This is a documentation for the Heterogeneity Dataset for Human Activity Recognition (HHAR) from Smartphones and Smartwatches from the public repository: https://archive.ics.uci.edu/ml/datasets/Heterogeneity+Activity+Recognition or the personal Website: http://cs.au.dk/~allans/heterogenity/.
The Heterogeneity Dataset for Human Activity Recognition from Smartphone and Smartwatches is a dataset devised to benchmark human activity recognition algorithms (classification, automatic data segmentation, sensor fusion, feature extraction, etc) containing sensor heterogeneities. The files in this archive contain all the samples from the activity recognition experiment. The dataset contains the readings of two motion sensors commonly found in smartphones' recorded while users executed activities scripted in no specific order carrying smartwatches and smartphones.
The data is split into 4 files in total divided by device (phone or watch) and sensor (gyroscope and accelerometer). The files for phones are: Phones_accelerometer.csv, Phones_gyroscope.csv for the accelerometer and gyroscope respectively, and for the Watch_accelerometer.csv, Watch_gyroscope.csv for the accelerometer and gyroscope as well.
Activities: ‘Biking’, ‘Sitting’, ‘Standing’, ‘Walking’, ‘Stair Up’ and ‘Stair down’. Sensors: Two embedded sensors, i.e., Accelerometer and Gyroscope sampled at the highest frequency possible by the device Devices: 4 smartwatches (2 LG watches, 2 Samsung Galaxy Gears) 8 smartphones (2 Samsung Galaxy S3 mini, 2 Samsung Galaxy S3, 2 LG Nexus 4, 2 Samsung Galaxy S+) Recordings: 9 users currently named: a,b,c,d,e,f,g,h,i consistently across all files.
This dataset were used in the course project in ID2223 HT17-18.
- Original Dataset: Heterogeneity Activity Recognition Data.
- We only used the accelerometer from phone data and only use the x,y,z features + the label.
- In
/HAR_Dataset/cleaned_data_parallelyou'll find cleaned data in parallel format, this is the recommended data to use for training. The cleaned data is put into sequence format with sliding windows of size 200 and stride 20. Furthermore, in the cleaned data the Null-classes are removed. - In
/HAR_Dataset/cleaned_datayou'll find single csv files with sequence data but with null-classes - In
/HAR_Dataset/original_datayou'll find the dataset as it looks before any preprocessing, downloaded from https://archive.ics.uci.edu/ml/datasets/Heterogeneity+Activity+Recognition at 10/12-2017 - See
hdfs:///Projects/har_2/Jupyter/for notebooks using this dataset - See also
./notebooksfor the public notebooks - In
/android_app/HAR.apkyou'll find a executable for running the model inside an android APP - In
/saved_model_w_nullyou'll find a frozen model after training with the null-class (accuracy around 95) - In
/saved_model_wo_nullyou'll find a frozen model after training without the null-class (accuracy around 97) - In
/slidesyou'll find the presentation slides from the presentation 9/1 2018
The data set is structured in the following way:
All the csv files have the same structure of following columns:
- 'Index',
- 'Arrival_Time',
- 'Creation_Time',
- 'x',
- 'y',
- 'z',
- 'User',
- 'Model',
- 'Device',
- 'gt'
And the columns have the following values:
- Index: is the row number.
- Arrival_Time: The time the measurement arrived to the sensing application
- Creation_Time The timestamp the OS attaches to the sample
- X,y,z The values provided by the sensor for the three axes, X,y,z
- User: The user this sample originates from, the users are named a to i.
- Model: The phone/watch model this sample originates from
- Device: The specific device this sample is from. They are prefixed with the model name and then the number, e.g., nexus4_1 or nexus4_2.
- Gt: The activity the user was performing: bike sit, stand, walk, stairsup, stairsdown and null
Each accelerometer sample if represented as a single row in the file and with all columns having repeated values. For the semantics of the different timestamp versions, see the publication [1].
Also due to issues with sampling some users have few collected samples for specific activities, e.g., User h and activity sit in the Phones_accelerometer.csv.
The null class is defined as null in the gt (groundtruth) column, whereas the rest of the classes are called bike sit, stand, walk, stairsup, stairsdown.
The names and models of the devices used in the HAR data set are:
- LG-Nexus 4 'nexus4_1' 'nexus4_2'
- Saumsung Galaxy S3 's3_1' 's3_2’
- Samsung Galaxy S3 min: 's3mini_1' 's3mini_2'
- Samsung Galaxy S+: 'samsungold_1' 'samsungold_2'
The names of the same devices used in the ‘still experiment’ are the following: ‘it-116', 'it-133', 'it-108', 'it-103','it-123','3Renault-AH', 'no-name/LG-Nexus4','G-Watch'
[1] Allan Stisen, Henrik Blunck, Sourav Bhattacharya, Thor Siiger Prentow, Mikkel Baun Kjærgaard, Anind Dey, Tobias Sonne, and Mads Møller Jensen "Smart Devices are Different: Assessing and Mitigating Mobile Sensing Heterogeneities for Activity Recognition" In Proc. 13th ACM Conference on Embedded Networked Sensor Systems (SenSys 2015), Seoul, Korea, 2015. http://dx.doi.org/10.1145/2809695.2809718
LSTM model inspired from a blog-post by Venelin Valkov. The blog-post used a different dataset and only ran locally.
There are four notebooks.
data_setupcontains data cleaning: remove Null-classes and save as parallelized.train_local_cpucontains local CPU training and distributed experiments and hyper-parameter tuningtrain_local_gpucontains local GPU training and distributed experiments and hyper-parameter tuningtrain_dist_asynccontains distributed training with TensorflowOnSpark and async SGDtrain_dist_synccontains distributed training with TensorflowOnSpark and sync SGD
Two extra notebooks that don't runt on hops:
local_notebooks/local_preprocess_dataWe encountered a bug on hops when using numpy and was advised on the gitter channel to run this locally. This notebook contains the first step in preprocessing, creating sliding window sequences of the data. Should be easy to adapt to hops as soon as this bug is fixed.local_notebooks/local_data_explorationSome plots with matplotlib.
The dataset contains sensordata collected from a accelerometer in a smartphone. The accelerometer measures the orientation of the phone in three coordinates: x,y,z. The machine learning task in this case is to predict the human activity from a sequence of phone-orientations in terms of x,y,z coordinates. We have chosen to use sequence-length of 200 for prediction and truncated backpropagation of length 200.
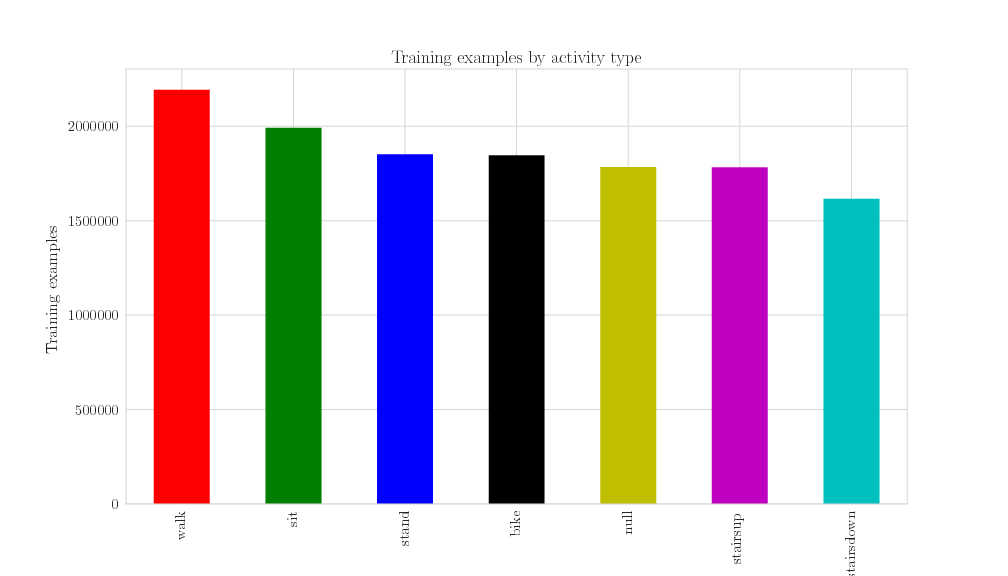
Class distribution. As mentioned in the paper describing the dataset, the human activities were recorded when test persons had the phone/device attached to a pocket on the chest.
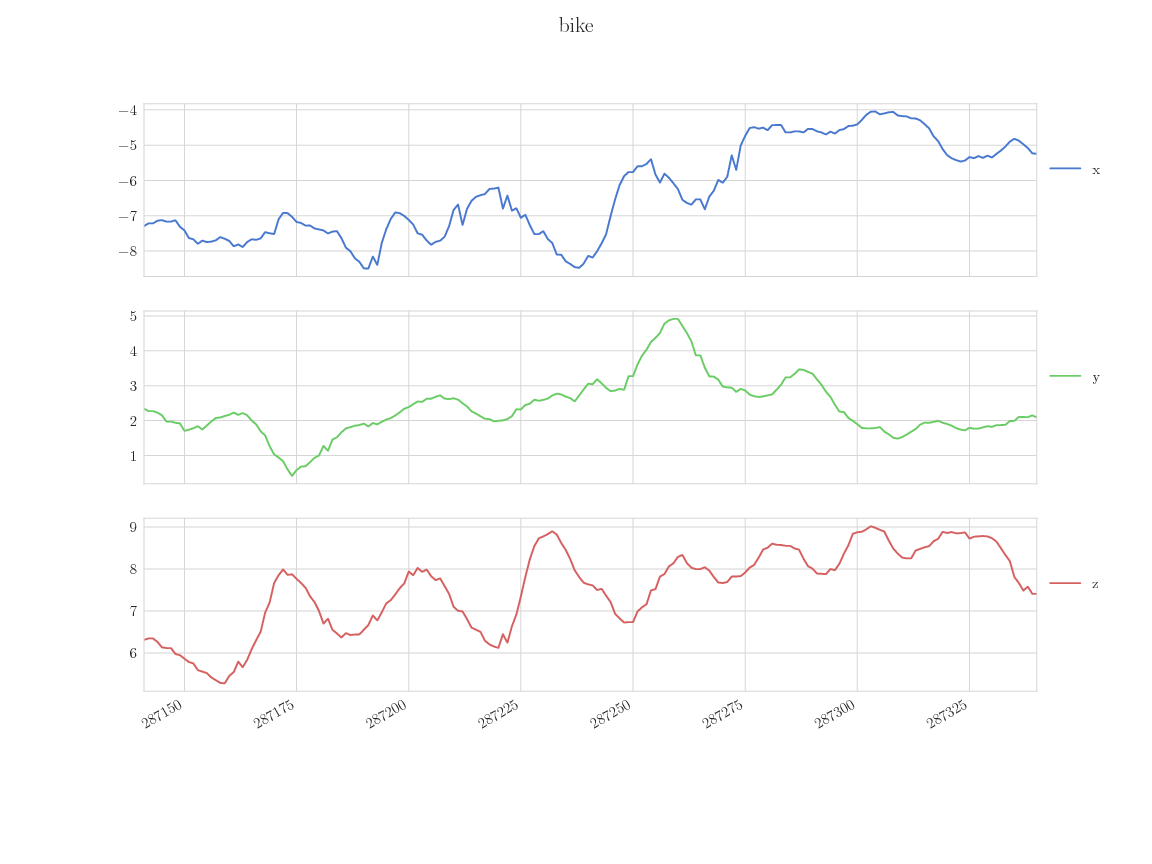
Sensor inputs for the activities "bike" and "sit".

A trained model is frozen and downloaded to edge devices where it is used in an phone-application to predict the human activity based on the sensor data.
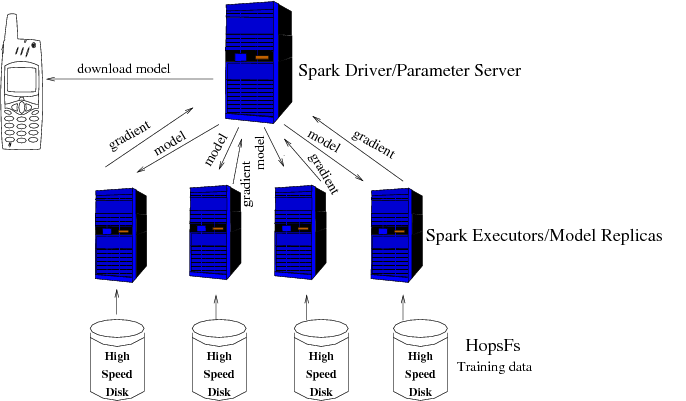
Distributed LSTM training on hops with TensorflowOnSpark.
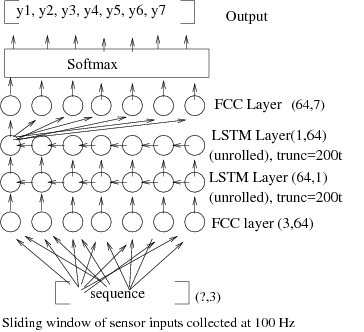
LSTM/RNN network for predicting human activities given a sequence of sensordata. Model size (excluding bias terms and regularization terms, assuming 32bit weights): 32(364 + 2(4(64^2 + 64^2)) + 647 = 32*66176 = 2117632 = (approximate) 260 KB). Each LSTM cell has 4 input gates, each one having one input weight matrix W of size 64^2 and one input recurrent weight matrix U of size 64^2.
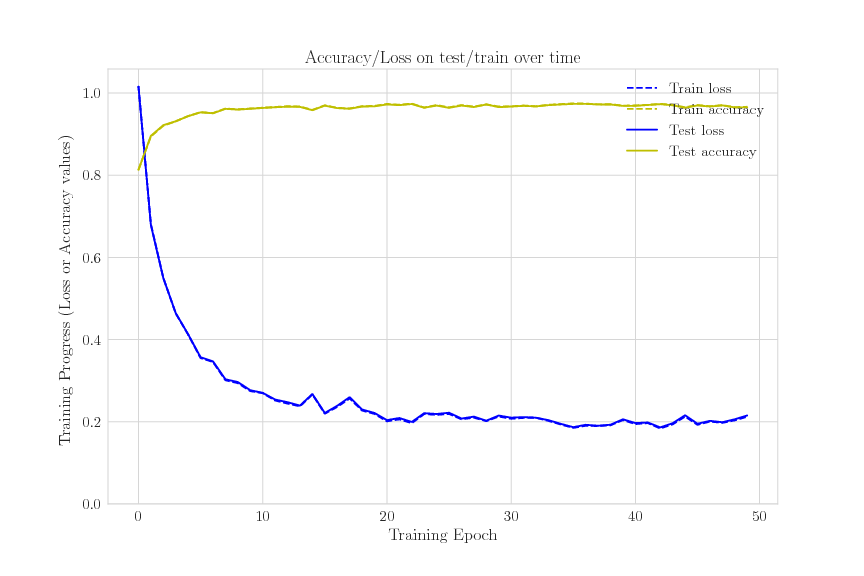
Accuracy and Loss over time during training for 50 epochs. Best result: 97% accuracy (24h training on single machine) Each epoch accounts for approximately 510 batches. Batch size = 1000, sequences are of length 200.
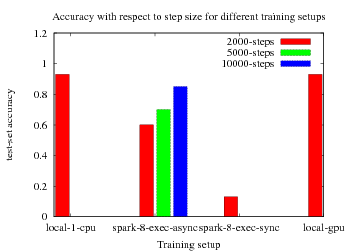
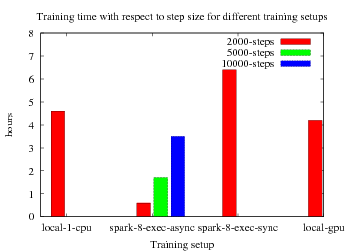
Very rough benchmarks on hops, all training setups used the same hyper-parameters.
Asynchronous SGD yielded near linear training speedup but slower convergence. Synchronous SGD was the slowest and suffered from exploding gradients (NaN loss). This indicates that the learning rate need to be fine-tuned for distributed training (This tuning have not been done yet). TF-GPUs don't support full LSTM operations, did only give small boost over CPU, had to run tensorflow with "soft_placement=true".
Download and run it on your android device, it uses the android API for accessing the sensordata from the phone's accelerometer and the frozen model to make predictions.
Kim Hammar, kimham@kth.se
Konstantin Sozinov, sozinov@kth.se