A Linear A decipherment programme written in Python language, under the guidance of Dr. Francesco Perono Cacciafoco (NTU, Singapore), Dr. Xu Duoduo (NTU, Singapore) together with the assistance of Chua Wen Qing (NTU, Singapore), Hu Man Keat (NTU NRP, Singapore) and Yu Ying Yao (NTU NRP, Singapore).
This program has been funded by the MOE AcRF Tier 1 Research Grant 2017-T1-002-193 Giving Voice to the Minoan People: The Decipherment of Linear A (Principal Investigator: Dr Francesco Perono Cacciafoco, Nanyang Technological University) and has been developed in the context of the same project.
Users can just open the shortcut "LinearADecipherment" application in the directory. The programme would start running. Do note that all files and folder need to be present in the working directory "LinearADecipherment" folder for the programme to run smoothly. The python file was converted to an .exe file via pyinstaller.

Users can just open the shortcut "LinearADecipherment" application in the directory. Similarly, the programme will start running, also note that all files and folder need to be present in the working directory "LinearADecipherment" folder. The python file was converted to an application file via py2app.
This is a link to download the application. https://www.dropbox.com/s/p8p519q8lhjmqgv/LinearADecipherment.zip?dl=0
These are the necessary steps to successfully run the programme.
-
Download the zip file and extract it. Open the "dist" folder and copy and paste the "LinearADecipherment" application into the original directory.
-
Press control + left-click and click "open" on the "LinearADecipherment" application file.
-
Cancel the warning message by MacOS.

-
Press control + left-click and click "open" on the "LinearADecipherment" application file again.

-
Click the "open" button and the programme will run smoothly.
The main python libraries used include
- PyQt5
- pandas
- openpyxl
This is a guide for users of the Linear A decipherment programme
The main window of our programme presents four key analysis functions
- General decipherment
- Specific Decipherment
- Analysis - I This programme aims to to provide automated methods to evaluate languages which greatly resemble Linear A.
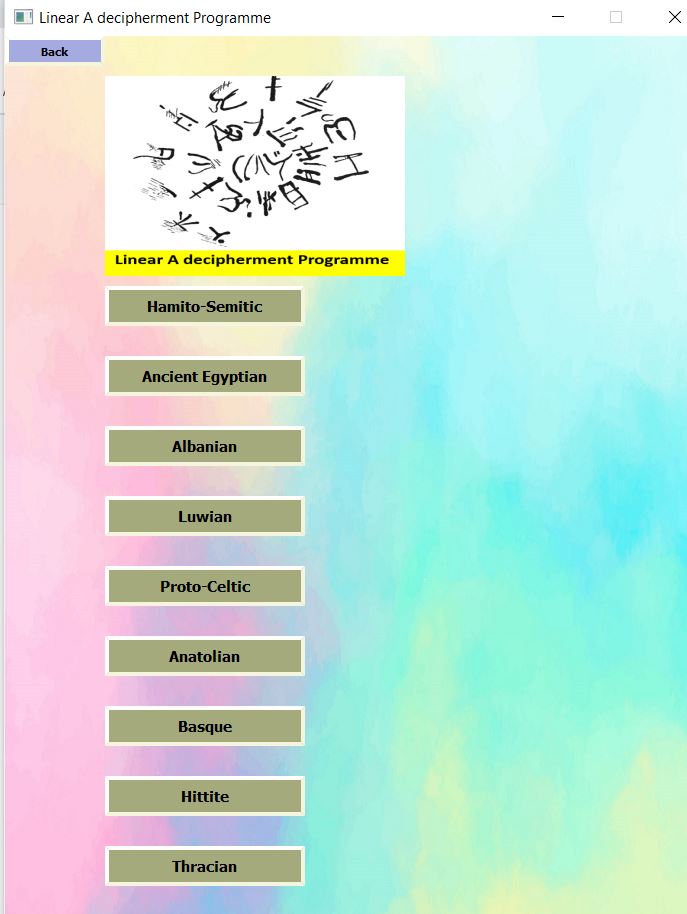
There are 9 built-in dictionaries for comparison with Linear A available in this function. These include Hamito-Semitic, Ancient Egyptian, Albanian, Luwian, Proto-Celtic, Anatolia, Basque (Both Pre-Basque and Proto-Basque), Hittite and Thracian.
The output for each specific decipherment contains two tables. The first of which is a result of a consonantal comparison - vowels in the dictionaries ({'a','e','i','o','u', 'A', 'E', 'I', 'O', 'U'}) were conditionally ignored to produce a one-to-one comparison between consonants. After performing said comparison, positive matches are displayed as shown.
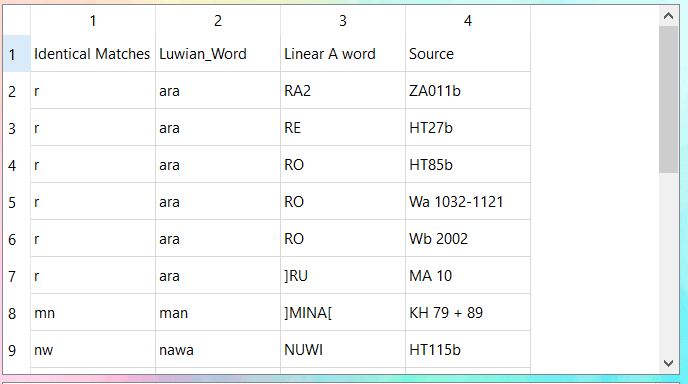
Each entry is displayed in this order: the identical matches from the comparison, the original word in said dictionary, the Linear A word and the source from which the Linear A word was found. The second table is a result of frequency analysis. The matching consonants in each matching triplet were counted, and are represented by letters a-z.
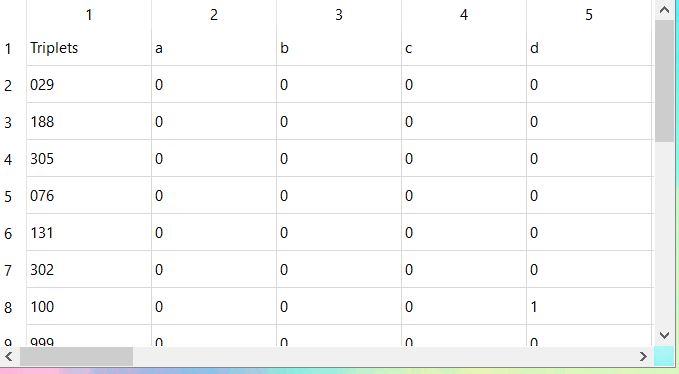
For example, the triplet 100 matched with the letter 'd' once, but matched with none of 'a', 'b', 'c' and 'd'.
Under the percentage analysis function, it provides the statistical analysis of the matches between the Luwian dictionary as well as the transcribed Linear A sources (GORILA volumes 1 - 5 inclusive). The analysis involve the number of unique matches, the total number of matches as well as the percentage of matches.
The General Decipherment function enables dynamic comparisons - users can supply their own Linear A list ("base sheet") and the dictionary list ("comparison sheet").
The base sheet must be in the Microsoft Excel Open XML Spreadsheet (.xlsx or .xls) format.
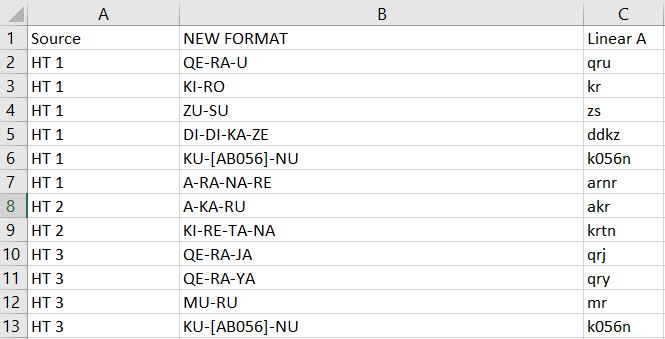
The entries must be listed as shown, in the order of "Source", "NEW FORMAT" and "Linear A". The source column is the corresponding source of the Linear A word and the linear A column shows the representation of the Linear A word in the base sheet.
The comparison sheet must be in the Microsoft Excel Open XML Spreadsheet (.xlsx or .xls) format as well.

The spreadsheet should contain only one column, which is represented as the "List" column as shown. The following entries are the words in the comparison dictionary.
This function also provides the output from a consonantal comparison, similar to that in Specific Decipherment. The results would be saved automatically under a Microsoft Excel Open XML Spreadsheet (.xlsx or .xls) file titled New_matches2 in the same directory.
This function also allows users to include Linear A fonts into their spreadsheet file. The Linear A fonts are from the "LinearADraft1.otf" file present in the directory. This Linear A font was a digital creation by a member in the NTU Singapore Linear A Decipherment research team.
The addition of the Linear A fonts would be automatically saved in your XLSX spreadsheet file in the same directory. Also, the changes would be displayed in the programme as shown, where the Linear A fonts are displayed in the 5th column.
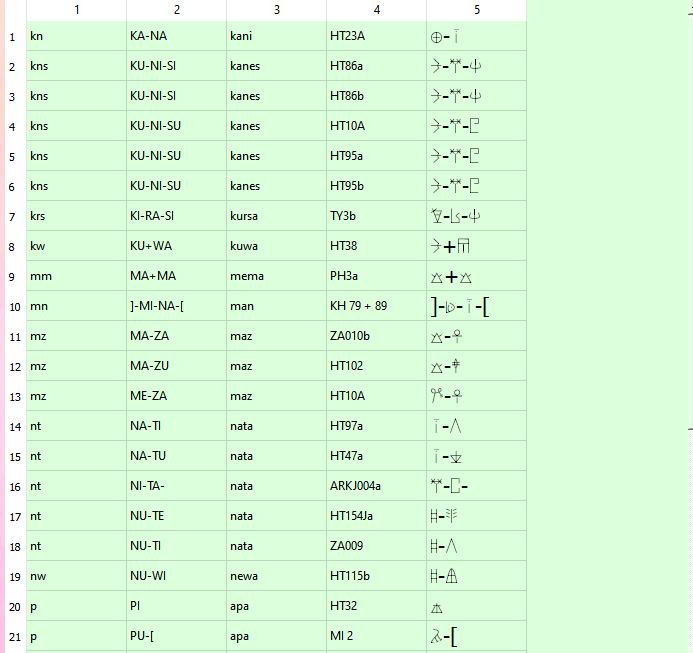
Assuming this is a dynamic comparison between the Linear A base sheet and an unknown comparison sheet, we see that the consonant cluster "kns" has 6 identical matches with the corresponding Linear A words, the original word and its corresponding source. The original word refers to the corresponding word in the comparison sheet.
This function provides a comparison result between the results of the dictionaries used Specific Decipherment. These dictionaries include Hamito-Semitic, Luwian, Anatolia, Basque (Pre-Basque and Proto-Basque), Hittite and Thracian.
The results would be displayed in a table format consisting of four columns titled "Identical Matches", "Dictionary Word", "Frequency", "Percentage".
Under "Identical matches", it would reflect the a matched cluster common among the dictionaries listed above.
Under "Dictionary Word", it would show the original words from the dictionaries that provides the matched cluster after the provisional removal of the vowels. This result would be displayed in a list format in this order,
[Anatolia, Hittite, Luwian, Thracian, Pre-Basque, Proto-Basque, Hamito-Semitic]
Under "Linear A word", it would reflect which Linear A word provides the matched cluster after the provisional removal of the vowels.
Under "Frequency", it would show the number of occurrences of each matched cluster present in each dictionary.
Under "Percentage", it would output the relative percentage of occurrence of each matched cluster among the other dictionaries.
Albanian - Vladimir E. Orel (2000), A Concise Historical Grammar of the Albanian Language: Reconstruction of Proto-Albanian
Anatolian - Ronald Kim, Norbert Oettinger, Elisabeth Rieken, Michael Weiss (2010), Ex Anatolia Lux: Anatolian and Indo-european Studies in Honor of H. Craig Melchert on the Occasion on His Sixty-fifth Birthday
Basque - Trask Larry (2008), Etymological Dictionary of Basque
Ancient Egyptian - E.A. Wallis Budge (1978), An Egyptian Hieroglyphic Dictionary : With an Index of English Words, King List, and Geographical List with Indexes, List of Hieroglyphic Characters, Coptic and Semitic Alphabets (Vol 1) and Paul Dickson (2014), Dictionary of Middle Egyptian.
Hamito-Semitic - Vladimir E. Orel and Olga V. Stolbova (1994), Hamito-Semitic Etymological Dictionary
Hitttie - Jaan Puhvel (1991 - 2017), ittite Etymological Dictionary, Volumes 1-10
Luwian - H. Craig Melchert (2015) , Cuneiform Luvian Lexicon
Proto-Celtic - Ranko Matasovic (2008), Etymological Dictionary of Proto-Celtic: 09
Thracian - Sorin Paliga (2006), Etymological Lexicon of the Indigenous (Thracian) Elements in Romanian.
Shield:
This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
