R-FCN提出PS-ROI-Pooling层不需要每一个roi单独提取特征再进行全连接操作进行分类和回归,R-FCN是全卷积网络能够提升训练和测试阶段的检测速度。
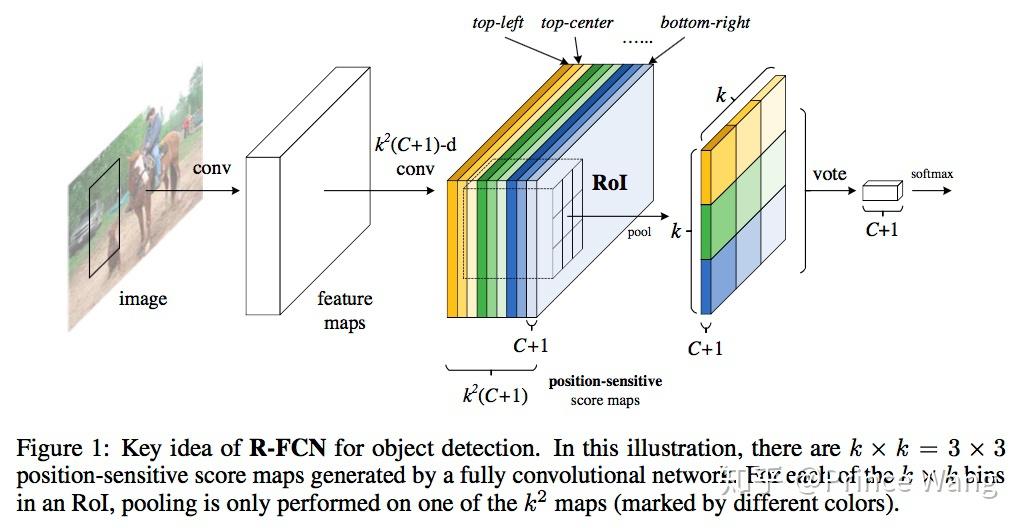
图1
作者论文实验中使用的ResNet-101,同时修改了部分网络,把conv5的stride=2改为了stride=1,同时中间卷积层的dilation设置为2,增加感受野。这样最后最总特征图谱为16倍下采样
Neck部分这里即为RPN部分,可参考Faster-RCNN的RPN部分。
RPN阶段刷选出rois通过position-sensitive RoI pooling layer,通过PS-ROI-Pooling操作提取特征来分类和回归。如下图所示:
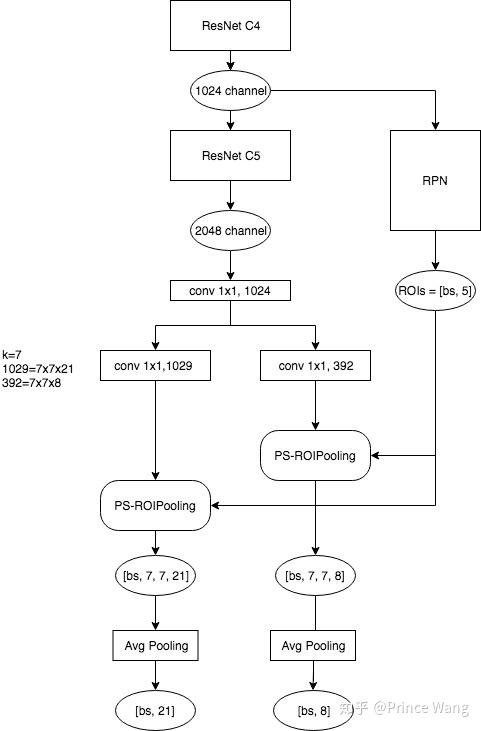
RPN得到的features会被复用到后面的分类中,这个特征提取器文中是使用的resnet101,假设这个特征图的大小是[1, H, W, 1024],本来ROI Pooling直接就在这上面截取ROI来分类了,而现在我们再后面再接上ResNet的C5(1024->2048, dilation=2),继续在上面接一个1x1的卷积(2048->1024),这个操作是为了降维和通道整合,同时不改变特征图大小。再经过一个1x1的卷积,把通道缩减为k x k x (C+1),这里的k指的是bin的数量,也就是上面说的3,类别假设是20,在实际的实现中,大部分的情况k=7。现在特征图大小是[1, H, W, 3x3x21]了,如下图,相同颜色的特征图对应着结果中对应颜色的位置,比如黄色的特征图对应结果中的左上角。特征图被分为9x21通道,每21个特征图代表这个位置(比如左上角)的21个分类的分数,比如[020]的特征图中每个点(x, y)表示原图上这个点是对应物体“左上部分“的概率,[2141]的特征图中每个点(x, y)表示原图上这个点是对应物体“上部分“的概率,以此类推。为了更直观的说明PS-ROIPooling的过程,如下的示意图所示:
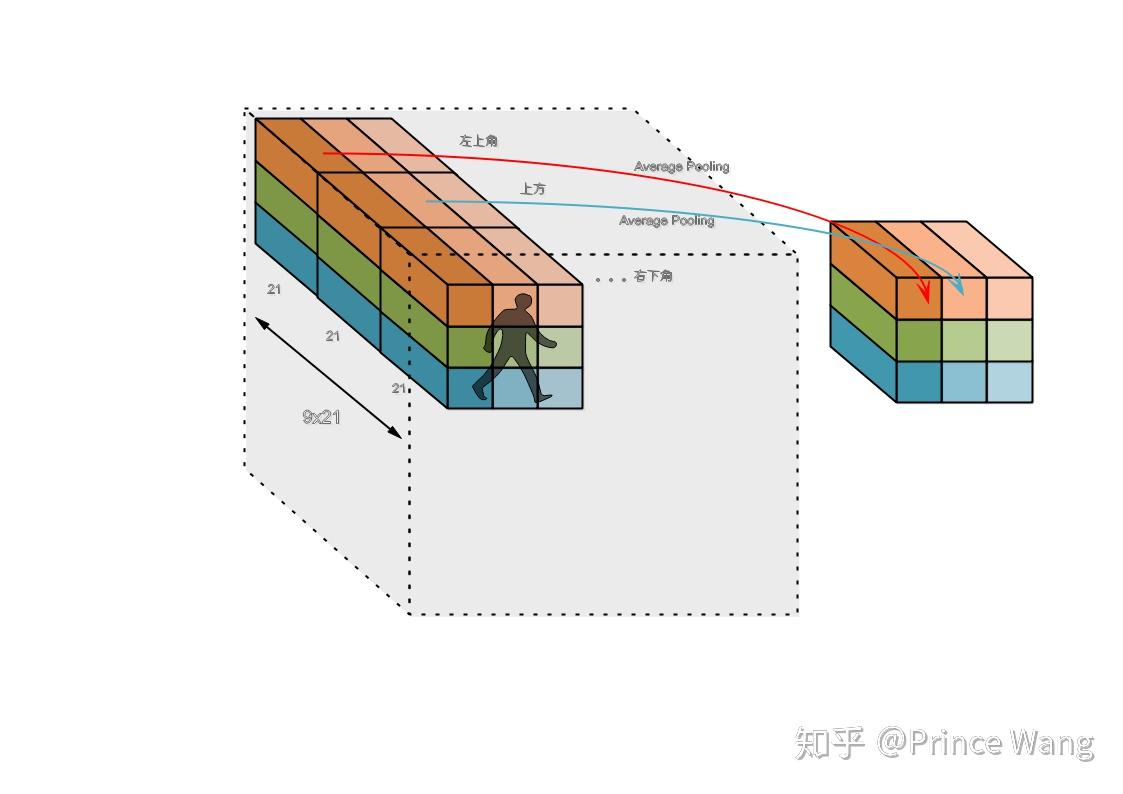
在上图中,每个ROI也被分为了3x3的bins,就和我们在普通的ROIPooling中做的一样,在确定完输入和输出的映射以后,PS-ROIPooling把对应的block中的值求Average Pooling(红色箭头),最后得出了一个[1x1x21]的向量。在经过PS-ROIPooling之后,把对应的特征图的部分做Average Pooling后的9个[1x1x21]的特征图后把这些特征图拼成[9x9x21],这个新的特征图的每个位置表示了该ROI候选框的9个子块区域是21个物体某一部分的概率。
可参考Faster-RCNN的Sample Assignment部分。
可参考Faster-RCNN的Decode部分。
可参考Faster-RCNN Loss部分。
我认为R-FCN最大的贡献是去除了Faster-RCNN的全链接层,用全卷积层来进行end-to-end训练,在训练和inference阶段能够较小计算量。至于论文里面所得位置敏感得分图的解释我觉得是有点自圆其说的感觉。