yolo4主要做了如下工作:
-
提出了一种实时、高精度的目标检测模型。 它可以使用1080Ti 或 2080Ti 等通用 GPU 来训练快速和准确的目标检测器;
-
在检测器训练阶段,验证了一些最先进的 Bag-of-Freebies 和 Bag-of-Specials 方法的效果;
-
对 SOTA 方法进行改进,使其效率更高,更适合单 GPU 训练,包括 CBN,PAN 和 SAM 等。
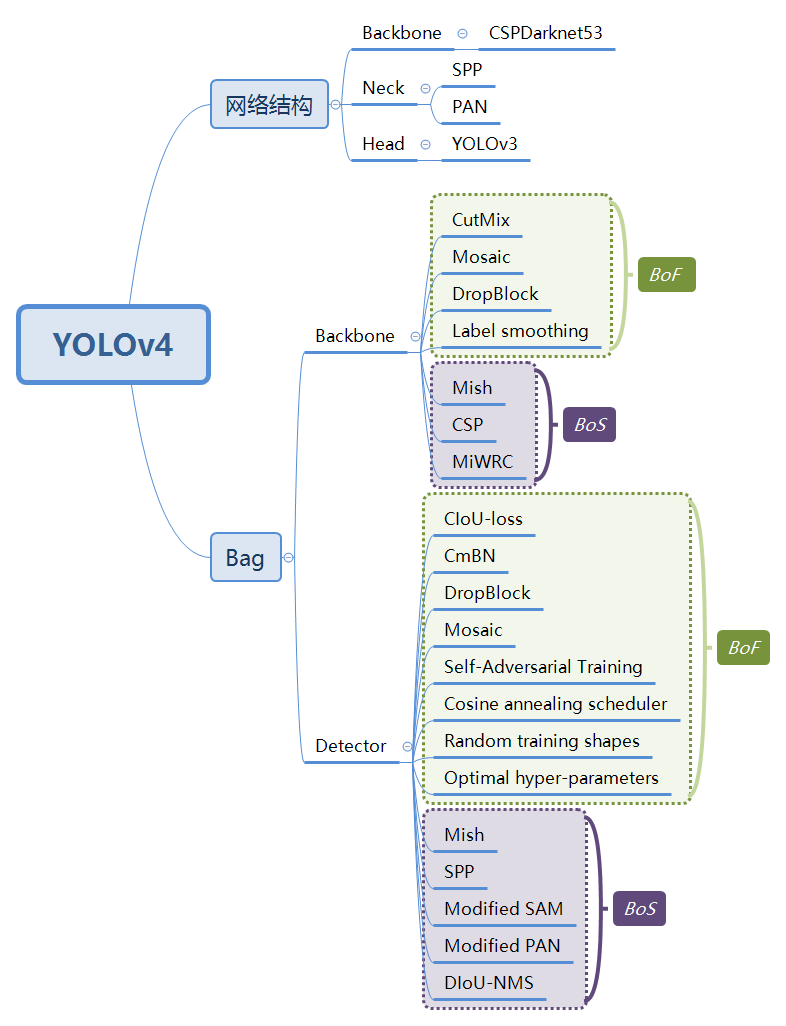
Yolo4的网络结构如下图所示:
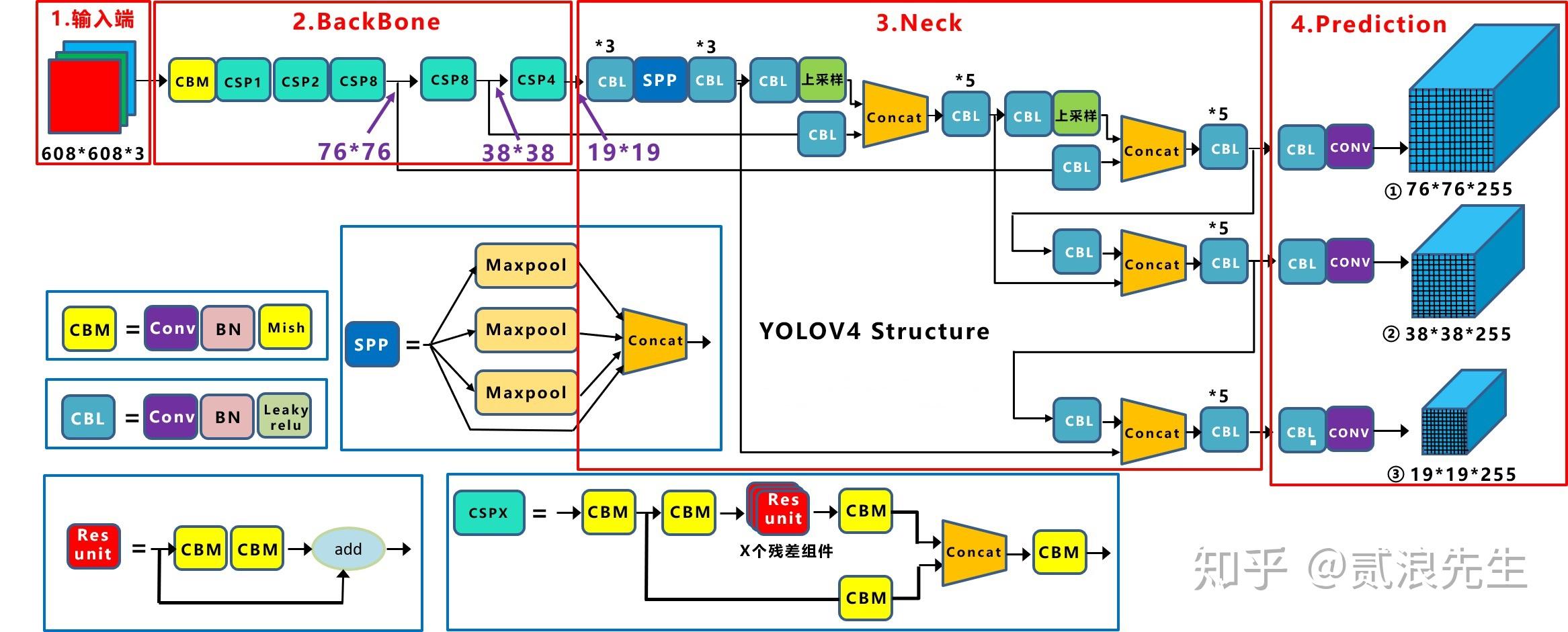
yolo4的主干网络网络为CSPDarknet53,CSPDarknet53是在Darknet53网络基础上添加CSP(Cross Stage Partial Network)模块,CSP模块主要是借鉴densenet的思想,提出跨阶段局部连接连接模块减小计算量,如下图所示:
可以看出csp把input split两部分,每一部分维度为原来的一半,第一部分作dense block的计算,第二部分与第一部分dense block的计算结果concate。作者尝试了3中csp结构,如下图所示:
b,c,d 3种结构的计算量跟精度如下图所示:
Fusion first结构减少了26%的计算量,但却损失1.5%的精度;Fusion last结构减小21%计算量,减少0.1%的计算量,b中结构减小13%计算量,增加0.2%计算量。yolo4中选取b结构。
Neck主要包含:
-
SPPNet
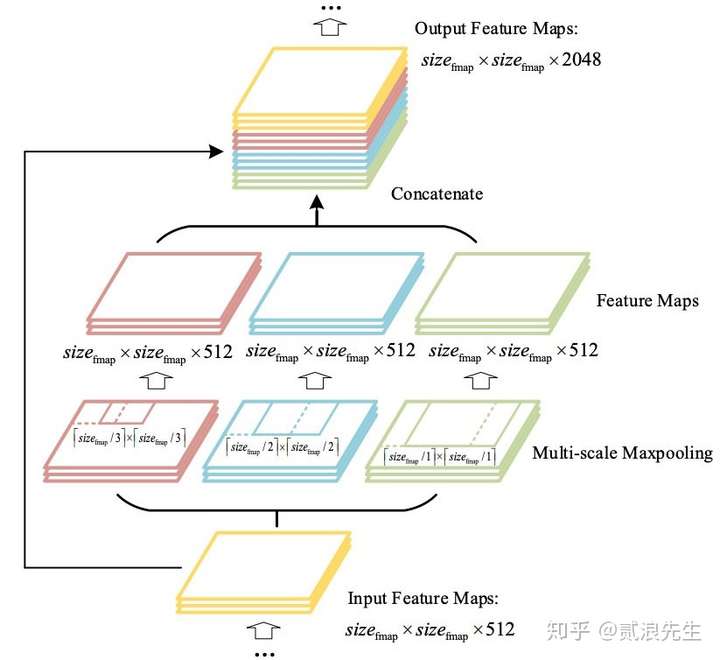
在 YOLOv4 中,对 SPP 进行了修改以保证输出的空间维度。 最大池化的核大小为 k = {1×1、5×5、9×9、13×13}。将来自不同核大小池化后的特征图串联在一起作为输出。 采用 SPP 层的方式,比单纯的使用单个尺寸核大小的最大池化的方式,更有效的增加主干网络的感受野,显著的分离最重要的上下文特征。 YOLOv3的作者在使用 608 * 608 大小的图像进行测试时发现,在 COCO 目标检测任务中,以 0.5% 的额外计算代价将 AP50 增加了 2.7%。
-
PANet
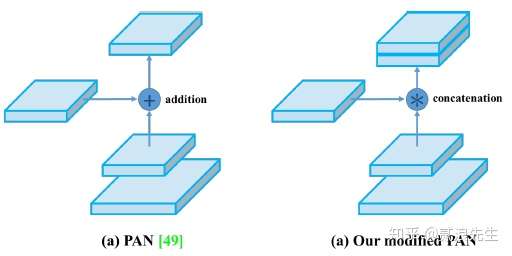
PANet是为了融合更加细粒度特征,FPN采用top-down形式融合特征,PANet自低向上的路径得到增强,使得底层信息更容易传播到顶部,在FPN中,局部信息会向上传播,如红色箭头所示。尽管图中可能没有展示清楚,但这条红色路径穿过了大约100多层。PANet引入一个捷径(绿色路径),其仅需10层左右就能抵达顶部的Ns层,这个短回路概念使得顶层也能获取到细粒度的局部信息。
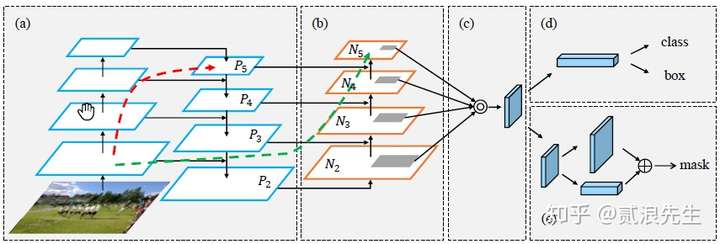
yolo4把原来PANet中add操作改成了concate操作。
参考Yolo3的Head
yolo4论文中还提出了SAM空间注意力模块,但是实际code中并未使用,猜测可能是计算量限制,SAM模块会为输入进行最大值和均值池化,从而得到两个特征图集合,最终进行卷积操作,之后再由一个sigmoid函数创建出空间注意力。这个空间注意力掩码再被应用于输入特征,从而输出经过注意力的特征图。原SAM模块如下图所示:

Yolo4改进了空间注意力模块,没有使用maxpool和avgpool

- Mosaic data aug mentation
- Self-Adversarial Training
- CmBN
- DropBlock
- Mish activation
-
分类损失函数:
交叉熵损失函数
-
回归损失函数:
CIOU-Loss
- DIOU-NMS
Yolo4的试验做的十分充分,各种训练技巧对于调参来说有可以借鉴很多,CSP模块能够有效减小模型计算量。