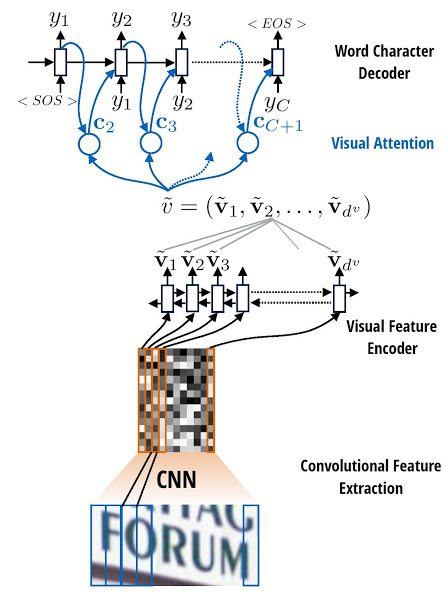
This repository implements the the encoder and decoder model with attention model for OCR in pytorch, and its arithmetic is based on the paper <Attention-based Extraction of Structured Information from Street View Imagery>.
⛳️ Network Framework:
- Pytorch 1.0+ ✔️
- python opencv 4.0.0+ ✔️
- scikit-image 0.15.0 ✔️
We need a file (specified by parameter TRAIN_DIR, TEST_DIR) containing the path of images and the corresponding characters.
- Download the data or you can use the Small_Synthetic_Chinese_String_Dataset, every image fixed 10 characters. 344000 training image, and about 20000 testing image, please download it via BaiDu
- The train.txt and test.txt are created as the follow form:
# path to image and label
./images/33069953_4129036931.jpg 到此刻,不要煮的时间
Trian the model with the bleow command:
python train.py --TRAIN_DIR ./data/train.txt --TEST_DIR ./data/test.txt --batch_size 64 --input_h 32 --input_w 100 --lr 0.001 --use_gpu TrueAfter a while, you will see something like the following output in out.txt:
...
2019-05-25 17:09:59,176: Epoch: 22 Batch: 4000 loss=0.016591 seq_acc=0.956629 char_acc=0.995143
2019-05-25 17:10:10,447: Epoch: 22 Batch: 4100 loss=0.016654 seq_acc=0.956391 char_acc=0.995114
2019-05-25 17:10:21,555: Epoch: 22 Batch: 4200 loss=0.016669 seq_acc=0.956269 char_acc=0.995099
2019-05-25 17:10:32,426: Epoch: 22 Batch: 4300 loss=0.016837 seq_acc=0.955952 char_acc=0.995051
2019-05-25 17:10:43,875: Epoch: 22 Batch: 4400 loss=0.016873 seq_acc=0.955824 char_acc=0.995038
2019-05-25 17:10:54,621: 尺寸更高清晰度更好材 ===> gt: 尺寸更高清晰度更好材
2019-05-25 17:10:54,622: Epoch: 22 Batch: 4500 loss=0.016806 seq_acc=0.955910 char_acc=0.995049
2019-05-25 17:11:05,843: Epoch: 22 Batch: 4600 loss=0.016755 seq_acc=0.955931 char_acc=0.995053
2019-05-25 17:11:16,932: Epoch: 22 Batch: 4700 loss=0.016758 seq_acc=0.955924 char_acc=0.995050
2019-05-25 17:11:28,228: Epoch: 22 Batch: 4800 loss=0.016769 seq_acc=0.955951 char_acc=0.995055
2019-05-25 17:11:39,340: Epoch: 22 Batch: 4900 loss=0.016807 seq_acc=0.955762 char_acc=0.995034
2019-05-25 17:11:50,375: 会让上司对你的印象大 ===> gt: 会让上司对你的印象大
2019-05-25 17:11:50,375: Epoch: 22 Batch: 5000 loss=0.016792 seq_acc=0.955759 char_acc=0.995036
2019-05-25 17:12:01,674: Epoch: 22 Batch: 5100 loss=0.016750 seq_acc=0.955778 char_acc=0.995041
2019-05-25 17:12:12,553: Epoch: 22 Batch: 5200 loss=0.016693 seq_acc=0.955877 char_acc=0.995052
2019-05-25 17:12:23,674: Epoch: 22 Batch: 5300 loss=0.016615 seq_acc=0.956002 char_acc=0.995070
2019-05-25 17:12:32,679: Epoch: 22 training: loss=0.016603 epoch_seq_acc=0.955927 epoch_char_acc=0.995063
✏️ Note that it takes quite a long time to reach convergence, since we are training the RCNN and attention model simultaneously.
The pretrianed model could download via Baidu, password( ++wxx8++ ), and copy it into ./checkpoints,and run:
python demo.py --img ./images/* --index_to_char ./data/index_to_char.json --checkpoints ./checkpoints/model_best.pt --use_gpu True
Input Images:
![]()
![]()
![]()
![]()
![]()
Output Text
====== Start Ocr ======
Path: image/1.jpg ===>>> 正如只有经过泥泞的道 ===>>> time cost: 0.097589
Path: image/2.jpg ===>>> 成功更容易光顾磨难和 ===>>> time cost: 0.019335
Path: image/3.jpg ===>>> 提供实时翻译复制及分 ===>>> time cost: 0.030660
Path: image/4.jpg ===>>> 小或者是yolo算法 ===>>> time cost: 0.023226
Path: image/5.jpg ===>>> 下一步就是设计算法得 ===>>> time cost: 0.017680
- Training model with the string have different lengths.👊
- Training model with different basebone, such as resnet50.👊