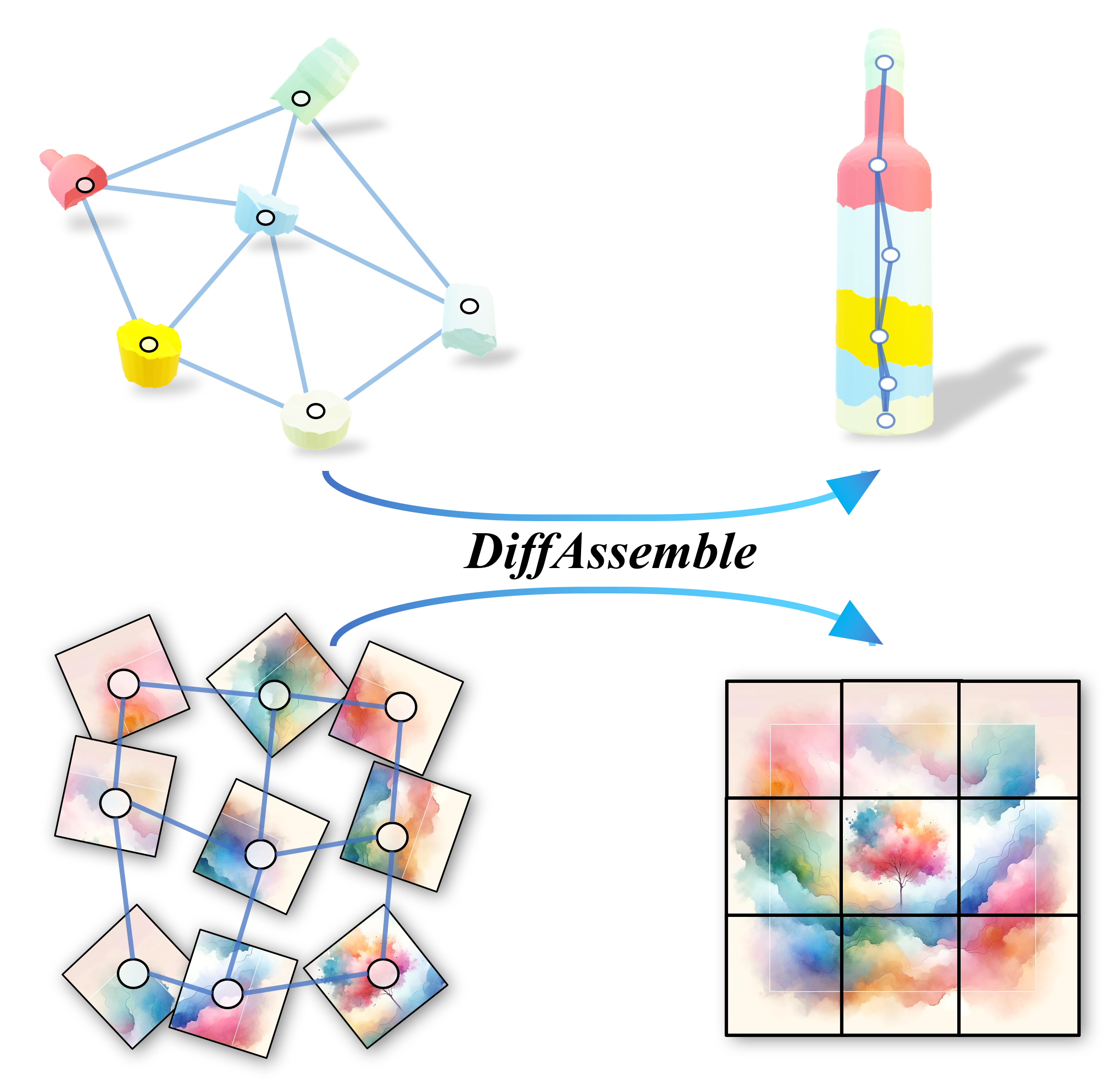
Reassembly tasks play a fundamental role in many fields and multiple approaches exist to solve specific reassembly problems. In this context, we posit that a general unified model can effectively address them all, irrespective of the input data type (images, 3D, etc.). We introduce DiffAssemble, a Graph Neural Network (GNN)-based architecture that learns to solve reassembly tasks using a diffusion model formulation. Our method treats the elements of a set, whether pieces of 2D patch or 3D object fragments, as nodes of a spatial graph. Training is performed by introducing noise into the position and rotation of the elements and iteratively denoising them to reconstruct the coherent initial pose. DiffAssemble achieves State-Of-The-Art (SOTA) results in most 2D and 3D reassembly tasks and is the first learning-based approach that solves 2D puzzles for both rotation and translation. Furthermore, we highlight its remarkable reduction in run-time, performing 11 times faster than the quickest optimization-based method for puzzle solving. We will release the code upon paper acceptance.
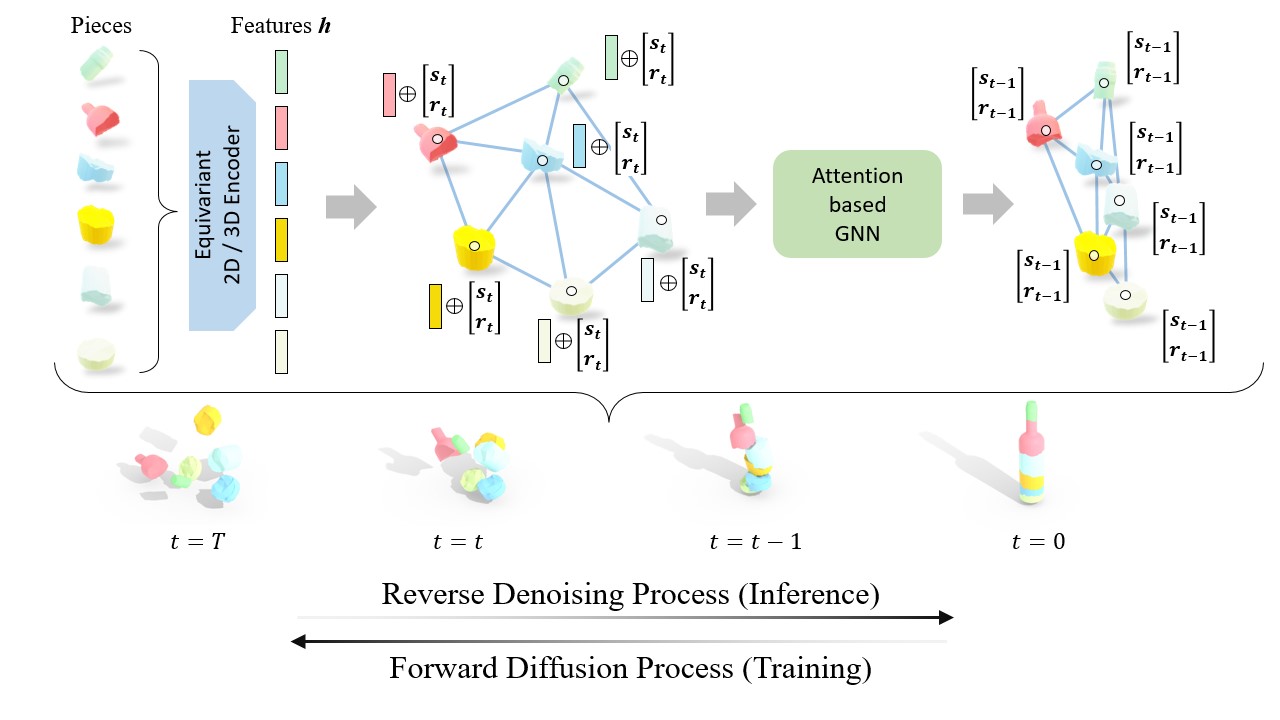 Following the Diffusion Probabilistic Models formulations, we model a Markov chain where we inject noise into the pieces’ position and orientation. At timestep
Following the Diffusion Probabilistic Models formulations, we model a Markov chain where we inject noise into the pieces’ position and orientation. At timestep
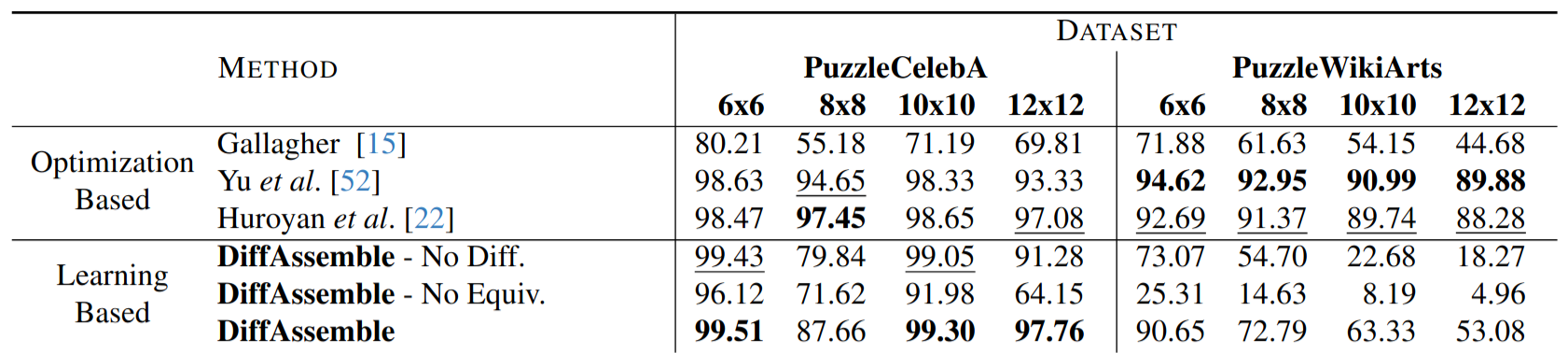 Table reports results for the visual puzzle reassembly task, with rotated and translated pieces. DiffAssemble achieves SOTA results in CelebA, improving over the optimization-based method. In Wikiart, the optimization-based approaches [22 , 52] outperform DiffAssemble. An explanation for this gap is that our method relies not only on pure visual appearances but also on the semantic content of the image.
Table reports results for the visual puzzle reassembly task, with rotated and translated pieces. DiffAssemble achieves SOTA results in CelebA, improving over the optimization-based method. In Wikiart, the optimization-based approaches [22 , 52] outperform DiffAssemble. An explanation for this gap is that our method relies not only on pure visual appearances but also on the semantic content of the image.
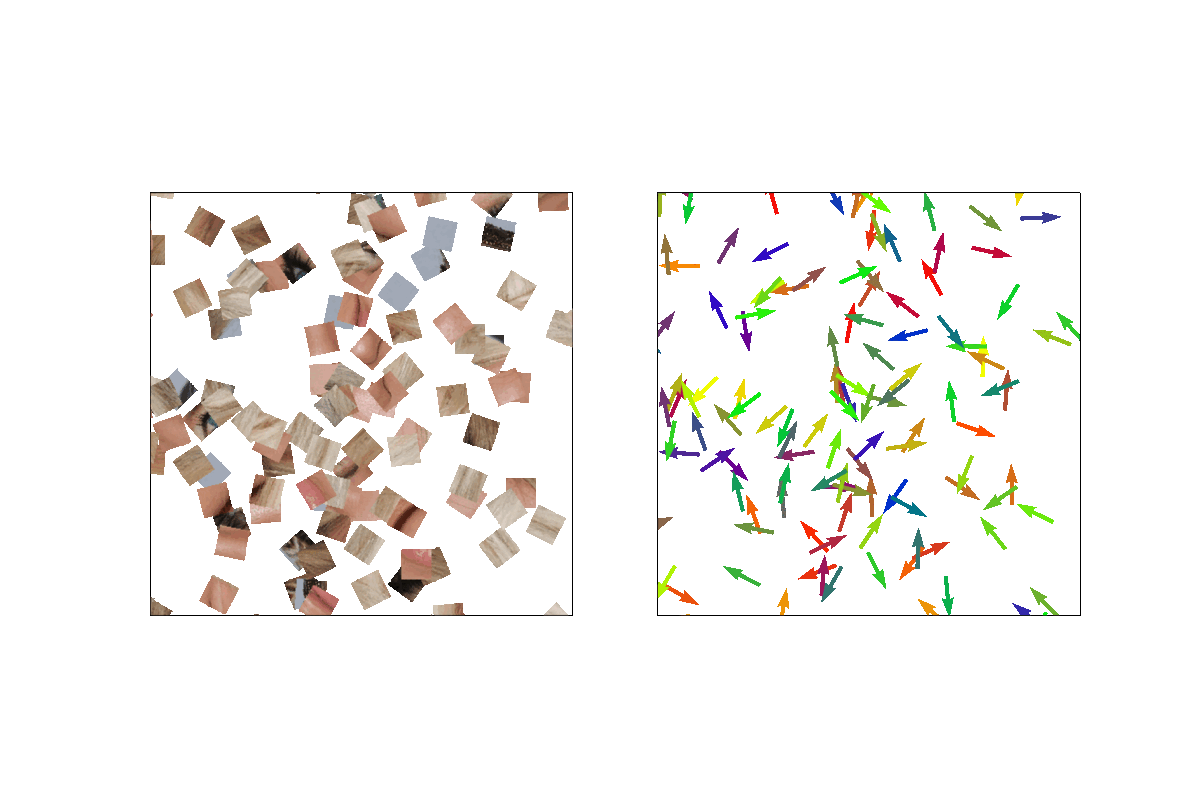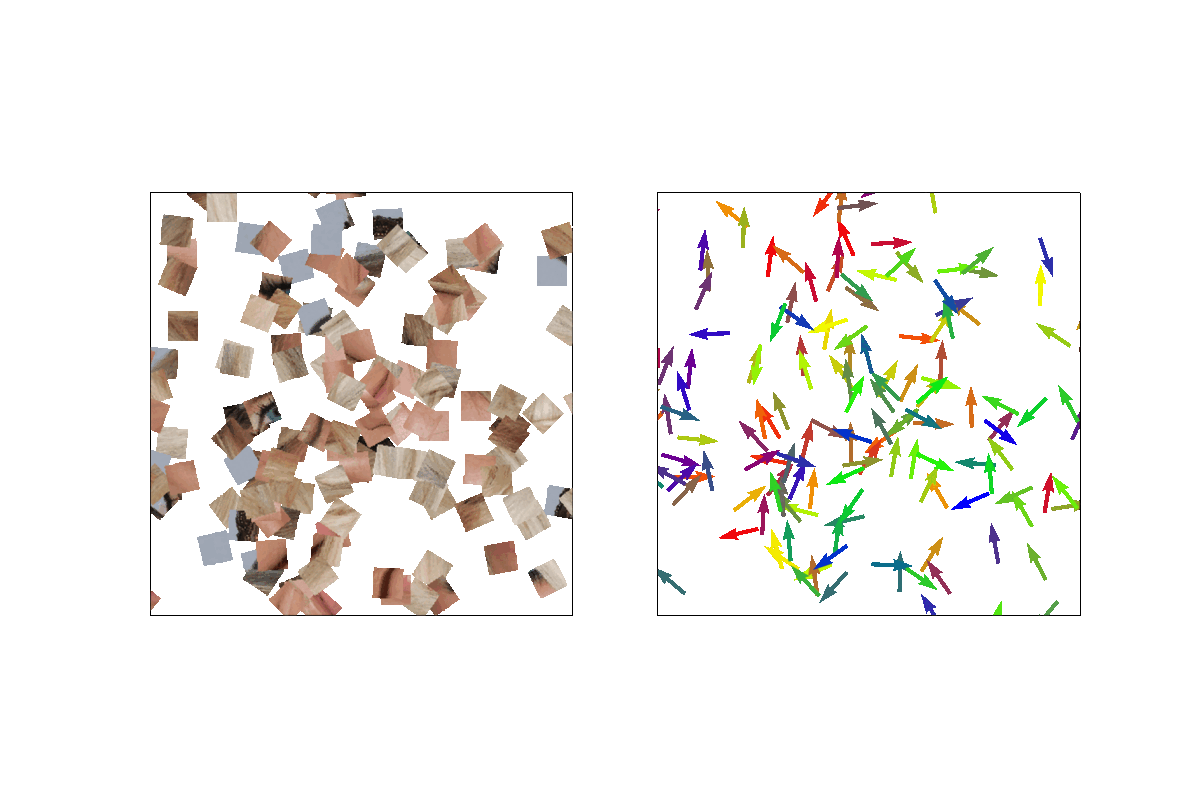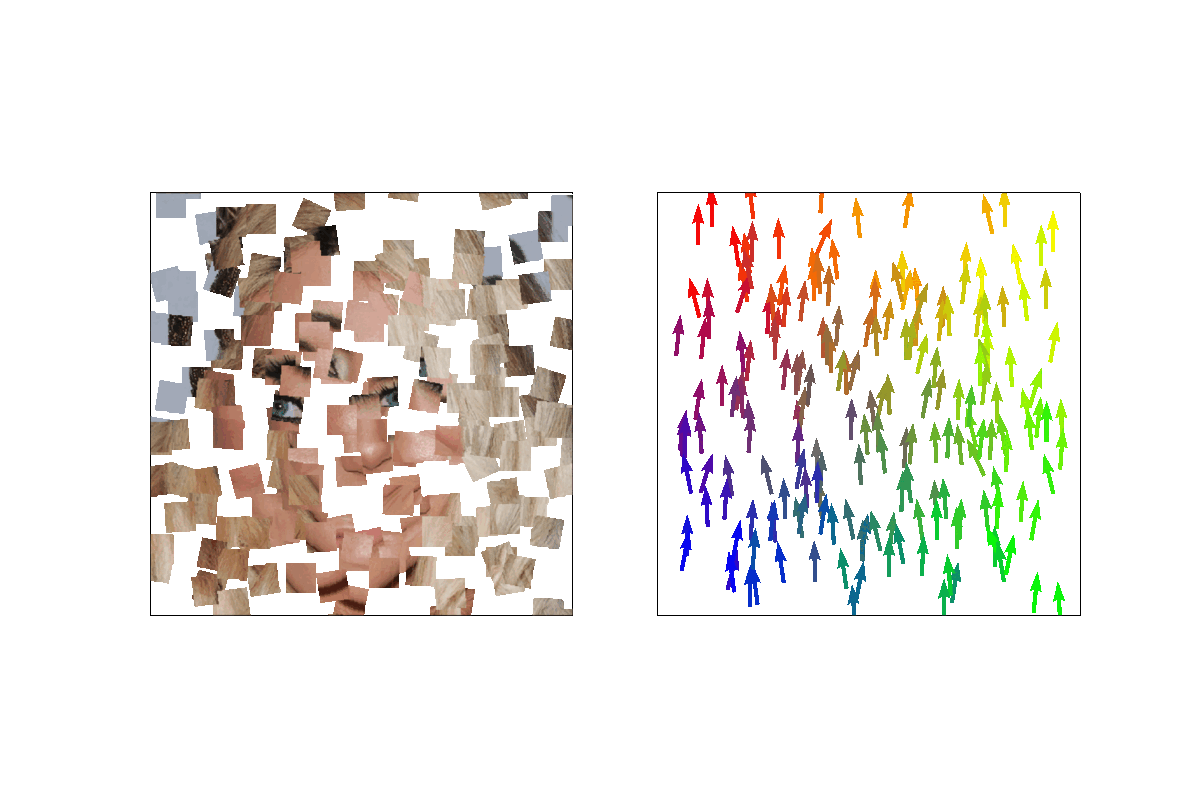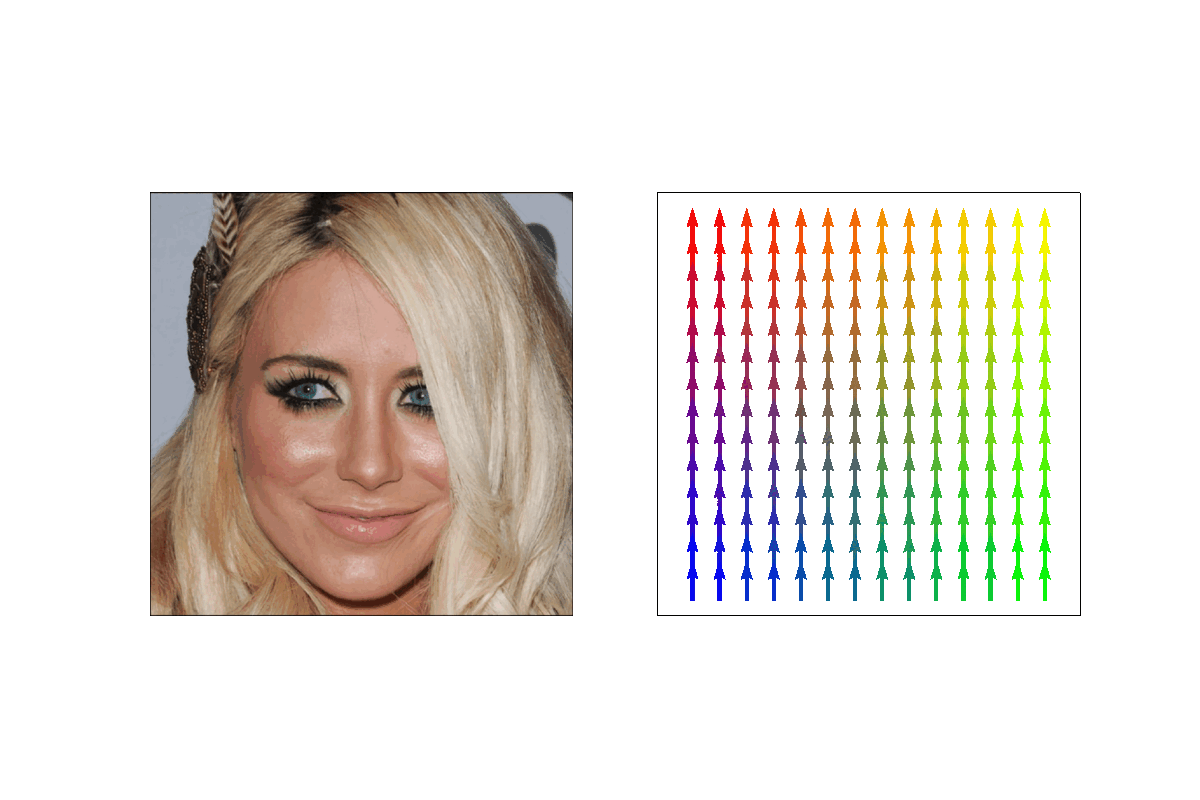

We report in the Table the results of the comparison on BB. Among the baselines, SE(3)-Equiv, which is the current SOTA, performs best in terms of RMSE(R), and DGL performs best in terms of RMSE(T) and PA. These baselines trade accuracy in rotation with accuracy in trans- lation, with SE(3)-Equiv performing well in rotation and worst in translation and DGL performing well in translation and badly in rotation. Contrarily, DiffAssemble outperforms the baselines on all metrics: rotation, translation, and part accuracy, showing the effectiveness of our approach.
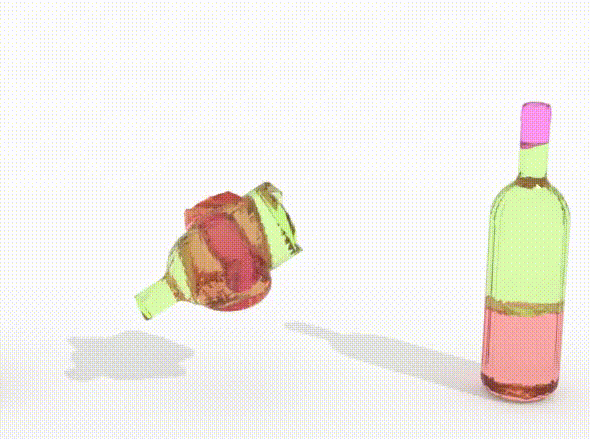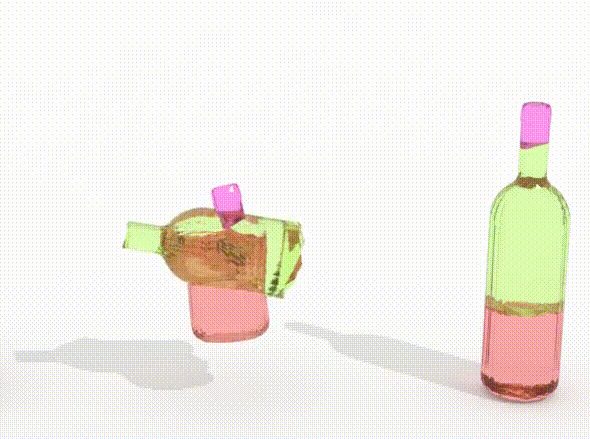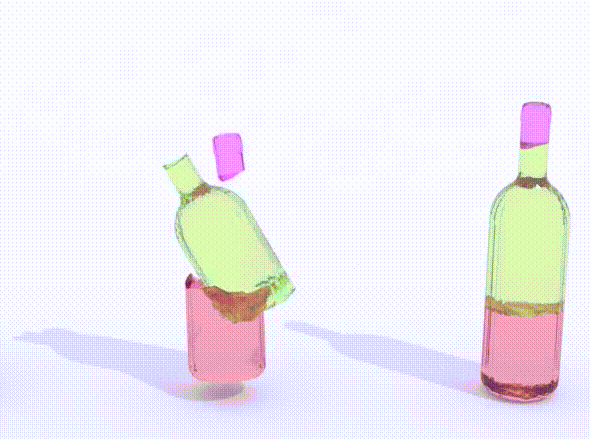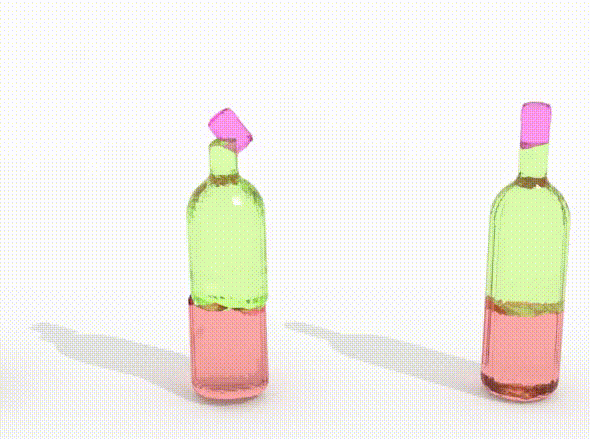
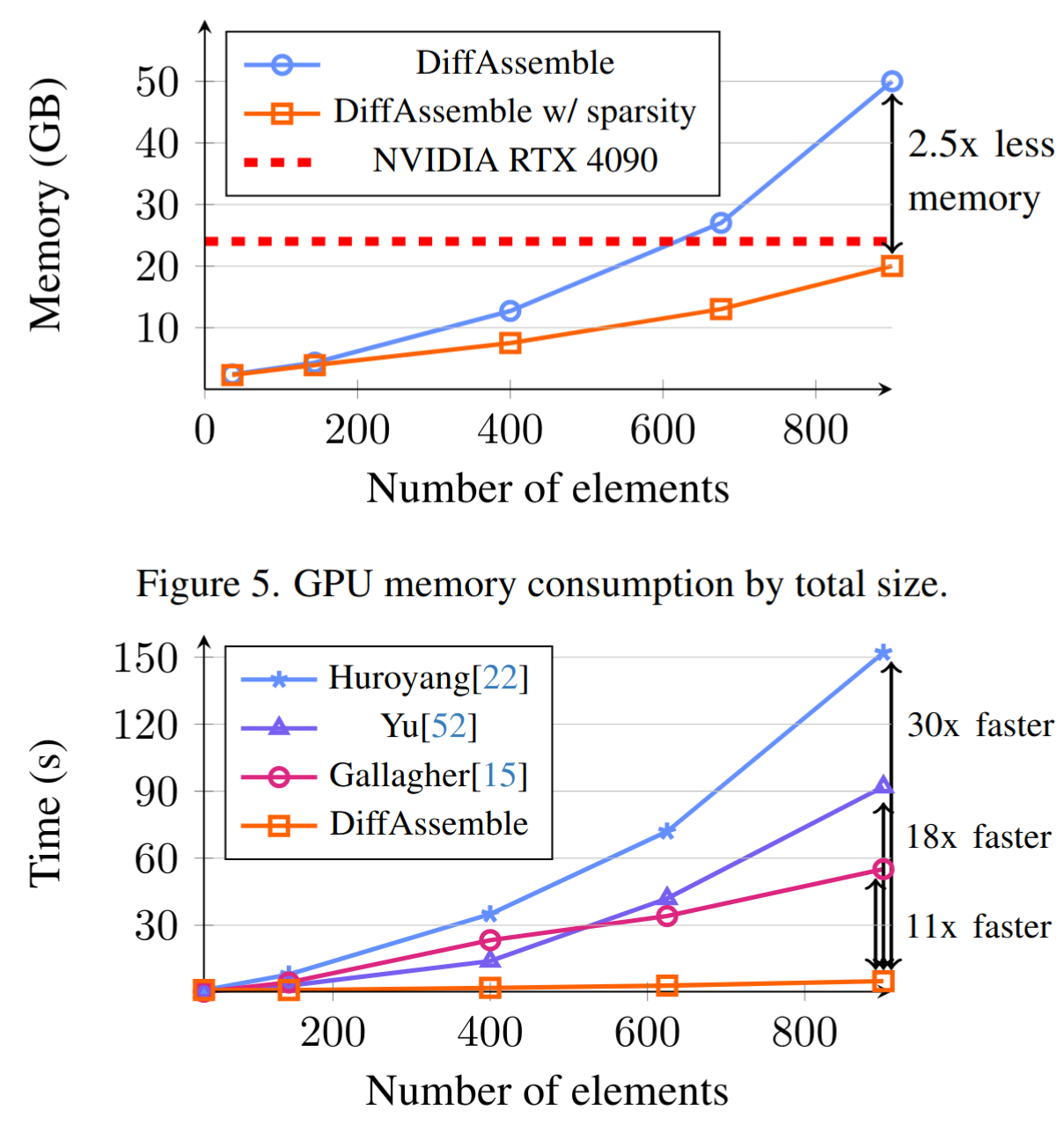
We investigate DiffAssemble with Exphander [41] for higher-dimensional puzzles. We explore the effectiveness of scaling our method with PuzzleCelebA puzzles up to 900 pieces (
The time required by optimization-based approaches increases exponentially with the number of elements and, consequently, with the number of matches. On the other hand, DiffAssemble re-
assembles up to 900 elements without scaling in time requirement, e.g., it solves
- Breaking bad: Link
- We provide the environment definition in
singularity/build/conda_env.yaml - Singularity image is also available at [WIP]
- Requirements:
- pytorch==1.12.1
- cudatoolkit<=11.3.10
- pyg
- einops
- black
- pre-commit
- pytorch-lightning<1.8
- pip
- matplotlib
- wandb
- transformers
- timm
- kornia
- trimesh
- scipy
@InProceedings{scarpellini2024diffassemble,
author = {Gianluca Scarpellini and Stefano Fiorini and Francesco Giuliari and Pietro Morerio and Alessio {Del Bue}},
title = {DiffAssemble: A Unified Graph-Diffusion Model for 2D and 3D Reassembly},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
}