Feature request: Add ability to skip steps in backtesting #631
Comments
|
Hello Kishan, All the strategies available for backtesting are the ones shown in the gifs in the User Guide that you may already be familiar with. https://skforecast.org/latest/user_guides/backtesting We have never thought of your alternative. We have indeed a lot of options to configure the refit of the model, but none to avoid predicting folds. For example, if I understand you correctly, the forecast horizon in your backtesting is 12 weeks. You suggest that users can choose to skip validation for some weeks. Is this correct? Thanks for opening the issue! Javi |
|
Hi @JavierEscobarOrtiz! Thanks for your reply!
Let me give an example to clarify. Imagine you have the following time series: [1,2,3,4,5,6,7,8,9,10]. I want the initial training size to be 4, the forecast horizon is 2, and I want the forecast origin to move forward by 2 steps during backtesting. So the folds I would have are: Train: [1,2,3,4], Test: [5, 6] This reduces the number of folds computed (thereby saving time) compared to moving the forecast origin forward by 1 each step. Does this make sense? Thanks again! |
|
Hi @KishManani, Thanks for the clarification, do you mean this strategy? I think I am missing something in your example. As I see it, you are predicting 2 steps per fold. Fold 1: Train [1, 2, 3, 4], steps = 2 [5, 6] Of course, as you increase the number of steps predicted in each iteration, the number of folds computed will decrease. Perhaps you are referring to this other strategy that reduces the number of backtesting fits: (it is not shown, but it can also keeps the fixed size of the training set by shifting its origin) Best, Javi |
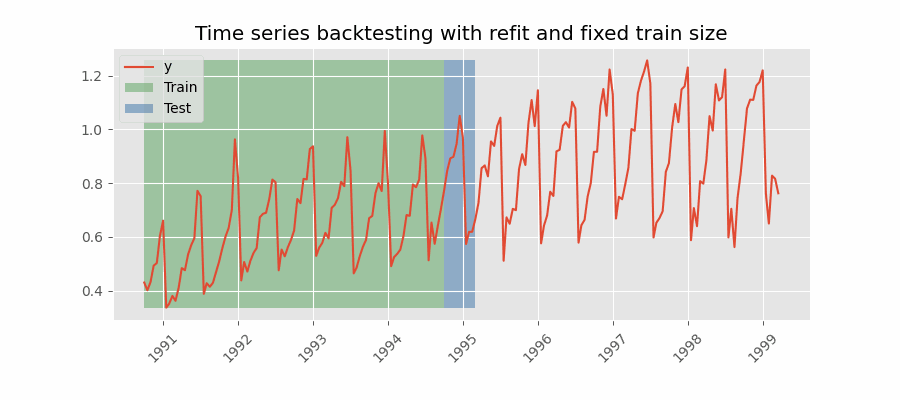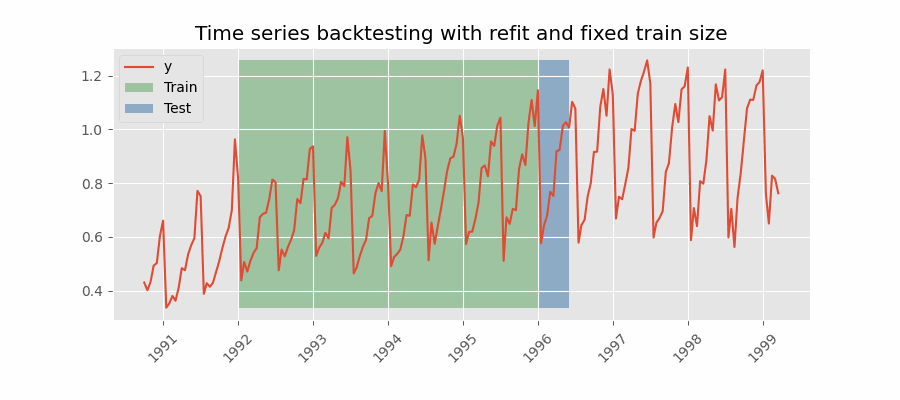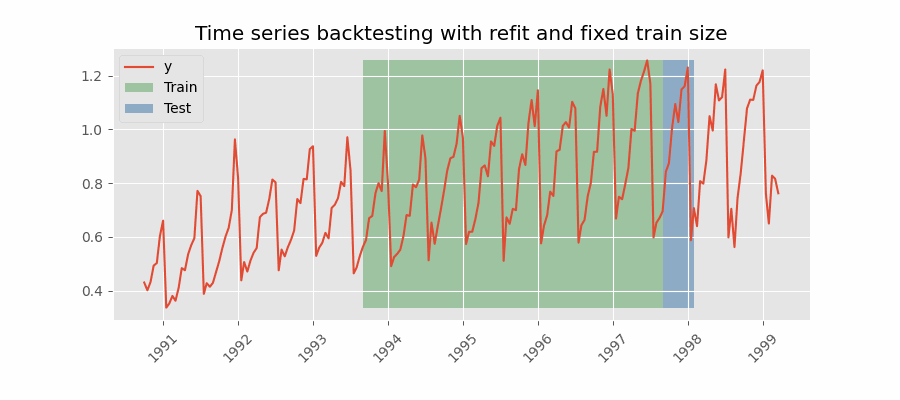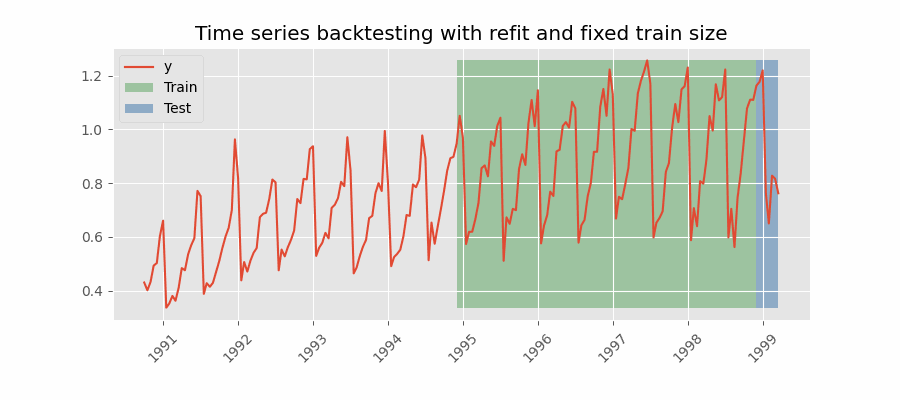
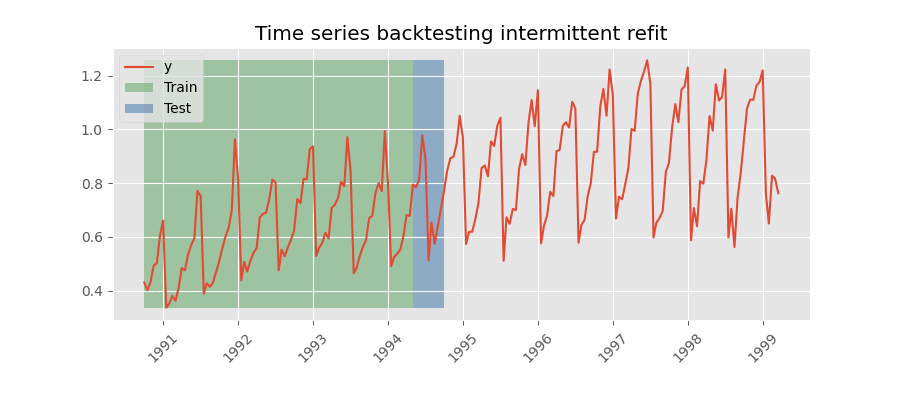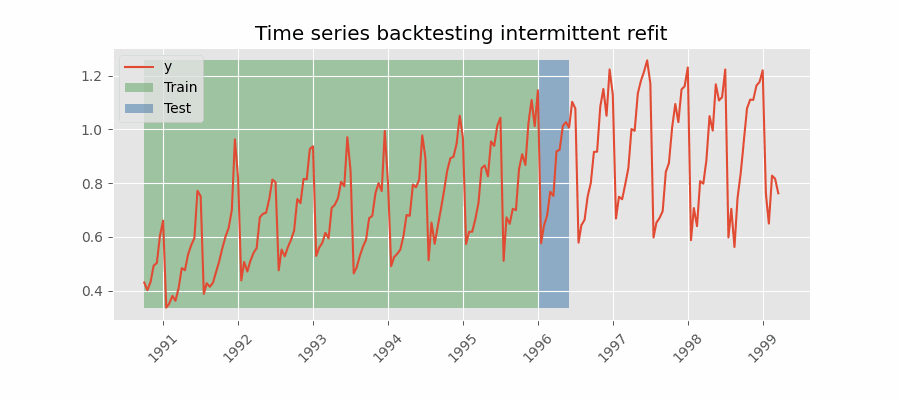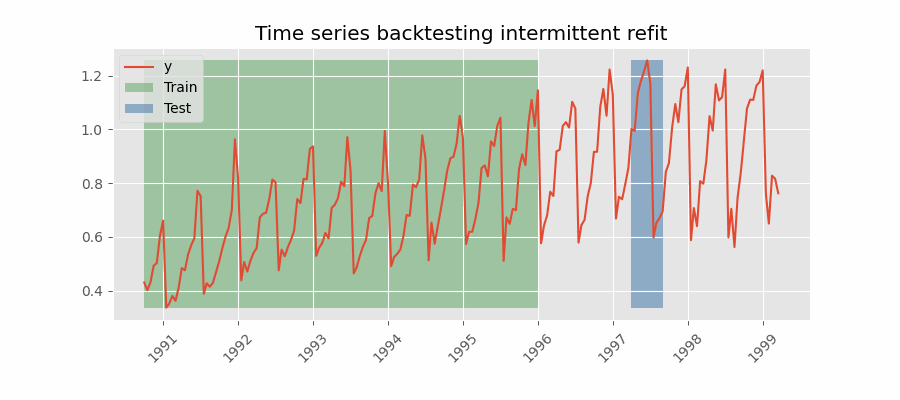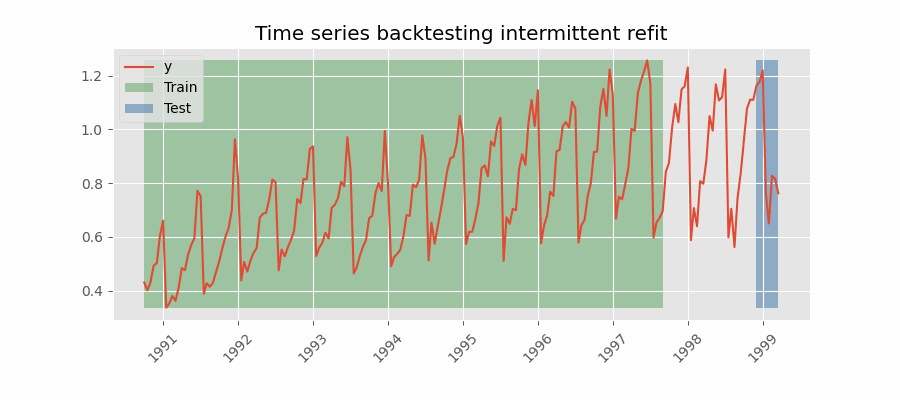
|
Thanks for the reply! I think there is a misunderstanding of the example I gave.
There are two different variables in my example which take the value 2 here. The forecast horizon is 2, we are predicting two steps into the future. The number of steps we move the forecast origin after each fold is also 2. These are two separate things. The first gif you provided appears to be moving forward by one step after each forecast. Is this correct? If so, I want to be able to specify for it to move forward by N steps to reduce the number of forecasts I make during backtesting. N = 1 gives: N = 2 would give: N = 3 would give: Does this clarify? Thanks again for help! |
|
Hi there, This will reduce the time of the backtesting process and therefore may be useful to speed up the hyperparameters search process, with the disadvantage of having a less exhaustive metric. @KishManani Do you know of another advantage? @JavierEscobarOrtiz This could be easily implemented as it only needs to skip some of the splits returned by |
Yes this is correct!
Not that I know of. Primarily a time saver. There is a short discussion about this in the original Facebook Prophet paper in section 4.3. Best wishes |
My current understanding is that in all the backtesters the forecast origin moves forward by one time step for each fold of backtesting. I think it would be helpful if users could set the forecast origin to move forward by N steps rather than just one step for each fold. This can help reduce the time for backtesting.
Apologies if this feature is already available, but from reading the docs I'm unsure whether it is.
Thank you!
Kishan
The text was updated successfully, but these errors were encountered: