Dogen v1.0.26, "Rio Bentiaba"
Bentiaba river, Namibe, Angola. (C) 2016 O Viajante.

Introduction
Welcome to yet another Dogen sprint! This one was a bit of a Klingon Release, if we've ever seen one. Now, I know we did say Sprint 25 was a hard slog, but on hindsight 'twas but a mere walk in the park when compared to what was to come. Sprint 26 was at least twice as hard, lasted almost twice as long in terms of elapsed-time, had around 20% extra resourcing compared to what we usually allocate to a sprint and involved such a degree of abstract thinking - given our modest abilities - we often lost the plot altogether and had to go back to first principles. To add insult to injury, after such an intense a bout of coding, we still ended up miles off of the original sprint goal, which was clearly far too ambitious to begin with. For all of its hardships, the sprint did end on a high note when we finally had time to reflect on what was achieved; and the conceptual model does appear to be nearing its final shape - though, of course, you'd be forgiven for thinking you've heard that one before. Alas, some things never change.
But that's quite enough blabbering - let's look at how and where the action took place.
User visible changes
This section covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were only two small user facing features, the video also discusses the work on internal features.
Video 1: Sprint 26 Demo.
Archetype Factories and Transforms
The main story visible to end users this sprint is deeply connected to our physical model changes, so it requires a fair amount of background in order to make sense of it. Before we proceed, we must first go through the usual disclaimers, pointing out that whilst this is technically a user facing story - in that any user can make use of this feature - in practice, it's only meant for those working in Dogen's internals - i.e. generating the code generator. It's also worthwhile pointing out that Dogen uses a generative architecture, where we try to generate as much as possible of Dogen using Dogen; and that we want the generated portion to increase over time. With those two important bits of information in hand, let's now take a step back to see how it all fits together.
MASD's logical model contains a set of modeling elements that capture the essential characteristics of the things we want to code-generate. Most of these elements are familiar to programmers because our targets tend to be artefacts created by programmers; these are classes, methods, enumerations and the like, the bricks and mortar we typically associate with the coding activity. However, from a MASD perspective, the story does not end there - and hence why we used the term "things". Ultimately, any artefact that contributes to a software product can be modeled as a logical entity, provided it exhibits "commonalities" which can be abstracted in order to recreate it via code generation. The fact that we model programming constructs is seen as more of a "coincidence" than anything else; what we really care about is locating and extracting certain kinds of structural patterns on files. One way to think about this is that we see some files as higher-dimensional structures that embed lower dimensional structures, which contain enough information to enable us to recreate the higher-dimensional structure. Our quest is to find cases where this happens, and to add the lower dimensional structures to our logical model. It just so happens that those lower dimensional structures are often programming constructs.

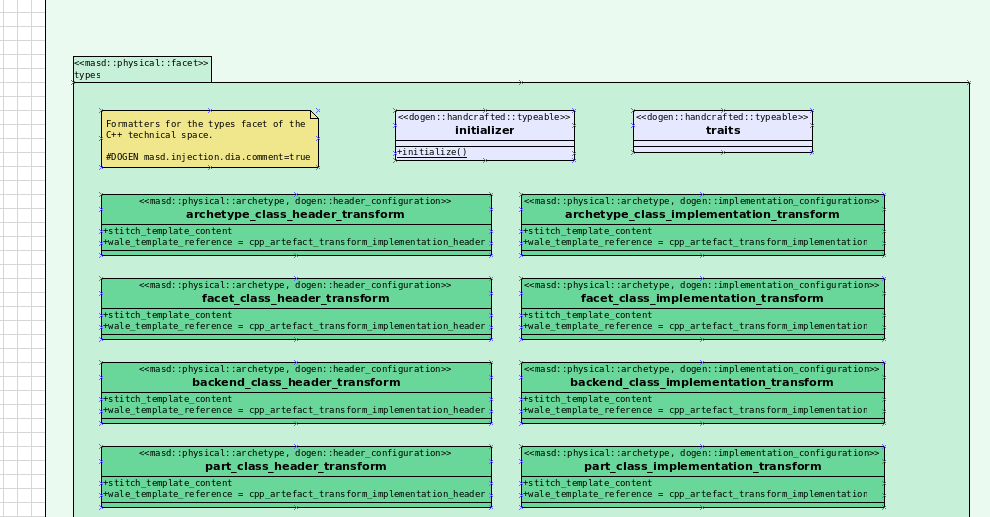
Figure 1: Archetypes representing M2T transforms in text.cpp model, on Sprint 25.
MASD provides a separation between logical entities and their eventual physical representation as a file. The mapping between the logical domain and the physical domain is seen as a projection through these spaces; one logical element projects to zero, one or many physical elements. In the physical domain, files are abstracted into artefacts (the physical model or PM), and each artefact is an instance of an archetype (the physical meta model or PMM). These are related in very much the same way a class and an object are: the artefact is an instance of an archetype. Until recently, we had to tell Dogen about the available archetypes "by hand" (a rough approximation): each text template had some boilerplate to inject the details of the archetype into the framework. After a great deal of effort, Sprint 25 finally brought us to a point where this code was generated by Dogen in the spirit of the framework. This was achieved by treating archetypes themselves as logical concepts, and providing physical projections for these logical elements as we do for any other logical element. Which neatly brings us to the present.
Archetypes had a single projection that contained two distinct bits of functionality:
- Telling the system about themselves: the above mentioned registration of the archetype, which is used by a set of transforms to generate the PMM.
- Providing an M2T transform: each archetype takes an associated logical element and generates its representation as an artefact.
The more we thought about it, the more it seemed strange that these two very different concerns were bundled into the same archetype. After all, we don't mix say serialisation with type definition on the same archetype, and for good reason. After some deliberation, we concluded it was there only for historical reasons. So this sprint we decided to project logical representations of some physical meta-model elements - e.g., backend, facet, archetype - onto two distinct physical archetypes:
- Factory: responsible for creating the physical meta-model element for the purposes of the PMM.
- Transform: responsible for the M2T transform.

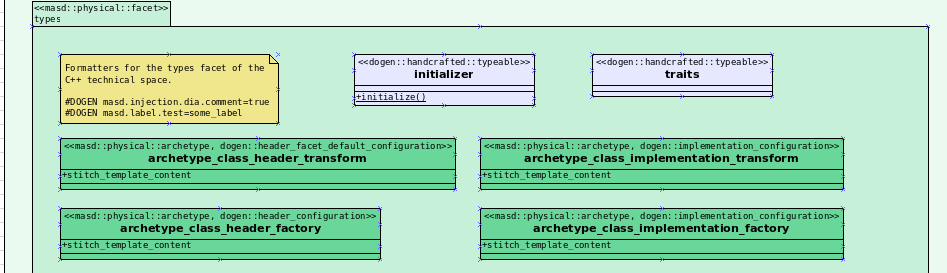
Figure 2: Archetypes after the split in the present sprint.
It all seemed rather logical (if you pardon the pun), until one started to implement it. Trouble is, because we are knee-deep in the meta-land, many things end up in surprising places when one takes them to their logical consequences. Take archetypes for example. There is an archetype that represents the archetype factory itself, as there is an archetype that represents the archetype transform itself too, and there are permutations of the two as well - leading us to very interesting names such as archetype_class_header_factory_factory, archetype_class_header_transform_transform and the like. At first glance, these appear to be straight out of Spolsky's Factory Factory Factory parable - a threshold that, when reached, normally signals a need to halt and rethink the design. Which we did. However, in our defence, there is some method to the madness. Let's dissect the first name:
- the logical element this archetype maps to is
archetype; - the particular item it is interested in is a C++
class_header; - but its not just any old archetype class header, its the one specifically made for the
factoryof the archetype; - which, as it turns out, its also the factory which generates the
factoryof the archetype.
I guess every creator of a "framework" always comes up with justifications such as the above, and we'd be hard-pressed to explain why our case is different ("it is, honest guv!"). At any rate, we are quite happy with this change as its consistent with the conceptual model and made the code a lot cleaner. Hopefully it will still make sense when we have to maintain it in a few years time.
Add Support for CSV Values in Variability
The variability model is a very important component of Dogen that often just chugs along, with only the occasional sharing of the spotlight (Sprint 22). It saw some minor attention again this sprint, as we decided to add a new value type to the variability subsystem. Well, two value types to be precise, both on the theme of CSV:
comma_separated: allows meta-data values to be retrieved as a set of CSV values. These are just a container of strings.comma_separated_collection: allows meta-data values to be collections ofcomma_separatedvalues.
We probably should have used the name csv for these types, to be fair, given its a well known TLA. A clean up for future sprints, no doubt. At any rate, this new feature was implemented to allow us to process relation information in a more natural way, like for example:
#DOGEN masd.physical.constant_relation=dogen.physical.helpers.meta_name_factory,archetype:masd.cpp.types.class_header
#DOGEN masd.physical.variable_relation=self,archetype:masd.cpp.types.archetype_class_header_factory
For details on relations in the PMM, see the internal stories section.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Ephemerides
This sprint saw the 12,000th commit to Dogen. To our displeasure, it also saw the implementation of the new GitHub design, depicted in Figure 3.

Figure 3: Dogen's GitHub repo at the 12,000th commit.
Milestones
No milestones where reached this sprint.
Significant Internal Stories
This sprint had the ambitious goal of replacing the hard-coded way in which we handle relationships in both the C++ and C# model with a PMM based approach. As it turns out, it was an extremely ambitious goal. There were two core stories that captured this work, each composed with a large number of small sub-stories; we grouped these into the two sections below.
Add Relations Between Archetypes in the PMM
It has been known for a long time that certain kinds of relationships exist at the archetype level, regardless of the state of the logical modeling element we are trying to generate. In other words, an archetype can require a fixed set of logical model elements, projected to a given archetype (e.g., say the type definition). For instance, when you implement an archetype, you may find it needs some specific "platform services" such as logging, iostreams, standard exceptions and so forth, which must be present regardless of the state of the logical model elements processed by the M2T transform. This is somewhat of a simplification because sometimes there is conditionality attached to these relations, but its a sufficient approximation of the truth for the present purposes. These we shall name constant relations, as they do not change with regards to the logical model element.
In addition, archetypes also have relations with other archetypes based on the specific contents of the logical model element they are trying to generate; for example, having an attribute may require including one or more headers for the logical model elements as given by the attribute's type - e.g., std::unordered_map<std::string, some_user_type> requires unordered_map and string from the std model, as well as some_user_type from the present model; or an archetype may require another archetype like, for example, a class implementation will always need the class header. In the first case we have an explicit relation, whereas in the latter case its an implicit relation, but both of these fall under the umbrella of variable relations because they vary depending on the data contained in the logical model element. They can only be known for sure when we are processing a specific model.
Up to now, we have modeled the projection of relations from the logical dimension into the physical dimension by allowing archetypes themselves to "manually" create dependencies. This meant that we pushed all of the problem to "run time", regardless of whether the relations are variable or constant; worse, it also means we've hard-coded the relations in a way that is completely transparent to the models - with "transparent" here having a bad connotation. Listing 1 provides an example of how these are declared. This approach is of course very much in keeping with Dogen's unspoken motto, shamelessly stolen elsewhere, of "first hard-code and get it to work in any way possible, as quickly as possible, then continuously refactor". Sadly, now has come the time for the second part of that motto, and that is what this story concerns itself with.
const auto io_arch(transforms::io::traits::class_header_archetype_qn());
const bool in_inheritance(o.is_parent() || o.is_child());
const bool io_enabled(builder.is_enabled(o.name(), io_arch));
const bool requires_io(io_enabled && in_inheritance);
const auto ios(inclusion_constants::std::iosfwd());
if (requires_io)
builder.add(ios);
using ser = transforms::serialization::traits;
const auto ser_fwd_arch(ser::class_forward_declarations_archetype_qn());
builder.add(o.name(), ser_fwd_arch);
const auto carch(traits::canonical_archetype());
builder.add(o.transparent_associations(), carch);
const auto fwd_arch(traits::class_forward_declarations_archetype_qn());
builder.add(o.opaque_associations(), fwd_arch);
const auto self_arch(class_header_transform::static_archetype().meta_name().qualified());
builder.add(o.parents(), self_arch);
using hash = transforms::hash::traits;
const auto hash_carch(hash::traits::canonical_archetype());
builder.add(o.associative_container_keys(), hash_carch);Listing 1: Fragment of inclusion dependencies in the class_header_transform.
The reason why we do not want relations to be transparent is because the graph of physical dependencies contains a lot of valuable information; for example, it could tell us if the user has decided to instantiate an invalid configuration such as disabling the hash facet and then subsequently creating a std::unordered_map instance, which requires it. In addition, we always wondered if there really was a reason to have a completely separate handling of relations for C++ and C#, or whether it was possible to combine the two into a unified approach that took into account the gulf of differences between the languages (e.g., #include of files versus using of namespaces). So the purpose of this story was to try to bring relations into the PMM as first class citizens so that we could reason about them, and then to generate the physical specificities of each technical space from this abstraction. With this release we have done the first of these steps: we have introduced all of the machinery that declares relations as part of the archetype factory generation, as well as all the paraphernalia of logical transforms which process the meta-data in order to bring it into a usable form in the physical domain. It was a very large story in of itself, but there were also a large number of smaller stories that formed the overall picture. These can be briefly summarised as follows:
- Analysis on solving relationship problems: Much of the work in finding a taxonomy for the different relation types came from this story, as well as deciding on the overall approach for modeling them in the logical and physical models.
- Create a TS agnostic representation of inclusion: Due to how we hard-coded relations, we needed to extract the requirements for the C++ Technical Space in a form that did not pull in too much C++-specific concepts. We've had the notion that some archetypes are "non-inclusive", that is to say, they generate files which we think cannot be part of any relation (e.g. inclusion of a
cppfile is not allowed). In this story we tried to generalise this notion. - Use PMM to compute
meta_name_indices: As part of the PMM clean-up, we want to start using it as much as possible to generate all of the data structures that we are at present hard-coded. This story was one such clean-up, which consolidated a lot of dispersed infrastructure into the PMM. - Add labels to archetypes: In the existing implementation we have the notion of "canonical archetypes". These exist so that when we have a logical model element and require the archetype that contains its type definition, we can "resolve" it to the appropriate archetype depending on the logical meta-type; e.g.
enum_header,class_header, and so forth. Labels were designed as generalisation of this mapping infrastructure, so that we can have arbitrary labels, including the somewhat more meaningfultype_definition. - Analysis on archetype relations for stitch templates: Stitch templates are their own nest of wasps when it comes to relations. We incorrectly allowed templates to have their own "inclusion" system via the
<#@ masd.stitch.inclusion_dependency="x.hpp">directive. This seemed really clever at the time, but in light of this analysis, it clearly suffers from exactly the same issues as the regular M2T transforms did - we have no way of knowing what these templates are pulling in, whether those models are available and so forth. With this analysis story we found a generalised way to bring in relations from stitch templates into the fold. However, the implementation will be no easy feat. - Analysis on reducing the number of required wale keys: Whilst we were looking at stitch it seemed only logical that we also looked at our other templating engine, wale (really, a poor man's implementation of mustache, which we will hopefully replace at some point). It seems obvious that we have far too many keys being passed in to our wale templates, and that the required data is available in the PMM. This story pointed out which bits of information can already be supplied by the PMM. We need a follow up implementation story to address it.
- Analysis on implementing containment with configuration: this story provides a much easier way to handle enablement, as opposed to the pairs of transforms we have at present that handle first a "global configuration" and then a "local configuration". With the analysis in this story we could "flatten" these into a single configuration which could then be processed in one go. However, the implementation story for this analysis will probably have to remain in the backlog as its not exactly a pressing concern.
- Merge kernel with physical meta-model: We originally had the notion of a "kernel", which grouped backends, facets and archetypes. However, we still don't really have a good use case for having more than one kernel. With this story we deprecated and removed the
kernelmeta-entity and flattened the PMM. We can always reintroduce it if a use case is found. - Move templating aspects of archetype into a generator type: Due to the complexity of having relations for the archetype as well as relations for the templates, we factored out the templating aspects of the archetype into a new logical entity called
archetype_text_templating. This made the modeling a bit more clearer, as opposed to names such as "meta-relations" that had been tried before. This story was further complemented by "Rename archetype generator" where we changed the name to its present form. - Remove traits for archetypes: With the rise of the PMM, we no longer need to hard-code archetype names via the so-called "traits". We started removing some of these, but many of the pesky critters still remain.
- Convert
wale_template_referenceto meta-data: Archetypes always had the ability to reference wale templates, as well as containing a stitch template. Due to some misguided need for consistency, we modeled both stitch template and the reference to a wale template as attributes. However, the net result was a huge amount of duplication, given that almost all archetypes use one of two wale templates. The problem should be fairly evident in Figure 1, even though it only shows a narrow window of thetext.cppmodel. With this story we moved this field to meta-data, meaning we can now use the profiling system to our advantage and therefore remove all duplication. Figure 2 depicts the new look. - Archetype kind and postfix as parts of a larger pattern: More analysis trying to understand how we can reconstruct file paths from the generalised elements we have in PMM. We tried to see if we can model these using the new labelling approach, with moderate success. The implementation story for this analysis is to follow, likely next sprint.
- Split physical relation properties: Trivial story to improve the modeling of relations on the physical domain. These now have its own top-level class.
{kind=link}
{kind=link}
All of these disparate stories molded the logical and physical models into containing the data needed to handle relations. After all of this work, we just about got to the point where we were trying to generate the relations themselves; and then we realised this task could not be completed until we resolved some key modeling errors of data types that really belonged in the physical domain but were unfortunately located elsewhere. So we downed our tools and started work on the next story.
Create an Archetype Repository in Physical Model
This story started with very good intentions but quickly became a dishevelled grab-bag of refactoring efforts. The main idea behind it was that we seem to have two distinct phases of processing of the physical model:
- the first phase happens during the logical to physical projection; at this point we need to perform a number of transforms to the physical model, but we are not quite yet ready to let go of the logical model as we still need the combined logical-physical space in order to perform the M2T transforms.
- the second phase happens once we have the stand alone physical model. This is fairly straightforward, dealing with any post-processing that may be required.
Our key concern here is with the first phase - and hopefully you can now see how this story relates to the previous one, given that we'd like to stick the processing of relations somewhere in there. Whilst it may be tempting to create an instance of the physical model for the first phase, we would then have to throw it away when we resume the guise of the logical-physical space in dogen.text. Besides, we did not really need a full blown physical model instance; all that is required is a set of artefacts to populate. And with this, the notion of the "artefact repository" was born. Whilst we were doing so, we also noticed something else that was rather interesting: the logical-physical space deals mainly with planes of the physical space that pertain to each individual modeling element (as covered by the story "Add hash map of artefacts in physical model"). We had originally incorrectly called these planes "manifolds", but subsequent reading seems to imply they are just 1D planes of a 2D space (see Manifolds: A Gentle Introduction). Once we understood that, we then refactored both the artefact repository as well as the physical model to be implemented in terms of these planes - which we have named artefact_set for now, though perhaps the name needs revisiting.
It took some doing to put the artefact repository and the plane approach in, but once it was indeed in, it made possible a great number of cleanups that we had been trying to do for many sprints. In the end, we were finally able to move all physical concepts that had been scattered around logical and text models - at one point we generated over 10 temporary non-buildable commits before squashing it into one monstrous commit. Though some further refactoring is no doubt required, at least now these types live in their final resting place in the physical model (Figure 4), together with a chain that populates the artefact repository. In the end, it was a rather rewarding change though it certainly did not seem so as we in the thick of doing it.

Figure 4: Physical model after refactoring.
MDE Paper of the Week (PofW)
This sprint we spent a bit more than usual reading MDE papers (6.1%), and read a total of 5 papers. It should have really been 6 but due to time constraints we missed one. As usual, we published a video on youtube with the review of each paper. The following papers were read:
- MDE PotW 10: Using Aspects to Model Product Line Variability: Groher, Iris, and Markus Voelter. "Using Aspects to Model Product Line Variability." SPLC (2). 2008. PDF
- MDE PotW 11: A flexible code generator for MOF based modeling languages: Bichler, Lutz. "A flexible code generator for MOF-based modeling languages." 2nd OOPSLA Workshop on Generative Techniques in the context of Model Driven Architecture. 2003. PDF
- MDE PotW 12: A Comparison of Generative Approaches: XVCL and GenVoca: Blair, James, and Don Batory. "A Comparison of Generative Approaches: XVCL and GenVoca." Technical report, The University of Texas at Austin, Department of Computer Sciences (2004). PDF
- MDE PotW 13: An evaluation of the Graphical Modeling Framework GMF: Seehusen, Fredrik, and Ketil Stølen. "An evaluation of the graphical modeling framework (gmf) based on the development of the coras tool." International Conference on Theory and Practice of Model Transformations. Springer, Berlin, Heidelberg, 2011. PDF
- MDE PotW 14: Features as transformations: A generative approach to software development: Vranić, Valentino, and Roman Táborský. "Features as transformations: A generative approach to software development." Computer Science and Information Systems 13.3 (2016): 759-778. PDF
Resourcing
As we alluded to in the introduction, this sprint had a whopping 95 hours worth of effort as opposed to the more traditional 80 hours - 18.7% more resourcing than usual. It also lasted for some 6 weeks rather than 4, meaning our utilisation rate was a measly 35%, our second worse since records begun on Sprint 20 (Figure 4). Partially this was due to work and life constraints, but partially it was also due to the need to have some time away from the rarefied environment of the logical-physical space, which is not exactly a friendly place to those who do not favour abstraction.

Figure 5: Utilisation rate since Sprint 20.
If one ignores those glaring abnormalities, the sprint was otherwise fairly normal. Around 75% of the resourcing was concerned with stories that contributed directly to the sprint goal - not quite the 80% of the previous sprint but not too shabby a number either. As the colouration of Figure 6 attests, those 75% were spread out across a decent number of stories, meaning we didn't do so bad in capturing the work performed. On non-core matters, we spent around 6.1% on MDE papers - up from 5.2% last sprint - but giving us a good bang for the buck with 5 papers instead of the 4 we had last sprint. Its a bit painful to read papers after a long week of coding for both professional and personal projects, but its definitely worth our while. We also had around 2.2% of the ask wasted on spikes, mainly troubleshooting problems with the nightly build and with Emacs/clangd. Finally, we dedicated almost 16% to process related matters, including 8.4% on editing the release notes and 6.1% on backlog grooming. Overall, it was a solid effort from a resourcing perspective, with the exception of the utilisation rate. Hopefully, regular service will be resumed next sprint on that regard.

Figure 6: Cost of stories for sprint 26.
Roadmap
Sadly, not much to be said for our road map. We did not make any progress with regards to closing the fabled generation meta-model clean-up given that we are yet to do a dent in the PMM relations. We probably should rename this milestone as well, given the generation model is long gone from the code-base. One for next sprint.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 2. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.26_amd64-applications.deb | dogen_1.0.26_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.26-Darwin-x86_64.dmg | DOGEN-1.0.26-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.26-Windows-AMD64.msi | DOGEN-1.0.26-Windows-AMD64.msi |
Table 1: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goal for the next sprint is carried over from the previous sprint. Given the overambitious nature of the previous sprint's goal, this time we decided to go for a single objective:
- implement locator and dependencies via PMM.
That's all for this release. Happy Modeling!