod = 0
for k, v in s1.items():
prod += v * s2.get(k, 0)
return prod / (norm1 * norm2)이를 정리하여 아래와 같은 핵심 문장 추출 함수를 만듭니다.
def textrank_keysentence(sents, tokenize, min_count, similarity, df=0.85, max_iter=30, topk=5)
g = sent_graph(sents, tokenize, min_count, min_sim, similarity)
R = pagerank(g, df, max_iter).reshape(-1)
idxs = R.argsort()[-topk:]
keysents = [(idx, R[idx], sents[idx]) for idx in reversed(idxs)]
return keysentsfrom konlpy.tag import Komoran
sents = [
'오패산터널 총격전 용의자 검거 서울 연합뉴스 경찰 관계자들이 19일 오후 서울 강북구 오패산 터널 인근에서 사제 총기를 발사해 경찰을 살해한 용의자 성모씨를 검거하고 있다 성씨는 검거 당시 서바이벌 게임에서 쓰는 방탄조끼에 헬멧까지 착용한 상태였다',
'서울 연합뉴스 김은경 기자 사제 총기로 경찰을 살해한 범인 성모 46 씨는 주도면밀했다',
'경찰에 따르면 성씨는 19일 오후 강북경찰서 인근 부동산 업소 밖에서 부동산업자 이모 67 씨가 나오기를 기다렸다 이씨와는 평소에도 말다툼을 자주 한 것으로 알려졌다',
'이씨가 나와 걷기 시작하자 성씨는 따라가면서 미리 준비해온 사제 총기를 이씨에게 발사했다 총알이 빗나가면서 이씨는 도망갔다 그 빗나간 총알은 지나가던 행인 71 씨의 배를 스쳤다',
'성씨는 강북서 인근 치킨집까지 이씨 뒤를 쫓으며 실랑이하다 쓰러뜨린 후 총기와 함께 가져온 망치로 이씨 머리를 때렸다',
'이 과정에서 오후 6시 20분께 강북구 번동 길 위에서 사람들이 싸우고 있다 총소리가 났다 는 등의 신고가 여러건 들어왔다',
'5분 후에 성씨의 전자발찌가 훼손됐다는 신고가 보호관찰소 시스템을 통해 들어왔다 성범죄자로 전자발찌를 차고 있던 성씨는 부엌칼로 직접 자신의 발찌를 끊었다',
'용의자 소지 사제총기 2정 서울 연합뉴스 임헌정 기자 서울 시내에서 폭행 용의자가 현장 조사를 벌이던 경찰관에게 사제총기를 발사해 경찰관이 숨졌다 19일 오후 6시28분 강북구 번동에서 둔기로 맞았다 는 폭행 피해 신고가 접수돼 현장에서 조사하던 강북경찰서 번동파출소 소속 김모 54 경위가 폭행 용의자 성모 45 씨가 쏜 사제총기에 맞고 쓰러진 뒤 병원에 옮겨졌으나 숨졌다 사진은 용의자가 소지한 사제총기',
'신고를 받고 번동파출소에서 김창호 54 경위 등 경찰들이 오후 6시 29분께 현장으로 출동했다 성씨는 그사이 부동산 앞에 놓아뒀던 가방을 챙겨 오패산 쪽으로 도망간 후였다',
'김 경위는 오패산 터널 입구 오른쪽의 급경사에서 성씨에게 접근하다가 오후 6시 33분께 풀숲에 숨은 성씨가 허공에 난사한 10여발의 총알 중 일부를 왼쪽 어깨 뒷부분에 맞고 쓰러졌다',
'김 경위는 구급차가 도착했을 때 이미 의식이 없었고 심폐소생술을 하며 병원으로 옮겨졌으나 총알이 폐를 훼손해 오후 7시 40분께 사망했다',
'김 경위는 외근용 조끼를 입고 있었으나 총알을 막기에는 역부족이었다',
'머리에 부상을 입은 이씨도 함께 병원으로 이송됐으나 생명에는 지장이 없는 것으로 알려졌다',
'성씨는 오패산 터널 밑쪽 숲에서 오후 6시 45분께 잡혔다',
'총격현장 수색하는 경찰들 서울 연합뉴스 이효석 기자 19일 오후 서울 강북구 오패산 터널 인근에서 경찰들이 폭행 용의자가 사제총기를 발사해 경찰관이 사망한 사건을 조사 하고 있다',
'총 때문에 쫓던 경관들과 민간인들이 몸을 숨겼는데 인근 신발가게 직원 이모씨가 다가가 성씨를 덮쳤고 이어 현장에 있던 다른 상인들과 경찰이 가세해 체포했다',
'성씨는 경찰에 붙잡힌 직후 나 자살하려고 한 거다 맞아 죽어도 괜찮다 고 말한 것으로 전해졌다',
'성씨 자신도 경찰이 발사한 공포탄 1발 실탄 3발 중 실탄 1발을 배에 맞았으나 방탄조끼를 입은 상태여서 부상하지는 않았다',
'경찰은 인근을 수색해 성씨가 만든 사제총 16정과 칼 7개를 압수했다 실제 폭발할지는 알 수 없는 요구르트병에 무언가를 채워두고 심지를 꽂은 사제 폭탄도 발견됐다',
'일부는 숲에서 발견됐고 일부는 성씨가 소지한 가방 안에 있었다'
]
komoran = Komoran()
def komoran_tokenizer(sent):
words = komoran.pos(sent, join=True)
words = [w for w in words if ('/NN' in w or '/XR' in w or '/VA' in w or '/VV' in w)]
return words
summarizer = KeysentenceSummarizer(
tokenize = komoran_tokenizer,
min_sim = 0.3,
verbose = False
)
keysents = summarizer.summarize(sents, topk=3)오패산터널 총격전 용의자 검거 서울 연합뉴스 경찰 관계자들이 19일 오후 서울 강북구 오패산 터널 인근에서 사제 총기를 발사해 경찰을 살해한 용의자 성모씨를 검거하고 있다 성씨는 검거 당시 서바이벌 게임에서 쓰는 방탄조끼에 헬멧까지 착용한 상태였다
경찰에 따르면 성씨는 19일 오후 강북경찰서 인근 부동산 업소 밖에서 부동산업자 이모 67 씨가 나오기를 기다렸다 이씨와는 평소에도 말다툼을 자주 한 것으로 알려졌다
서울 연합뉴스 김은경 기자 사제 총기로 경찰을 살해한 범인 성모 46 씨는 주도면밀했다
To summarize texts with keywords,
from textrank import KeywordSummarizer
summarizer = KeywordSummarizer(tokenize=komoran_tokenizer, min_count=2, min_cooccurrence=1)
summarizer.summarize(sents, topk=20)[('용의자/NNP', 3.040833543583403),
('사제총/NNP', 2.505798518168069),
('성씨/NNP', 2.4254730689696298),
('서울/NNP', 2.399522533743009),
('경찰/NNG', 2.2541631612221043),
('오후/NNG', 2.154778397410354),
('폭행/NNG', 1.9019818685234693),
('씨/NNB', 1.7517679455874249),
('발사/NNG', 1.658959293729613),
('맞/VV', 1.618499063577056),
('분/NNB', 1.6164369966921637),
('번동/NNP', 1.4681655196749035),
('현장/NNG', 1.4530182347939307),
('시/NNB', 1.408892735491178),
('경찰관/NNP', 1.4012941012332316),
('조사/NNG', 1.4012941012332316),
('일/NNB', 1.3922748983755766),
('강북구/NNP', 1.332317291003927),
('연합뉴스/NNP', 1.3259099432277819),
('이씨/NNP', 1.2869280494707418)]
개발 환경: Ubuntu(Docker), HTML, CSS, PHP, JS
활용 플랫폼: Docker, PHP, Apache
FROM oberd/php-8.0-apache
RUN apt-get update && apt-get install -y vim
RUN echo "AddType application/x-httpd-php .html" >> /etc/apache2/mods-enabled/mime.conf
COPY src/ .
RUN cp crawling_main.html index.html
- 웹 구축을 위해 Apache를 사용.
- HTML에서 PHP 문법을 사용하기 때문에 PHP + HTML+PHP 호환 Apache 설정 추가.
function db_get_pdo()
{
$host = $_SERVER['REMOTE_ADDR'];
$host[-1] = '3';
$port = '3306';
$dbname = 'crawl_new';
$charset = 'utf8';
$username = 'root';
$db_pw = "test1234";
$dsn = "mysql:host=$host;port=$port;dbname=$dbname;charset=$charset";
$pdo = new PDO($dsn, $username, $db_pw);
return $pdo;
}
function db_select($query, $param=array()){
$pdo = db_get_pdo();
try {
$st = $pdo->prepare($query);
$st->execute($param);
$result =$st->fetchAll(PDO::FETCH_ASSOC);
$pdo = null;
return $result;
} catch (PDOException $ex) {
return false;
} finally {
$pdo = null;
}
}$JTBC = db_select("select * from JTBC");
$KBS = db_select("select * from KBS");
$MBC = db_select("select * from MBC");
$NEWS1 = db_select("select * from NEWS1");
$NEWSIS = db_select("select * from NEWSIS");
$SBS = db_select("select * from SBS");
$YTN = db_select("select * from YTN");
$연합뉴스 = db_select("select * from 연합뉴스");
$경향신문 = db_select("select * from 경향신문");
$국민일보 = db_select("select * from 국민일보");
$조선일보 = db_select("select * from 조선일보");
$한겨레 = db_select("select * from 한겨레");
- php PDO를 통해 MySQL DB와 Connection.
<div class="rankingnews _popularWelBase _persist">
<div class="rankingnews_head">
<h2 class="rankingnews_tit">실시간 <em>뉴스</em></h2>
<ul class="rankingnews_tab">
<li class="rankingnews_tab_item nclicks('RBP.rnk') is_selected"><a href="./crawling_new.html">최신 뉴스</a></li>
<li class="rankingnews_tab_item nclicks('RBP.cmt') "><a href="./crawling_main.html">주요 뉴스</a></li>
<li class="rankingnews_tab_item nclicks('RBP.cmt')"><a href="./crawling_keywords.html">실시간 검색어</a></li>
</ul>
</div>
<div class=\"rankingnews_box_wrap _popularRanking\">
<div class=\"rankingnews_box\">
<a href=\"{$NEWS[$i]['url']}\" class=\"rankingnews_box_head nclicks('RBP.rnkpname')\">
<span class=\"rankingnews_thumb\"><img src= \"{$NEWS[$i]['image']}\" width=\"26\" height=\"26\" alt=\"KBS\"></span>
<strong class=\"rankingnews_name\">{$NEWS[$i]['name']}</strong>
</a>
<ul class=\"rankingnews_list\">
<li>
<em class=\"list_ranking_num\">$a</em>
<div class=\"list_content\">
<a href=\"{$NEWS[$i]['db'][$j]['url']}\" class=\"list_title nclicks('RBP.rnknws')\">{$NEWS[$i]['db'][$j]['title']}</a>
<span class=\"list_time\">{$NEWS[$i]['db'][$j]['time']}</span>
</div>
<a href=\"{$NEWS[$i]['db'][$j]['url']}\" class=\"list_img nclicks('RBP.rnknws')\">
<img src=\"{$NEWS[$i]['db'][$j]['image']}\" width=\"70\" height=\"70\" alt=\"\" onerror=\"this.src='https://ssl.pstatic.net/static.news/image/news/errorimage/noimage_70x70_1.png';\">
</a>
</li>
</ul>
</div>
</div>
</div>- NAVER 뉴스 TEMPLATE HTML, CSS를 PHP로 커스텀마이징하여 활용. (DB와 연계)
<script language="JavaScript">
new Chart(document.getElementById("pie-chart"), {
type: 'pie',
data: {
labels: [
"<?= $KEYWORDS[0]['keyword'] ?>", "<?= $KEYWORDS[1]['keyword'] ?>", "<?= $KEYWORDS[2]['keyword'] ?>", "<?= $KEYWORDS[3]['keyword'] ?>",
"<?= $KEYWORDS[4]['keyword'] ?>", "<?= $KEYWORDS[5]['keyword'] ?>", "<?= $KEYWORDS[6]['keyword'] ?>", "<?= $KEYWORDS[7]['keyword'] ?>",
"<?= $KEYWORDS[8]['keyword'] ?>", "<?= $KEYWORDS[9]['keyword'] ?>", "<?= $KEYWORDS[10]['keyword'] ?>", "<?= $KEYWORDS[11]['keyword'] ?>",
"<?= $KEYWORDS[12]['keyword'] ?>", "<?= $KEYWORDS[13]['keyword'] ?>", "<?= $KEYWORDS[14]['keyword'] ?>", "<?= $KEYWORDS[15]['keyword'] ?>",
"<?= $KEYWORDS[16]['keyword'] ?>", "<?= $KEYWORDS[17]['keyword'] ?>", "<?= $KEYWORDS[18]['keyword'] ?>", "<?= $KEYWORDS[19]['keyword'] ?>"
],
datasets: [{
label: "Population (millions)",
backgroundColor: ['#202020', '#242424', '#282828', '#2c2c2c', '#303030', '#343434', '#383838', '#3c3c3c', '#404040', '#444444', '#484848', '#4c4c4c', '#505050', '#545454', '#585858', '#5c5c5c', '#606060', '#646464', '#686868', '#6c6c6c'],
data: [
"<?= $KEYWORDS[0]['persent'] ?>", "<?= $KEYWORDS[1]['persent'] ?>", "<?= $KEYWORDS[2]['persent'] ?>", "<?= $KEYWORDS[3]['persent'] ?>",
"<?= $KEYWORDS[4]['persent'] ?>", "<?= $KEYWORDS[5]['persent'] ?>", "<?= $KEYWORDS[6]['persent'] ?>", "<?= $KEYWORDS[7]['persent'] ?>",
"<?= $KEYWORDS[8]['persent'] ?>", "<?= $KEYWORDS[9]['persent'] ?>", "<?= $KEYWORDS[10]['persent'] ?>", "<?= $KEYWORDS[11]['persent'] ?>",
"<?= $KEYWORDS[12]['persent'] ?>", "<?= $KEYWORDS[13]['persent'] ?>", "<?= $KEYWORDS[14]['persent'] ?>", "<?= $KEYWORDS[15]['persent'] ?>",
"<?= $KEYWORDS[16]['persent'] ?>", "<?= $KEYWORDS[17]['persent'] ?>", "<?= $KEYWORDS[18]['persent'] ?>", "<?= $KEYWORDS[19]['persent'] ?>"
]
}]
},
options: {
title: {
display: true,
text: '실시간 검색어 순위'
}
}
});
</script>- 실시간 검색어 순위를 표현하는 부분은 Chart.js를 활용.
Docker-Compose 를 활용.
version: '3.8'
services:
site:
build: ./crawl_site/
image: gyeongje/site
container_name: site
ports:
- "80:80"
depends_on:
- crawl_main
- crawl_new
- crawl_keyword
- crawl_main_db
- crawl_new_db
- crawl_keyword_db
restart: always
crawl_main:
build: ./crawl_main/
image: gyeongje/crawl_main
container_name: crawl_main
stdin_open: true
tty: true
depends_on:
- crawl_main_db
- crawl_new_db
- crawl_keyword_db
restart: always
crawl_new:
build: ./crawl_new/
image: gyeongje/crawl_new
container_name: crawl_new
stdin_open: true
tty: true
depends_on:
- crawl_main
restart: always
crawl_keyword:
build: ./crawl_keyword/
image: gyeongje/crawl_keyword
container_name: crawl_keyword
stdin_open: true
tty: true
depends_on:
- crawl_main
- crawl_new
restart: always
crawl_main_db:
image: mysql
container_name: crawl_main_db
environment:
- MYSQL_ROOT_PASSWORD=test1234
- TZ=Asia/Seoul
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
- --skip-character-set-client-handshake
crawl_new_db:
image: mysql
container_name: crawl_new_db
environment:
- MYSQL_ROOT_PASSWORD=test1234
- TZ=Asia/Seoul
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
- --skip-character-set-client-handshake
depends_on:
- crawl_main_db
crawl_keyword_db:
image: mysql
container_name: crawl_keyword_db
environment:
- MYSQL_ROOT_PASSWORD=test1234
- TZ=Asia/Seoul
command:
- --character-set-server=utf8mb4
- --collation-server=utf8mb4_unicode_ci
- --skip-character-set-client-handshake
depends_on:
- crawl_main_db
- crawl_new_db
docker-compose down
docker-compose up -d --build
DEMO 영상 (link)
