- Restore support for CI/CD.
| <75> | ||||
| Headline | Time | % | ||
|---|---|---|---|---|
| Total time | 85:02 | 100.0 | ||
| Stories | 85:02 | 100.0 | ||
| Active | 85:02 | 100.0 | ||
| Edit release notes for previous sprint | 6:06 | 7.2 | ||
| Create a demo and presentation for previous sprint | 0:27 | 0.5 | ||
| Fix broken org-mode tests | 3:09 | 3.7 | ||
| Sprint and product backlog grooming | 9:00 | 10.6 | ||
| Move build to GitHub | 4:07 | 4.8 | ||
| Update vcpkg to latest | 3:00 | 3.5 | ||
| Remove third-party dependencies outside vcpkg | 1:19 | 1.5 | ||
| Remove deprecated travis and appveyor config files | 0:02 | 0.0 | ||
| Create clang build using libc++ | 0:36 | 0.7 | ||
| Rewrite CTest script to use github actions | 13:15 | 15.6 | ||
| Remove database options from help | 0:07 | 0.1 | ||
| Generate doxygen docs and add to site | 1:51 | 2.2 | ||
| Add packaging step to github actions | 0:21 | 0.4 | ||
| Setup MSVC Windows build for debug and release | 3:31 | 4.1 | ||
| Can’t see build info in github builds | 0:35 | 0.7 | ||
| Update build instructions in readme | 0:34 | 0.7 | ||
| Replace Dia IDs with UUIDs | 0:22 | 0.4 | ||
| Update the test package scripts for the GitHub CI | 0:39 | 0.8 | ||
| Move codec related tests into codecs | 1:02 | 1.2 | ||
| Add “verbatim” PlantUML extension | 2:07 | 2.5 | ||
| Comment out clang-cl windows build | 0:56 | 1.1 | ||
| Updates to the readme | 0:30 | 0.6 | ||
| Create a series of lectures on MDE and MASD | 9:36 | 11.3 | ||
| Setup the laptop for development | 3:07 | 3.7 | ||
| Update README with thesis info | 0:56 | 1.1 | ||
| Tests should take full generation into account | 1:11 | 1.4 | ||
| Gitter notifications for builds are not showing up | 0:14 | 0.3 | ||
| Update nightly builds to use new vcpkg setup | 7:52 | 9.3 | ||
| Assorted improvements to CMake files | 6:26 | 7.6 | ||
| Windows package is broken | 0:31 | 0.6 | ||
| Capitalise titles in models correctly | 0:06 | 0.1 | ||
| Add full and relative path processing to PM | 0:12 | 0.2 | ||
| Add support for relations in codec model | 0:54 | 1.1 | ||
| Consider standardising all templates as mustache templates | 0:21 | 0.4 |
Agenda:
(org-agenda-file-to-front)Add github release notes for previous sprint.
Release announcements:

_Municipal stadium in Moçamedes, Namibe. (C) 2020 [Administração Municipal De Moçâmedes](https://www.facebook.com/permalink.php?id=1473211179380654&story_fbid=3035581253143631)._
# Introduction
Happy new year! The first release of the year is a bit of a bumper one: we finally managed to add support for [org-mode](https://orgmode.org), and transitioned _all_ of Dogen to it. It was a mammoth effort, consuming the entirety of the holiday season, but it is refreshing to finally be able to add significant user facing features again. Alas, this is also a bit of a bitter-sweet release because we have more or less run out of coding time, and need to redirect our efforts towards writing the PhD thesis. On the plus side, the architecture is now up-to-date with the conceptual model, mostly, and the bits that aren't are fairly straightforward (famous last words). And this is nothing new; Dogen development has always oscillated between theory and practice. If you recall, a couple of years ago we had to take a nine-month coding break to learn about the theoretical underpinnings of [MDE](https://en.wikipedia.org/wiki/Model-driven_engineering) and then resumed coding on [Sprint 8](https://github.com/MASD-Project/dogen/releases/tag/v1.0.08) for what turned out to be a 22-sprint-long marathon (pun intended), where we tried to apply all that was learned to the code base. Sprint 30 brings this long cycle to a close, and begins a new one; though, this time round, we are hoping for far swifter travels around the literature. But I digress. Lets not get lost talking about the future, and focus instead on the release at hand. And _what_ a release it was.
# User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail.
[](https://youtu.be/ei8B1Pine34)
_Video 1: Sprint 30 Demo._
## Org-mode support
A target that we've been chasing for the longest time is the ability to create models using [org-mode](https://orgmode.org). We use org-mode (and [emacs](https://www.gnu.org/software/emacs)) for pretty much everything in Dogen, such time keeping and task management - it's how we manage our [product](https://github.com/MASD-Project/dogen/blob/master/doc/agile/product_backlog.org) and [sprint backlogs](https://github.com/MASD-Project/dogen/blob/master/doc/agile/v1/sprint_backlog_30.org), for one - and we'll soon be using it to write [academic papers](https://jonathanabennett.github.io/blog/2019/05/29/writing-academic-papers-with-org-mode/) too. It's just an amazing tool with a great tooling ecosystem, so it seemed only natural to try and see if we could make use of it for modeling too. Now, even though we are very comfortable with org-mode, this is not a decision to be taken lightly because we've been using [Dia](https://wiki.gnome.org/Apps/Dia) since Dogen's inception, over eight years ago.
_Figure 1: Dia diagram for a Dogen model with the introduction of colouring, Dogen [v1.0.06](https://github.com/MASD-Project/dogen/releases/tag/v1.0.06)_
As much as we profoundly love Dia, the truth is we've had concerns about relying on it _too much_ due to its [sparse maintenance](https://gitlab.gnome.org/GNOME/dia). In particular, Dia relies on an old version of GTK, meaning it could get pulled from distributions at any time; we've already had a similar experience with [Gnome Referencer](https://tracker.debian.org/news/937606/removed-122-2-from-unstable/), which wasn't at all pleasant. In addition, there are a number of "papercuts" that are mildly annoying, if livable, and which will probably not be addressed; we've curated a list of [such issues](https://github.com/MASD-Project/dogen/blob/master/doc/agile/v1/sprint_backlog_28.org#dia-limitations-that-impact-dogen-usage), in the hope of _one day_ fixing these problems upstream. The direction of travel for the maintenance is also not entirely aligned with our needs. For example, we recently saw the removal of python support in Dia - at least in the version which ships with Debian - a feature in which we relied upon heavily, and intended to do more so in the future. All of this to say that we've had a number of ongoing worries that motivated our decision to move away from Dia. However, I don't want to sound too negative here - and please don't take any of this as a criticism to Dia or its developers. Dia is an absolutely brilliant tool, and we have used it for over two decades; It is great at what it does, and we'll continue to use it for free modeling. Nonetheless, it has become increasingly clear that the directions of Dia and Dogen have started to diverge over the last few years, and we could not ignore that. I'd like to take this opportunity to give a huge thanks to all of those involved in Dia (past and present); they have certainly created an amazing tool that stood the test of time. Also, although we are moving away from Dia use in mainline Dogen, we will continue to support the Dia codec and we have tests to ensure that the current set of features [will continue to work](https://github.com/MASD-Project/frozen).
That's that for the rationale for moving away from Dia. But why org-mode? We came up with a nice laundry list of reasons:
- **"Natural" Representation**: org-mode documents are trees, with arbitrary nesting, which makes it a good candidate to represent the nesting of namespaces and classes. It's just a _natural_ representation for structural information.
- **Emacs tooling**: within the org-mode document we have full access to Emacs features. For example, we have spell checkers, regular copy-and-pasting, etc. This greatly simplifies the management of models. Since we already use Emacs for everything else in the development process, this makes the process even more fluid.
- **Universality**: org-mode is fairly universal, with support in [Visual Studio Code](https://github.com/vscode-org-mode/vscode-org-mode), [Atom](https://atom.io/packages/organized) and even [Vim](https://github.com/jceb/vim-orgmode) (for more details, see [Get started with Org mode without Emacs](https://opensource.com/article/19/1/productivity-tool-org-mode)). None of these implementations are as good as Emacs, of course - not that we are biased, or anything - but they are sufficient to at least allow for basic model editing. And installing a simple plugin in your editor of choice is much easier than having to learn a whole new tool.
- **"Plainer" plain-text**: org-mode documents are regular text files, and thus easy to life-cycle in a similar fashion to code; for example, one can version control and diff these documents very easily. Now, we did have Dia's files in uncompressed XML, bringing some of these advantages, but due to the verbosity of XML it was very hard to see the wood for the trees. Lots of lines would change every time we touched a model element - and I literally mean "touch" - making it difficult to understand the nature of the change. Bisection for example was not helped by this.
- **Models as documentation**: Dogen aims to take the approach of "Literate Modeling" described in papers such as [Literate Modelling - Capturing Business Knowledge with the UML](https://discovery.ucl.ac.uk/id/eprint/933/1/10.0_Literate_Modelling.pdf). It was clear from the start that a tool like Dia would not be able to capture the wealth of information we intended to add to the models. Org-mode on the other hand is the ideal format to bring disparate types of information together (see [Replacing Jupyter with Orgmode](https://rgoswami.me/posts/jupyter-orgmode) for an example of the sort of thing we have in mind).
- **Integration with org-babel**: Since models contain fragments of source code, org-mode's support for [working with source code](https://orgmode.org/manual/Working-with-Source-Code.html) will come in handy. This will immediately be really useful for handling text templates, and even more so in the future when we add support for code merging.
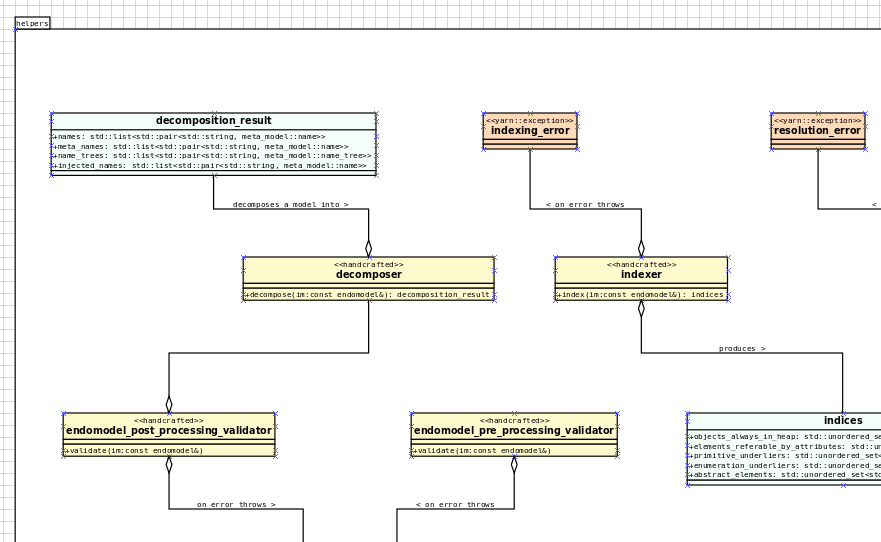
Over the past few sprints we've been carrying out a fair bit of experimentation on the side, generating org-mode files from the existing Dia models; it was mostly an exercise in feasibility to see if we could encode all of the required information in a comprehensible manner within the org-mode document. These efforts convinced us that this was a sensible approach, so this sprint we focused on adding end-to-end support for org-mode. This entailed reading org-mode documents, and using them to generate the exact same code as we had from Dia. Unfortunately, though [C++ support for org-mode exists](https://orgmode.org/worg/org-tools/index.html), we could not find any suitable library for integration in Dogen. So we decided to write a simple parser for org-mode documents. This isn't a "generic parser" by any means, so if you throw invalid documents at it, do expect it to blow up _unceremonially_. Figure 2 shows the ```dogen.org``` model represented as a org-mode document.

_Figure 2: ```dogen.org``` model in the org-mode representation._
We tried as much as possible to leverage native org-mode syntax, for example by using [tags](https://orgmode.org/manual/Tags.html) and [property drawers](https://orgmode.org/manual/Property-Syntax.html) to encode Dogen information. However, this is clearly a first pass and many of the decisions may not survive scrutiny. As always, we need to have a great deal of experience editing models to see what works and what does not, and it's likely we'll end up changing the markup in the future. Nonetheless, the guiding principle is to follow the "spirit" of org-mode, trying to make the documents look like "regular" org-mode documents as much as possible. One advantage of this approach is that the existing tooling for org-mode can then be used with Dogen models - for example, [org-roam](https://www.orgroam.com/), [org-ref](https://github.com/jkitchin/org-ref) _et al._ Sadly, one feature which we did not manage to achieve was the use of ```stitch-mode``` in the org-babel blocks. It appears there is some kind of incompatibility between org-mode and [polymode](https://github.com/polymode/polymode); more investigation is required, such as for instance playing with the interestingly named [poly-org](https://github.com/polymode/poly-org). As Figure 3 demonstrates, the stitch templates are at present marked as ```fundamental```, but users can activate stitch mode when editing the fragment.

_Figure 3: Stitch template in ```dogen.text``` model._
In order to make our life easier, we implemented conversion support for org-mode:
```
$ head dogen.cli.dia
<?xml version="1.0" encoding="UTF-8"?>
<dia:diagram xmlns:dia="http://www.lysator.liu.se/~alla/dia/">
<dia:diagramdata>
<dia:attribute name="background">
<dia:color val="#ffffffff"/>
</dia:attribute>
<dia:attribute name="pagebreak">
<dia:color val="#000099ff"/>
</dia:attribute>
<dia:attribute name="paper">
$ dogen.cli convert --source dogen.cli.dia --destination dogen.cli.org
$ head dogen.cli.org
#+title: dogen.cli
#+options: <:nil c:nil todo:nil ^:nil d:nil date:nil author:nil
#+tags: { element(e) attribute(a) module(m) }
:PROPERTIES:
:masd.codec.dia.comment: true
:masd.codec.model_modules: dogen.cli
:masd.codec.input_technical_space: cpp
:masd.codec.reference: cpp.builtins
:masd.codec.reference: cpp.std
:masd.codec.reference: cpp.boost
```
This feature was mainly added for our benefit, but it may also be useful for any users that wish to update their models from Dia to org-mode. We made use of conversion to migrate all of the Dogen core models into org-mode, including the library models - though these required a bit of manual finessing to get them into the right shape. We also performed a number of modeling tasks in the sprint using the new format and the work proceeded as expected; see the below sections for links to a video series on this subject. However, one thing we did notice is that we missed the ability to visualise models as UML diagrams. And that gives us a nice segway into the second major story of this sprint.
## Initial PlantUML support
Whilst the advantages of modeling using textual languages over graphical languages are patently obvious, the truth is the modeling process requires _both views_ in order to progress smoothly. Maybe its just me but I get a lot of information about a system very quickly just by looking at a well-curated class diagram. It is especially so when one does not touch a sub-system for extended periods of time; it only takes a few minutes to observe and absorb the structure of the sub-system by looking carefully at its class diagram. In Dogen, we have relied on this since the beginning, particularly because we need to context-switch in-and-out so often. With the move to org-mode we suddenly found ourselves unable to do so, and it was quite disorienting. So we decided to carry out yet another little experiment: to add basic support for [PlantUML](https://plantuml.com/). PlantUML is a textual notation that describes pretty much all types of UML diagrams, as well as a tool that converts files in that notation over to a graphical representation. The syntax is very simple and intuitive. Take for example one of the samples they supply:
```PlantUML
@startuml
Class11 <|.. Class12
Class13 --> Class14
Class15 ..> Class16
Class17 ..|> Class18
Class19 <--* Class20
@enduml
```
This very simple and compact notation produces the rather wonderful UML class diagram:

_Figure 4: UML Class Diagram generated from PlantUML sample. Source: [PlantUML site](https://plantuml.com/class-diagram)._
Given the notation is so straightforward, we decided to create a codec that outputs PlantUML documents, which can then be processed by their tool. To do so, simply convert the model:
```
$ dogen.cli convert --source dogen.cli.org --destination dogen.cli.plantuml
```
The listing below has a fragment of the output produced by Dogen; it contains the PlantUML representation of the ```dogen.org``` model from Figure 2.
```PlantUML
@startuml
set namespaceSeparator ::
note as N1
Provides support for encoding and decoding Emacs's org-mode
documents.
The support is very basic and focuses only on the features
of org mode required by Dogen.
end note
namespace entities #F2F2F2 {
class section #F7E5FF {
+{field} blocks std::list<block>
}
class document #F7E5FF {
+{field} affiliated_keywords std::list<affiliated_keyword>
+{field} drawers std::list<drawer>
+{field} section section
+{field} headlines std::list<headline>
}
<snip>
```
You can process it with PlantUML, to produce SVG output (or PNG, etc):
```
$ plantuml dogen.org.plantuml -tsvg
```
The SVG output is particularly nice because you can zoom in and out as required. It is also rendered very quickly by the browser, as attested by Figure 5.

_Figure 5: ```dogen.org``` SVG representation, produced by PlantUML._
While it was fairly straightforward to add _basic_ PlantUML support, the diagrams are still quite far from the nice orderly representations we used to have with Dia. They are definitely an improvement on not having any visual representation at all, mind you, but of course given our OCD nature, we feel compeled to try to get them as close as possible to what we had before. In order to do so we will have to do some re-engineering of the codec model and bring in some of the information that lives in the logical model. In particular:
- generalisation parsing so that we can depict these relationships in the diagram; this is actually quite tricky because some of the information may live on profiles.
- some level of resolution: all intra-model types must be resolved in order to support associations.
These changes will have to remain on the work stack for the future. For now the diagrams are sufficient to get us going, as Figures 5 and 6 demonstrate. Finally, its also worthwhile pointing out that PlantUML has [great integration with Emacs](https://github.com/skuro/plantuml-mode) and with org-mode in particular, so in the future it is entirely possible we could "inject" a graphical representation of model elements into the model itself. Clearly, there are many possibilities to explore here, but for now these remain firmly archived in the "future directions" section of the product backlog.

_Figure 6: PlantUML representation of ```dogen.profiles``` model._
### Add support for reference directories
With this release we also managed to add another feature which we have been pinning for: the ability to have models in multiple directories. A new command line parameter was added: ```--reference-directory```.
```
[marco@lovelace dia]$ /work/DomainDrivenConsulting/masd/dogen/integration/build/output/clang11/Release/stage/bin/dogen.cli generate --help
Dogen is a Model Driven Engineering tool that processes models encoded in supported codecs.
Dogen is created by the MASD project.
Displaying options specific to the generate command.
For global options, type --help.
Generation:
-t [ --target ] arg Model to generate code for, in any of the
supported formats.
-o [ --output-directory ] arg Output directory for the generated code.
Defaults to the current working directory.
-r [ --reference-directory ] arg One or more directories to check for
referenced models.
[marco@lovelace dia]$
```
Users can supply directories containing their models and Dogen will check those directories when resolving references. This means you no longer need to keep all your models in a big jumble on the same directory, but should instead start to keep them together with the code they generate. We used this feature in Dogen to separate the old ```dogen.models``` directory, and created a number of ```modeling``` directories where all the content related to modeling for a given component will be placed. For example, see the ```dogen.org``` [modeling directory](https://github.com/MASD-Project/dogen/tree/master/projects/dogen.org/modeling):
```
$ ls -l
total 76
-rw-r--r-- 1 marco marco 3527 2021-01-02 12:37 CMakeLists.txt
-rw-r--r-- 1 marco marco 10360 2021-01-03 17:36 dogen.org.org
-rw-r--r-- 1 marco marco 3881 2021-01-03 13:53 dogen.org.plantuml
-rw-r--r-- 1 marco marco 60120 2021-01-03 13:54 dogen.org.svg
```
# Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log. As usual, for all the gory details of the work carried out this sprint, see [the sprint log](https://github.com/MASD-Project/dogen/blob/master/doc/agile/v1/sprint_backlog_30.org).
## Milestones and Ephemerides
This sprint saw the 13,000th commit to Dogen.
_Figure 7_: Commit number 13,000th was made to the Dogen GitHub repository.
## Significant Internal Stories
This sprint had two key goals, both of which were achieved: org-mode and PlantUML support. These were described in the user facing stories above. In this section we shall provide more details about how this work was organised, as well as other stories which were not user facing.
### Org-mode work
The following stories were required to bring about org-mode support:
- **Add support for reading org mode documents**: creation of an org-mode parser, as well as a model to represent the types of this domain.
- **Add org-mode codec for input**: story to plug in the new org-mode parser into the codec framework, from an input perspective.
- **Create a model to org transform**: output side of the work; the addition of a transform which takes a Dogen model and generates an org-mode document.
- **Add tags to org model**: originally we tried to infer the element's meta-type by its position (e.g. package, "regular" element, attribute). However, it soon became obvious this was not possible and we ended up having to add org tags to perform this work. A story related to this one was also **Assorted improvements to org model**, where we sorted out a small number of papercuts with the org documents.
- **Consider replacing properties drawer with tables**: an attempt to use org-mode tables instead of property drawers to represent meta-data. We had to cancel the effort as we could not get it to work before the end of the sprint.
- **Convert library models into org**: we spent a fair bit of time in converting all of the JSON models we had on our library into org-mode. The automatic conversion worked fairly well, but it was missing some key bits which had to be added manually.
- **Convert reference models into org**: similarly to the library models, we had to convert all of Dogen's models into org-mode. This also includes the work for [C++](https://github.com/MASD-Project/cpp_ref_impl/tree/master/projects/cpp_ref_impl.models/org) and [C#](https://github.com/MASD-Project/csharp_ref_impl/tree/master/Src/CSharpRefImpl.Models/org) reference models. We managed to use the automatic conversion for all of these, after a fair bit of work on the conversion code.
- **Create a "frozen" project**: although we were moving away from Dia, we did not want the existing support to degrade. The Dia Dogen models are an exacting test in code generation, which add a lot of value. There has always been an assumption that these would be a significant part of the code generator testing suite, but what we did not anticipate is that we'd move away from using a "core" codec such as Dia. So in order not to lose all of the testing infrastructure we decided to create a ["frozen" version of Dogen](https://github.com/MASD-Project/frozen), which in truth is not completely frozen, but contains a faithful representation across all supported codecs of the Dogen models at that point in time. With Frozen we can guarantee that the JSON and Dia support will not be any worse for all the features used by Dogen at the time the snapshot was taken.
- **Remove JSON and Dia models for Dogen**: once Frozen was put in place, we decommissioned all of the existing Dia and JSON models within Dogen. This caused a number of breaks which had to be hunted down and fixed.
- **Add org-to-org tests** and **Analysis on org mode round-tripping**: we added a "special" type of round-tripping: the org-to-org conversion. This just means we can read an org-mode document and then regenerate it without introducing any differences. It may sound quite tautological, but it has its uses; for example, we can introduce new features to org documents by adding it to the output part of the transform chain and then regenerating all documents. This was useful several times this sprint. It will also be quite useful in the future, when we integrate with external tooling; we will be able to append data to user models without breaking any of the user content (hopefully).
- **Inject custom IDs into org documents**: we tried not to have an identifier in org-mode documents for each element, but this caused problems when recreating the topology of the document. We had to use our org-to-org transform to inject ```custom_id``` (the org-mode attribute [used for this purpose](https://writequit.org/articles/emacs-org-mode-generate-ids.html)), though some had to be injected manually.
### Whitespace handling
Whilst it was introduced in the context of the org-mode, the changes to the handling of whitespace are a veritable epic in its own right. The problem was that in the past we wanted to preserve whitespace as supplied by the user in the original codec model; however, if we did this for org-mode documents, we would end up with very strange looking documents. So instead we decided to trim leading and trailing whitespace for all commentary. It took a while to get it to work such that the generated code had no differences, but this approach now means the org-mode documents look vaguely sensible, as does the generated code. The following stories were involved in adding this feature:
- **Move documentation transform to codec model**: for some reason we had decided to place the documentation trimming transform in the logical model. This made things a lot more complicated. In this sprint we moved it into the codec model, which greatly simplified the transform.
**Stitch templates are consuming whitespace**: this was a bit of a wild-goose chase. We thought the templates were some how causing problems with the spacing, but in the end it was just to do with how we trim different assets. Some hackery was required to ensure text templates are correctly terminated with a new line.
- **Remove leading and trailing new lines from comments**: the bulk of the work where we trimmed all commentary.
- **Allow spaces in headlines for org mode documents**: to make org-mode documents more readable, we decided to allow the use of spaces in headlines. These get translated to underscores as part of the processing. It is possible to disable this translation via the not-particularly-well-named key ```masd.codec.preserve_original```. This was mainly required for types such as ```unsigned int``` and the like.
### PlantUML work
There were a couple of stories involved in adding this feature:
- **Add PlantUML markup language support**: the main story that added the new codec. We also added CMake targets to generate all models.
- **Add comments to PlantUML diagrams**: with this story we decided to add support for displaying comments in modeling elements. It is somewhat experimental, and its look and feel is not exactly ideal, but it does seem to add some value. More work on the cosmetics is required.
### Smaller stories
A number of smaller stories was also worked on:
- **Merge dia codec model into main codec model**: we finally got rid of the Dia "modelet" that we have been carrying around for a few sprints; all of its code has now been refactored and placed in the ```dogen.codec``` model, as it should be.
- **Split orchestration tests by model and codec**: our massive file containing all code generation tests was starting to cause problems, particularly with treemacs and lsp-mode in emacs. This story saw the monster file split into a number of small files, organised by codec and product.
- **Add missing provenance details to codec models**: whilst trobuleshooting an issue we noticed that the provenance details had not been populated correctly at the codec level. This story addresses this shortcoming and paves the way for GCC-style errors, which will allow users to be taken to the line in the org-document where the issue stems from.
### Video series of Dogen coding
This sprint we recorded some videos on the implementation of the org-mode codec, and the subsequent use of these models. The individual videos are listed on Table 2, with a short description. They are also available as a playlist, as per link below.
[](https://www.youtube.com/playlist?list=PLwfrwe216gF0wdVhy4fO1_QXJ-njWLSy4)
_Video 2: Playlist "MASD - Dogen Coding: Formatables Refactor"._
|Video | Description |
|---------|-----------------|
| [Part 1](https://youtu.be/xfJNJ_9uAGU) | In this part we provide context about the current task and start off by doing some preliminary work setting up the required infrastructure.|
| [Part 2](https://youtu.be/HueypBCfwIM) | In this video we review the work done to process org mode documents, and start coding the codec transform. However, we bump into a number of problems.|
| [Part 3](https://youtu.be/QE7P9s-8Xg0) | In this video we review the work done to get the org codec to generate files, and analyse the problems we're having at present, likely related to errors processing profiles.|
| [Part 4](https://youtu.be/I-PkSHkpwhI) | In this video we review the work done offline to implement the basic support for reading org-mode documents and start the work to write org mode documents using our org model.|
| [Part 6](https://youtu.be/ZfpqC9PuEog) | In this part we review the round-trip work made to support org mode, and refactor the tags used in org models. We also add support for org custom IDs.|
| [Part 7](https://youtu.be/6XDt7lV0k_k) | Addendum video where we demonstrate the use of the new org mode models in a more expansive manner.|
| [Part 8](https://youtu.be/6wqsbT-jG6Y) | In this second addendum we work on the org-to-org transform, solving a number of issues with whitespacing.|
| [Part 9](https://youtu.be/GvsI7IGk5sY) | In this video we try to explore moving away from properties to represent meta-data and using tables instead, but we run into a number of difficulties and end up spending most time fixing bugs related to element provenance.|
## Resourcing
As you can see from the lovely spread of colours of the pie chart, our story-keeping this sprint was much healthier than usual; the biggest story took 24.3% which is also a great sign of health. Our utilisation rate was also the highest since records began, at 70%, and a marked improvement over the measly 35% we clocked last sprint. To be fair, that is mainly an artefact of the holiday season more than anything else, but who are we to complain - one is always happy when the numbers are going in the right direction, regardless of root cause. On the less positive front, we spent around 16.2% on activities that were not related to our core mission - a sizable increase from the 11% last time round, with the main culprit being the 4.5% spent on addressing Emacs issues (including some [low-level elisp investigations](https://github.com/Alexander-Miller/treemacs/issues/752)). On the plus side, we did make a few nice changes to our Emacs setup, which will help with productivity, so its not just sunk costs. Predictably, the _circa_ 84% dedicated to "real work" was dominated by org-mode stories (~54%), with PlantUML coming in at a distant second (7%). All and all, it was a model sprint - if you pardon the pun - from a resourcing perspective.

_Figure 8_: Cost of stories for sprint 30.
## Roadmap
The road map has been working like clockwork for the last few sprints, with us ticking stories off as if it was a mere list - clearly no longer the Oracle of Delphi it once was - and this sprint was no exception. Were we to be able to continue with the same release cadence, the next sprint would no doubt also tick off the next story on our list. Alas, we have ran out of coding time, so Sprint 31 will instead be very long running sprint, with very low utilisation rate. In addition, we won't bother creating sprints when the work is completely dedicated to writing; instead, regular service will resume once the writing comes to an end.


# Binaries
You can download binaries from either [Bintray](https://bintray.com/masd-project/main/dogen/1.0.30) or [GitHub](https://github.com/MASD-Project/dogen/releases/tag/v1.0.30), as per Table 3. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in [zip](https://github.com/MASD-Project/dogen/archive/v1.0.30.zip) or [tar.gz](https://github.com/MASD-Project/dogen/archive/v1.0.30.tar.gz) format.
| Operative System | Format | BinTray | GitHub |
|----------|-------|-----|--------|
|Linux Debian/Ubuntu | Deb | [dogen_1.0.30_amd64-applications.deb](https://dl.bintray.com/masd-project/main/1.0.30/dogen_1.0.30_amd64-applications.deb) | [dogen_1.0.30_amd64-applications.deb](https://github.com/MASD-Project/dogen/releases/download/v1.0.30/dogen_1.0.30_amd64-applications.deb) |
|Windows | MSI | [DOGEN-1.0.30-Windows-AMD64.msi](https://dl.bintray.com/masd-project/main/DOGEN-1.0.30-Windows-AMD64.msi) | [DOGEN-1.0.30-Windows-AMD64.msi](https://github.com/MASD-Project/dogen/releases/download/v1.0.30/DOGEN-1.0.30-Windows-AMD64.msi) |
_Table 3: Binary packages for Dogen._
**Note 1:** The Linux binaries are not stripped at present and so are larger than they should be. We have [an outstanding story](https://github.com/MASD-Project/dogen/blob/master/doc/agile/product_backlog.org#linux-and-osx-binaries-are-not-stripped) to address this issue, but sadly CMake does not make this a trivial undertaking.
**Note 2:** Due to issues with Travis CI, we did not manage to get OSX to build, so and we could not produce a final build for this sprint. The situation with Travis CI is rather uncertain at present so we may remove support for OSX builds altogether next sprint.
# Next Sprint
The goals for the next sprint are:
- to implement path and dependencies via PMM.
That's all for this release. Happy Modeling!Time spent creating the demo and presentation.
Marco Craveiro Domain Driven Development Released on 5th January 2021
At present a number of tests are failing. These are mainly due to org-mode rountripping and spacing.
Differences found. Outputting head of first 5 diffs.
diff -u include/dogen.identification/types/identification.hpp include/dogen.identification/types/identification.hpp
Reason: Changed generated file.
--- include/dogen.identification/types/identification.hpp
+++ include/dogen.identification/types/identification.hpp
@@ -26,12 +26,7 @@
#endif
/**
- * @brief Collection of types related to naming, labelling and general
- * identification within Dogen.
- *
- * UML representation:
- *
- * \image html dogen.identification/modeling/dogen.identification.svg
+ * @brief \image html dogen.identification/modeling/dogen.identification.svg
*/
namespace dogen::identification {
}
../../../../projects/dogen.orchestration/tests/dogen_org_product_tests.cpp(178): error: in "dogen_product_org_tests/dogen_identification_org_produces_expected_model": check mg::check_for_differences(od, m) has failed
Conversion generated differences: "/work/DomainDrivenConsulting/masd/dogen/integration/projects/dogen/modeling/dogen.org"
@@ -494,3 +494,4 @@
:END:
An error ocurred when dumping dogen's specs.
+
../../../../projects/dogen.orchestration/tests/dogen_org_product_tests.cpp(188): error: in "dogen_product_org_tests/dogen_org_conversion_has_no_diffs": check diff.empty() has failed
Conversion generated differences: "/work/DomainDrivenConsulting/masd/dogen/integration/projects/dogen.cli/modeling/dogen.cli.org"
@@ -181,3 +181,4 @@
:END:
Which style to use when dumping the specs.
+
../../../../projects/dogen.orchestration/tests/dogen_org_product_tests.cpp(202): error: in "dogen_product_org_tests/dogen_cli_org_conversion_has_no_diffs": check diff.empty() has failed
Conversion generated differences: "/work/DomainDrivenConsulting/masd/dogen/integration/projects/dogen.logical/modeling/dogen.logical.org"
@@ -4668,3 +4668,4 @@
:END:
An error has occurred while formatting.
+
../../../../projects/dogen.orchestration/tests/dogen_org_product_tests.cpp(244): error: in "dogen_product_org_tests/dogen_logical_org_conversion_has_no_diffs": check diff.empty() has failed
Conversion generated differences: "/work/DomainDrivenConsulting/masd/dogen/integration/projects/dogen.identification/modeling/dogen.identification.org"
@@ -12,6 +12,7 @@
:masd.codec.reference: dogen.profiles
:masd.variability.profile: dogen.profiles.base.default_profile
:END:
+
\image html dogen.identification/modeling/dogen.identification.svg
* entities :module:
../../../../projects/dogen.orchestration/tests/dogen_org_product_tests.cpp(286): error: in "dogen_product_org_tests/dogen_identification_org_conversion_has_no_diffs": check diff.empty() has failed
Updates to sprint and product backlog.
Travis is no longer supported, nor is bintray. We should move our CI pipeline to GitHub.
Links:
- reddit: GitHub action to set vcpkg up and cache it
- build-vcpkg: example vcpkg.
Merged stories:
Consider moving CI to GitHub Actions
At present we are using Travis and AppVeyor for our CI. However, it would be nice to have a single place with all of the CI (and even more ideally, packaging as well). GitHub seems to offer some kind of CI support via GitHub actions. However, we need to first move to building on docker.
Actually it seems we don’t even need to do very much. See this article.
Links:
- Github Actions, C++ with Boost and cmake, almost a 50% speedup with caching
- libdtl-dev: dependency available on debian now.
- quantlib GH: support for all operative systems (OSX, Win, Linux) as well as a number of interesting actions.
We need to get latest vcpkg locally and update all dependencies.
Links:
We need to simplify our third party packages story:
- remove relational support: Since we do not make use of ODB at present we probably could remove support altogether.
- remove boost-di: we only use this in a very limited manner, but because of it we need to carry our own vcpkg patches.
- deprecate MASD fork of vcpkg.
As part of the move to github we should drop all of the legacy files. This also includes the old build scripts from the shell.
At present we cannot build using clang. The main issue seems to be that dogen code is using libc++ whereas the vcpkg dependencies are using the GCC standard library. For now we can default to GCC’s library and create a new story to use clangs.
We need to re-write our existing CTest script to make it fit the GitHub actions approach and integrate it with the lukka scripts.
Links:
- 23383: CTest: Integrating dashboards and Github Actions
- #73: Integrating CMake actions with CDash and CTest
Previous understanding
At present we are not running the tests in github actions.
Notes:
- at present it seems the only advantage of the lukka cmake scripts is the setting up of the VCPKG caching.
We removed the relational model, but the options are still in the help.
Rationale: we’ve got the basics working, with badge and manual uploading of docs to the site. Create a new story for integrating this with CI.
Now we have a site, we could add the doxygen docs to it.
Notes:
- consider adding links in the source code to the PlantUML diagrams so that they come out in doxygen.
- add badge for documentation. Example:
[]- add SVG of models to the docs.
Links:
- doxygen-awesome-css: “Doxygen Awesome is a custom CSS theme for doxygen html-documentation with lots of customization parameters.W
- Dogen documentation
- reddit: dxoygen (sic.) awesome css : make your doxygen docs looking more modern
- GH issue: Creating a link to the dark theme: opened a ticket about adding a link to the dark theme version.
- Example doxygen badge
- doxygen: IMAGE_PATH
- doxygen: /image
We should really create packages for all builds. We need to also check that when we tag we create packages.
Notes:
- we are packaging but we can’t see the resulting files. Perhaps they only appear at the end of the workflow?
Notes:
- At present the Windows build seems to be using a mix of Ming and MSVC (but failing to find MSVC). We need to make sure both vcpkg and the build use MSVC.
- debug build has a config type of release. Use the release type consistently in case its causing other problems. Done.
- ccache is not creating the cache correctly on windows. Seems to work for MSVC now but not clang-cl. However, we never had a green build so that may be related. Wait until we have one to re-access.
- debug build was breaking due to use of ccache. Removed this for MSVC builds.
Links:
In the past, --version showed the commit details etc from CI builds. It seems
that is no longer working.
We should only support VCPKG builds now. Update docs.
Its not obvious why this build is failing. llvm-cov is probably returning
non-zero.
This was resolved by capturing the coverage exit status.
We still have lots of IDs in models from Dia:
:PROPERTIES: :custom_id: O65 :END:
We need to update these to use UUIDs.
We can probably install debian packages in GitHub CI. Try to see if we can run the old package test scripts in GitHub.
At present we have tests that just convert from one codec to another but are located in orchestration. These tests should live in the codec component.
Also, add tests for PlantUML.
One very simple way to improve diagrams is to allow users to associate a fragment of PlantUML code with a class, for example:
masd.codec.plantuml: myclass <>-- other_class : test
This fragments are added after the class, verbatim. Its up to the users to annotate diagrams as they see fit, we merely copy and paste these annotations.
In the future, we may spot patterns of usage that can be derived from meta-data, but for now we just need the diagrams to be usable like they were in Dia.
Notes:
- notes are not indented at present.
- we are not leaving a space after inheritance.
- empty classes still have brackets.
- no top-level namespace for model. We didn’t have this in Dia either.
Tasks:
- add new feature in codec model.
- add properties in model and element to store the data.
- when converting into PlantUML, output the new properties after dumping the class.
- move codec to codec tests from orchestration to codec component.
- codec needs to have a way to bootstrap its context without requiring orchestration.
Conclusions:
- we’ve implemented this functionality and it does indeed do much of the work as expected. We can probably leave it as-is, but for its main use case its not ideal. This is because we already have most of the required information in the form of model data, its just not organised in a good way. Instead what we need to do is to model relationships correctly at codec level and use these to express the PlantUML relationships. We also need to allow users to manually add more relationships. This will be captured in a separate story.
We are failing to link:
lld-link: error: undefined symbol: __declspec(dllimport) public: void __cdecl boost::archive::archive_exception::`vbase dtor'(void)
For now, comment out clang-cl build. Created story in backlog to deal with this properly.
After the vcpkg update we ended up with some inconsistencies in the readme. Fix those.
In preparation for the viva, we need to review all of our research material. Record a series of lectures on MASD as preparation.
Links:
- MASD: An introduction to Model Assisted Software Development: youtube playlist.
We need to move to the new vcpkg setup, with latest clang and gcc.
Now that we have finished the thesis, we need to update references to it in README.
At present tests for Dogen are respecting the requested features in each model, i.e. we only generate the requested facets. However, for nightlies we have an override to generate all possible facets. This means that tests would fail if we tried to compare generated code against what is in the Dogen repo. This results in special cases for the nightly build. However, if somehow we could get the tests to respect the override, then we would not need a pristine directory for comparisons, making nightlies a less special case.
We used to see travis and appveyor build notifications. We stopped seeing them after moving to github actions. This is useful because we can see them from Emacs in IRC.
Notes:
- it seems the settings have an option for this in webhooks. Redo the hook to see if it helps.
Links:
At present we are still relying on the old vcpkg setup, with downloads from dropbox etc. We need to move to the new world of presets.
Notes:
- update the compiler versions (e.g.
clang9-Linux-x86_64-Debug, etc). - we are using the old CTest script.
- bypass presets altogether, set everything up manually. Actually this is not
quite that simple because we are using the same script for continuous builds.
Simpler way:
- supply a “build id”. Detect all parameters from build ID.
- supply a flag “use presets”. If true, use the build id as the preset. Otherwise, rely on the environment.
- actually there are several approaches we can take for this:
- supply all parameters on a preset name but call it “build name” since that is the CDash nomenclature. Also supply a flag to determine if one is to use presets or not. This should solve the impedance mismatch between nightlies, continuous and local dev.
- alternatively, use the build name as-is and split/parse it inside CMake
script. This means less parameters to supply, e.g.:
export cmake_args="model=Continuous,preset=${preset},configuration=${{matrix.buildtype}}"We could just supply one parameter.
- use symlinks in nightly to simulate directory layout. However, not clear how we would solve the “dogen pristine” problem.
- we can’t use presets at all because they have:
WITH_FULL_GENERATION="OFF"We need to set this to on.
include(CheckIPOSupported)
check_ipo_supported(RESULT result)
if(result)
set_target_properties(foo PROPERTIES INTERPROCEDURAL_OPTIMIZATION TRUE)
endif()
LINK_WHAT_YOU_USE
set(CMAKE_CXX_CLANG_TIDY "clang-tidy" "-checks=*")
<LANG>_CLANG_TIDY: CMake 3.6+
<LANG>_CPPCHECK
<LANG>_CPPLINT
<LANG>_INCLUDE_WHAT_YOU_USE
install(TARGETS MyLib
EXPORT MyLibTargets
LIBRARY DESTINATION lib
ARCHIVE DESTINATION lib
RUNTIME DESTINATION bin
INCLUDES DESTINATION include
)Previous understanding
It seems we are not using proper CMake idioms to pick up compiler features, as explained here:
- Modern CMake for Library Developers
- An Introduction to Modern CMake
- CMake - Introduction and best practices
- Building Science with CMake
- CXP: C++ Cross Platform: A template project for creating a cross platform C++ CMake project using modern CMake syntax and transitive dependencies.
- CGold: The Hitchhiker’s Guide to the CMake
- Polly: Collection of CMake toolchains
- GH cmake_modules: “This repository provides a wide range of CMake helper files.”
We need to implement this using proper CMake idioms.
Notes:
- Add version and language to project.
- start using target compile options for each target. We will have to repeat the same flags; this could be avoided by passing in a variable. See also What is the modern method for setting general compile flags in CMake?
- define qualified aliases for all libraries, including nested aliasing for
dogen::test_models. Ensure all linking is done against qualified names. - use target include directories for each target and only add the required
include directories to each target. Mark them with the appropriate visibility,
including using
interface. We should then remove all duplication of libraries in the specs. - try replacing calls to
-std=c++-14with compiler feature detection. We need to create a list of all C++-14 features we’re using. - remove all of the debug/release compilation options and start using
CMAKE_BUILD_TYPEinstead. See this example. We added build type support to our builds, but as a result, the binaries moved fromstage/bintobin. There is no obvious explanation for this. - remove
STATICon all libraries and let users specify which linkage to use. We already have a story to capture this work. - remove the stage folder and use the traditional CMake directories. This will also fix the problems we have with BUILD_TYPE.
- consider buying the CMake book: https://crascit.com/professional-cmake/.
Merged stories:
Usage of external module path in cmakelists :story:
It seems like we are not populating the target names properly. Originally the target name for test model all built-ins was:
dogen_all_builtins
When we moved the test models into test_models the target name did
not change. It should have changed to:
dogen_test_models_all_builtins
When we install the windows package under wine, it fails with:
E0fc:err:module:import_dll Library boost_log-vc143-mt-x64-1_78.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe") not found 00fc:err:module:import_dll Library boost_filesystem-vc143-mt-x64-1_78.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe") not found 00fc:err:module:import_dll Library boost_program_options-vc143-mt-x64-1_78.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe") not found 00fc:err:module:import_dll Library libxml2.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe") not found 00fc:err:module:import_dll Library boost_thread-vc143-mt-x64-1_78.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe") not found 00fc:err:module:LdrInitializeThunk Importing dlls for L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe" failed, status c0000135
This will probably be fixed when we move over to the new way of specifying dependencies in CMake. Do that first and revisit this problem.
Actually, this did not help. We then used the new VCPKG macro (see links) which now includes all of boost. We are failing on:
00fc:err:module:import_dll Library MSVCP140_CODECVT_IDS.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\boost_log-vc143-mt-x64-1_78.dll") not found 00fc:err:module:import_dll Library boost_log-vc143-mt-x64-1_78.dll (which is needed by L"C:\\Program Files\\DOGEN\\bin\\dogen.cli.exe") not found
Links:
- CMake: provide option to deploy DLLs on install() like VCPKG_APPLOCAL_DEPS #1653
- InstallRequiredSystemLibraries MSVCP140.dll is missing
- InstallRequiredSystemLibraries purpose
We still have models with lower case titles:
* initializer :element:
Capitalise these correctly.
When we tried to do this to the dogen model, generation failed with the following error:
Error: Object has attribute with undefined type: spec_category
We are probably not normalising to lower case.
In addition
Merged stories:
Capitalise model headers correctly
At present most models still use the “all lower case” notation, copied from Dia. We need to capitalise headers correctly so that when we generate documentation they come out correctly.
We need to be able to generate full paths in the PM. This will require access to the file extensions. For this we will need new decoration elements. This must be done as part of the logical model to physical model conversion. While we’re at it, we should also generate the relative paths. Once we have relative paths we should compute the header guards from them. These could be generalised to “unique identifiers” or some such general name perhaps. That should be a separate transform.
Notes:
- we are not yet populating the archetype kind in archetypes so we cannot locate the extensions. Also we did not create all of the required archetype kinds in the text models. The populating should be done via profiles.
- we must first figure out the number of enabled backends. The meta-model properties will always contain all backends, but not all of them are enabled.
- we need to populate the part directories. For this we need to know what parts are available for each backend (PMM), and then ensure the part properties have been created. We also need a directory for the part in variability. It is not clear we have support for this in the template instantiation domains - we probably only have backend, facet, archetype.
- guiding principle: there should be a direct mapping between the two hierarchical spaces: the definition meta-model of the physical space and its instances in the file-system.
Merged stories:
Map archetypes to labels
We need to add support in the PMM for mapping archetypes to labels. We may need to treat certain labels more specially than others - its not clear. We need a container with:
- logical model element ID
- archetype ID
- labels
Implement locator in physical model
Use PMM entities to generate artefact paths, within m2t.
Create a archetypes locator
We need to move all functionality which is not kernel specific into yarn for the locator. This will exist in the helpers namespace. We then need to implement the C++ locator as a composite of yarn locator.
Other Notes
At present we have multiple calls in locator, which are a bit ad-hoc. We could potentially create a pattern. Say for C++, we have the following parameters:
- relative or full path
- include or implementation: this is simultaneously used to determine the placement (below) and the extension.
- meta-model element:
- “placement”: top-level project directory, source directory or “natural” location inside of facet.
- archetype location: used to determine the facet and archetype postfixes.
E.g.:
make_full_path_for_enumeration_implementation
Interestingly, the “placement” is a function of the archetype location (a given artefact has a fixed placement). So a naive approach to this seems to imply one could create a data driven locator, that works for all languages if supplied suitable configuration data. To generalise:
- project directory is common to all languages.
- source or include directories become “project sub-directories”. There is a mapping between the artefact location and a project sub-directory.
- there is a mapping between the artefact location and the facet and artefact postfixes.
- extensions are a slight complication: a) we want to allow users to override header/implementation extensions, but to do it so for the entire project (except maybe for ODB files). However, what yarn’s locator needs is a mapping of artefact location to extension. It would be a tad cumbersome to have to specify extensions one artefact location at a time. So someone has to read a kernel level configuration parameter with the artefact extensions and expand it to the required mappings. Whilst dealing with this we also have the issue of elements which have extension in their names such as visual studio projects and solutions. The correct solution is to implement these using element extensions, and to remove the extension from the element name.
- each kernel can supply its configuration to yarn’s locator via the kernel interface. This is fairly static so it can be supplied early on during initialisation.
- there is still something not quite right. We are performing a mapping between some logical space (the modeling space) and the physical space (paths in the filesystem). Some modeling elements such as the various CMakeLists.txt do not have enough information at the logical level to tell us about their location; at present the formatter itself gives us this hint (“include cmakelists” or “source cmakelists”?). It would be annoying to have to split these into multiple archetypes just so we can have a function between the archetype location and the physical space. Although, if this is the only case of a modeling element not mapping uniquely, perhaps we should do exactly this.
- However, we still have inclusion paths to worry about. As we done with the source/include directories, we need to somehow create a concept of inclusion path which is not language specific; “relative path” and “requires relative path” perhaps? These could be a function of archetype location.
Merged stories:
Generate file paths as a transform
We need to understand how file paths are being generated at present; they should be a transform inside generation.
Create the notion of project destinations
At present we have conflated the notion of a facet, which is a logical concept, with the notion of the folders in which files are placed - a physical concept. We started thinking about addressing this problem by adding the “intra-backend segment properties”, but as the name indicates, we were not thinking about this the right way. In truth, what we really need is to map facets (better: archetype locations) to “destinations”.
For example, we could define a few project destinations:
masd.generation.destination.name="types_headers" masd.generation.destination.folder="include/masd.cpp_ref_impl.northwind/types" masd.generation.destination.name=top_level (global?) masd.generation.destination.folder="" masd.generation.destination.name="types_src" masd.generation.destination.folder="src/types" masd.generation.destination.name="tests" masd.generation.destination.folder="tests"
And so on. Then we can associate each formatter with a destination:
masd.generation.cpp.types.class_header.destination=types_headers
Notes:
- these should be in archetypes models.
- with this we can now map any formatter to any folder, particularly if this is done at the element level. That is, you can easily define a global mapping for all formatters, and then override it locally. This solves the long standing problem of creating say types in tests and so forth. With this approach you can create anything anywhere.
- we need to have some tests that ensure we don’t end up with multiple files with the same name at the same destination. This is a particular problem for CMake. One alternative is to allow the merging of CMake files, but we don’t yet have a use case for this. The solution would be to have a “merged file flag” and then disable all other facets.
- this will work very nicely with profiles: we can create a few out of the box
profiles for users such as flat project, common facets and so on. Users can
simply apply the stereotype to their models. These are akin to “destination
themes”. However, we will also need some kind of “variable replacement” so we
can support cases like
include/masd.cpp_ref_impl.northwind/types. In fact, we also have the same problem when it comes to modules. A proper path is something like:include/${model_modules_as_dots}/types/${internal_modules_as_folders}include/${model_modules_as_dots}/types/${internal_modules_as_dots}.include/${model_modules_as_dots}/types/${internal_modules_as_underscores}_
This is extremely flexible. The user can now create a folder structure that depends on package names etc or choose to flatten it and can do so for one or all facets. This means for example that we could use nested folders for
include, not use model modules forsrcand then flatten it all fortests. - actually it is a bit of a mistake to think of these destinations as purely physical. In reality, we may also need them to contribute to namespaces. For example, in java the folders and namespaces must match. We could solve this by having a “module contribution” in the destination. These would then be used to construct the namespace for a given facet. Look for java story on backlog for this.
- this also addresses the issue of having multiple serialisation formats and
choosing one, but having sensible folder names. For example, we could have
boost serialisation mapped to a destination called
serialisation. Or we could map it to say RapidJSON serialisation. Or we could support two methods of serialisation for the same project. The user chooses where to place them.
One very simple way to improve diagrams is to allow users to associate a fragment of PlantUML code with a class, for example:
masd.codec.plantuml: myclass <>-- other_class : test
This fragments are added after the class, verbatim. Its up to the users to annotate diagrams as they see fit, we merely copy and paste these annotations.
In the future, we may spot patterns of usage that can be derived from meta-data, but for now we just need the diagrams to be usable like they were in Dia.
Notes:
- notes are not indented at present.
- we are not leaving a space after inheritance.
- empty classes still have brackets.
- no top-level namespace for model. We didn’t have this in Dia either.
Tasks:
- add new feature in codec model.
- add properties in model and element to store the data.
- when converting into PlantUML, output the new properties after dumping the class.
- move codec to codec tests from orchestration to codec component.
- codec needs to have a way to bootstrap its context without requiring orchestration.
At present we have a somewhat complex story with regards to templating:
- we use a mustache-like approach called wale, built in-house. It is used for some header files such as the M2T transforms.
- we use a t4-like approach called stitch, also in-house. It is used for the implementation of the M2T transforms.
What would be really nice is if we could use the same approach for both, and if that approach was not part of Dogen. The purpose of this story is to explore the possibility of replacing both with a standard implementation of mustache, ideally available on vcpkg. We already have a story for replacing wale with mustache in the backlog, so see that for the choice of implementation. This story concerns itself mainly with the second item in the above list; that is, can we replace stitch with mustache.
In order to answer this question we first must try to figure out what the differences between T4 and mustache are. T4 is a “generator generator”. That is, the text template generates C# code that generates the ultimate target of the template. This means it is possible to embed any logic within the T4 template as required, to do complex processing. It also means the processing is “fast” because we generate C# code rather than try to introspect at run time. Stitch uses the same approach. However, after many years of using both T4 and Stitch, the general conclusion has been that the templates should be kept as simple as possible. The main reason is that “debugging” through the templates is non-trivial, even though it is simple C++ code (in the case of stitch).
Mustache on the other hand puts forward an approach of logic-less templates. That is, the templates are evaluated dynamically by the templating engine, and the engine only allows for a very limited number of constructs. In some implementations, the so called “template hash”, that is the input to the template, is a JSON object. All the template can do is refer to entries in the JSON object and replace tokens with the values of those entries.
Until recently we deemed mustache to be too simple for our needs because Dogen templates were very complex. However, several things have changed:
- we do not want the templates to have any indentation at all; this should be left to clang-format as a subsequent T2T transform. This removes a lot of functionality we had in Stitch.
- we do not want the logical model objects to be processed any further in the template. As explained above this leads to a lot of complications. We want the object to be in its final form.
- we want all relationships etc to be encoded in the logical model object prior to M2T transformation.
In other words, we have slowly been converging towards logic-less templates, though we are not yet there. The main stumbling blocks are:
- epilogue and prologue are at present handled by assistants:
text::formatters::assistant ast(lps, e, a, true/*requires_header_guard*/);
const auto& o(ast.as<logical::entities::structural::object>(e));
{
auto sbf(ast.make_scoped_boilerplate_formatter(o));
{
const auto ns(ast.make_namespaces(o.name()));
auto snf(ast.make_scoped_namespace_formatter(ns));
#>
class <#= o.name().simple() #>;
<#+
} // snf
#>
<#+
} // sbf
Ideally we should just have a way to ask for the values of these fields.
- we need to investigate all templates and see if a JSON representation of a logical model element is sufficient to capture all required information. However the best way to do this is to have an incremental approach: provide a mustache based M2T and then incrementally move each M2T at a time.
If we do move to mustache, there are lots of advantages:
- remove all of templating code.
- we could allow users to supply their own mustache templates in a model. We can even allow for the dynamic creation of PMM elements and then the association of those elements with templates. End users cannot of course extend the LMM, but even just extending the LMM gives them a lot of power.
- we could create a stand alone tool that allows users to play with templates.
All they need is a dump of the JSON representation of the objects in their
model (this could be an option in Dogen). Then the tool can take the template
and the JSON and render it to
std::out. This makes template development much easier. If we integrate it with Emacs, we could even have a view where we do: 1) JSON 2) template 3) output. Users can then change 1) and 2) and see the results in 3). We don’t even have to extend emacs for this, we could just use the compilation command.
Notes:
- if we could create JSON schemas for the LMM, we could then allow users to create their own JSON representations. Not sure how useful this would be.
- we need JSON support in Dogen for this.
- we need to measure how much slower Dogen would be with this approach. Presumably mustache is a lot slower that Stitch.
- from this perspective, the PMM is fixed but the PM then becomes a dynamic entity. We can supply a PM model with Dogen but that is just Dogen’s interpretation of the physical space; users could supply their own PM’s as required. The PMs need to bind to the PMM: either the user supplies its own TS, part etc or it must bind (via meta-data) to existing parts, TS etc. We also need to support two styles of declaring PM entities: inline (e.g. nested) or outline (e.g. we want to bind a given facet, part etc to an already existing TS, etc).
- we could hash both the mustache template and the JSON object used as input, and save those two hashes in the generated file. If the hashes match, don’t bother regenerating.
Links:
Merged stories:
Implement wale in terms of existing template libraries
Originally we implemented wale as a quick hack, but we stated:
A second point is the use of bustache vs rolling our own trivial mustache-like implementation:
- if we use bustache we can, in the future, start to make use of complex mustache templates. We don’t have a use case for this now, but there is no reason to preclude it either.
- however, with bustache as a third-party dependency we now have to worry about generating OSX and windows binaries for the library. Until we do, the builds will break.
For now, to make life easier we will roll our own. As soon as we have a stable windows environment we will move to bustache.
We should really move to one of these mustache implementations. Inja seems to be the most sensible one, even though it depends on a JSON library. We will need JSON internally anyway, so it may be the time to add a dependency. We should also have a way to associate an arbitrary JSON document with a formatter so that users can create their own templates with their own parameters and the model is merely used for pass-through.
We should also start to create a standard set of variables that dogen exports into inja such as object name, namespaces, etc. These are “system variables” and do not require any action from the user. In fact, if we use the JSON based approach, we could define a JSON schema for meta-model elements which is MASD specific. These are used by the templates.
Note that stitch only makes sense when we are creating a code generator (at least given the use cases we have so far) whereas inja makes sense even for regular models and can be applied to items in any technical space.
Links:
- boostache
- mstch
- plustache (in vcpkg)
- ginger
- render
- inja: in vcpkg, needs JSON library. Emacs mode. “Inja is a template engine for modern C++, loosely inspired by jinja for python. It has an easy and yet powerful template syntax with all variables, loops, conditions, includes, callbacks, and comments you need, nested and combined as you like. Inja uses the wonderful json library by nlohmann for data input.”
- amps
- ctemplate: This library provides an easy to use and lightning fast text templating system to use with C++ programs. It was originally called Google Templates, due to its origin as the template system used for Google search result pages.
- ctpp GH: See also homepage. Seems a bit unmaintained but may have some good ideas. See What is CTPP?
- CXXCTP GH: “Add custom features to C++ language, like metaclasses, Rust-like traits, reflection and many more. A fully open source, powerful solution for modification and generation of C++ source code. Reduce the amount of boilerplate code in your C++ projects.”
- autoprogrammer GH: “Welcome to Autoprogrammer, the C++ code generation tool! This tool helps you dramatically reduce the amount of boilerplate code in your C++ projects. Based on clang frontend, the ‘autoprogrammer’ parses your C++ source files and generates new set C++ sources. For instance, it generates enum-to-string converting functions for you. Instead of you.”
- utility-boilerplate-qt GH: “Template for creating simple cross-platform application with GUI based on Qt.”
Consider renaming =wale= to =mustache=
We need to rename all of the wale templates to mustache.
Consider renaming =wale= to =tangle=
Wale and stitch are remnant from the sewing days. Whilst stitch is
still vaguely appropriate, we can’t even remember what wale stands
for. We should use a more domain-specific term such as weave or
tangle. In fact, we probably should rename stitch to weave given
it weaves text with code, and find a better name for wale. Its not
“tangling” (given tangling, as we understand it from org-mode, is just
another name for weaving). We need to look into logic-less templates
terminology.
Actually this is a mistake. Wale is just a poor-person’s mustache and will be replaced by a proper implementation of mustache as soon as we can. We should instead start calling it mustache and explain this is just a temporary fix.
Consider renaming logic-less templates
Originally we though this was a good name because it was used by some domain experts, but it seems it generates more confusion than anything. It may just be a term used by mustache and other niche template groups. We should probably rename it to text templates given most domain experts know what that means.
In addition, the templates should be specific to their types; we need to know if its a mustache template or a stitch template because the processing will be very different. The templates should be named after their type in the logical model. Rename these to wale templates.
Actually its not yet clear if the existing logic could not be extended to other template types. We should wait until we implement it front to back and then make a decision.
The most obvious thing is just to call the templates after their actual name: mustache.