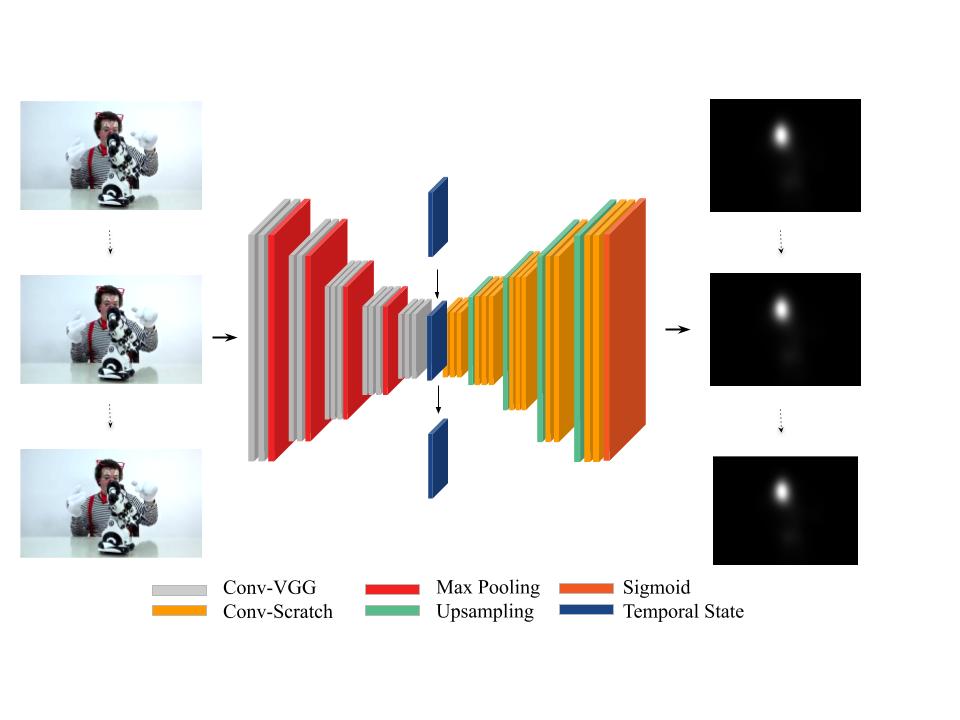
SalEMA is a video saliency prediction network. It utilizes a moving average of convolutional states to produce state of the art results. The architecture has been trained on DHF1K.
Find the published version of our work here: arXiv, or check our friendly summary on medium. Also, if this project has been helpful to your work, please consider citing us:
@inproceedings{linardos2019simple,
author = {Panagiotis Linardos and
Eva Mohedano and
Juan Jos{\'{e}} Nieto and
Noel E. O'Connor and
Xavier Gir{\'{o}}{-}i{-}Nieto and
Kevin McGuinness},
title = {Simple vs complex temporal recurrences for video saliency prediction},
booktitle = {30th British Machine Vision Conference 2019, {BMVC} 2019, Cardiff,
UK, September 9-12, 2019},
pages = {182},
publisher = {{BMVA} Press},
year = {2019},
url = {https://bmvc2019.org/wp-content/uploads/papers/0952-paper.pdf},
timestamp = {Thu, 30 Apr 2020 17:36:09 +0200},
biburl = {https://dblp.org/rec/conf/bmvc/LinardosMNONM19.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
- Download our best configuration of the SalEMA model here (364MB)
- Download our best configuration of the SalCLSTM model here (580MB)
- Download our baseline, the SalBCE model here (364MB)
Sample video (click to be redirected to youtube):

- Clone the repo:
git clone https://github.com/Linardos/SalEMA- Install requirements
pip install -r requirements.txtYou may use our pretrained model for inference on either of the 3 datasets: DHF1K [link], Hollywood-2 [link], UCF-sports [link] or your own dataset so long as it follows a specific folder structure:
To perform inference on DHF1K validation set:
python inference.py -dataset=DHF1K -pt_model=SalEMA30.pt -alpha=0.1 -start=600 -end=700 -dst=/path/to/output -src=/path/to/DHF1KTo perform inference on Hollywood-2 or UCF-sports test set (because of the way the dataset is structured, it's convenient to use the same path for dst and src):
python inference.py -dataset=Hollywood-2 -pt_model=SalEMA30.pt -alpha=0.1 -dst=/path/to/Hollywood-2/testing -src=/path/to/Hollywood-2/testingpython inference.py -dataset=UCF-sports -pt_model=SalEMA30.pt -alpha=0.1 -dst=/path/to/UCF-sports/testing -src=/path/to/UCF-sports/testingTo perform inference on your own dataset make sure to follow a simple folder structure (one superfolder given as root at the input, which includes folders of frames) and use the tag "other":
python inference.py -dataset=other -alpha=0.1 -pt_model=SalEMA30.pt -dst=/path/to/output -src=/path/to/superfolder/framesIf your dataset follows a more quirky structure you might need to manipulate the data_loader source code.
To train on DHF1K using CUDA:
python train.py -dataset=DHF1K -pt_model=False -new_model=SalEMA -ema_loc=30 -start=1 -end=4 -src=/path/to/DHF1K -use_gpu='gpu' -epochs=7To train on Hollywood-2, UCF-sports using CUDA. For fine-tuning a pretrained model, use a higher number of epochs, the training commences from the epoch number where it stopped on:
python train.py -dataset=Hollywood-2 -pt_model=SalEMA30.pt -new_model=SalEMA -ema_loc=30 -src=/path/to/Hollywood-2 -use_gpu='gpu' -epochs=10 -lr=0.0000001