
목차
1. 프로젝트 소개
2. 프로젝트 기획 - 시연영상
3. 맡은 역할
4. 트러블슈팅
5. 회고
추천시스템 프로젝트 - [웹소설] 일타강사 AI의 기막힌 추천 (웹타추)
Doc2vec 을 이용하여 사용자가 선호하는 소설의 줄거리를 분석하고 그와 유사한 줄거리를 가진 소설을 추천하는 웹사이트 제작
- 자연어 처리와 벡터 임베딩을 통한 줄거리 유사도 비교로 웹소설을 추천
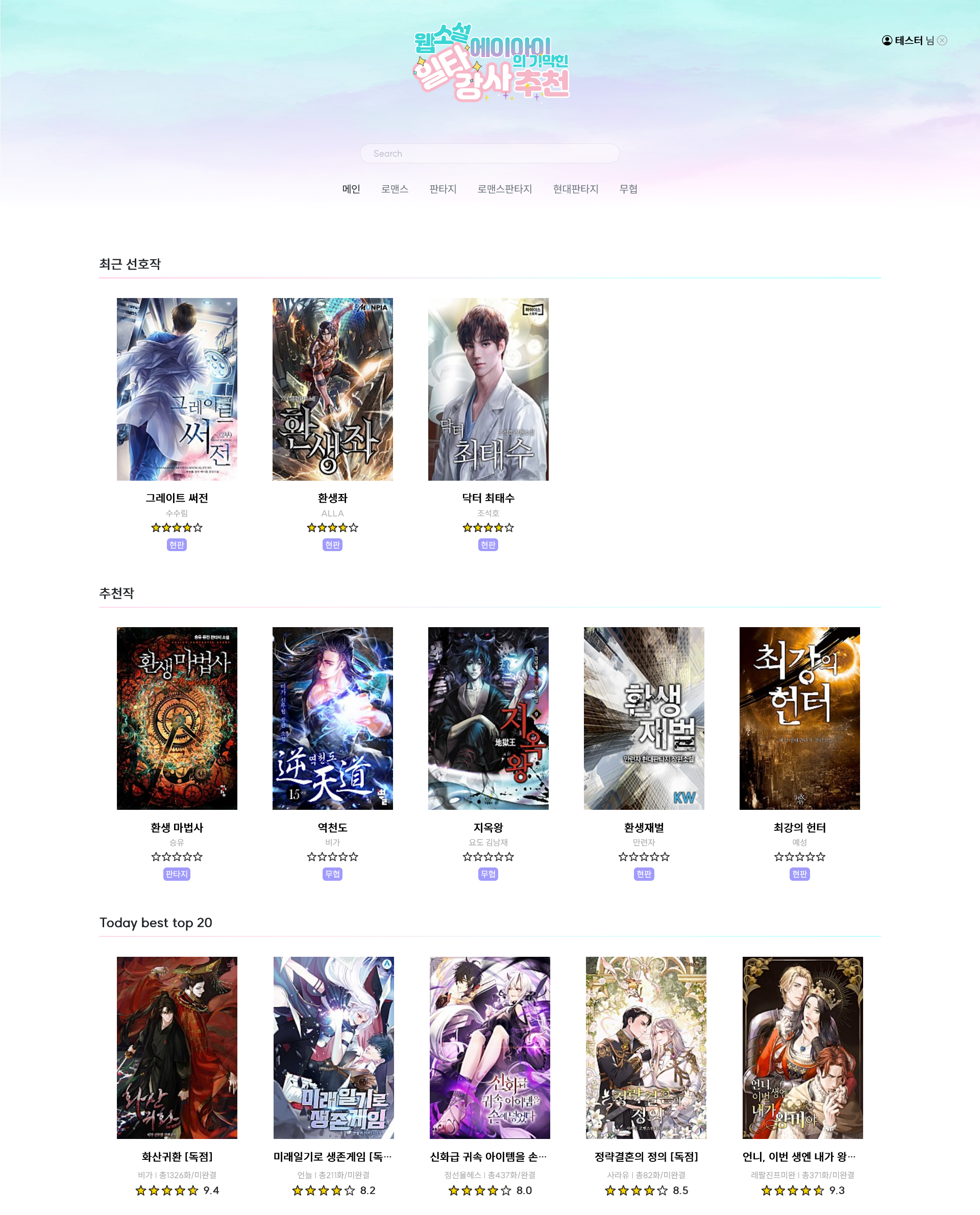
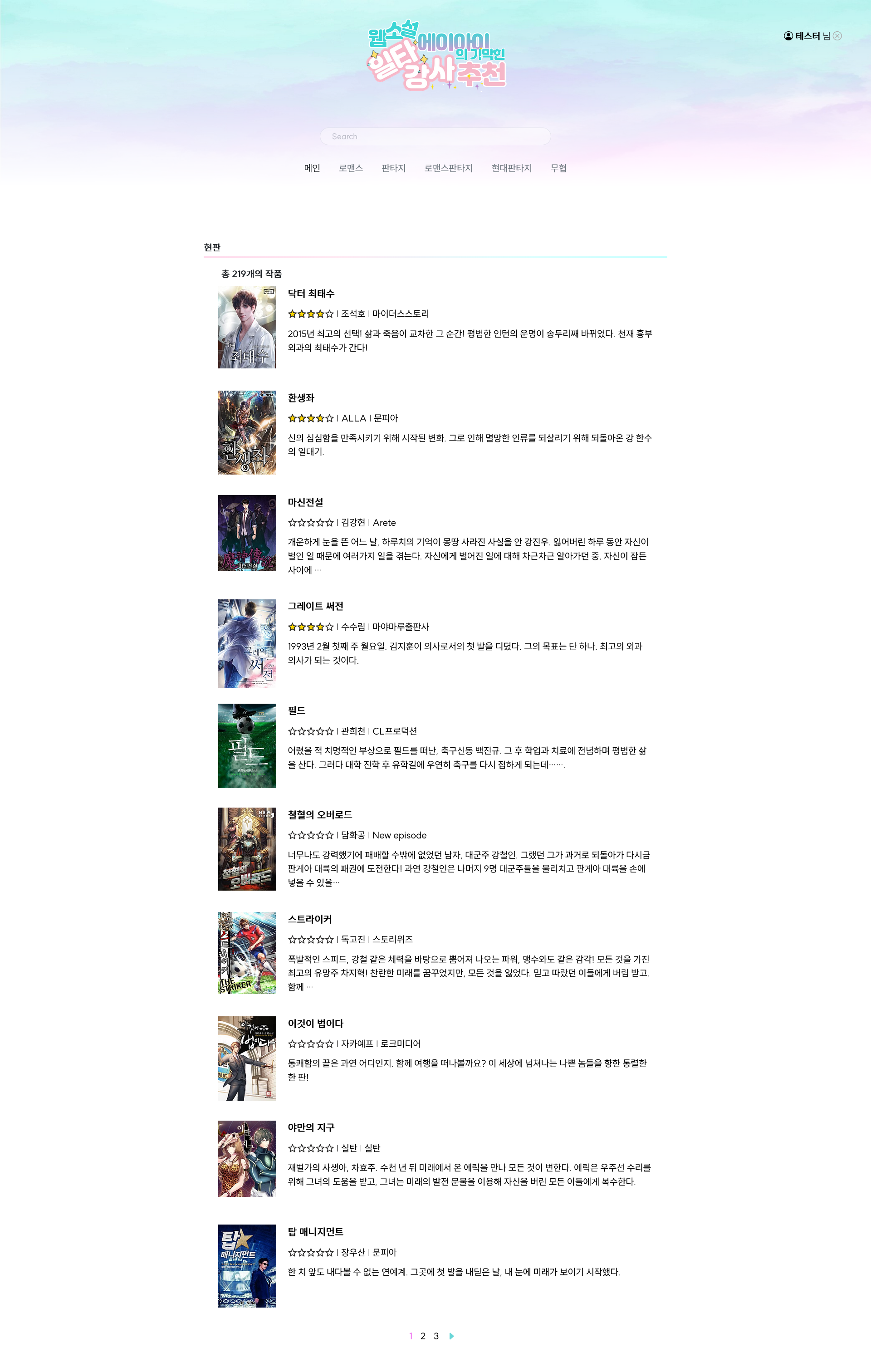
- 메인 페이지에서 네이버 시리즈 소설 일간 순위 크롤링 해서 20위까지 보여줌
- 각 작품에 사용자들이 작성한 리뷰 키워드 표시와 좋아요를 누른 소설의 줄거리 키워드 표시
- S.A : 블로그로 이동(☞゚ヮ゚)☞
- 시연영상 : 시연 영상 확인하기(☞゚ヮ゚)☞
- 원본 팀 깃허브 : https://github.com/cmjcum/webtachu
- 프로젝트 기간 : 2022.06.02 ~ 2022.06.13
웹소설의 줄거리를 자연어 처리와 벡터 임베딩을 이용해 분석하고 추천
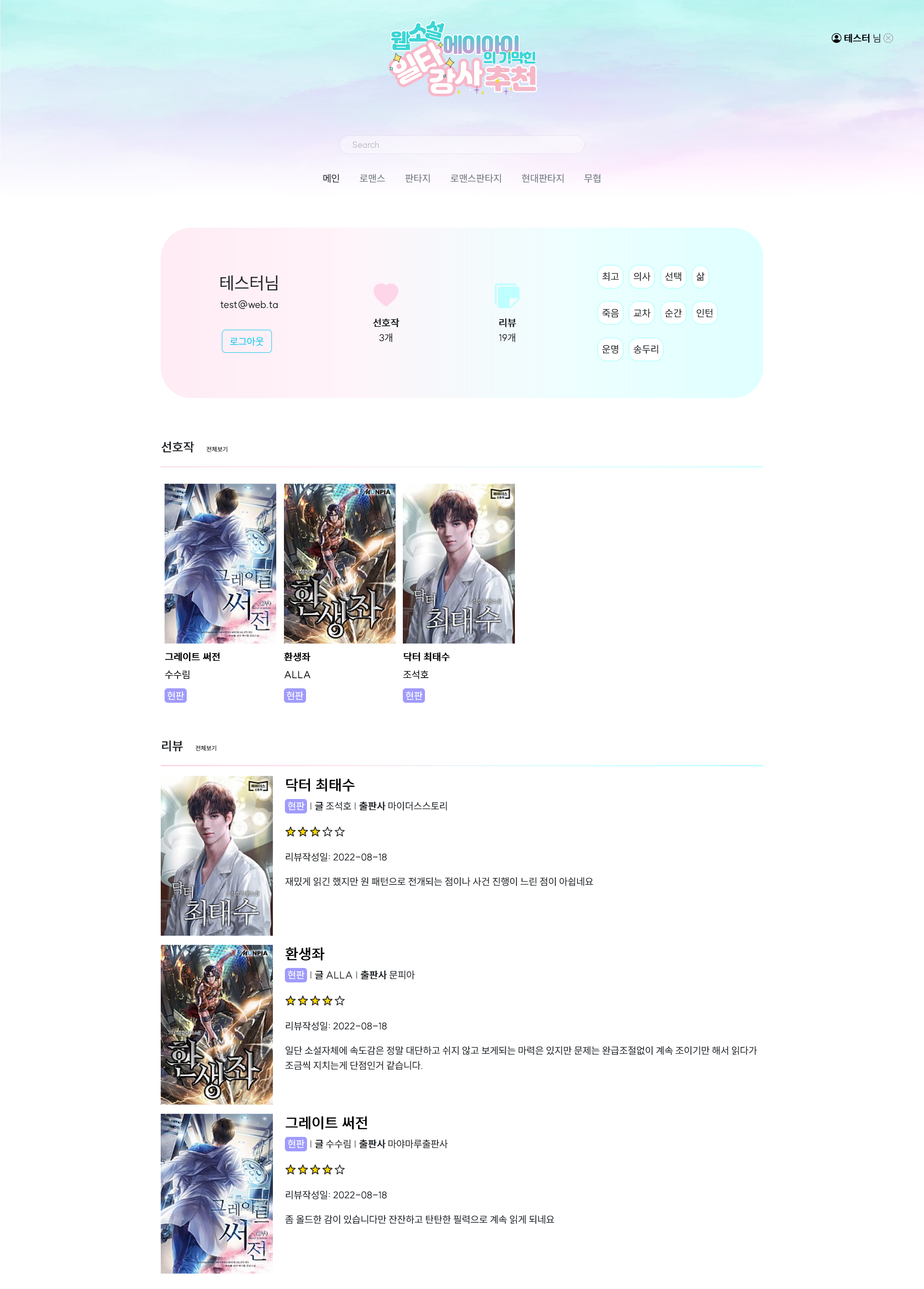
- 선호작을 누른 작품들의 스토리와 유사도가 높은 작품들을 추천, 선호작을 아직 누르지 않았다면 별점이 높은 작품들을 추천
- Today best top 20 - 네이버 시리즈의 일간 Top100에서 20위까지 크롤링해서 보여주기
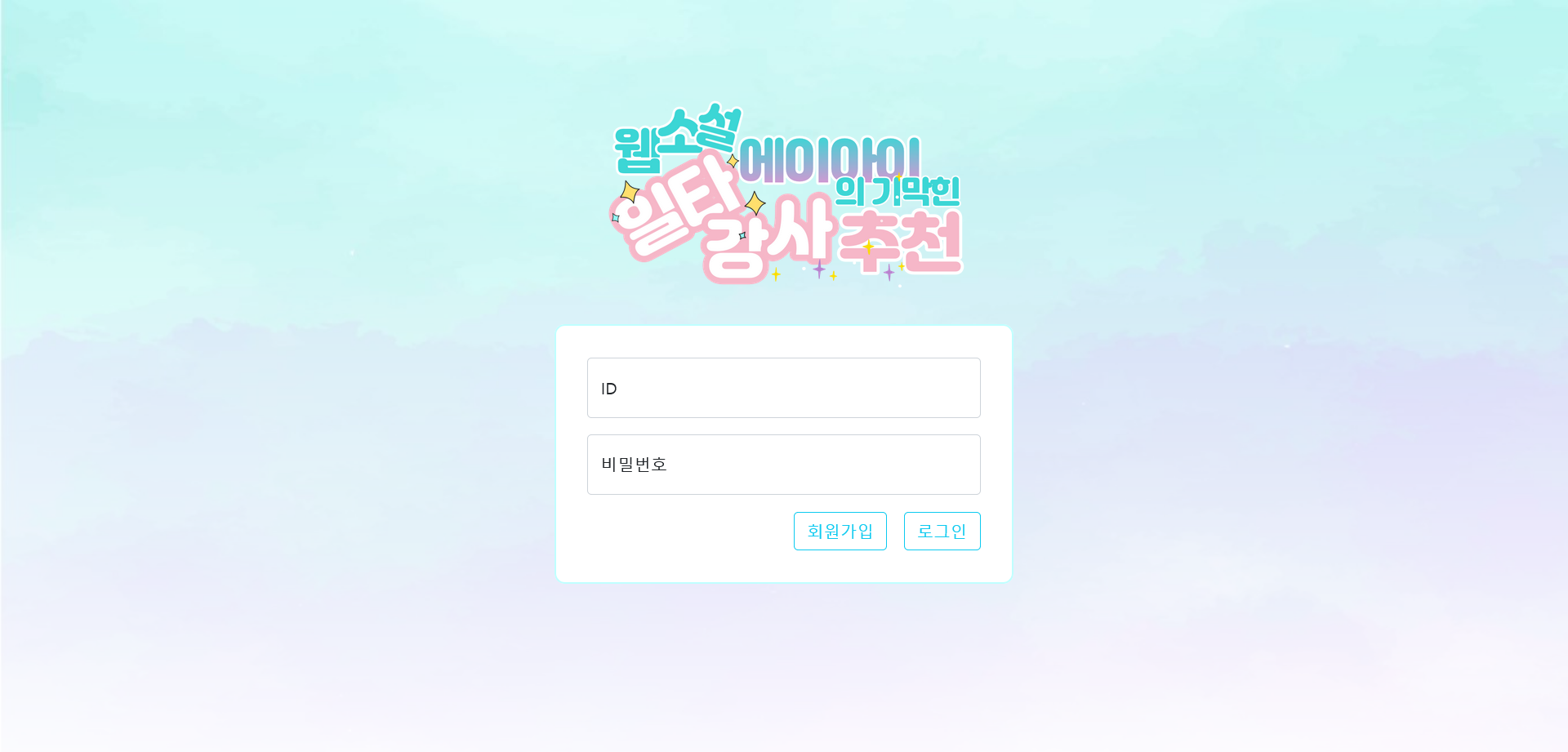
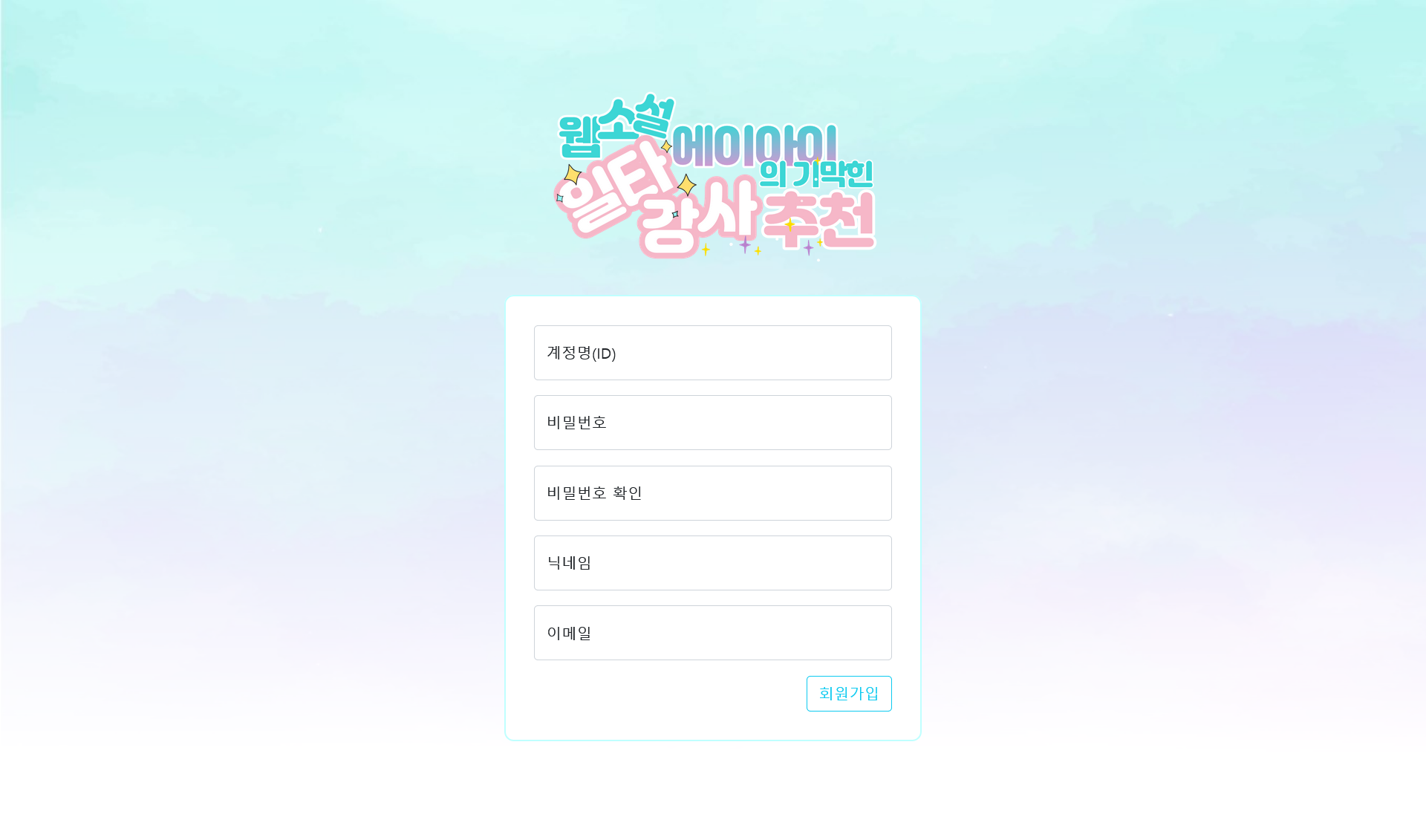
- 회원가입 및 로그인 - 장고 내장 모델 사용
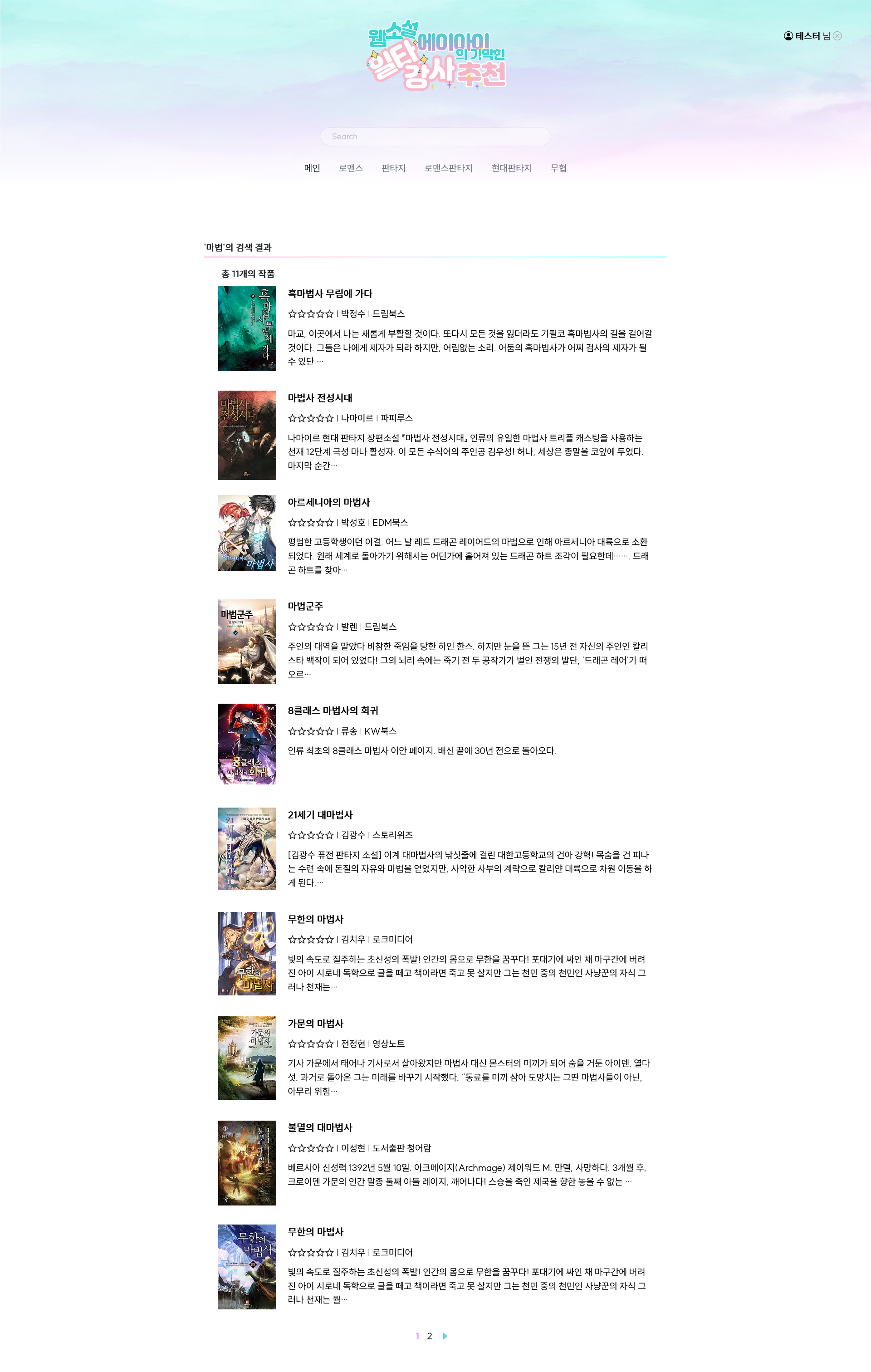
- 장르별 페이지에서 작품들을 Django 내장 Paginator를 사용하여 한 페이지 당 10 개씩 표시
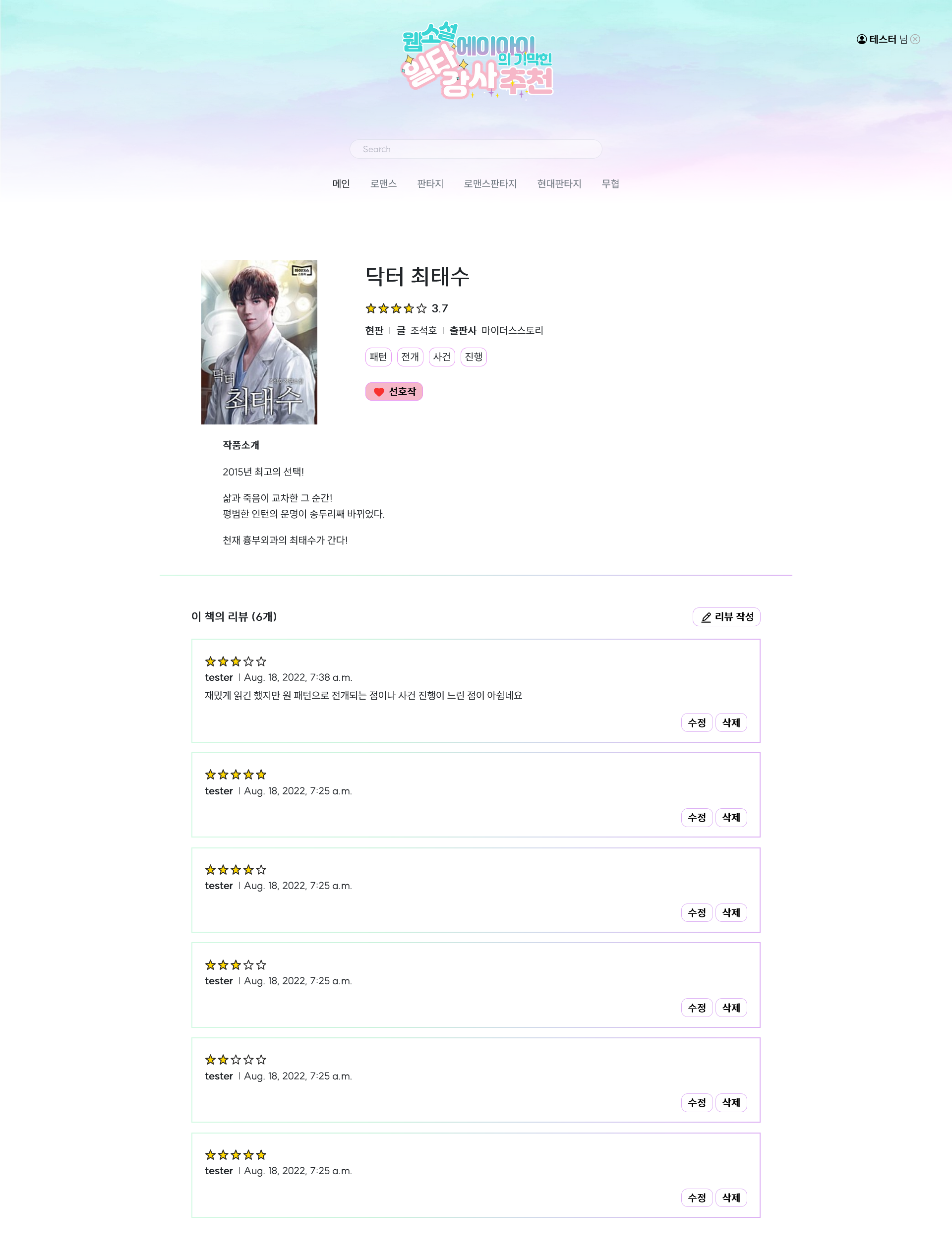
- 작품 상세 페이지에서 리뷰들의 키워드를 분석해서 가장 많은 키워드 상위 5개, 마이 페이지에서 선호작 누른 작품들의 줄거리 키워드 빈도수 상위 10개 표시
- 리뷰 CRUD
- 작품 상세페이지 제작
- 작품 리뷰 CRUD 기능
메인페이지 Today best top 20 크롤링 및 작품 클릭시 네이버 시리즈의 해당 작품 페이지 이동 기능
새로고침할 때마다 새로 크롤링하고, 해당 작품을 누르면 네이버 시리즈의 해당 작품 페이지로 이동하도록 구현
import requests
from bs4 import BeautifulSoup
url = 'https://series.naver.com/novel/top100List.series?rankingTypeCode=DAILY&categoryCode=ALL'
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url,headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#content > div > ul > li')
li_list = []
for li in lis:
cover_line = li.select_one('a > img')
cover = cover_line['src']
title = cover_line['alt']
author = li.select_one('div.comic_cont > p.info > span:nth-child(4)').text
star = li.select_one('div.comic_cont > p.info > em.score_num').text
detail = li.select_one('div.comic_cont > p.info > span:nth-child(6)').text
dic = {'cover':cover, 'title':title, 'author':author, 'author':author, 'star':star, 'detail':detail}
li_list.append(dic)
print(li_list)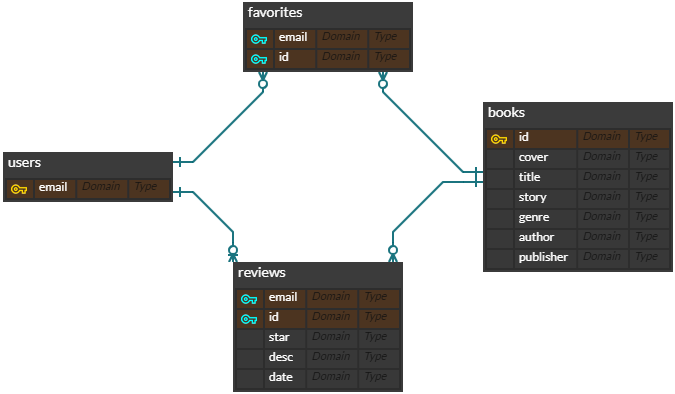
처음에 크롤링을 할 때 bs4를 이용해 전체 작품목록에서 각 작품의 상세페이지로 연결되는 url을 크롤링하고, 크롤링한 url에 각각 접속하여 작품들의 상세정보를 크롤링해왔습니다. 각 작품 상세페이지에서 작품의 전체 줄거리는 <더보기> 버튼을 눌러야만 보이는 방식이어서 크롤링 결과물에 작품줄거리가 전부 잘려있었습니다. 그래서 동적페이지에서도 사용가능한 selenium 을 같이 사용했습니다.
(코랩 : https://colab.research.google.com/drive/1olprD0sgSfZdq36o8ox0_lx8DLN1f7US?usp=sharing)
오류메세지를 보고 처음에 update 함수에서 문제가 있는 줄 알았는데, origin_review 로 불러오는 대상이 잘못되었다는 것을 알았습니다. get() 이 가져오는 것은 해당하는 객체 하나이고, filter()는 해당하는 여러개의 객체를 포함하는 QuerySet을 가져온다는 것을 알게 되어서 origin_review 를 불러올 때
ReviewModel.objects.get(id=review_id) 를 ReviewModel.objects.filter(id=review_id) 로 수정하였습니다.
# modify_review
@login_required
def modify_review(request, book_id, review_id):
origin_review = ReviewModel.objects.filter(id=review_id)
if request.method == "POST":
star = int(request.POST.get('rating', 0))
review = request.POST.get('review', '')
date = timezone.now()
origin_review.update(star=star, desc=review, date=date)
return redirect('book_info', book_id)
크롤링을 하는 부분에서 생각보다 많은 시간을 잡아먹었다. 깔끔하게 크롤링을 하기위해 고려해야할 것도 많았고, 규칙적이지 않아서 크롤링이 불가능 한 것도 많았다. 원래 웹타추로 구현하고 싶었던 것은 사용자의 평점을 기반으로 소설을 추천해주는 협업필터링 방식의 추천시스템이었는데, 유저데이터가 없어서 줄거리를 분석해서 유사도가 높은 웹소설을 추천해주는 방식으로 노선을 변경해서 조금 아쉬웠다. 크롤링한 데이터를 기반으로 모델을 테스트해본 결과 줄거리가 유사한 작품을 잘 추천하기는 하지만, 줄거리가 소설의 전체를 잘 반영하기는 어렵기 때문에 작품 분위기나 문체 등을 고려할 수 없어서 실제 서비스를 했을 때 사용자의 만족도가 높을 것 같지는 않았다.
프로젝트 후반에는 화면공유를 하면서 세부적인 디자인 변경이나 자잘한 기능을 추가하고, 버그를 즉각적으로 발견하고 나눠서 수정하는 시간을 가졌다. 점점 팀워크도 더 잘 맞는 것 같고, 다들 열정적이라 프로젝트가 더 재미있었던 것 같다.
 |
 |
 |
 |
|---|---|---|---|
| 로그인 | 회원가입 | 메인 페이지 | 장르별 작품 리스트 |
 |
 |
 |
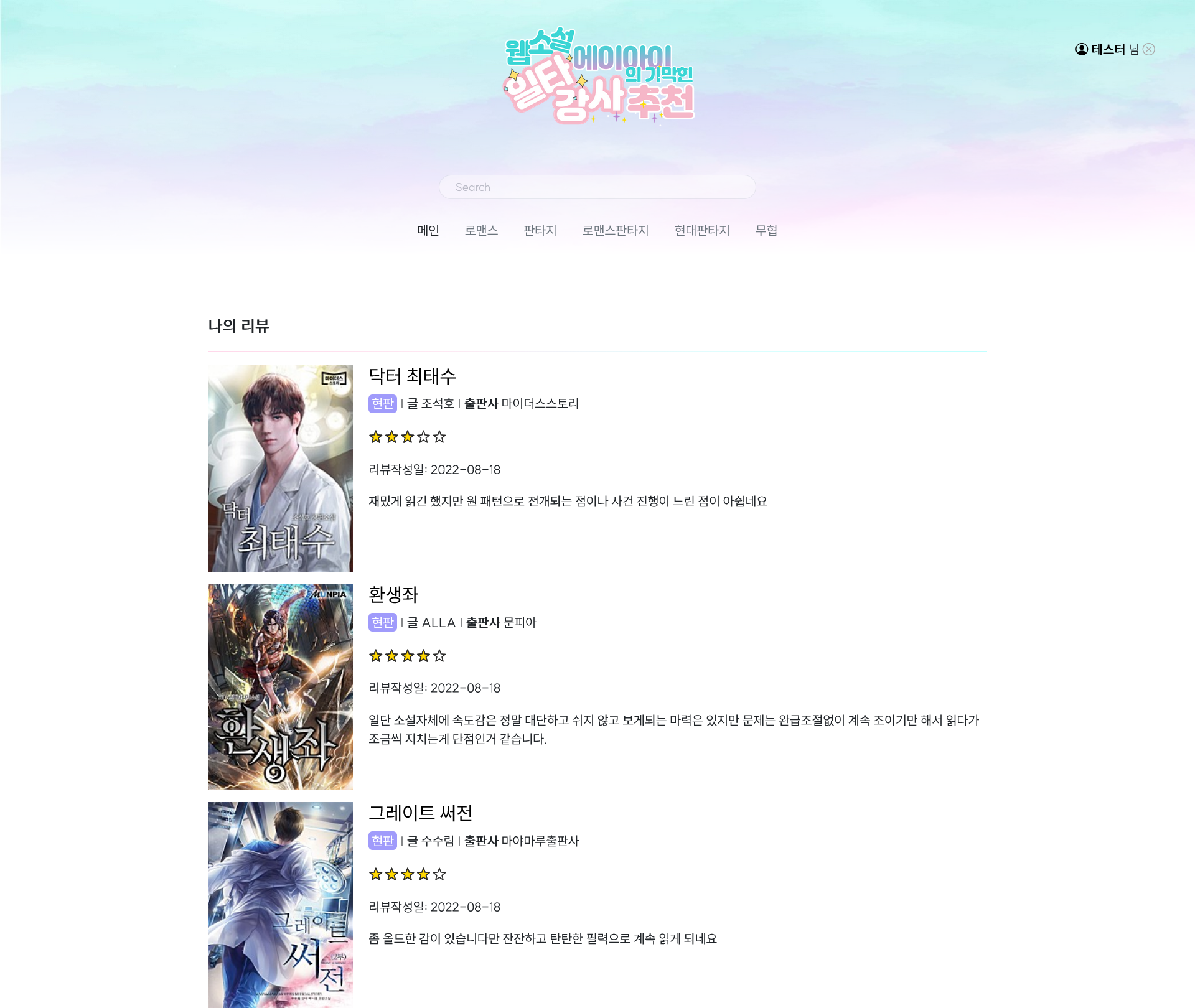 |
| 검색 결과 | 작품 상세 페이지 | 마이 페이지 | 나의 리뷰 모아보기 |
| 이름 | 역할 | 깃허브 |
|---|---|---|
| 김동근 | 메인 페이지, 장르별 페이지 | |
| 노을 | 로그인 페이지, 마이 페이지 | |
| 이정아 | 작품 상세 페이지 | |
| 이현경 | 작품 상세 페이지 |
- 추천 모델 제작은 다 같이 한다.