ridge_regression.ipynb: The original jupyter notebook I used to train my model, downloaded from Google Colab;
ridge_regression.py: The transformed .py format of ridge_regression.ipynb;
app folder: contains an implementation of web application using fastapi;
main.py: creates the web app and implementes GET/POST HTTP methods;
model folder: wraps up the trained model;
model.py: retrieves the saved model and sets up I/O;
trained linear model.pkl: The trained model I saved from ridge_regression.py;
neural network.ipynb: My neural network try out which didn't work out well.
Github Repository: https://github.com/JingyangYU63/ml-web-app
Dockerhub Repository: https://hub.docker.com/repository/docker/jy732/ml-web-app/general
Heroku App Link: https://ml-web-app.herokuapp.com/
I proposed the method of predicting a future day's receipts number based on the past few (30 in my code) days. For the samll volume of data, I choose a linear model - Ridge Regression over deep learning/ neural networks like LSTM (a simple model usually exhibits better performance over deep neural networks when data volume is relatively small). Before building up my model, I choose to read and pre-process the data, including adding a data normalization step to maintain the data value within a common scale (10^6-10^7 is too large). As the optimization method, SGD + momentum helps accelerate gradients vectors in the right directions, thus leading to faster converging (this is crucial when tuning the hyperparameters which requires high amount of computation). Beside that, I also observed that a good memory locality (where the variable’s memory accesses are more predictable, i.e. avoids memory allocation in the running of program by pre-allocating memories ahead) could improve performance of SGD. In this project, Bayesian Optimization is adapted for hyperparameter tuning for its efficiency over grid search/ random search (instead of painstakingly trying every hyperparameter set or testing hyperparameter sets at random, the Bayesian optimization method can converge to the optimal hyperparameters. Thus, the best hyperparameters can be obtained without exploring the entire sample space).
Additionally, I also used hand-written backprop system for tensors to optimize a simple one-hidden-layer neural network. Similarly, I adapted SGD + momentum as my optimizer and Bayesian Optimization for hyperparameter tuning. However, the prediction result come out bad like I expected. It was quite well when predicting the first few days of 2022, before the predicted figures converge to some constant number when day number increased (the differennce between predctions for Dec 30 and Dec 31 is less than 10). Though I didn't use the prediction made by the neural network when building the web application, I still include the jupyter notebook in the git repository incase you're interested.
Run commands below in command line to lauch the app (make sure you're under the directory of ml-web-app):
docker build -t app-name .
docker run -p 80:80 app-nameThen open your web browser at your local host port http://0.0.0.0:80/docs. Press the "Try it out" icon under the POST tab and replace the "string" with the month of 2022 you're looking for.
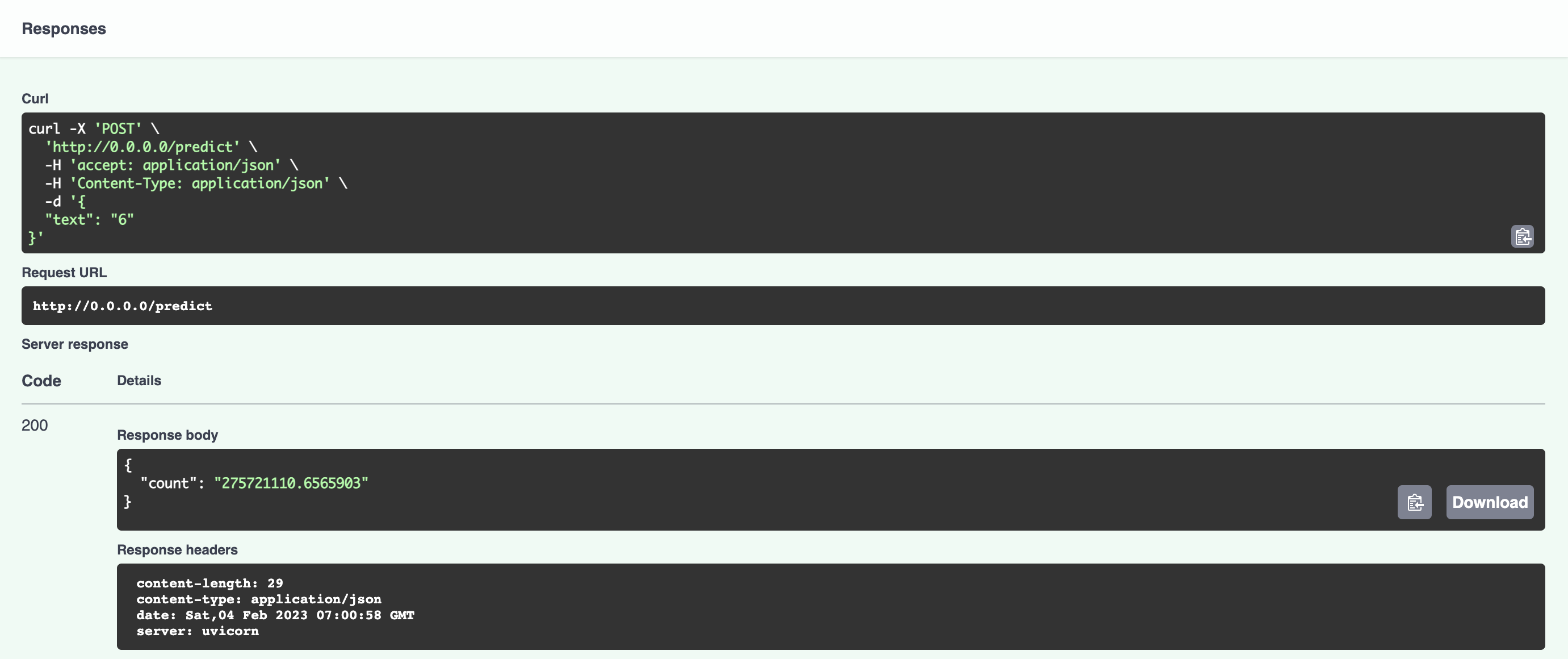
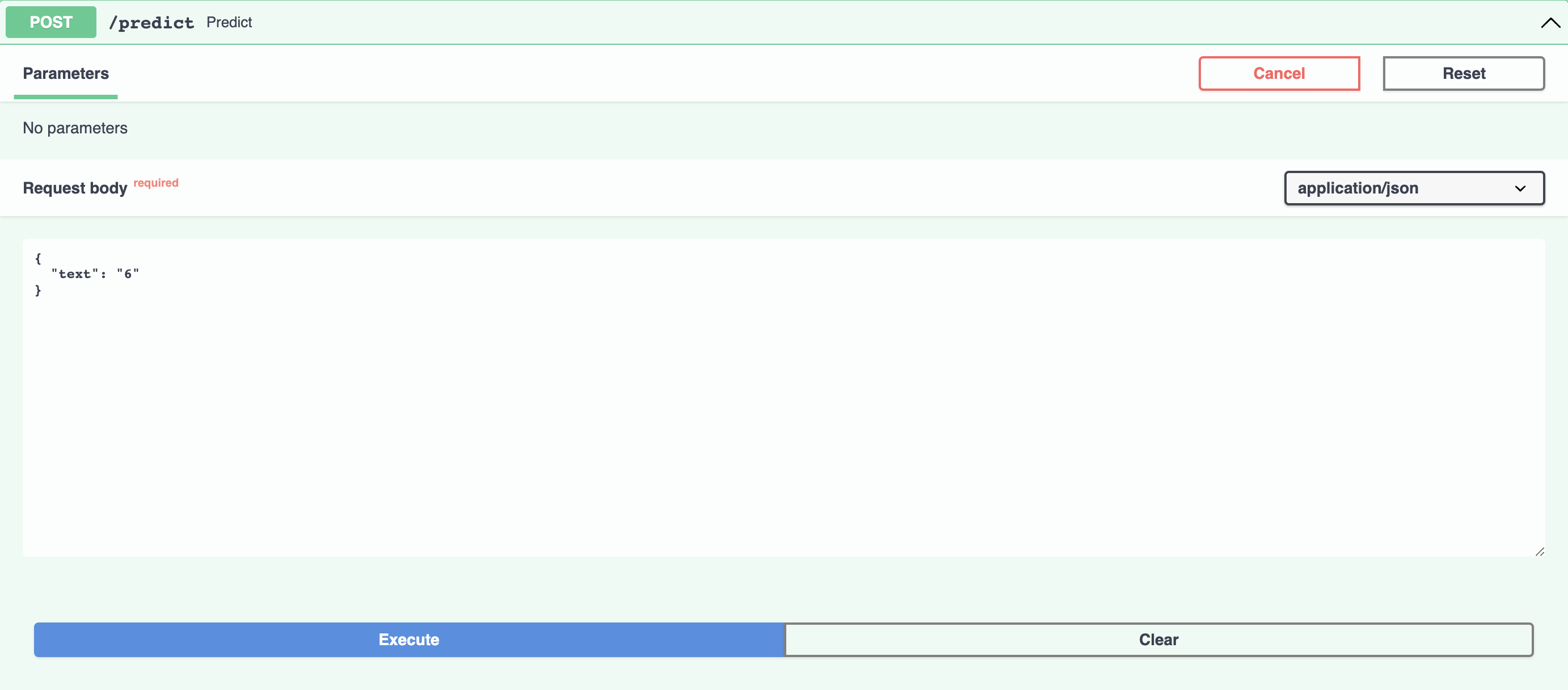 By hitting the execute icon you'll get the estimated number of the scanned receipts for the month you specified (for here entries of 6, Jun and June are equivalent) at the
response body (getting the number of the scanned receipts for June 2022 in the below example).
By hitting the execute icon you'll get the estimated number of the scanned receipts for the month you specified (for here entries of 6, Jun and June are equivalent) at the
response body (getting the number of the scanned receipts for June 2022 in the below example).
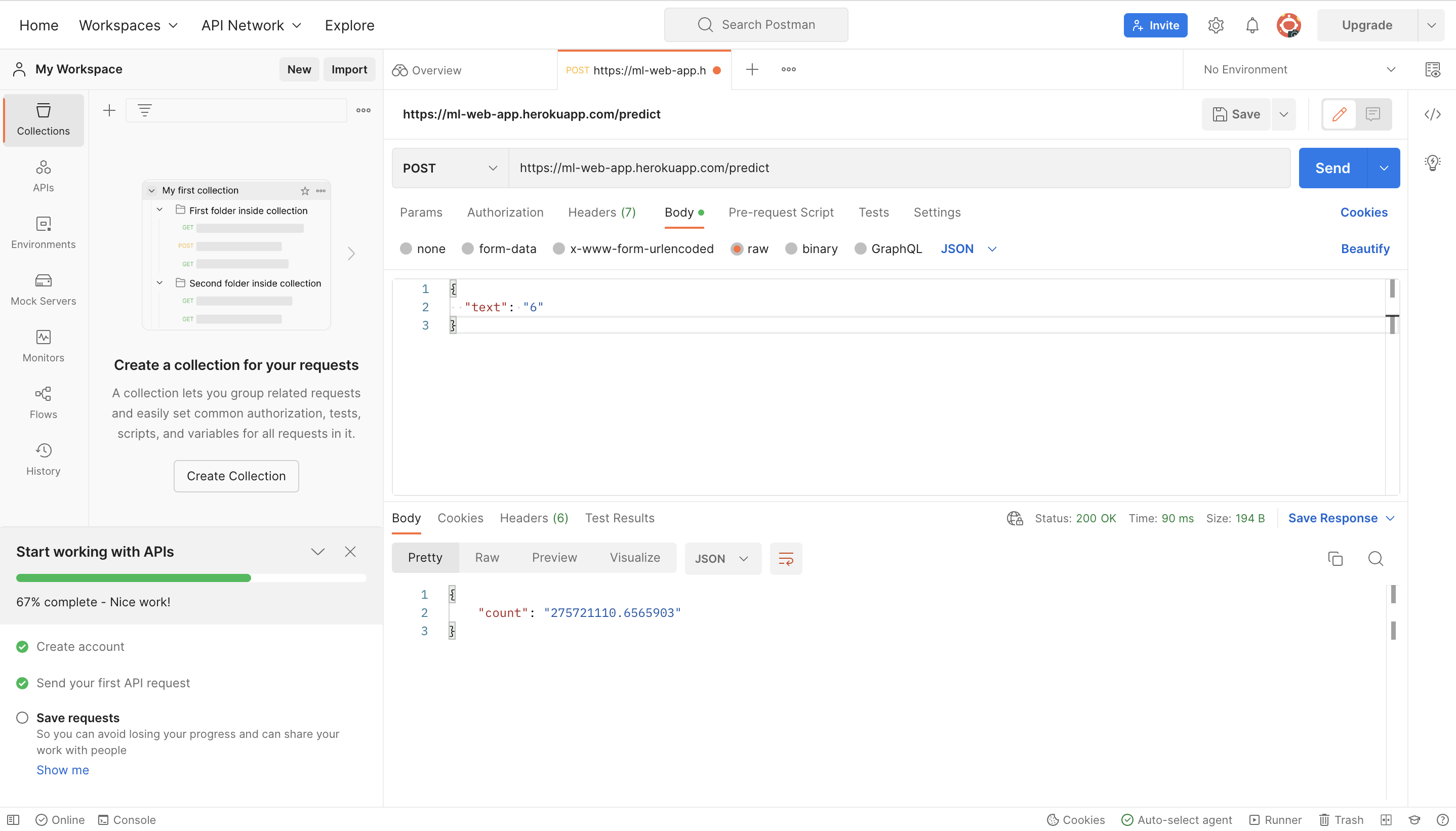
First you need to signup with Postman (https://www.postman.com/), then create a new request. Open up your work space, create a new request and select the POST request to paste the link (https://ml-web-app.herokuapp.com/predict) to the input rectangle. Then select "Body" tab below and enter the request body in JSON format. Finally, you will get the result by hitting "Send" icon (getting the number of the scanned receipts for June 2022 in the below example).