Dogen v1.0.12, "Estádio do Atlético"
Estádio Joaquim Morais, Moçamedes, Namibe. (C) 2018 Jornal de Angola.

Overview
With Sprint 12 we are hoping to finally return to a regular release cadence. This was a much more predictable two-week sprint, which largely delivered on the sprint's mission statement of cleaning up the mess of refactors and reactivating system testing. As such, it was not a particularly exciting sprint in terms of end user features, but still got us very excited because we are finally paying off years of technical debt in a manner that respects established MDE theory.
Internal Changes
The key internal changes are described in the next sections.
Complete the orchestration refactor
We have now finally got a proper pipeline of tasks, with well-defined roles and terminology:
- injection: responsible for importing external models into MASD. The name "injection" comes from the MDE concept of injecting external technical spaces into a technical space.
- coding: meta-model responsible for modeling software engineering entities.
- generation: meta-model responsible for the expansion into facets, providing a multidimensional extension to the coding model. The role of generation is to get the meta-model as close as possible to the requirements of code-generation.
- extraction: responsible for extracting a model out of MASD into an external technical space. Again, the name "extraction" comes from the MDE notion of extracting content from one technical space into another.
The biggest advantage of this architecture is that we now have a simple pipeline of transformations, taking us from the original external model into the final generated code:

This orchestration pipeline is conceptually similar to the architecture of a compiler, and each of these high-level transforms can be thought of as a "lowering phase" where we move to lower and lower levels of abstraction. However, for a proper technical explanation of the approach you'll have to wait for the PhD thesis to be published.
This work has enabled us to do a number of important clean ups, such as:
- core models now have a uniform structure, with distinct meta-models, transform-sets and transform contexts. We don't have special cases any more.
- all of the mix-and-match processing that occurred inside of the coding model is now gone (e.g. injection work, extraction work, etc).
- the creation of the extraction transform pipeline made things significantly easier to implement features such as diffing and the dry run mode (see user visible changes).
Reactivate all system tests
One of the biggest problems we faced of late has been a lack of adequate testing. Whilst we were experimenting with the architecture, we had to disable all system tests as they became completely out of sync with the (admittedly crazy) experiments we were carrying out. However, before we can enter the last few refactors, we desperately needed to have system tests again.
This sprint saw a lot of infrastructural work to enable a more sensible approach to system testing; one that takes into account both reference models (C++ and C#) as well as using dogen's own models. In order to make this practical, we ended up having to improve the conversion of Dia models into JSON as well. On the plus side, our code coverage has experienced a marked uptick:
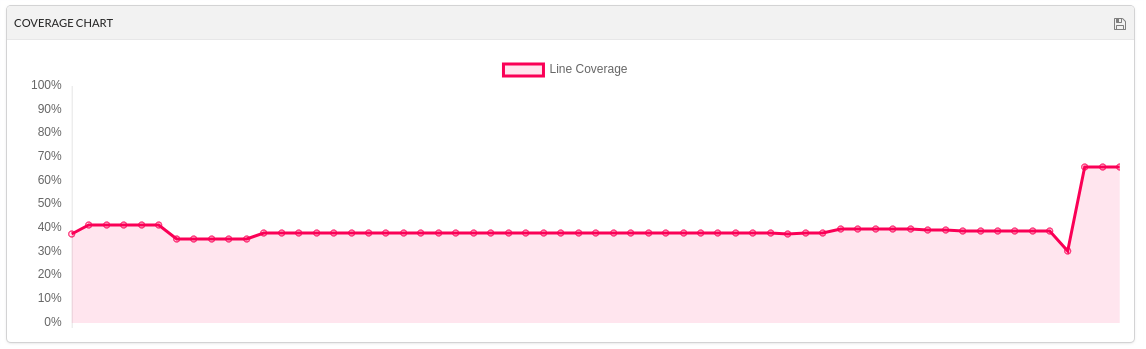
However, analysis reveals that we are still not testing a fair bit of the generated code, so next sprint the objective is to close the gap further in code coverage and testing.
User visible changes
We've finally got round creating a video to demo the user visible features added in this sprint:

Hopefully this will become a habit from now on. The next sections describe in more detail the key user visible changes.
Improvements on handling of references
There were two key changes on how references are processed. First, we no longer automatically include system models. From now on, these are treated just like any other model and must be included manually. As an example, a C++ model using the STL, C++ built-in types and boost would now need to have the following references:
#DOGEN masd.injection.reference=cpp.builtins
#DOGEN masd.injection.reference=cpp.std
#DOGEN masd.injection.reference=cpp.boost
Whilst it is a bit of an inconvenience to have to add these to every other model (specially builtins and std), this does mean that there are now no special cases and no need for "speculative processing" of models. In the past we loaded all system models and there was a lot of extra logic to determine which ones where needed by whom (e.g. do not load C# system models for a C++ model, but maybe load it for a LAM model, etc). We have now placed the onus of determining what should be loaded onto the user, who knows what models to load.
A second related change is that references are now transitive. This means that if model A depends on model B which depends on model C, you no longer need to add a reference to model C in model A as you had to in the past; the reference from model B to model C will be honoured. Sounds like a trivial change, but in reality this was only possible because of the move towards a simplified pipeline (as outlined in the previous section).
Dry-run mode
One of the biggest annoyances we've had is the need to code generate in order to see what would change. The problem with C++ is that, if the generated code is not what you'd expect - a fairly common occurrence when you are developing the code generator, as it turns out - you end up with a large number of rebuilt translation units for no good reason. Thus we copied the idea from vcpkg and others of a "dry-run mode": in effect, do all the transforms and produce all the generated code, but don't actually write it to the filesystem. Of course, the logical conclusion is that some kind of diffing mechanism is required in order to see what would change. For this we relied on the nifty Diff Template Library, which provides a very simple way of producing unified diffs from C++. Sadly it was not on vcpkg, but the most excellent vcpkg developers responded quickly to our PR, so you if you'd like to use it, you can now simply vcpkg install dtl.
As a result, with a fairly simple incantation, you can now see what dogen would like to do to your current state. For example, say we've updated the comment for property attribute of the hello_world.dia test model; to check our changes, we could do:
$ ./masd.dogen.cli generate --target hello_world.dia --dry-run-mode-enabled --diffing-enabled --diffing-destination console
diff -u include/dogen.hello_world/types/one_property.hpp include/dogen.hello_world/types/one_property.hpp
Reason: Changed generated file.
--- include/dogen.hello_world/types/one_property.hpp
+++ include/dogen.hello_world/types/one_property.hpp
@@ -33,7 +33,7 @@
public:
/**
- * @brief This is a sample property.
+ * @brief This is a sample property. Test diff
*/
/**@{*/
const std::string& property() const;
Whilst the arguments required may appear a bit excessive at this point, we decided to roll out the feature as is to gain a better understanding of how we use it. We will then clean up the arguments as required (for example, should dry run mode default to --diffing-enabled --diffing-destination console?).
As an added bonus, if you choose to output to file instead of console, we generate a patch file which can be patched on the command line via patch. We don't have a particular use case for this as of yet, but it just seems nice.
Reporting
A feature that is related to dry-run mode is reporting. We originally merged the two together but then realised that reporting might be useful even when you don't require a diff or a dry run, so we ended up implementing it stand alone. Reporting provides an overview of the operations dogen performed (or would have performed, if you are in dry run mode) to your file system. And, as with tracing, you can visualise it on org mode, making it really easy to navigate if you are a vi or emacs user:
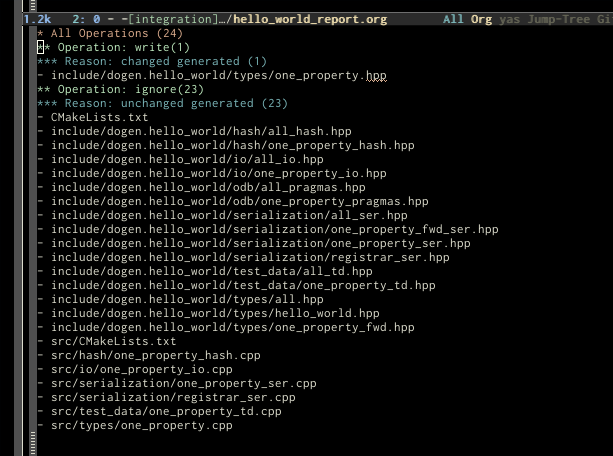
However, if you'd like to grep for specific types of operations, you can use the plain report instead:
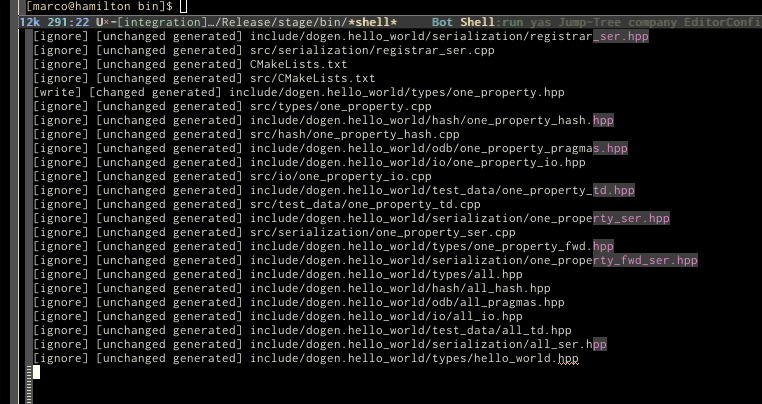
To enable reporting, simply do:
./masd.dogen.cli generate --target hello_world.dia --reporting-enabled --reporting-style org-mode
Replacing org-mode with plain as required. And, as explained, you can always add --dry-run-mode-enabled if you'd like.
Byproducts directory
Even before the advent of diffing and reporting, we were already generating a large number of non-code related files, all of which were fairly randomly placed in the filesystem. With this release, we just couldn't continue with this approach so, instead, all of the non-generated files are now created under a "byproducts" directory. This includes:
- log files;
- traces;
- diff reports, when outputting to file;
- reports...
And any future functionality we may add. This means that you can now safely delete the byproducts directory and know that you have got rid of all files. We write to masd.dogen.byproducts by default, but if you'd like to place it elsewhere, use --byproduct-directory. The directory is organised by "run identifier", allowing you to generate multiple models into the same directory:
$ tree
.
├── cli.generate.hello_world.dia
│ ├── cli.generate.hello_world.dia.log
│ ├── hello_world_report.org
│ └── hello_world_report.txt
├── tests.code_generation.masd.dogen.annotations.dia
│ ├── annotations.patch
│ └── annotations_report.org
├── tests.code_generation.masd.dogen.annotations.json
│ ├── annotations.patch
│ └── annotations_report.org
Graph of Transforms
A minor feature that was added this sprint was the ability to print a GraphViz graph of transforms. This is done by exporting tracing information with the dot format, e.g.:
./masd.dogen.cli generate --target hello_world.dia --tracing-enabled --tracing-format graphviz
The output can then be post processed with dot to generate a PDF:
$ cd masd.dogen.byproducts/cli.generate.hello_world.dia/tracing/
$ dot -Tpdf transform_stats.dot -O
The PDF is quite large because the transform graph is getting extremely complex. This small sample is representative of the output:

Other
As usual, for more details of the work carried out this sprint, see the sprint log.
Next Sprint
Now that we have the testing in place, our key objective for next sprint is to move all of the decoration related code into the meta-model. This means that much of what currently exists as assorted files that dogen loads on startup would become regular model entities, paving the way for a much more configurable model.
Binaries
You can download binaries from Bintray for OSX, Linux and Windows (all 64-bit):
Note: There was a bug in windows builds; the binaries are incorrectly labelled as the previous release.
For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available below.