Плюшки • Как использовать? • Установка • Стек • Авторы
- Кейс: "Статический анализатор SparkSQL с возможностью добавления пользовательских правил"
- Решают: команда I PRO
- Ссылка на репозиторий
- Ссылка на PyPi
- Ссылка на Google Colab - здесь можно попробовать код в действии онлайн, достаточно запустить все ячейки!
Необходимо разработать статический анализатор SparkSQL кода. Грамматика должна расширяться через отдельный BNF файл (https://en.wikipedia.org/wiki/Backus–Naur_form). Есть возможность добавлять пользовательские проверки в коде. Есть ООП интерфейс для использования из кода. Инструмент должен быть быстрым и изолированным.
swissql - это python библиотека для статического анализа SparkSQL, к которой также предоставляется CLI. Она состоит из следующих модулей:
- Syntax - синтаксический разбор и построение AST
- Format - форматирование
- Style - стилистический анализ
- Optimize - оптимизация SparkSQL запроса
- Anti_pattern - выявление антипаттернов
- Rule - поддержка пользовательских правил на основе BNF
- Extract - анализ SQL строк в кодовой базе
...или что делает это решение особенным.
- CLI интерфейс - сделает интеграцию в CI/CD как никогда привычной.
- Разноцветный текст для облегчения визуального восприятия в консоли.
- Утилита выложена и доступна на PyPi, что облегчает интеграцию в рабочий процесс.
- Использование поддерживаемых решений - это позволяет без проблем масштабировать проект и легче адаптировать его под другие диалекты SQL.
- Комментарии в коде помогут без лишних проблем использовать библиотеку в других python скриптах.
- Оптимизация запросов позволит сэкономить ресурсы при работе с BigQuery.
# Установка sqlcheck ( https://github.com/jarulraj/sqlcheck#installation )
# Debian
wget https://github.com/jarulraj/sqlcheck/releases/download/v1.3/sqlcheck-x86_64.deb
dpkg -i sqlcheck-x86_64.deb
# Windows
# При установке для Windows не забудьте добавить sqlcheck в PATH
wget https://github.com/jarulraj/sqlcheck/releases/download/v1.3/sqlcheck.exe
# После sqlcheck, установим swissql
pip install swissqlНаглядно использование swissql описано в нашем ноутбуке на Google Colab. Ниже приведены его фрагменты с объяснением того, как и что работает.
Синтаксический разбор SparkSQL и построение AST с помощью sqlglot позволяет проводить RBO (rule-based) оптимизации в модуле Optimize. Пример построенного AST:
$ # Использование отдельного модуля - Syntax
!python -m swissql syntax -q "SELECT * from x join y on x.id = y.id where x.id > 2"
[Generating syntax tree using sqlglot]
(SELECT expressions:
(STAR ), from:
(FROM expressions:
(TABLE this:
(IDENTIFIER this: x, quoted: False))), joins:
(JOIN this:
(TABLE this:
(IDENTIFIER this: y, quoted: False)), on:
(EQ this:
(COLUMN this:
(IDENTIFIER this: id, quoted: False), table:
(IDENTIFIER this: x, quoted: False)), expression:
(COLUMN this:
(IDENTIFIER this: id, quoted: False), table:
(IDENTIFIER this: y, quoted: False)))), where:
(WHERE this:
(GT this:
(COLUMN this:
(IDENTIFIER this: id, quoted: False), table:
(IDENTIFIER this: x, quoted: False)), expression:
(LITERAL this: 2, is_string: False))))С помощью sqlfluff мы получаем рекомендации по стилю кода. Пример рекомендаций можно увидеть ниже:
# Использование отдельного модуля - Style
!python -m swissql style -q "SELECT * from x join y on x.id = y.id where x.id > 2"
[Style sql query use sqlfluff]
/home/quakumei/Workspace/Code/sparkySQL/SparkSQL-Analyzer/swissql/analyzers/style/intermediate.sql
== [/home/quakumei/Workspace/Code/sparkySQL/SparkSQL-Analyzer/swissql/analyzers/style/intermediate.sql] FAIL
L: 1 | P: 1 | L044 | Query produces an unknown number of result columns.
L: 1 | P: 8 | L027 | Unqualified reference '*' found in select with more than
| one referenced table/view.
L: 1 | P: 10 | L010 | Keywords must be consistently upper case.
L: 1 | P: 17 | L010 | Keywords must be consistently upper case.
L: 1 | P: 17 | L051 | Join clauses should be fully qualified.
L: 1 | P: 24 | L010 | Keywords must be consistently upper case.
L: 1 | P: 39 | L010 | Keywords must be consistently upper case.
L: 1 | P: 53 | L009 | Files must end with a single trailing newline.
All Finished!
Форматирование кода осуществляется так же с помощью sqlglot. Пример отформатированного запроса:
[Formatting sql query using sqlglot]
SELECT
*
FROM x
JOIN y
ON x.id = y.id
WHERE
x.id > 2
Первичная оптимизация запроса производится с помощью sqlglot на основе построенного ранее AST дерева и схемы данных. Полный список
оптимизаций запроса включаает в себя такие операции как
expression = qualify_tables(expression, db=db, catalog=catalog)
expression = isolate_table_selects(expression)
expression = qualify_columns(expression, schema)
expression = pushdown_projections(expression)
expression = normalize(expression)
expression = unnest_subqueries(expression)
expression = expand_multi_table_selects(expression)
expression = pushdown_predicates(expression)
expression = optimize_joins(expression)
expression = eliminate_subqueries(expression)
expression = quote_identities(expression)
return expressionПример оптимизированного запроса:
# Использование отдельного модуля - Optimize
!python -m swissql optimize -q "SELECT * from x join y on x.id = y.id where x.id > 2" -s '{"x":{"id":"INT", "name":"STRING"},"y":{"id":"INT","name":"STRING"}}' -o optimize
[Optimizing sql query using sqlglot]
Optimization: optimize
SELECT
"x"."id" AS "id",
"x"."name" AS "name",
"y"."id" AS "id",
"y"."name" AS "name"
FROM (
SELECT
"x"."id" AS "id",
"x"."name" AS "name"
FROM "x" AS "x"
WHERE
"x"."id" > 2
) AS "x"
JOIN (
SELECT
"y"."id" AS "id",
"y"."name" AS "name"
FROM "y" AS "y"
) AS "y"
ON "x"."id" = "y"."id"Стоит отметить, что с помощью флага -o вы можете указать конкретно какие оптимизации вам требуются.
С помощью sqlcheck мы проверяем наши запросы на наличие в них антипаттернов. Модуль особенно полезен, поскольку предоставляет подробное объяснение, почему то или иное решение - плохое, и предлагает методы его решения.
Актуальный список выявляемых антипаттернов представлен здесь
# Использование отдельного модуля - Anti_Pattern
!python -m swissql anti_pattern -q "SELECT * from x join y on x.id = y.id where x.id > 2"
�[33m[Detecting anti-patterns using sqlcheck]�[0m
sqlcheck version 1.2.1
Debug build (NDEBUG not #defined)
+-------------------------------------------------+
| SQLCHECK |
+-------------------------------------------------+
> RISK LEVEL :: ALL ANTI-PATTERNS
> SQL FILE NAME :: temp.sql
> COLOR MODE :: ENABLED
> VERBOSE MODE :: ENABLED
> DELIMITER :: ;
-------------------------------------------------
==================== Results ===================
-------------------------------------------------
SQL Statement at line 1: �[1m�[31mselect * from x join y on x.id = y.id where x.id > 2;�[0m�[39m
[temp.sql]: (�[1m�[32mHIGH RISK�[0m�[39m) �[1m�[34mSELECT *�[0m�[39m
● Inefficiency in moving data to the consumer:
When you SELECT *, you're often retrieving more columns from the database than
your application really needs to function. This causes more data to move from
the database server to the client, slowing access and increasing load on your
machines, as well as taking more time to travel across the network. This is
especially true when someone adds new columns to underlying tables that didn't
exist and weren't needed when the original consumers coded their data access.
● Indexing issues:
Consider a scenario where you want to tune a query to a high level of
performance. If you were to use *, and it returned more columns than you
actually needed, the server would often have to perform more expensive methods
to retrieve your data than it otherwise might. For example, you wouldn't be able
to create an index which simply covered the columns in your SELECT list, and
even if you did (including all columns [shudder]), the next guy who came around
and added a column to the underlying table would cause the optimizer to ignore
your optimized covering index, and you'd likely find that the performance of
your query would drop substantially for no readily apparent reason.
● Binding
Problems:
When you SELECT *, it's possible to retrieve two columns of the same name from
two different tables. This can often crash your data consumer. Imagine a query
that joins two tables, both of which contain a column called "ID". How would a
consumer know which was which? SELECT * can also confuse views (at least in some
versions SQL Server) when underlying table structures change -- the view is not
rebuilt, and the data which comes back can be nonsense. And the worst part of it
is that you can take care to name your columns whatever you want, but the next
guy who comes along might have no way of knowing that he has to worry about
adding a column which will collide with your already-developed names.
[Matching Expression: �[1m�[34mselect *�[0m�[39m at line 1]
==================== Summary ===================
All Anti-Patterns and Hints :: 1
> High Risk :: 1
> Medium Risk :: 0
> Low Risk :: 0
> Hints :: 0
Поддержка пользовательских правил осуществляется с помощью Lark и добавления пользователем файлов с прописанной BNF грамматикой необходимого паттерна. Пример грамматики и обнаружения паттерна - ниже
# Как выглядит файл с BNF грамматикой
!cat rules/filter2.lark
SELECT WILDCARD ANTIPATTERN :END_OF_COMMENT:
start: /./ start | pattern start | /./ | pattern
pattern: "SELECT *"i
%import common.INT
//%ignore " "
%ignore "\n"Обнаружение пользовательского правила:
# Использование отдельного модуля - Rules
!python -m swissql rule -r filter2.lark -q "SELECT * from x join y on x.id = y.id where x.id > 2"
[Finding rules using lark]
Rule filter2.lark found:
Positions: (1, 1)
Comment: SELECT WILDCARD ANTIPATTERN Extract - модуль, на основе регулярных выражений для обнаружения строк и их парсинга с помощью Lark для отсеивания не SQL-запросов. Позволяет извлечь из кодовой базы SQL-запросы для дальнейшей обработки и рефакторинга. Пример работы:
# Анализируемый кусок кода
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType
from datetime import datetime, date
from pyspark.sql import Row
def init_spark():
spark = SparkSession.builder.appName("HelloWorld").getOrCreate()
sc = spark.sparkContext
return spark, sc
# SQl Queries
sql_queries = [
'SELECT * FROM table1;',
'SELECT * FROM table1 WHERE id = 1;',
'SELECT * FROM table1 WHERE id = 1 AND name = "John" OR name = "Jane" OR name = "Jack";',
]
def main():
spark_sql_queries = [
"SELECT * FROM table",
]
...
if __name__ == "__main__":
main()Результат:
# Использование отдельного модуля - Swissql extractor
!python -m swissql extract -f examples/example3.py
[Extracting Spark SQLs from file using lark]
Found:
SELECT * FROM table1
SELECT * FROM table1 WHERE id = 1
SELECT * FROM table1 WHERE id = 1 AND name = "John" OR name = "Jane" OR name = "Jack"
SELECT * FROM table
select * from tableA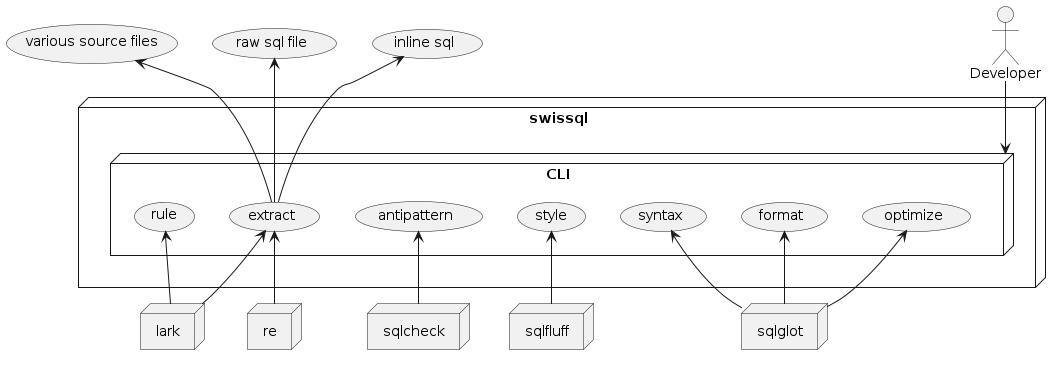
- argparse - Построение CLI
- sqlglot - Синтаксический разбор SparkSQL, оптимизация и форматирование
- sqlfluff - Стилистический анализ SparkSQL, рекомендации по стилю и форматирование
- sqlcheck - Детекция анти-паттернов в запросах SparkSQL. Рекоммендации по улучшению кода.
- Lark - Парсинг на основе BNF грамматики. Проверка строк на наличие SQL запроса, пользовательские правила.
Качество и едиснтво стиля кода в репозитории обеспечивается с помощью линтера black
- Распараллеливание вычислений при вызове
swissql all- позволило бы в несколько раз ускорить выполнение программы - Красивый веб-интерфейс
- Улучшить поиск антипаттернов в SparkSQL с использованием технологий искусственного интеллекта (ML / GNN)
- Егор Голубев - бекенд-разработчик
- Андрей Баранов - бекенд-разработчик
- Егор Смурыгин - продукт-менеджер
- Лебедева Татьяна - бекенд-разработчик
- Тампио Илья - бекенд-разработчик