
- Arduino Mega
- ESP 32 camera and Wi-Fi module
- Ultrasonic distance sensor
- Wheels IR speed sensor - calculating exact distance
- 2 servos robotic arm - camera rotation

You can find the code of the Arduino car here
Machine learning logics are written on Python using Tensorflow and Keras libraries for models operation and OpenCv for Computer Vision image preprocessing and objects detection.
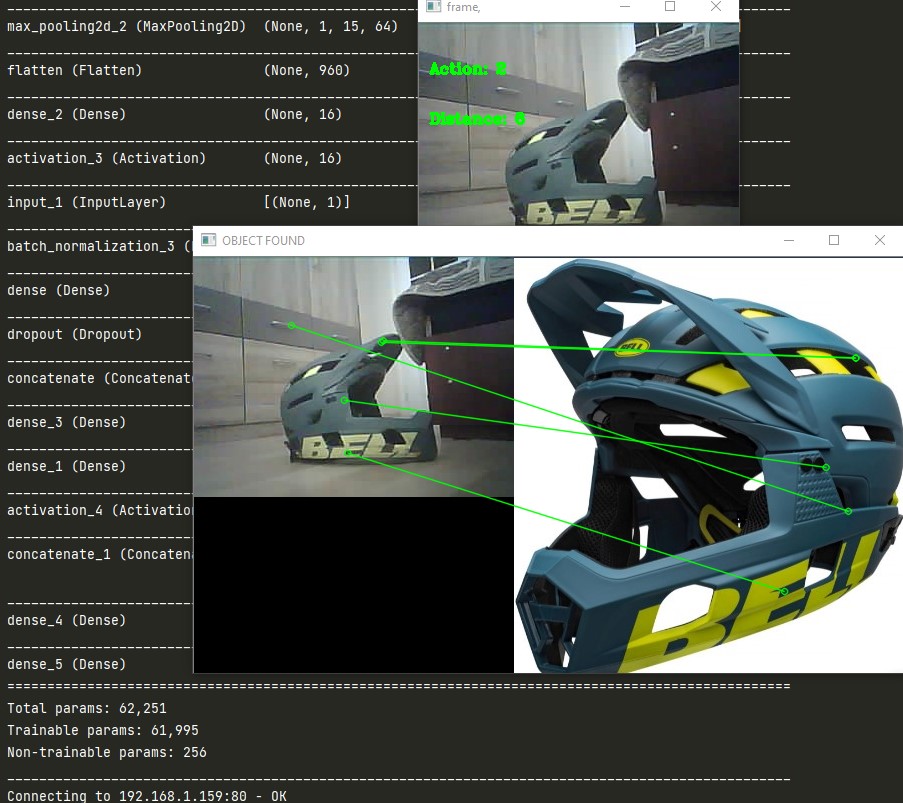
I process the input image from the car into Canny-edges, Black-and-white, resized and depth images. I also find contours and search for objects in a frame. These data are fed into the neural network for more approximate calculation of the decision.

Type of the model is defined by rewards the model was given to specify purpose of actions
This type is focused on exploring as bigger territory as possible. Positive reward was given for image frames difference and new objects detected. And negative for getting too close to some obstacle.
The model was trained in a same way as the explorer with an addittion of searching for a specific object in frames. Searching is made by looking for similar hotpoints with ones in a folder with example images of the wanted objects.
This type is different in it's base, because the action decision, doesn't come from the neural network, but from an algorithm, that detects the object(face) and moves to the direction of the object. I've made it in different variations:
- Looking for a face in the frame from car and moving to the direction of the face movement
- Choosing a specific object and moving to the direction of the object movement
- The following was made with webcam movement only or with the movement of the whole car, using wheels motors rotation

This agent is created of two similar DQN models: target and q model
It took around 20 hours to train the model on 10 000 steps dataset (10 000 frames, distances, random action and other infromation calculated from these three) locally on my computer Trained model weights are saved here in .h5 format
This agent is made of only one similar Q model as in the previous agent with diferent training method using only one network.
Training was performed on all of these combinations of different parameters, such as: input data dimension, filters, droputs and activation functions
Here you can see the average reward each of the combinations achieved:

Paramters combinations:

Trained model weights are saved here in .h5 format
- Resized video frame in all RGB colors
- BlackAndWhite thresholded image
- Canny edges frame
- Distance
- Q value for each of the actions (Left, Right, Forward)
