爬虫的应用领域非常广泛,目前利用爬虫技术市面上已经存在了比较成熟的搜索引擎产品,如百度、谷歌,以及其他垂直领域搜索引擎,这些都是非直接目的;还有一些推荐引擎,如今日头条,可以定向给用户推荐相关新闻;爬虫还可以用来作为机器学习的数据样本。
本项目的主要目的是为了更好的整合利用安全领域特有的社区资源优势。首先使用Scrapy爬虫框架结合NoSQL数据库Redis编写分布式爬虫,并对先知、安全客、嘶吼三个知名安全社区进行技术文章的爬取;然后选取ElasticSearch搭建搜索服务,同时提供了RESTfulweb接口;最后通过Django搭建可视化站点,供用户透明的对文章进行搜索。
最终通过本项目可以更加透彻的理解爬虫的相关知识;在熟练运用Python语言的基础上,更加深入的掌握开源的爬虫框架Scrapy,为后续其他与爬虫相关的业务奠定理论基础和数据基础;进一步理解分布式的概念,为大数据的相关研究和硬件条件奠定基础;熟练掌握Python搭建网站的框架Django,深入理解基于Lucene的搜索服务器ElasticSearch。
Redis是完全开源免费的,遵守BSD协议的,高性能的key-value数据库。Redis与其他key-value 缓存产品有以下三个特点:
(1)Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。这样可以防止数据的丢失,在实际生产应用中数据的完整性是必须保证的。
(2)Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。这些功能更强大的数据存储方式极大地节约了存储空间,优化了查询的性能,大大提高了查询效率。存储的目的是为了后期更好的取出,Redis很好地做到了这一点。
(3)Redis支持数据的备份,即master-slave模式的数据备份。主从结构目前是大数据里面的主流结构,主从模式能保证数据的健壮性和高可用。当出现电脑宕机,硬盘损坏等重大自然原因时,主从模式能很好的保证存储的数据不丢失,随时恢复到可用状态。
Scrapy的原理如下所示:
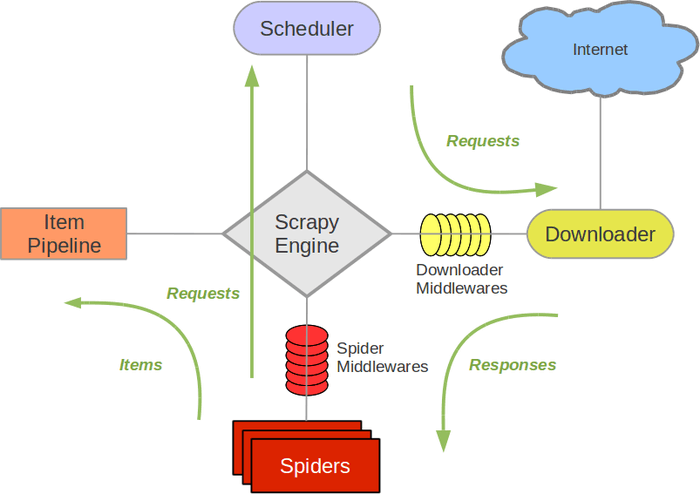
各个组件的解释如下:
(1)Scrapy Engine(引擎):负责Spider、Item Pipeline、Downloader、Scheduler中间的通讯,信号、数据传递等,相当于人的大脑中枢,机器的发动机等,具有显著的作用。
(2)Scheduler(调度器):负责接收引擎发送过来的Request请求,并按照一定的方式逻辑进行整理排列,入队,当引擎需要时,再交还给引擎。
(3)Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
(4)Spider(爬虫):负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
(5)Item Pipeline(管道):负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)。
(6)Downloader Middlewares(下载中间件):可以当作是一个可以自定义扩展下载功能的组件。
(7)Spider Middlewares(Spider中间件):可以理解为是一个可以自定义扩展和操作引擎以及Spider中间通信的功能组件(例如进入Spider的Responses;和从Spider出去的Requests)。
整个Scrapy爬虫框架执行流程可以理解为:爬虫启动的时候就会从start_urls提取每一个URL,然后封装成请求,交给engine,engine交给调度器入队列,调度器入队列去重处理后再交给下载器去下载,下载返回的响应文件交给parse方法来处理,parse方法可以直接调用XPATH方法提取数据了。
Scrapy是一个通用的爬虫框架,但是不支持分布式,Scrapy-Redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以Redis为基础的组件,具体的分布式Scrapy-Redis介绍见本文3.3章节。
MySQL是一个关系型数据库管理系统,最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS 应用软件之一。MySQL是一种关系型数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高了灵活性。
正是基于MySQL体积小、速度快、成本低的特点,本项目使用它对爬取下来的数据进行长期稳定的存储,同时利用Scrapy还可以异步进行数据的存储。在本项目中,我们要爬取的数据至少包括:文章题目、文章内容、文章链接、文章标签、作者、发表时间、访问量、封面图等。


Django是一个开放源代码的Web应用框架,由Python开发的基于MVC构造的框架。在Django中,控制器接受用户输入的部分由框架自行处理,因此更加关注模型,模板和视图,即MVT。
-
模型(Model),即数据存取层,处理与数据相关的所有事物:包括如何存取,如何验证有效性,数据之间的关系等。
-
视图(View),即表现层,处理与表现相关的逻辑,主要是显示的问题。
-
模板(Template),即业务逻辑层,主要职责是存取模型以及调取恰当模板的相关逻辑。
控制器部分,由Django框架URLconf来实现,而URLconf机制恰恰又是使用正则表达式匹配URL,然后调用合适的函数。因此只需要写很少量的代码,只需关注业务逻辑部分,大大提高了开发的效率。使用Django搭建搜索引擎的界面,简单便捷且界面交互效果良好,适应需求,无须成本。同时Scrapy与Django的代码模式有些类似,如Django中的Model与Scrapy中的Item,Scrapy也提供了相应的DjangoItem类,其从Django模型中获取字段(field)定义。
ElasticSearch是一个基于Lucene的实时的分布式搜索和分析引擎,设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用非常方便。基于RESTful接口。ElasticSearch具有广泛的用户,如DELL,GitHub,Wikipedia等。
ElasticSearch和关系型数据库之间的对比如下所示:
| Index(索引库) | Database(数据库) |
|---|---|
| Type(类型) | Table(表) |
| Document(文档) | Row(行) |
| Field(字段) | Column(列) |
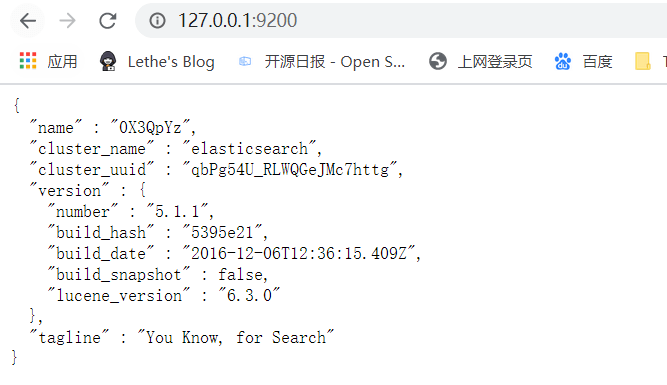
Elasticsearch-RTF是针对中文的一个发行版,使用稳定的Elasticsearc版本,并且下载测试好对应的插件,如中文分词插件等,目的是可以下载下来就可以直接的使用。项目构建过程中选择的是 Elasticsearch-RTF 5.1.1 版本。安装后启动,效果如下所示,通常运行在9200端口:
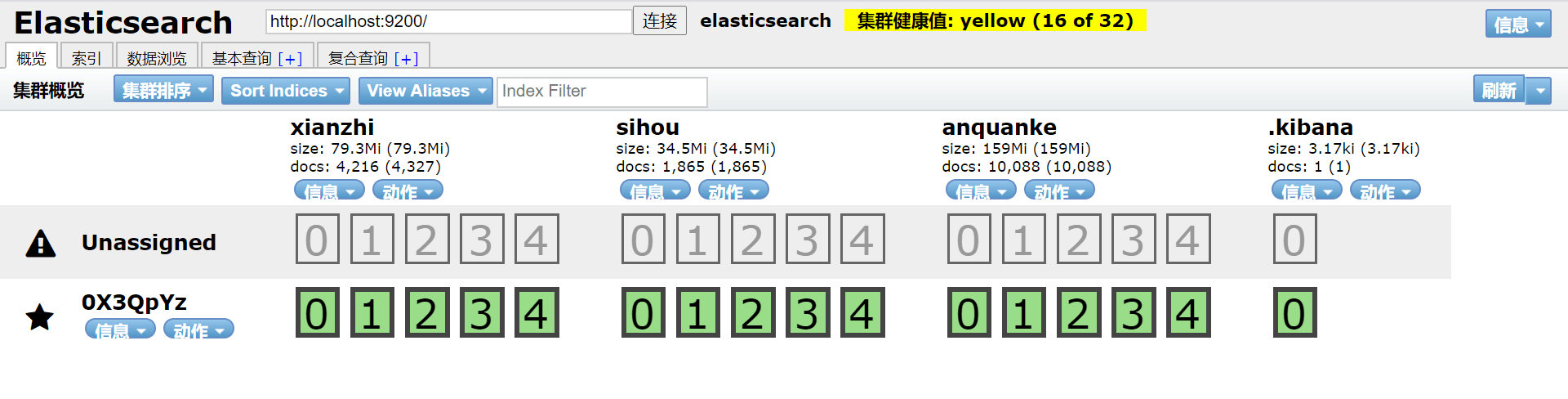
ElasticSearch-head是一个Web前端插件,用于浏览Elastic⁃Search集群并与之进行交互,它可以作为ElasticSearch插件运行,一般首选这种方式,当然它也可以作为独立的Web应用程序运行。它的通用工具有三大操作:
ClusterOverview,显示当前集群的拓扑,并允许执行索引和节点级别的操作;有几个搜索接口可以查询原生Json或表格格式的检索结果;显示集群状态的几个快速访问选项卡;一个允许任意调用RESTful API的输入部分。
运行结果如下,通常运行在9100端口:
Kibana是一个开源的分析与可视化平台,设计出来用于和Elasticsearch一起使用的。可以用kibana搜索、查看、交互存放在Elasticsearch索引里的数据,使用各种不同的图表、表格、地图等。kibana能够很轻易地展示高级数据分析与可视化。Kibana使理解大量数据变得容易。它简单、基于浏览器的接口能快速创建和分享实时展现Elasticsearch查询变化的动态仪表盘。Kibana启动完成后,可看到插入数据和页面查询显示结果,通常运行在5607端口:

反爬措施:网站在处理反爬的过程中,很常见的一种方式就是通过检测User-agent来拒绝非浏览器的访问。
作为应对,我们需要在每次发送请求时加上浏览器的User-Agent字段,可以在Scrapy的middlewares.py中自定义RandomUserAgentMiddleware类,并作为Download Middleware启用。Download Middware是引擎和下载器的中间件,每个Request在爬取之前都会调用其中开启的类,从而对Request进行一定的处理,在这里就是对每个请求加上随机的User-Agent。

关于如何获取到随机的User-Agent,可以通过fake_useragent库获取,实际上这个库的作者维护了一个User-Agent的集合,使用方法如下,通过实例化UserAgent类,可以利用random随机取出一个User-agent以供使用:

反爬措施:如果同一个IP地址访问过于频繁时,就直接将访问的IP地址进行封锁,短期内进行访问。
对于这种反爬手段,可以维护一个IP代理池,当IP被封锁时进行IP的更换,或者通过代理隐藏自己的IP。目前网上提供代理的网站服务有不少,通常是充值一定的费用,就可以使用它提供的代理IP。由于本项目中对代理池的需求不大,因此仅是使用一个免费的代理网站进行演示,如下:

为了获取该网站上的代理IP地址,可以单独写一个小爬虫将该网站提供的http代理爬取到数据库proxy_ip中:
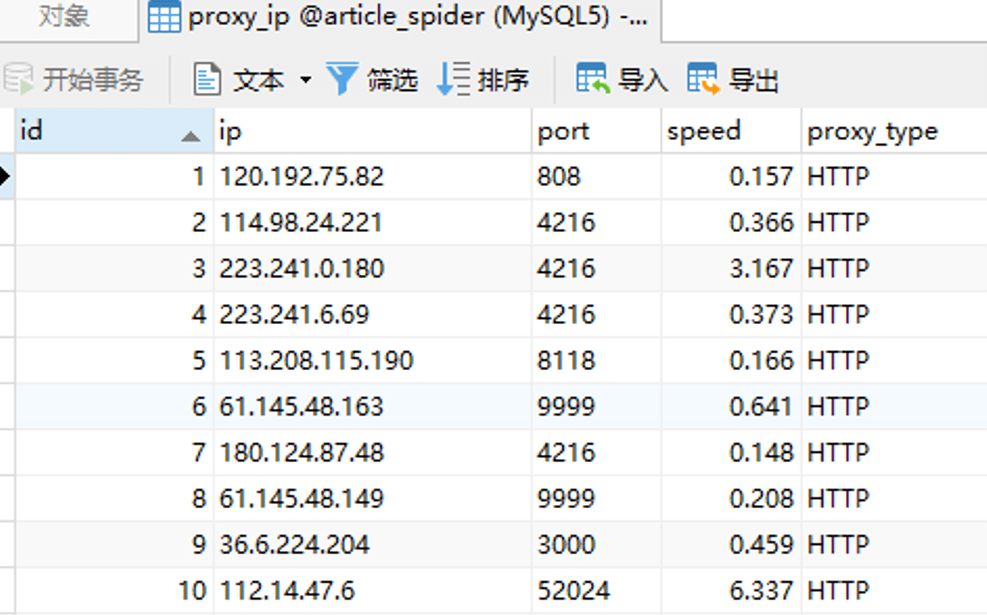
同样是以Download Middleware的方式,在Request爬取前,从数据库中随机取出一个代理,通过代理进行访问并爬取。

反爬措施:如果访问过快的话,会返回其他状态码/跳转等(302、429等)来阻止你继续访问内容页面,如下在爬取嘶吼时候,若访问频率过快,则会出现如下页面:

对于这一反爬的应对措施,主要有以下两种思路:
-
在Scrapy中可以直接设置每次请求之间的间隔来降低频率。
-
自定义Middleware在每次接收到的Response被跳转时,将爬虫暂停一段时间再继续爬取。
在本项目中,使用的第二种方法,实现代码如下,在遇到频率先之后将爬虫暂停15秒再继续,经测试,可以有效的处理嘶吼的该反爬措施:

反爬措施:有些网站可以通过跟踪 Cookie 来识别是否是同一个客户端。如果同一个客户端在单位时间内的请求过于频繁,则判断为爬虫,对此客户端进行禁止。
这个处理反爬的方式比较简单,Scrapy 默认开启了 Cookie,而如果爬取过程中不需要登录的话,就可以在setting.py文件中将COOKIES_ENABLED设置为False即可。

反爬措施:在进行登录等操作时,要求用户输入随机生成的验证码,验证码输入正确才能进行下一步的操作。
验证码可以说是当前最常见的一种反爬措施,几乎所有需要登录的地方都需要用户输入验证码来证明操作不是有机器人或者爬虫完成的。验证码的识别问题是一个较为复杂的问题,由于其并不是本项目中的研究重点,因此我们主要考虑如何应用现有的验证码识别方式即可。当前比较常见的验证码识别方式有如下三种:
-
编码实现:有能力的情况下可以自己训练模型,通常可以使用谷歌公司提供的tesseract-ocr库,但是对于噪音较多的而验证码来说,识别率并不是很高。
-
在线打码:即使用某些在线平台提供的api接口,将爬虫获取的验证码图片上传至api,该平台会在内部进行识别,并返回结果。
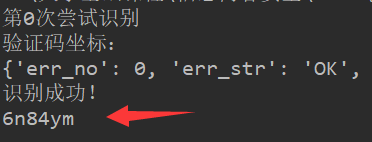
目前在线打码是使用最多的一种方式,使用起来快捷方便、可以识别多种验证码类型,且准确率较高,缺点就是通常来说需要收费,不过价格也不会太高。代码就是像平台api提供使用者的用户名、密码和验证码即可,下图为验证码的识别效果:
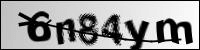
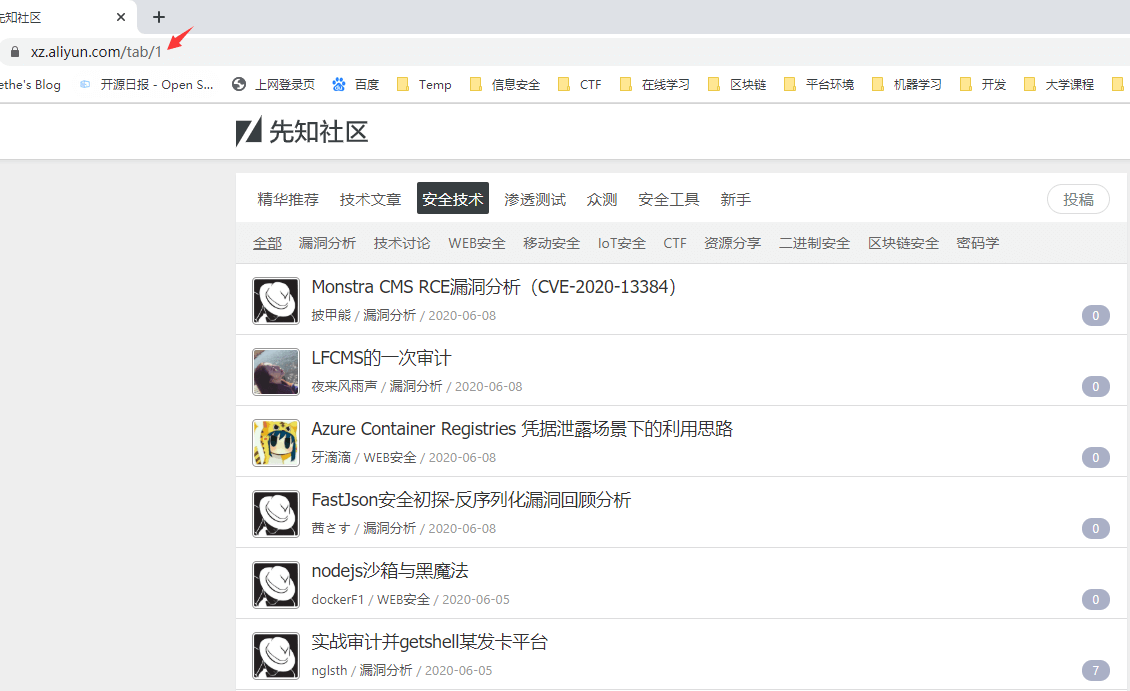
对于先知社区的爬取,可以说是比较容易的,该网站逻辑架构简洁明了,首页中即有文章列表和文章分类tab。 通过进一步分析可知,每个分类的tab序号不同,通过/tab/1的方式可获取不同种类的文章。
分页也是通过?page=2参数进行分页,也比较的清楚:
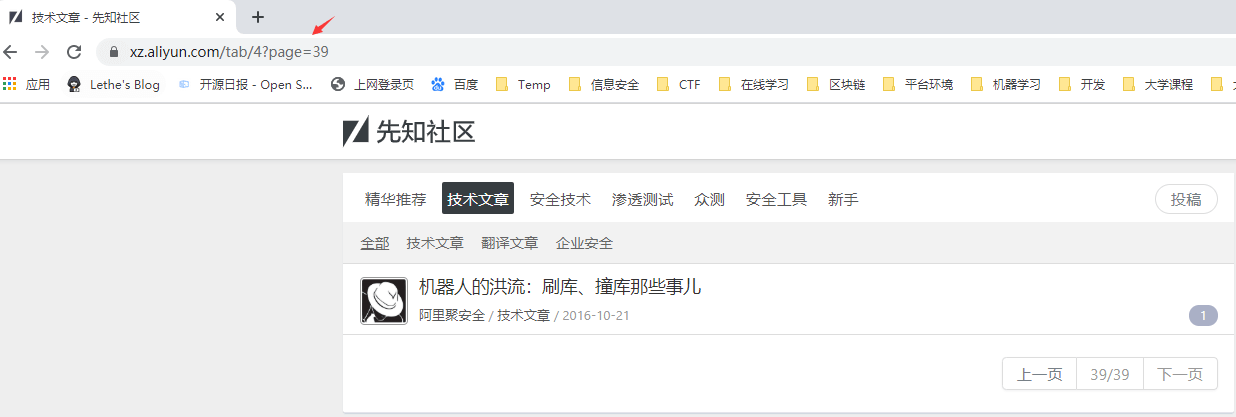
因此我们的爬虫实现思路如下:
(1)遍历每一个tab页面。
(2)对页面中的每个文章信息进行爬取,包括文章链接。
(3)对步骤2中提取的每个文章页面再进行爬取,取得文章具体信息。
(4)当前页面爬取完后,判断是否存在“下一页”按钮来判断是否爬取完成。
在Scrapy中的Spider代码如下:
from scrapy.http import Request
from urllib import parse
from ..items import XianzhiArticleItem, ArticleItemLoader
from ..utils.common import get_md5
from scrapy_redis.spiders import RedisSpider
class XianzhiSpider(RedisSpider):
name = 'xianzhi' # 启动的时候指定名称
redis_key = 'xianzhi:start_urls'
# allowed_domains = ['xz.aliyun.com']
# start_urls = ['https://xz.aliyun.com/']
def parse(self, response):
tabs = [1, 4, 7, 9, 10, 13]
for tab in tabs:
tab_url = response.url + 'tab/{}'.format(tab)
yield Request(url=tab_url, callback=self.tab_parse)
# 爬取的每个url会进入这个函数,会返回response
def tab_parse(self, response):
# 解析列表页中的所有文章url并交给scrapy下载后并进行解析
post_nodes = response.css('table.table.topic-list tr')
for post_node in post_nodes:
image_url = post_node.css('a.user-link img::attr(src)').extract_first() # 图片地址
post_url = post_node.css('a.topic-title::attr(href)').extract_first() # 获取文章的地址
yield Request(url=parse.urljoin(response.url, post_url), meta={"front_image_url": image_url},
callback=self.parse_detail)
# 提取下一页并交给scrapy下载
next_url = response.css('div.pagination.clearfix li:nth-child(3) a::attr(href)').extract_first("")
if next_url and next_url.startswith('?'):
yield Request(url=parse.urljoin(response.url, next_url), callback=self.tab_parse)
def parse_detail(self, response):
# 通过item_loader加载item
item_loader = ArticleItemLoader(item=XianzhiArticleItem(), response=response)
item_loader.add_value('front_image_url', [response.meta.get('front_image_url', '')])
item_loader.add_css('title', '.content-title::text') # 添加css选择器
item_loader.add_value('url', response.url)
item_loader.add_value('url_object_id', get_md5(response.url))
item_loader.add_css('create_date', '.info-left span:nth-child(3)::text')
item_loader.add_css('view_count', '.info-left span:nth-child(5)::text')
item_loader.add_css('author', '.info-left span:nth-child(1)::text')
item_loader.add_css('follow_count', '#follow-count::text')
item_loader.add_css('mark_count', '#mark-count::text')
item_loader.add_css('content', '#topic_content')
item_loader.add_css('tags', '.content-node a::text')
article_item = item_loader.load_item()
yield article_item # 传递到pipelines安全客的首页看起来比先知社区要复杂一些,并且是鼠标点击“加载更多”来分页的,爬取难度看似更大。但是通过分析翻页时的请求包,发现安全客是也是通过请求api来获取文章的信息的,api链接如下:
https://api.anquanke.com/data/v1/posts?size=20&page=2
我们通过观察此api返回的内容,不难推测到:url中参数size指的是一页请求的文章数量,参数page则是表示当前页数。

我们继续分析该api返回的json内容:

除了没有直接给出文章的url以及文章内容之外,我们爬虫所所需要的信息都可以直接获取,只需要简单的解析返回的json即可。
-
虽然没有给出文章url但是给出了id,我们容易得到固定的文章url格式为:/post/id/206483,即我们可以通过id来得到文章url。
-
而文章的内容,我们则需要先用id构造文章url,然后异步发送请求来获取content。
实现代码如下:
import json
from scrapy.http import Request
from ..items import AnquankeArticleItem, ArticleItemLoader
from ..utils.common import get_md5
from scrapy_redis.spiders import RedisSpider
class AnquankeSpider(RedisSpider):
name = 'anquanke'
redis_key = 'anquanke:start_urls'
# allowed_domains = ['api.anquanke.com', 'anquanke.com']
# start_urls = ['https://api.anquanke.com/data/v1/posts?size=500']
def parse(self, response):
res = json.loads(response.text)
posts = res.get('data')
for post in posts:
# 剔除掉活动和招聘的文章
if ('招聘' in post.get('tags')) or ('活动' in post.get('tags')):
continue
item_loader = ArticleItemLoader(item=AnquankeArticleItem(), response=response)
item_loader.add_value('title', post.get('title'))
item_loader.add_value('create_date', post.get('date'))
item_loader.add_value('front_image_url', post.get('cover'))
item_loader.add_value('author', post.get('author').get('nickname'))
item_loader.add_value('view_count', post.get('pv'))
item_loader.add_value('comment_count', post.get('comment'))
item_loader.add_value('like_count', post.get('like_count'))
item_loader.add_value('tags', post.get('tags'))
yield Request(url='https://www.anquanke.com/post/id/{}'.format(post.get('id')),
meta={'article_item': item_loader}, callback=self.parse_content)
# 获取下一页
next_url = res.get('next')
if next_url:
yield Request(url=next_url, callback=self.parse)
def parse_content(self, response):
item_loader = response.meta.get('article_item', '')
content = response.css('div.article-content').extract_first().replace('data-original=', 'src=')
item_loader.add_value('content', content)
item_loader.add_value('url', response.url)
item_loader.add_value('url_object_id', get_md5(response.url))
article_item = item_loader.load_item()
yield article_item嘶吼的分页也是通过点击“加载更多”,但是分析后可知其分页方式实际上和先知的类似,即通过?page=2进行分页。
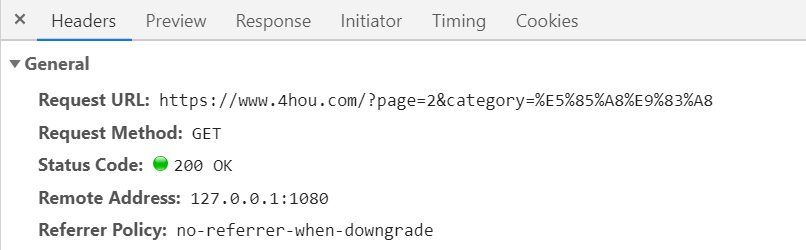
但是这样有个问题是如何判断最后一页,在项目中我尝试了以下两种方法,最终使用了第二个方法:
-
首先考虑设置一个变量page,每次翻页时加一,当页面的文章列表为空的时候判断为最后一页,但是Scrapy是异步框架,在快速爬取的过程中page的使用会混乱。
-
于是考虑设定一个最大的page数,这里页数最多的是web安全分类(126页),所以我们就默认爬取的每个分类页数都设置为大于126的数(或者更大一些),然后再判断是否存在文章列表,存在就继续爬取,否则就转到下一页。
另外就是嘶吼的文章分类位于首页的“阅读”下拉栏中,但是实际上也已经在htm;
中可以找到:
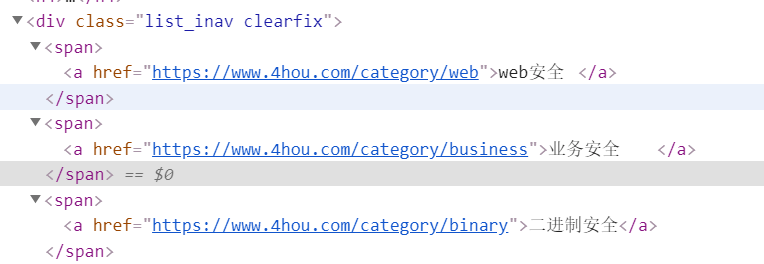
实现代码如下:
from scrapy.http import Request
from ..items import ArticleItemLoader, SihouArticleItem
from ..utils.common import get_md5
from scrapy_redis.spiders import RedisSpider
class A4houSpider(RedisSpider):
name = 'sihou'
redis_key = 'sihou:start_urls'
# allowed_domains = ['4hou.com']
# start_urls = ['https://www.4hou.com']
# 爬取的每个url会进入这个函数,会返回response
def parse(self, response):
# types = response.css('div.technology a::attr(href)').extract()
for type_url in response.css('div.technology a::attr(href)').extract(): # 获取各个分类标签
for i in range(1, 150):
page = "?page={}".format(i)
yield Request(url=type_url + page, callback=self.parse_post)
def parse_post(self, response):
# 解析列表页中的所有文章url并交给scrapy下载后并进行解析
if response.css('div.main-box') != []:
post_nodes = response.css('div.main-box')
for post_node in post_nodes:
image_url = post_node.css('div.new_img img::attr(src)').extract_first() # 图片地址
view_count = post_node.css('div.read span::text').extract_first().replace(',', '') # 浏览量
praise_count = post_node.css('div.Praise span::text').extract_first().replace(',', '') # 点赞数
post_url = post_node.css('div.new_con a::attr(href)').extract_first()
yield Request(url=post_url,
meta={'front_image_url': image_url, 'view_count': view_count,
'praise_count': praise_count},
callback=self.parse_detail)
def parse_detail(self, response):
# 通过item_loader加载item
item_loader = ArticleItemLoader(item=SihouArticleItem(), response=response)
item_loader.add_value('front_image_url', [response.meta.get('front_image_url', '')])
item_loader.add_css('title', 'h1.art_title::text') # 添加css选择器
item_loader.add_value('url', response.url)
item_loader.add_value('url_object_id', get_md5(response.url))
item_loader.add_css('create_date', 'div.art_time span:nth-child(3)::text')
item_loader.add_value('view_count', response.meta.get('view_count', '0'))
item_loader.add_css('author', 'span.sir::text')
item_loader.add_value('praise_count', response.meta.get('praise_count', '0'))
item_loader.add_css('content', 'div.article_cen')
item_loader.add_css('tags', 'span.lei::text')
article_item = item_loader.load_item()
yield article_item # 传递到pipelines原来的Scrapy是不支持分布式的,我们知道Scrapy在进行爬虫爬取网站时,会在内存中维护一个Request队列,首先将start_urls放入该队列中,然后在爬取的过程中,不断的将URL插入该队列或从队列中取出。除此之外,Scrapy还需要维护一个去重队列,用来对爬取的URL进行去重操作。
所以,若要将我们的Scrapy项目重构为分布式的项目,主要需要解决的问题就是下面两个:
-
Request 队列集中管理:scheduler以队列形式存储在内存中,而其他服务器无法拿到当前服务器内存中的内容。
-
scrapy的去重队列也是放在内存中,如何对去重队列进行集中管理。
实际上使用Scrapy进行分布式爬虫的编写并不是特别复杂,其原理及思路主要如下:
(1)把自己的核心服务器称为master,而把用于跑爬虫程序的机器称slave。
(2)采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了。
(3)我们在master上搭建一个redis数据库(只用作url的存储,不关心爬取的具体数据),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。
(4)这样尽管有多个slave,我们都可以设置其scrapy-redis从master的redis服务器中获取url。实际上除了url,scrapy-redis还会在redis服务器上存储去重队列,以及一个items数据库。
(5)程序移植性强,把slave上的程序移植到另一台机器上运行非常的简单。
Scrapy-Redis分布式爬虫的大致原理图如下:
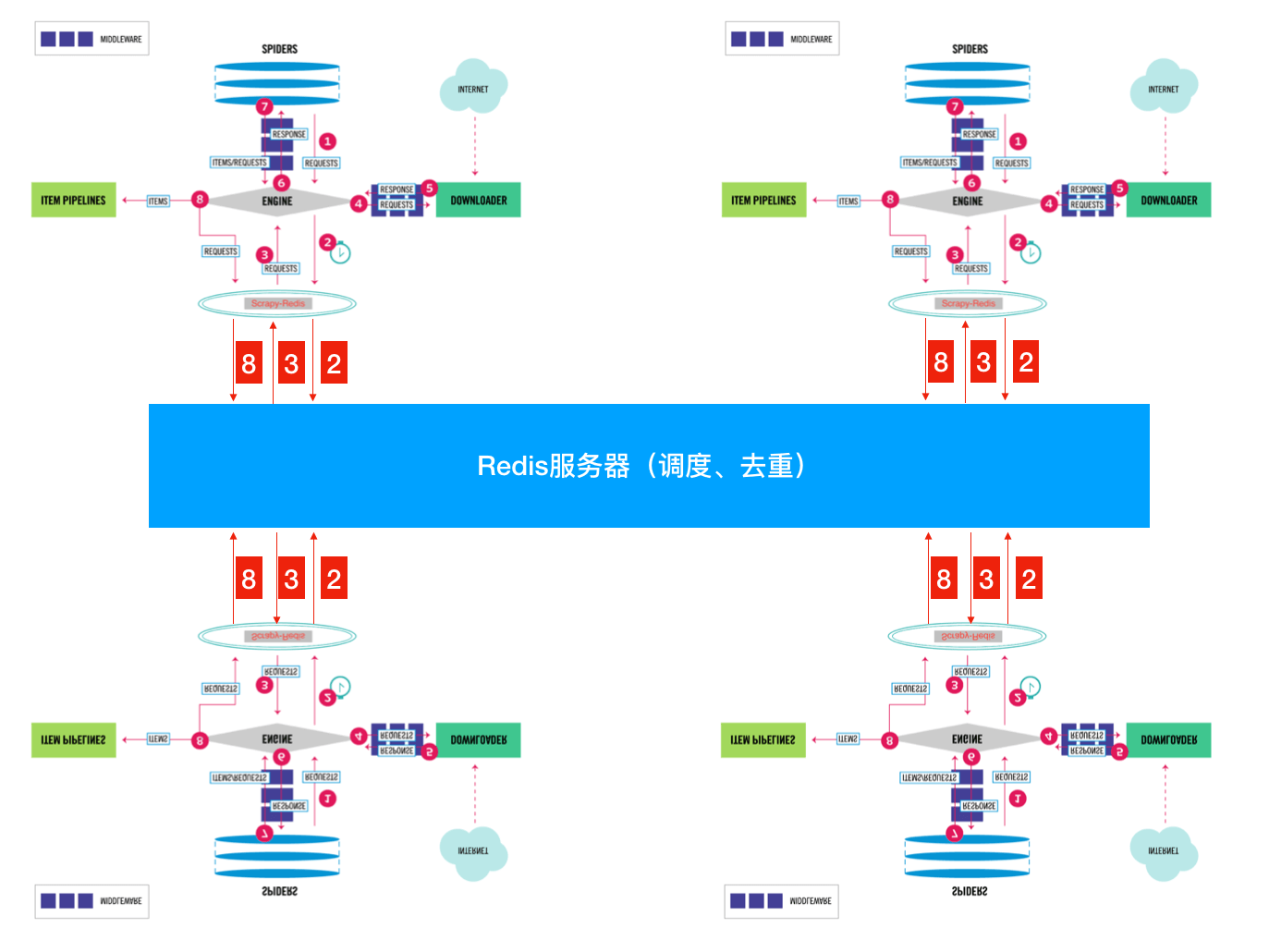
针对于本项目中,Scrapy-Redis分布式爬虫的实现思路如下:
(1)使用两台机器,一台是win10(本机),一台是(ubuntu),分别在两台机器上部署scrapy来进行分布式抓取一个网站
(2)Win10作为Master,开启redis服务,同时也作为一个slave进行抓取;Ubuntu作为一个slave来进行抓取,两台机器的爬虫均从redis服务端中获取url。
(3)master的爬虫运行时会把提取到的url封装成request放到redis中的数据库,并且从该数据库中不断的提取request后下载网页,再把网页的内容存放到redis的另一个items数据库中。
(4)slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis。
(5)重复上面的3和4,直到master的redis中的request数据库为空,再把master的redis中的items数据库写入到Mysql数据库中。
(6)Raster里的reids还有一个dupefilter数据库,用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),用来去重的。
具体代码实现,首先要重构的是Scrapy的spider,即需要将原来爬虫类继承Scrapy-redis的RedisSpider类:
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
name = 'myspider'
def parse(self, response):
# do stuff
pass除此之外,还需要再setting.py中进行一些分布式的设置,例如:
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Store scraped item in redis for post-processing.
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}本项目的具体配置,可见源代码setting.py。
对于搜索引擎的使用,首先要明确以下两个问题:
(1)我们对于搜索引擎需求:
-
高效
-
零配置、完全免费
-
能够简单通过json和http与搜索引擎交互
-
搜索服务器稳定
-
能够简单的将一台服务器扩展到上百
(2)为什么不能用传统的关系数据库完成搜索功能
-
无法打分
-
无分布式
-
无法解析请求搜索
-
效率低
-
需要单独实现分词
倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
以英文为例子,加上要索引的文本如下:
T_0="It is what it is"
T_1="what is it"
T_2="it is a banana"
若使用传统的正向索引,即索引如下:
Docs={
0 => "It is what it is"
1 => "what is it"
2 => "it is a banana"
}
而使用倒排索引,索引如下:
"a": {2}
"banana": {2}
"is": {0, 1, 2}
"it": {0, 1, 2}
"what": {0, 1}
另外,倒排索引待解决问题如下:
-
大小写转换问题,如 python 和 PYTHON 应该为一个词
-
词干抽取,looking 和 look 应该处理为一个词
-
分词
-
倒排索引文件过大,压缩编码
使用ElasticSearch时,对于查询出的文档无疑会有文档相似度之别。而理想的排序是和查询条件相关性越高排序越靠前,而这个排序的依据就是_score。
Elasticsearch使用布尔模型查找匹配文档,并用一个名为实用评分函数的公式来计算相关度。这个公式借鉴了词频/逆向文档频率(TF-IDF)和向量空间模型,同时也加入了一些现代的新特性,如协调因子、字段长度归一化以及词或查询语句权重提升,公式如下:


对上述公式中的部分概念进行如下解释:
(1)词频(Term frequency)
语在文档中出现的频度是多少,频度越高,权重越大。一个5次提到同一词语的字段比一个只有1次提到的更相关。词频的计算方式如下:
词语t在文件d的词频(tf)是这个词语在文档中出现次数的平方根。
(2)逆向文档频率(Inverse document frequency)
词语在集合所有文档里出现的频次。频次越高,权重越低。常用词如and或the对于相关度贡献非常低,因为他们在多数文档中都会出现,一些不常见词语如elastic或lucene可以帮助我们快速缩小范围找到感兴趣的文档。逆向文档频率的计算公式如下:
词语t的逆向文档频率(Inverse document frequency)是:索引中文档数量除以所有包含该词语文档数量后的对数值。
(3)字段长度正则值(Field-length norm)
字段的长度是多少,字段越短,字段的权重越高。如果词语出现在类似标题title这样的字段,要比它出现在内容body这样的字段中的相关度更高。字段长度的正则值公式如下:
字段长度正则值是字段中词语数平方根的倒数。
(4)查询正则因子(Query Normalization Factor)
查询正则因子(queryNorm)试图将查询正则化,这样就能比较两个不同查询结果。尽管查询正则值的目的是为了使查询结果之间能够相互比较,但是它并不十分有效,因为相关度分数_score的目的是为了将当前查询的结果进行排序,比较不同查询结果的相关度分数没有太大意义。
(5)查询协调(Query Coordination)
协调因子(coord)可以为那些查询词语包含度高的文档提供“奖励”,文档里出现的查询词语越多,它越有机会成为一个好的匹配结果。
在本项目中为了更加模拟成熟搜索引擎的模式,并且方便用户的查询,加入了搜索提示的功能,所要达到的效果如下,即当用户输入搜索关键词后,搜索框下方会实时显示根据此关键词所相关联的结果。

要实现此功能,需要利用到ElasticSearch中的suggest用法:
-
首先需要在每个mapping中增加一个suggest字段类型为Completion。
-
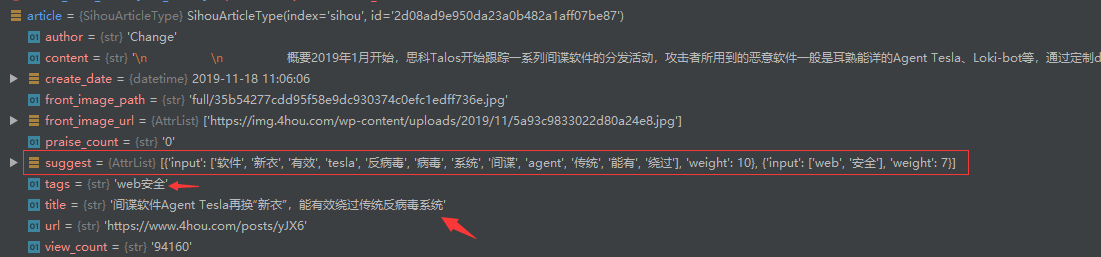
在items.py中为每个类增加suggest字段,创建一个函数(gen_suggests)来生成suggest的数组(可以使用_analyze接口自动分词获得相应的关键词数组),并且可以对搜索字段设置权重weight。
gen_suggests函数的实现代码如下:

使用_analyze接口自动分词调试结果如下:
模糊搜索即根据用户输入的搜索关键词,返回与其最相关的搜索内容。模糊搜索的实现主要是根据编辑距离来判断。
编辑距离是一种字符串之间相似程度的计算方法,即两个字符串之间的编辑距离等于使一个字符串变成另一个字符串而需要进行插入、删除、替换、相邻字符串交换位置四种操作的最少次数。例如,Linux与linx的编辑距离是1,它们之间的变换只需要进行1步操作。关于编辑距离的求法,普遍采用的是动态规划。
在ElasticSearch中需要设置:
-
Fuzziness:表示最小编辑距离,小于最小编辑距离的可以模糊搜索到,可设置为AUTO。
-
prefix_length:前边不参与模糊查询的词长度为多少。例如在查询footbal时,若该参数设为3,则foatball将不能匹配到。
由于Web开发的知识,并不是本课程设计的主要考察点,且报告长度有限,因此具体的网站开发流程将不在报告中体现。本节内容将对网站开发中所涉及到的爬虫、分布式及搜索服务设计的问题进行阐述。
在网站中,我们预计在侧边加上分布式爬虫对各个网站所爬取的文章数量,效果如下:

传统的思路是每次显示时,进行一次数据数量的查询,但是这样显然会降低网站的加载速率。本项目中采取一种更有效率的方式,即利用Redis实现。具体来说:每个爬虫在redis中维护一个全局变量,每次存储一个数据时就在redis中对一个全局变量加一。最后显示的时候,从redis中读取该变变量即可获得统计数据,这样就避免了每次都去检索。
演示效果如下:
本项目的文章搜索网站中另一个比较重要的功能即为“热门搜索”,即将用户搜索次数最多的关键词列举出来。这实际上是一个Top n问题,利用Redis也是可以非常简单高效的实现。
具体实现方法为在Redis中创建一个可排序列表,每次当用户查询一个关键词时,就将其加到列表中,同时加上相应的分数,最后取得时候按分数排序即可取出热门搜索。
另外,还有“我的搜索”功能,此功能实现较为简单,直接利用前端Javascript即可实现。
效果图如下:

在分布式爬虫系统中面临的各种复杂的挑战中,除了分布式任务的调度、分布式系统中负载均衡等,分布式系统中URL去重更是非常重要的一点。分布式系统中URL去重算法影响着系统的效率,面对上百亿的URL设计一个优秀的去重算法能提高整个系统的性能。
目前的爬虫系统对于URL的去重策略主要有以下几种:
-
将访问过的URL保存到数据库中;
-
将访问过的URL保存到set中,只需要O(1)的代价就可以查询URL;
-
URL经过md5等方法哈希后保存到set中(scrapy-redis默认)
-
用bitmap方法将访问过的URL通过hash函数映射到某一位。
-
bloomfilter方法对bitmap进行改进,多重hash函数降低冲突。
Scrapy框架使用的默认去重策略是上述的第三种方式,即使用sha1算法,对每一个request对象加密,生成40位十六进制数,并且scrapy的去重默认会保存到内存中,如果任务重启,会导致内存中所有去重队列消失。
而我们在将项目重构为分布式爬虫系统后,Scrapy-Redis重写了Scrapy的调度器和去重队列,所以需要在settings中修改如下两列:
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"我们可以稍微分析一下Scrapy-Redis的去重重要代码:
def request_seen(self, request):
"""Returns True if request was already seen.
Parameters
----------
request : scrapy.http.Request
Returns
-------
bool
"""
fp = self.request_fingerprint(request)
# This returns the number of values added, zero if already exists.
added = self.server.sadd(self.key, fp)
return added == 0
def request_fingerprint(self, request):
"""Returns a fingerprint for a given request.
Parameters
----------
request : scrapy.http.Request
Returns
-------
str
"""
return request_fingerprint(request)首先拿到scrapy.http.Request会先调用self.request_fingerprint去计算,也就是scrapy的sha1算法去哈希,然后会向redis中添加该指纹。该函数的作用是:计算该请求指纹,添加到redis的去重队列,如果已经存在该指纹,返回True。
我们可以看到,只要有在settings中添加DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter",就会在redis中新加一列去重队列,这样左的优缺点如下:
-
优点:将内存中的去重队列序列化到redis中,及时爬虫重启或者关闭,也可以再次使用,你可以使用SCHEDULER_PERSIST来调整缓存
-
缺点:如果你需要去重的指纹过大,redis占用空间过大。8GB=8589934592Bytes,平均一个去重指纹40Bytes,约可以存储214,748,000个(2亿)。所以在做关系网络爬虫中,序列化到redis中可能并不是很好,保存在内存中也不好,所以就产生了布隆过滤器。
上一小节的最后提到了布隆过滤器(Bloom Filter),这是一种目前来看效率较高、对内存消耗也较少的URL去重策略。它的算法原创建一个 m 位的BitSet,先将所有位初始化为0,然后选择 k 个不同的哈希函数。第 i 个哈希函数对字符串 str 哈希的结果记为 h(i, str),且 h(i, str) 的范围是 0~m-1。
Bloom Filter的操作主要如下两种:
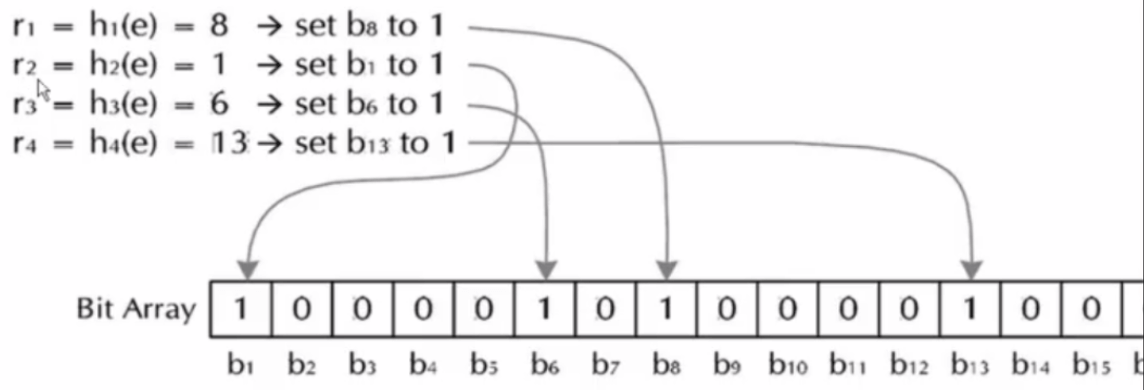
(1)Bloom Filter加入字符串
对于字符串str,分别计算h (1, str) ,h (2, str)…(k, str)。然后将BitSet的第h(1, str)、h(2, str)…(k, str)位设为1,这样字符串str映射到了BitSet中的k个二进制位了。
原理图如下:
(2)检测字符串是否存在
对于字符串str,分别计算h(1,str),h(2,str)…(k,str)。然后检查BitSet的第h(1, str)、h(2, str)…h(k, str)位是否为1,若其中任何一位不为1则可以判定str一定没有被记录过。若全部位都是1,则“认为”字符串str存在。
若一个字符串对应的Bit不全为1,则可以肯定该字符串一定没有被Bloom Filter记录过,因为字符串被记录过,其对应的二进制位肯定全部被设为1了。
但是若一个字符串对应的Bit全为1,实际上是不能100%的肯定该字符串被Bloom Filter记录过的,因为有可能该字符串的所有位都刚好是被其他字符串所对应。这种将该字符串划分错的情况,称为False Positive。
Bloom Filter的具体实现代码如下:
import redis
import math
import time
class PyBloomFilter():
# 内置100个随机种子
SEEDS = [543, 460, 171, 876, 796, 607, 650, 81, 837, 545, 591, 946, 846, 521, 913, 636, 878, 735, 414, 372,
344, 324, 223, 180, 327, 891, 798, 933, 493, 293, 836, 10, 6, 544, 924, 849, 438, 41, 862, 648, 338,
465, 562, 693, 979, 52, 763, 103, 387, 374, 349, 94, 384, 680, 574, 480, 307, 580, 71, 535, 300, 53,
481, 519, 644, 219, 686, 236, 424, 326, 244, 212, 909, 202, 951, 56, 812, 901, 926, 250, 507, 739, 371,
63, 584, 154, 7, 284, 617, 332, 472, 140, 605, 262, 355, 526, 647, 923, 199, 518]
# capacity是预先估计要去重的数量
# error_rate表示错误率
# conn表示redis的连接客户端
# key表示在redis中的键的名字前缀
def __init__(self, capacity=1000000000, error_rate=0.00000001, conn=None, key='BloomFilter'):
self.m = math.ceil(capacity * math.log2(math.e) * math.log2(1 / error_rate)) # 需要的总bit位数
self.k = math.ceil(math.log1p(2) * self.m / capacity) # 需要最少的hash次数
self.mem = math.ceil(self.m / 8 / 1024 / 1024) # 需要的多少M内存
self.blocknum = math.ceil(self.mem / 512) # 需要多少个512M的内存块,value的第一个字符必须是ascii码,所有最多有256个内存块
self.seeds = self.SEEDS[0:self.k]
self.key = key
self.N = 2 ** 31 - 1
self.redis = conn
def add(self, value):
name = self.key + "_" + str(ord(value[0]) % self.blocknum)
hashs = self.get_hashs(value)
for hash in hashs:
self.redis.setbit(name, hash, 1)
def is_exist(self, value):
name = self.key + "_" + str(ord(value[0]) % self.blocknum)
hashs = self.get_hashs(value)
exist = True
for hash in hashs:
exist = exist & self.redis.getbit(name, hash)
return exist
def get_hashs(self, value):
hashs = list()
for seed in self.seeds:
hash = mmh3.hash(value, seed)
if hash >= 0:
hashs.append(hash)
else:
hashs.append(self.N - hash)
return hashs
pool = redis.ConnectionPool(host='127.0.0.1', port=6379, db=0, password='yuan123')
conn = redis.StrictRedis(connection_pool=pool)
if __name__ == '__main__':
start = time.time()
bf = PyBloomFilter(conn=conn)
bf.add('www.baidu.com')
bf.add('www.google.com')
print(bf.is_exist('www.zhihu.com'))
print(bf.is_exist('www.baidu.com'))
end = time.time()
print(end - start)上述测试代码运行结果如下,结果中0代表未重复,1代表已重复,从时间来看效率还是比较高的:

本项目的分布式演示用到了本机(Windows 10)同时作为master和slave,另有一台Vmware虚拟机(Ubuntu)作为slave。
首先分别在两个系统上运行main.py文件,使爬虫运行,但是由于此使Redis中并没有创建start_urls,所以两个系统下的slave爬虫均处于等待状态:
(1)Windows 10:
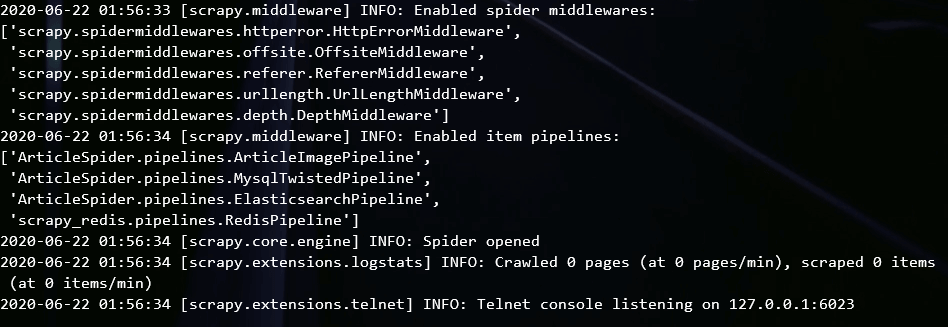
(2)Ubuntu:
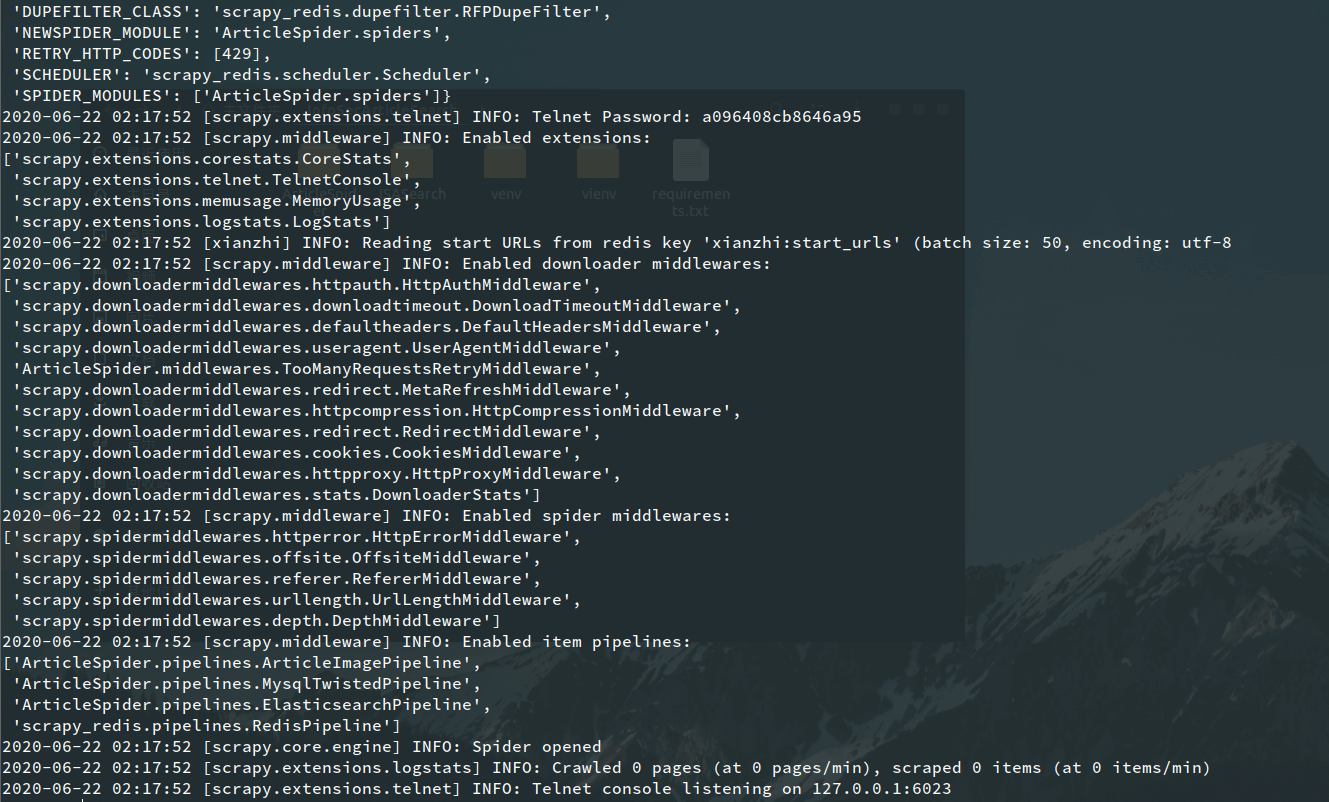
要启动爬虫,首先需要建立一个Redis客户端并连接对应的Redis服务端,然后使用如下命令加入将带爬取的首页url加入start_urls中:
lpush xianzhi:start_urls https://xz.aliyun.com/Redis命令如下:

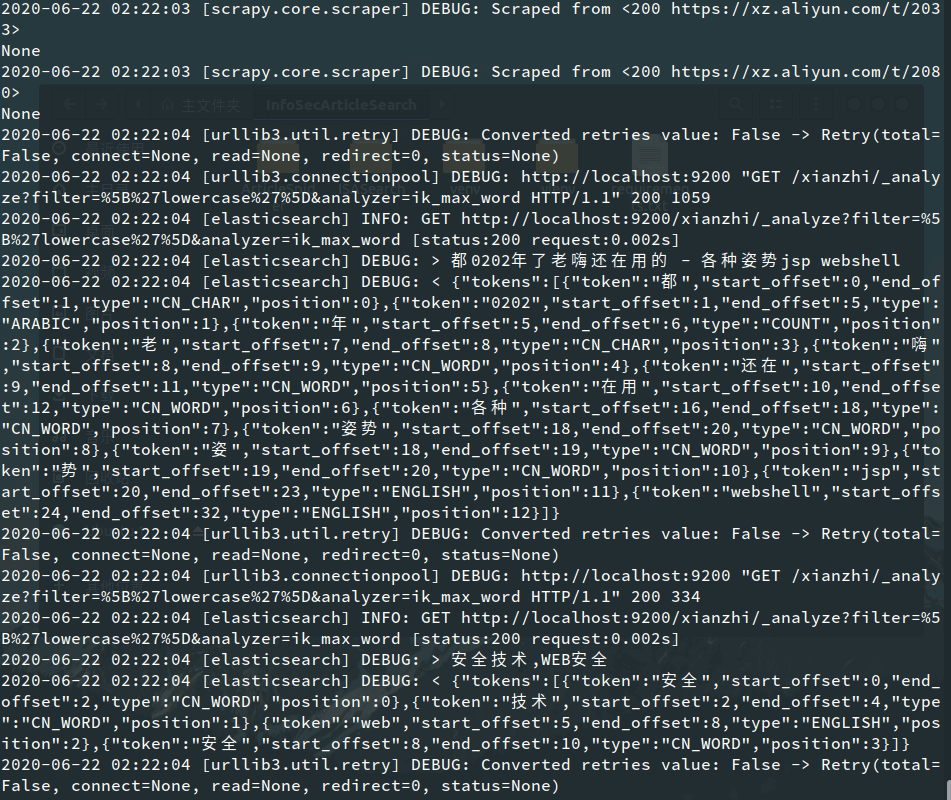
执行完上述命令后,可以看到slaves上的爬虫开始进行分布式爬取:
(1)Windows 10
(2)Ubuntu
搜索网站的首页效果图展示如下,可以看到搜索框下面具有“热门搜索”和“我的搜索”列表,只需要在搜索框中输入关键词,然后点击搜素按钮即可进行搜索:

用户进行搜索,假设搜索框中输入关键词“python”,系统可根据该关键词进行搜索提示,效果展示如下:
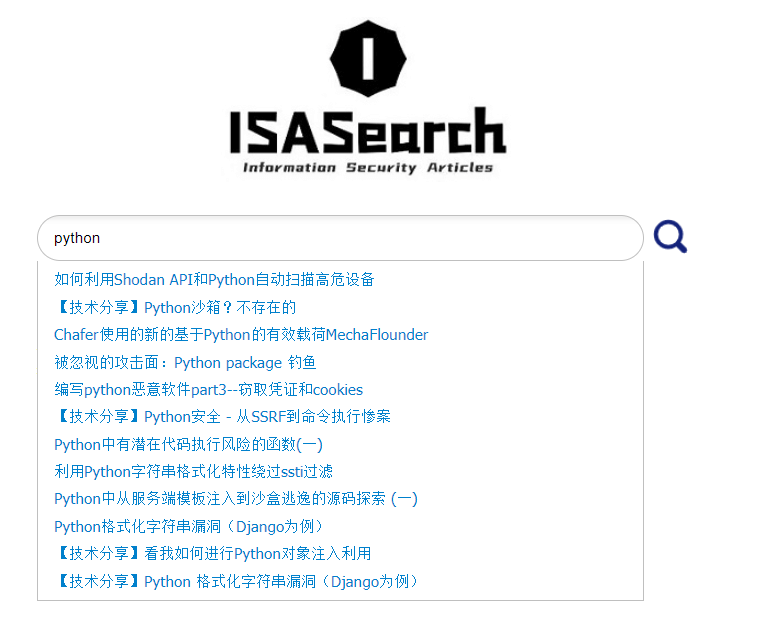
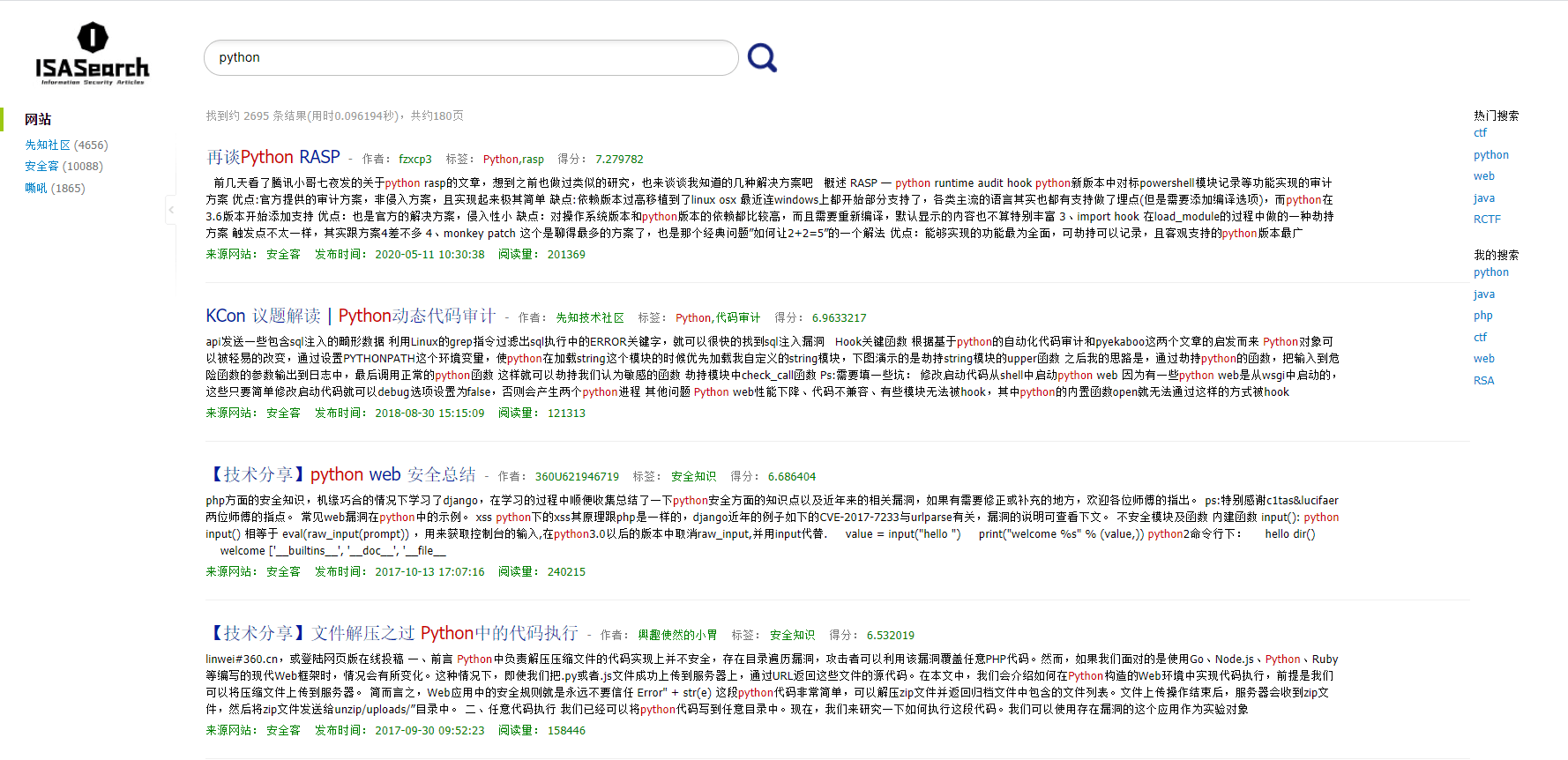
点击搜索后,会跳转到搜索结果页面,页面左侧即位爬虫统计数据,页面中间为搜索到的文章信息(包括题目、作者、标签、评分、来源、发布时间、阅读量),页面右侧即为实时更新的“热门搜索”和“我的搜索”列表:
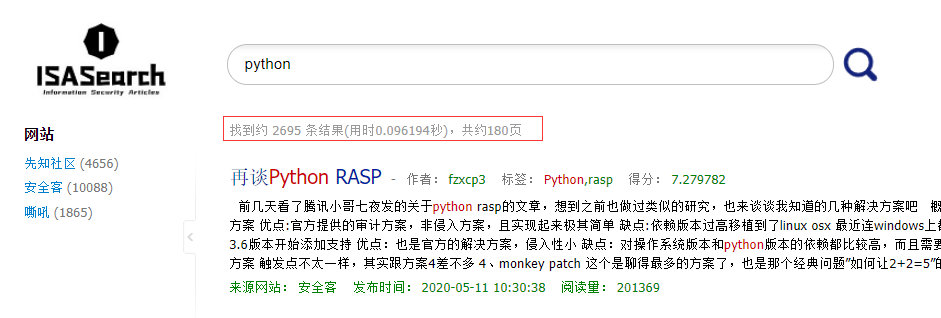
在搜索结果中还可以看到根据关键词所搜索道德结果数量、搜索用时以及页数:
分页跳转则在页面的最底部: