SJSU CMPE 295 Master Project
Team Members:
- Jia Ma
- Kevin Lai
- Ying Laura Liu
- Junteng Tan
- K-nearest neighbors (KNN) is a machine learning algorithm that is able to perform classification of an object based on the distance between the object and its nearest neighbors.
- In order to achieve our project's goal, we needed to construct a timeline consisting of news articles that would form the context of our knowledge graph. However, because we have a variety of news articles that focus on different aspects of a subject, we needed to figure out a method to group closely related news articles together.
- For example, during the coronavirus (COVID-19) pandemic, many news articles spoke about the different aspects of the pandemic such as the following:
- Infection Rate and Death Rate
- Virulence of the Disease
- Availability or Shortage of Medical Supplies and Equipment
- Promising or Potential Treatments and Cures
- Governments' Responses to the Virus around the World
- Lockdown Rules and Impacts
- Etc.
- We can see that even when the subject (COVID-19) is the same across multiple news articles, the underlying topics in regards to that subject may actually be different and focus on different aspects of that subject.
- For example, during the coronavirus (COVID-19) pandemic, many news articles spoke about the different aspects of the pandemic such as the following:
- So, because the focus was on classifying objects by finding other "closely related" objects, we chose KNN because it can classify an object based on its "closely related" nearest neighbors.
- Get the news article data
- We would either fetch recently published news articles from the Internet or use existing news articles from our database as the sample for the KNN training and testing.
- Perform Data Cleaning and Preparations
- We performed data cleaning and data preparations to convert the contents of the news documents into tokens that form the bag of words that would later be used for topic modeling.
- Perform LDA Topic Modeling on the Cleaned data
- We performed LDA topic modeling on the resulting bag of words to establish a set of topics that we will classify brand new articles into.
- Perform KNN Classification on a New Sample of News Articles
- We partitioned our dataset of recently published news articles into an 80/20 split for training and testing.
- Then, we ran the KNN algorithm on the partitioned dataset to test the KNN's accuracy in classifying news articles.
- Check KNN's Prediction Results
- We achieved around 60% accuracy with our KNN model when trying to predict the topic of a news article.
- The python notebook was executed and ran on Google Colab.
- You do not need to install anything locally when running the code on Google Colab.
- The code already contains the necessary commands to install the required libraries.
https://colab.research.google.com/drive/1KKGNYr6HtdLNMkcIAr3-pGPTw26U1-ok
The python notebook was executed and ran on Google Colab.
Colab Notebook URL: https://colab.research.google.com/drive/1DWw-RBn-Qlgi969fh_Mer2l4NFPpgooi?authuser=1#scrollTo=UzffsZxNkzJ9
- Feature 1. Sentiment Analysis - 0.84
- Feature 2. LDA Topic Modelling - 0.56
- Feature 3. Sensationalism - 0.95
- Feature 4. Political Affiliation - 0.35
- Feature 5. Clickbait - 0.1
- Feature 6. Spam - 0.54
- Feature 7. Author Credibility - 0.98
- Feature 8. Source Reputation - 0.71
- Feature 9. Content Length - 0.6
- Feature 10. Word Frequency - 1
- Feature 11. Bias - 0.05
We use these 11 features to detect the fakeness of the articles as showing above.
For each features, we use the normalized accuracy as weight. We use the youden's index equation which is shown below to calculate the weight for each feature.
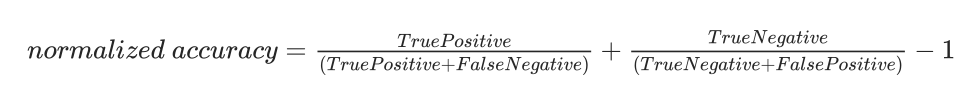
This is a graph embedding neural network to predic a future topic.
1.install required packages
pip install tweet-preprocessor
pip install google-api-python-client
pip install -q stellargraph[demos]==1.0.0rc1
2.Runtime Environment: Colab GPU enabled
3.Training Plot

This is a graph embedding neural network to validate the topic predicted from Stella Graph above.
steps to run the neuralcoref auto generated knowledge graph and Object-relationship-subject triplets
(do not use pip install. we want to use the latest Spacy version in the later part of the code. But Neuralcoref 4.0 is not compatible with Spacy's 'pip install' version. We have to build from source for both Spacy and Neuralcoref to execute this code in Jupyter Notebook with Python 3.Colab doesn't work since it keeps crashing with Spay and Neuralcoref together.)
- build Spacy from source https://spacy.io/usage has instruction on how to build spacy from source.
python -m pip install -U pip
git clone https://github.com/explosion/spaCy
cd spaCy
python -m venv .env
source .env/bin/activate
export PYTHONPATH=`pwd`
pip install -r requirements.txt
python setup.py build_ext --inplace
- build neuralcoref from source (do not use pip install)
git clone https://github.com/huggingface/neuralcoref.git
cd neuralcoref
pip install -r requirements.txt
pip install -e .
- in terminal:
python -m spacy download en_core_web_lg
pip install wikipediaapi
-
remove below two lines of code from file. We used these two lines to avoid scraping web time by saving the scraped data to a csv file first. Then you could scrape data yourself! pd.read_csv("test1.csv").head() wiki_data = pd.read_csv("test1.csv")
-
Ampligraph used the generated triplets as training, testing, validation datasets. Here is colab link for the 4 ampligraph models ComplEx DistMult, RESCAL, TransE: https://colab.research.google.com/drive/1wnm8betVQB67S-8K0D8oZo13ShVtjntj#scrollTo=CebLOmJWegRj https://colab.research.google.com/drive/19RaziEiyr8VVXMKg9OpBc2PMagt5J0i0#scrollTo=CebLOmJWegRj https://colab.research.google.com/drive/1ywTXZl2JbvyK91cadxkB5FI0OI33K8ld#scrollTo=G1phXrSeegT6 https://colab.research.google.com/drive/1NV06M6TICUigKbQt9kQ5wsHL6L2oEYHB#scrollTo=CebLOmJWegRj
-
Ampligrah is used to validate Stella Graph predicted topic's probability and likelihood ranking.
- Gather text data from news sources
- Perform Named Entity Recognition (NER) with Spacy on the news text data to get a set of entities
- Filter the set of entities to obtain a smaller subset containing only interesting and relevant entities: (using entity_type such as Companies and part_of_speech such as Nouns, Adjectives, or a combination of both).
- Use LDA to Extract Topics from the entity subset
- Get a list of top related words (based on word frequency) from the topics
- Perform Google search on each Entity
- Go to each search results URLs
- Then, scape text from the URLs
- Repeat starting from step 2 from above 9a. Create a graph based on the results. (This is the topic graph.) (Steps in Forming the Context of the Graph)
- Create/Establish an event timeline with the topic graph using timestamps such as dates/time from the articles. (This timeline will form the context of the graph.)
- Based on the established event timeline (containing past and present events), predict new events that might occur. 11a. To predict the new events, start by performing distillation (with LSTM or Transformer) on the event timeline 11b. Then, create a deep learning model such as a Neural Network model to predict future events
https://colab.research.google.com/drive/1ORptuFuArk0tqwhZgX7vPgGKtOL1SZpD?authuser=1 (Data scraping)
https://colab.research.google.com/drive/1tlbxxwPYTQZza5yoyFauF-9RPoBMbTlj?authuser=1 (Data scraping)
Google Drive for the datasets: https://drive.google.com/drive/folders/1Hemgwf5RGu2akOSmxzSYWgogYFbUUtWK?usp=sharing