In recent years, deep learning approaches have obtained very high performance across many Natural Language Processing tasks like Sentiment Analysis, Named Entity Recognition, Text Classification, Document Classification, Topic Modeling, and Web search. Most of these tasks in NLP are sequence modeling i.e. mapping a fixed-length input with a fixed-length output where the length of the input and output may differ.
The traditional machine learning models and neural networks cannot capture the sequential information present in the text. Therefore, people started using recurrent neural networks (RNN and LSTM) because these architectures can model sequential information present in the text. However, these recurrent neural networks have their own set of problems. One major issue is that RNNs cannot be parallelized because they take one input at a time. In the case of a text sequence, an RNN or LSTM would take one token at a time as input. So, it will pass through the sequence token by token. Hence, training such a model on a big dataset will take a lot of time.
Another problem in Natural Language Processing is the shortage of training data as this field is diverse, and the most taskspecific dataset contains only a few thousand or a few hundred training examples. To address these problems researchers have developed a variety of techniques for training general-purpose language representation models using an enormous amount of unannotated text on the web. This pre-trained model can then be fine-tuned on small data NLP tasks which will result in substantial accuracy improvements compared to training on these datasets from scratch. One such Pretrained model is BERT stands for Bidirectional Encoder Representations from Transformers released in late 2018 by Google. BERT is designed to pre-train deep bidirectional representations from an unlabeled text by jointly conditioning on both left and right context in all layers.So this Project utilizes the pre-trained BERT model by fine-tuning the parameters and train the new model for our performing Named Entity Recognition.
In this project we use BERT with huggingface PyTorch library to quickly and efficiently fine-tune a model to get near state of the art performance in Named Entity Recognition. NER is widely used NLP task tht tries to locate the names and entities contained in a piece of text, commonly things like people organisation, locations etc.
BERT model was introducted by the Google Team in 2018 (https://arxiv.org/abs/1810.04805) in the Paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding . BERT uses Masked Language Model, that randomly masks some of the tokens from the inputs and the objective is to predict the original vocabulary id of the masked word based only on its context. Unlike left-to-right language model pretraining, the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional Transformers.
BERT uses Transformers, an attention mechanism that learns contextual relations between words in a text. In its vanilla form, Transformer(paper by Google) includes two separate mechanism - an encoder that reads the text input and a decoder that produces a prediction for the task.
A High-Level look of encoder-decoder(courtesy https://jalammar.github.io/illustrated-transformer/)

If we look the Transformer part, we can see the encoder component and decoder component and the connection between them below

The encoder component can be imagined as a stack of encoders and same goes for the decoder part.

As opposed to the sequence-to-sequence model like LSTM or RNN model which reads the text sequencially, the Transformer encoder reads the entire sequence of words at once. Therefore it is considered bi-directional model. BERT takes the output of the encoder and uses that training layer which perform two innovative training techniques, masking and Next Sentence Prediction.
Dataset used in this model is MIT Movie Corpus. The MIT Movie Corpus is a semantically tagged training and test corpus in BIO format. The eng corpus are simple queries, and the trivia10k13 corpus are more complex queries.
https://groups.csail.mit.edu/sls/downloads/movie/
Both the train and test datasets are single files containing movie-related text where each word has a NER tag specifying it as one of the following entities. The NER tag follows a special format used widely in NER literature called IOB format(Inside,Outside and Beginning Format).
- O:This Tag means the word is not part of the entity
- B:this tag means the word is either a single word entity name or else the first word in a multi-word entity name
- I: this tag means the word is part of a ulti-word entity but is not the first word in the full entity name
- Sentences containing a list of tokenized sentences
- Lable containing a list of corresponding IOB
- Map the words to theirs IDs in the BERT vocabulary and forwords that arent in the BERT vocabulary
- The tokenizer will break these down into subwords
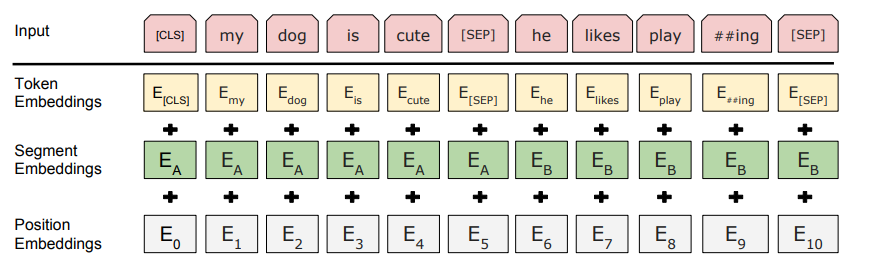
- BERT requires that we prepend the special [CLS] token to the beginning of every sentence
- Append the [SEP] token at the end.
- To support the batch processing of the inputs all the sentences should be padded out(with special [PAD] token) to the same length.
- [0]: input ids
- [1]: attention masks
- [2]: labels

First of all we process our data into desired format for fine tuning. We separate the data into sentencs and label.
The dataset comes already "tokenized" in the sense that it'split into list of words. Here is the steps that are occuring:
We measure the length of all the sentences and look at the distribution of lengths in order to choose a sensible "max_len" value for padding our sentences to.

We Divided our training set to use 90% for training and 10% for validation. For we used TenSorDataset for combining training inputs into tensors. We'll also create an iterator for our dataset using the torch DataLoader class. This helps save on memory during training because, unlike a for loop, with an iterator the entire dataset does not need to be loaded into memory.
We have used BertForTokenClassification which is a normal Bert model with an added single linear layer that is used for classification of each token entity class. As we feed input data, the entire pre-Trained Bert model and the additional untrained classification layer is trained our specific task
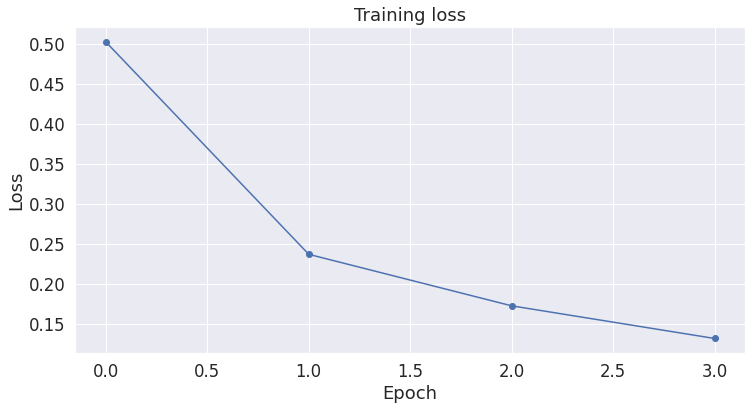
We stored the average loss after each epoch so we can plot them. For each batch of the training data,we progress the update for every 40 batches. We unpack the training batch from the data loader. A batch containes three pytorch tensors:
Now we'll load the holdout dataset and prepare inputs just as we did with the training set. Then we'll evaluate predictions using F-1 score because this is the metrics used for CoNLL2003 and other NER datasets and gives an intuitive understanding of model performance.
After coverting the test datasets into suitable format, we are then using sklearn metrics to calculate F-1 score will comes out to 94.44%
