System and end-to-end (E2E) tests for cardano-node.
Check this documentation for more details.
The easiest way to run the tests is by using Github Actions.
- fork this repository
- enable Github Actions in your fork ("Settings" / "Actions" / "General" / "Actions permissions", check "Allow all actions and reusable workflows")
- go to "Actions", select "01 Regression tests" (or "02 Regression tests with db-sync")
- select "Run workflow"
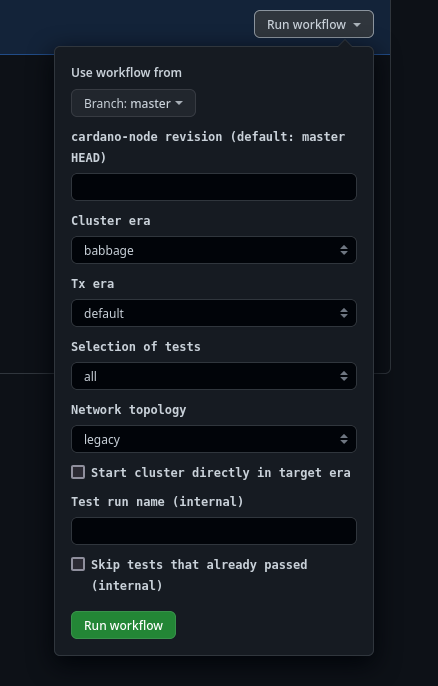
-
install and configure nix, follow cardano-node documentation
-
clone this repo
-
run the tests
./.github/regression.sh
NOTE
When using CI_BYRON_CLUSTER, it takes ~ 30 minutes for local cluster instance to get from Byron to Babbage. If it seems that tests are stuck, they are likely just waiting for local cluster instances to be fully started.
Sometimes it is useful to run individual tests and keep the local cluster running in between test runs.
-
run nix shell that has all the needed dependencies
nix flake update --accept-flake-config --override-input cardano-node "github:IntersectMBO/cardano-node/master" # change `master` to rev you want nix develop --accept-flake-config .#venv
-
prepare testing environment
source ./prepare_test_env.sh babbage # 'conway' is also supported
-
start the cluster instance
./dev_workdir/babbage_fast/start-cluster
-
run some test
pytest -s -k test_minting_one_token cardano_node_tests/tests/tests_plutus # or run some tests and see all the executed `cardano-cli` commands pytest -s --log-level=debug -k test_minting_one_token cardano_node_tests/tests/tests_plutus -
stop the cluster instance
./dev_workdir/babbage_fast/stop-cluster
Tests execution can be configured using env variables.
SCHEDULING_LOG– specifies the path to the file where log messages for tests and cluster instance scheduler are storedPYTEST_ARGS– specifies additional arguments for pytest (default: unset)MARKEXPR– specifies marker expression for pytest (default: unset)TEST_THREADS– specifies the number of pytest workers (default: 20)CLUSTERS_COUNT– number of cluster instances that will be started (default: 9)CLUSTER_ERA– cluster era for Cardano node – used for selecting the correct cluster start script (default: babbage)TX_ERA(deprecated) – era for transactions – can be used for creating Shelley-era (Allegra-era, ...) transactions (default: unset)COMMAND_ERA– era for cardano-cli commands – can be used for creating Shelley-era (Allegra-era, ...) transactions (default: unset)NUM_POOLS– number of stake pools created in each cluster instance (default: 3)ENABLE_P2P– use P2P networking instead of the default legacy networking (default: unset)MIXED_P2P– use mix of P2P and legacy networking; half of stake pools using legacy and the other half P2P (default: unset)DB_BACKEND– 'mem' or 'lmdb', default is 'mem' (or legacy) backend if unset (default: unset)SCRIPTS_DIRNAME– path to a dir with local cluster start/stop scripts and configuration files (default: unset)BOOTSTRAP_DIR– path to a bootstrap dir for the given testnet (genesis files, config files, faucet data) (default: unset)KEEP_CLUSTERS_RUNNING– don't stop cluster instances after testrun is finished (WARNING: this implies interactive behavior when running tests using the./.github/regression.shscript)
When running tests using the ./.github/regression.sh script, you can also use
CI_BYRON_CLUSTER- start local cluster in Byron era, and progress to later eras by HFs (same effect asSCRIPTS_DIRNAME=babbage)NODE_REV- revison ofcardano-node(default: 'master')DBSYNC_REV- revison ofcardano-db-sync(default: unset; db-sync is not used by default)CARDANO_CLI_REV- revison ofcardano-cli(default: unset; cardano-cli bundled in cardano-node repo is used by default)PLUTUS_APPS_REV- revison ofplutus-apps(default: 'main')
For example:
-
running tests on local cluster intances, each with 6 stake pools and mix of P2P and legacy networking
NUM_POOLS=6 MIXED_P2P=1 ./.github/regression.sh
-
running tests on local cluster intances using 15 pytest workers, Babbage cluster era, Alonzo transaction era, cluster scripts that start a cluster directly in Babbage era, and selecting only tests without 'long' marker that also match the given
-kpytest argumentTEST_THREADS=15 CLUSTER_ERA=babbage TX_ERA=alonzo SCRIPTS_DIRNAME=babbage_fast PYTEST_ARGS="-k 'test_stake_pool_low_cost or test_reward_amount'" MARKEXPR="not long" ./.github/regression.sh
-
running tests on Shelley-qa testnet with '8.0.0' release of
cardano-nodeNODE_REV=8.0.0 BOOTSTRAP_DIR=~/tmp/shelley_qa_config/ ./.github/regression.sh
Install and configure nix, follow cardano-node documentation. Install and configure poetry, follow Poetry documentation.
Create a Python virtual environment (requires Python v3.8 or newer) and install this package together with development requirements:
./setup_dev_venv.shWhen running tests, the testing framework starts and stops cluster instances as needed. That is not ideal for test development, as starting a cluster instance can take up to several epochs (to get from Byron to Babbage). To keep the Cardano cluster running in between test runs, one needs to start it in 'development mode':
-
cd to 'cardano-node' repo
cd ../cardano-node -
update and checkout the desired commit/tag
git checkout master git pull origin master git fetch --all --tags git checkout tags/<tag>
-
launch devops shell
nix develop .#devops -
cd back to 'cardano-node-tests' repo
cd ../cardano-node-test -
activate virtual env
poetry shell
-
add virtual env to
PYTHONPATHexport PYTHONPATH="$(echo $VIRTUAL_ENV/lib/python3*/site-packages)":$PYTHONPATH
-
prepare cluster scripts for starting local cluster directly in Babbage era
prepare-cluster-scripts -d <destination dir>/babbage_fast -s cardano_node_tests/cluster_scripts/babbage_fast/
-
set env variables
export CARDANO_NODE_SOCKET_PATH=<your path to cardano-node repo>/state-cluster0/bft1.socket DEV_CLUSTER_RUNNING=1
-
start the cluster instance in development mode
<destination dir>/babbage_fast/start-cluster
After the cluster starts, keys and configuration files are available in the <your path to cardano-node repo>/state-cluster0 directory. The pool-related files and keys are located in the nodes subdirectory, genesis keys in the shelley and byron subdirectories, and payment address with initial funds and related keys in the byron subdirectory. The local faucet address and related key files are stored in the addrs_data subdirectory.
To restart the running cluster (eg, after upgrading cardano-node and cardano-cli binaries), run:
./scripts/restart_dev_cluster.shNOTE
Restaring the running development cluster is useful mainly when using the "babbage" start scripts (not the "babbage_fast" version). It takes ~ 30 minutes for the local cluster instance to get from Byron to Babbage. Starting local cluster using the "babbage_fast" version takes less than 1 minute.
To check that the development environment was correctly setup, run the ./check_dev_env.sh script.
$ ./check_dev_env.sh
'cardano-node' available: ✔
'cardano-cli' available: ✔
'python' available: ✔
'pytest' available: ✔
'nix-shell' available: ✔
'jq' available: ✔
'supervisord' available: ✔
'supervisorctl' available: ✔
'bech32' available: ✔
inside nix shell: ✔
in repo root: ✔
DEV cluster: ✔
python works: ✔
in python venv: ✔
venv in PYTHONPATH: ✔
cardano-node-tests installed: ✔
pytest works: ✔
same version of node and cli: ✔
socket path set: ✔
socket path correct: ✔
socket path exists: ✔
cluster era: babbage
transaction era: babbage
using dbsync (optional): ✔
dbsync available: ✔
P2P network (optional): -
Example:
pytest -k "test_name1 or test_name2" cardano_node_tests
pytest -m "not long" cardano_node_tests
pytest -m smoke cardano_node_tests/tests/test_governance.pyIt is sufficient to activate the Python virtual environment before running linters, development cluster is not needed:
-
activate virtual env
poetry shell
-
run linters
make lint
Sometimes it is useful to test local changes made to cardano-clusterlib. To install cardano-clusterlib in development mode:
-
activate virtual env
poetry shell
-
enable legacy behavior (needed by
mypyandpylintlinters)export SETUPTOOLS_ENABLE_FEATURES="legacy-editable"
-
update virtual env (answer 'y' to question "Install into the current virtual env? [y/N]")
./setup_dev_venv.sh
-
uninstall
cardano-clusterlibinstalled by poetrypip uninstall cardano-clusterlib
-
cd to 'cardano-clusterlib-py' repo
cd ../cardano-clusterlib-py -
install
cardano-clusterlibin development modepip install -e . -
cd back to 'cardano-node-tests' repo
cd - -
check that you are really using cardano-clusterlib files from your local repo
python -c 'from cardano_clusterlib import clusterlib_klass; print(clusterlib_klass.__file__)'
Note that after you run poetry install (eg through running ./setup_dev_venv.sh), poetry will reinstall cardano-clusterlib. If you want to keep using cardano-clusterlib in development mode, you'll need to repeat the steps above.
Edit pyproject.toml and run
./poetry_update_deps.shBuild and deploy documentation:
./deploy_doc.shInstall this package and its dependencies as described above.
Run pre-commit install to set up the Git hook scripts that will check your changes before every commit. Alternatively, run make lint manually before pushing your changes.
Follow the Google Python Style Guide, with the exception that formatting is handled automatically by Black (through the pre-commit command).
See the CONTRIBUTING document for more details.