Dogen v1.0.27, "Independência"
Abandoned freighter North of Namibe, Angola. (C) Alfred Weidinger, 2011

Introduction
We've been working on Dogen for long enough to know that there is no such thing as an easy sprint; still, after a long sequence of very challenging ones, we were certainly hoping for an easier ride this time round. Alas, not to be. Due to never ending changes in personal circumstances, both with work and private life, Sprint 27 ended up being an awfully long sprint, with a grand total of 70 elapsed days rather than the 30 or 40 customary ones. To make matters worse, not only was it a bit of a fragmented sprint in time - a bit stop-start, if we're honest - but it was also somewhat disjointed in terms of the work as well. One never ending story occupied the bulk of the work, though it did have lots of challenging variations; and the remainder - a smattering of smaller stories - were insufficient to make any significant headway towards the sprint goals. Ah, the joys of working on such a long, open-ended project, hey. And to round it all up nicely, we weren't able to do a single MDE Paper of the Week (PofW); there just weren't enough hours in the day, and these were the first ones to fall by the wayside. They will hopefully resume at the usual cadence next sprint.
The picture may sound gloomy, but do not fear. As we shall see in these release notes, we may have not achieved what we set out to achieve originally, but much else was achieved nevertheless - giving us more than sufficient grounds for our unwavering developer optimism. Omnia mutantur, nihil interit, as Ovid would say.
User visible changes
This section normally covers stories that affect end users, with the video providing a quick demonstration of the new features, and the sections below describing them in more detail. As there were no user facing features, the video discusses the work on internal features instead.
Video 1: Sprint 27 Demo.
Development Matters
In this section we cover topics that are mainly of interest if you follow Dogen development, such as details on internal stories that consumed significant resources, important events, etc. As usual, for all the gory details of the work carried out this sprint, see the sprint log.
Significant Internal Stories
The story arc of the last few sprints has been centred around reducing the impedance mismatch between Dogen's source code and the conceptual model for the Logical-Physical Space (at times called the LPS). In turn, the LPS stemmed from the work we were doing in cleaning up the text models - in particular the C++ and C# backends; in other words, what we have been trying to achieve for some time now is to remove a large amount of hard-coding and just plain old bad modeling in those two models. For a throw back, see the section Towards a physical Model in the release notes of Sprint 23. At any rate, every time we try to address what appears to be a fairly straightforward issue, we soon realise it has big implications for the LPS, and then we end up going on yet another wild goose chase to try to find a solution that is in keeping with the conceptual model. Once its all resolved, we then go back to the task at hand and move forwards by a metre or so... until we find the next big issue. It has been this way for a while and sadly this sprint was no different. The main story that consumed just under 51% of the ask was the creation of a new model, the identification model, which was not directly aligned with the sprint goal. We then worked on a series of smaller stories that were indeed aligned with the goal, but which also required what appears to be a never ending series of mini-spikes. Lets have a quick look at all of these stories.
Create an identification model
The graph of relationships between the different models in Dogen has been a source of concern for a very long time, as this blog post attests. We are facing the typical engineering trade-offs: on one hand, we do not want cycles between models because that severely impairs testability and comprehension; on the other hand, we do not want a small number of "modelets", which have no well-defined responsibilities beyond simply existing to break up cycles. One such bone of contention has been the strange nature of the relationship between the logical and physical models. To be fair, this tangled relationship is largely a byproduct of the fundamental nature of the LPS, which posits that the logical-physical space is one combined entity. Predictably, these two models have a lot of references to each other:
- the
logicalmodel contains inside of it a model of thephysicalentities, which is use to code-generate these entities. - the
physicalmodel represents regions of the LPS for a given point in the logical axis of the LPS, and therefore needs to reference thelogicalmodel.
Until this sprint the problem had been resolved by duplicating types from both models. This was not an ideal approach but it did address both the problem of cycles as well as avoiding the existence of modelets. As we continued to move types around on our clean ups, we eventually realised that there are only a small number of types needed for these cross-model relationships to be modeled correctly; and as it turns out, pretty much all of these types seem to be related in one way or another to the "identification" of LPS entities. Now, this is not completely true - a few types are common but not really related to identification; but in the main, the notion holds sufficiently true. Therefore we decided to create a model with the surprising name of identification and put all the types in there. So far so good. This could have possibly been done with a simple set of renames, which would not take us too long. However, we were not content and decided to address a second long standing problem: avoid the use of "strings" everywhere for identification. If you've watched the Kevlin Henney classic presentation Seven Ineffective Coding Habits of Many Programmers, you should be aware that using strings and other such types all over the place is a sign of weak domain modeling. If you haven't, as with all Henney talks, I highly recommend it. At any rate, for the purposes of the present exercise, the Thomas Fagerbekk summary suffices:
4. We don't abstract enough.
Use your words, your classes, your abstractions. Don't do Strings, Lists and integers all over the place. [...] Instead, think about how you can communicate the meaning of the objects in the domain. Kevlin pulls up a wordcloud of the words used most frequently in a codebase (about 38-minute mark in the video): The most common words should tell you something about what the codebase is about. [...] A bad example shows List, Integer, String and such basic structures as the most common words. The better example has PrintingDevice, Paper, Picture. This makes the code less readable, because such generic variables can represent so many different things.
Now, if you have even a passing familiarity with Dogen's source code, you could not have helped but notice that we have a very large number of distinct IDs and meta-IDs all represented as strings. We've known for a long while that this is not ideal, not just because of Henney's points above, but also because we often end up using a string of "type" A as if it were a string of "type" B (e.g. using a logical meta-model ID when we are searching for a physical ID, say). These errors are painful to get to the bottom of. Wouldn't it be nice if the type system could detect them up front? Given these are all related to identification, we thought, might as well address this issue at the same time. And given Dogen already has built-in support for primitive types - that is, wrappers for trivial types such as string - it did seem that we were ready to finally make this change. Designing the new model was surprisingly quick; where the rubber met the road was on refactoring the code base to make use of the shiny new types.
Video 2: Part 1 of 3 of the series of videos on the Identification Refactor.
As you can imagine, and we now know first hand, modifying completely how "identification" works across a large code base is anything but a trivial exercise. There were many, many places where these types were used, sometimes incorrectly, and each of these places had its own subtleties. This change was one long exhausting exercise of modifying a few lines of code, dealing with a number of compilation errors and then dealing with many test failures. Then, rinse, repeat. Part of the not-exactly-fun-process was recorded on a series of videos, available on the playlist MASD - Dogen Coding: Identification Refactor:
- MASD - Dogen Coding: Identification Refactor - Part 1
- MASD - Dogen Coding: Identification Refactor - Part 2
- MASD - Dogen Coding: Identification Refactor - Part 3
These videos catch a tiny sliver of the very painful refactor, but they are more than sufficient to give a flavour of the over 42 hours of "joy" we went through. Having said that, in the end we did experience moments of non-sarcastic joy because the code base is now so much better for it. If nothing else, at least now a word cloud will not have std::string as its most common type - or so one would hope; the hypothesis was not put to the test, probably out of fear. At any rate, we felt this approach was such an improvement that we started to think of all the other types of patterns we have which share similarities with primitives; and how they could also benefit from a similar clean up. However, the reverie quickly ended; at this stage, these are but wishful dreams, a mere gathering of requirements for that one day where our copious free time will allow us to take on a side project of such magnitude. Once backlogged, the dreams quickly faded away and we were back to the task at hand.
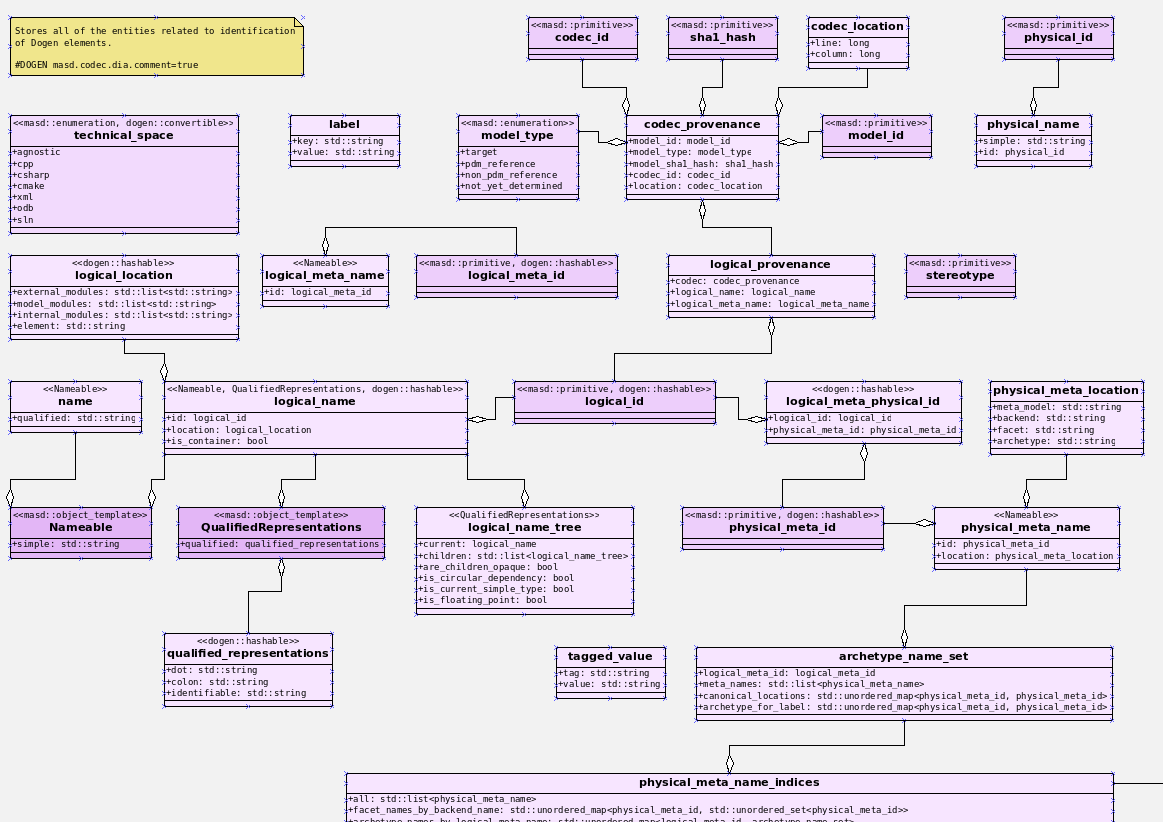
Figure 1: The Dogen Identification model.
Rename injection to codec
A small but very helpful change - nay, instrumental change - on our never ending quest to clean up the conceptual model was the renaming of the injection models to codec. In order to understand its importance, we need to go back in time via our old favourite imagine of the Dogen pipeline:

Figure 2: The Dogen pipeline, circa Sprint 12.
Almost every box in this diagram has changed name, as our understanding of the domain evolved, though their functional roles remained fairly constant. This sprint it was the turn of the "injection" box. This happened because we begun to realise that there are several "forces" at play:
- the terms injection and extraction imply the notion that elements are to be projected with regards to a technical space; when into a technical space, then its an injection, and when out of a technical space, its an extraction.
- the process of performing the projection can be done by the same set of classes. That is, it's often convenient to declare an encoder and a decoder next to each other because the coding and decoding is functionally very similar.
- the generation of text from model elements is considered an extraction, as is the plain conversion of models of one type to another. However, given there is a very well understood set of terms regarding the transformation of model elements into text - e.g., model-to-text transforms - its not insightful to call this an extraction.
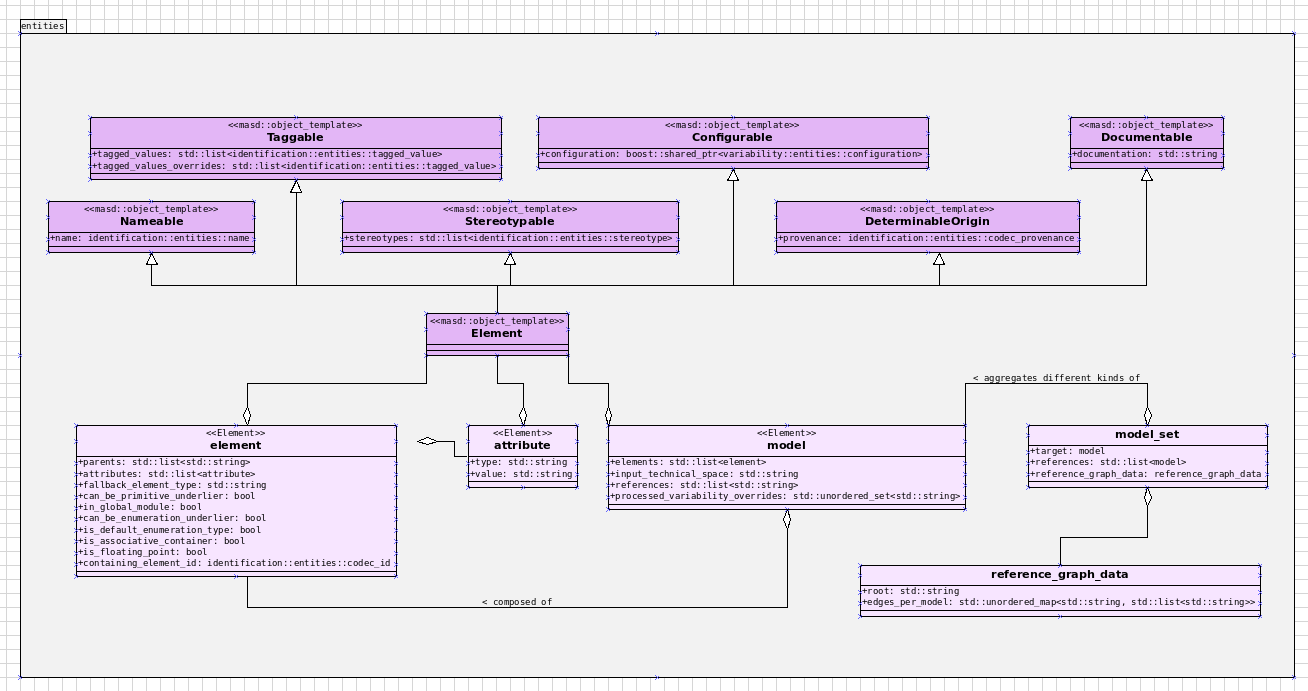
Figure 3: the Dogen Codec model.
When we took all this factors into account, it became obvious we could not call these models "injection" or "injectors", because that is not all that they do. We debated calling them "inxtractors" given they were both injectors and extractors, but quickly realised we were entering the terminological domain of "modems" (i.e., "modulators" and "demodulators") and so we settled on calling them "codecs" because they encode and decode elements from the format of one technical space to the format of another. Once the light-bulb went off, all was light and the rename itself was fairly trivial.
Assorted conceptual model clean ups
A number of small stories worked on were directly or indirectly related to conceptual model clean ups - that is, the polishing of the code to make it coherent with our present understanding of the conceptual model. These were:
- Create a logical to physical projector: In the past we had transforms and adapters which had bits of the projection work. Now that we understand projections much better, it makes sense to have dedicated classes responsible for the projection.
- Clean up the logical-physical model: A bit of a grab-bag story related to all sorts of miscellaneous clean up work done on the
textandphysicalmodels. Whilst the story itself wasn't huge (7% of the ask), it delivered immense amounts of clarity. As an example, instead of duplicating properties from both thelogicalandphysicalmodels in the text model, we now have modeled it very clearly as a representation of LPS, in a way that is completely transparent (c.f., Figure 4). We also finally renamed theartefact_setto a physicalregion, which is in keeping with the LPS, as well as the removal of a large number of duplicate types and properties in the physical model.
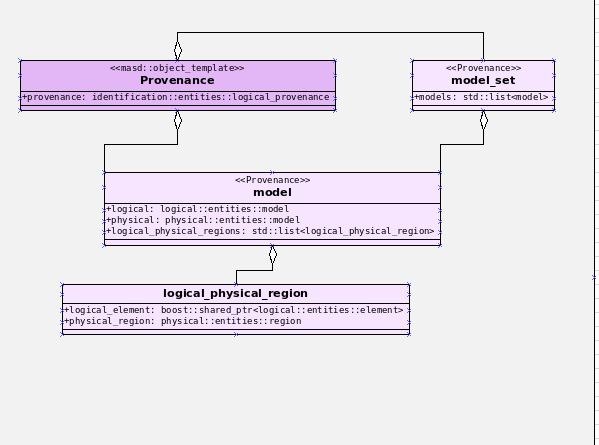
Figure 4: The refactored Dogen Text model.
- Empty path ID error in logs: yet another clean up story, this entailed understanding why we were producing so many weird and wonderful warnings in the log files related to empty paths. Turns out we had missed out some of the logic regarding the filtering out of reference models prior to generation - in particular the Platform Definition Models or PDMs - which resulted in us trying to look for paths where none exist. With this clean up we have a proper transform to filter out all artefacts and even whole regions of physical space which are not supposed to exist at the point at which we write files to the file-system (
remove_regions_transform). - Add instances of physical meta-model elements: This story was a bit of a mind-bender in terms of the LPS. Thus far we have relied on the usual meta-model taxonomy as prescribed by the OMG. However, with this sprint we started to break with the nice clear cut hierarchical model because we noticed that there is in fact a layer in between the physical meta-model (PMM) and the physical model (PM). This layer comes to be because the PMM is configurable via the variability elements that Dogen supports. This variability means that the actual PMM a given model has could be completely different from another model. Now, of course, we only allow a very restricted form of configuration at this level, but nonetheless its large enough that it requires a large amount of supporting data structures. As we did not quite know what to call these data structures, we decided to go for the suitably incorrect postfix of
_properties. Henney would not have been proud, clearly.
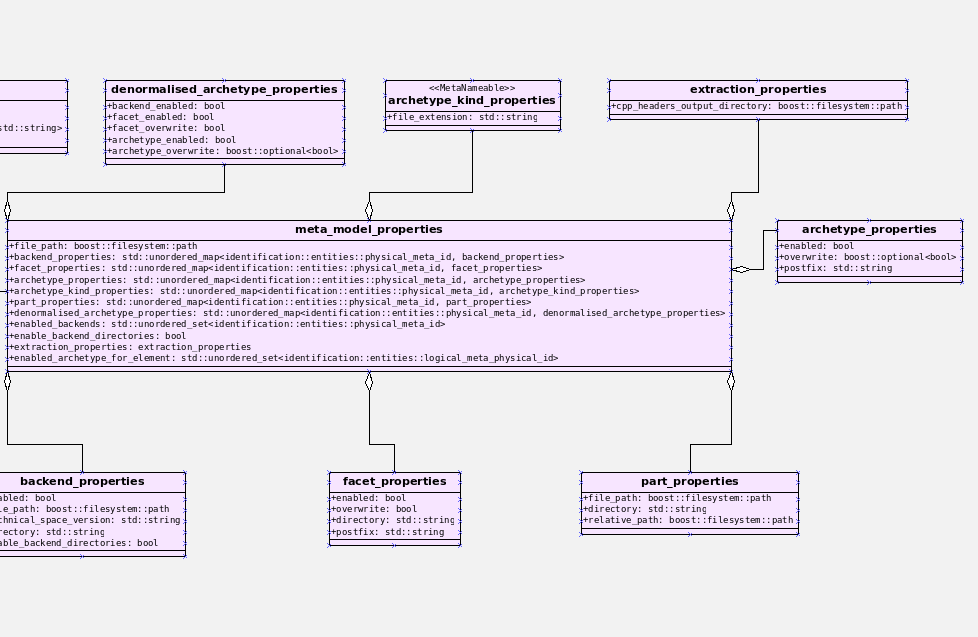
Figure 5: Dogen meta-model properties.
- Add dependencies to artefacts: work was started but not completed on adding dependencies to artefacts and archetypes, but we then ran into all of the clean ups mentioned above. It shall continue next sprint, where we will hopefully describe this story properly.
- Add full and relative path processing to PM: similarly to the previous story, this is a long standing story which is part of the clean up arc. Each sprint we tend to do a bit of progress on it, but sadly, it also generates a large amount of spikes, meaning we never tend to get very far. When we do complete it, we shall provide a complete description of this endeavour.
- Other minor stories: Stories comprising 0.1% to 0.3% of the ask were also completed, but were very minor. For example, we toyed with removing split project support, but in the end concluded this did not provide the bang we expected and, in the end, rolled back the changes.
Resourcing
As we've already mentioned, resourcing this sprint was completely dominated by one big ol' massive story: updating the entire code base to use the new identification model. Weighing in at 51%, it amply demonstrates our inability to break up large stories into small, digestible pieces. In reality, we probably should have had an epic encompassing around 3 or 4 stories, one for each chunk of the pipeline - e.g. injection, logical, physical, etc. As it was, we bundled all the work into one massive story, which is not ideal for the purposes of analysis. For example, the logical work was the largest of them all, but that is not visible through the lens of the data. OK, so the breaking down of stories was not exactly amazing, but on the plus side we did spend 82% of the total ask on "real engineering", as opposed to the other 18% allocated to "housekeeping". These were scattered over release notes (8.8%), backlog management (3%), demos (just under 1%) and addressing issues with nightlies, at a costly 5.3%. Finally, what was truly not ideal was our utilisation rate of 20% - the lowest since records begun in Sprint 20. Sadly, this particular metric is only a function of our desires to a small degree, and much more a function of the environment we operate in, so there is only so much we can do to optimise it. Overall, and given the constraints, one would have to conclude this was a pretty efficient sprint, though we do hope the utilisation rate can start to climb to number levels in the near future.

Figure 6: Cost of stories for sprint 27.
Roadmap
Our oracular project plan suffered the traditional updates - that is, move everything forward by a sprint and pray next sprint delivers some action on the sprint goals. To be perfectly honest, there is a very clear pattern asserting itself, which is to say the clean up associated with the LPS is extremely difficult and utterly impossible to estimate. So the always dubious project plan has become of even less value. But since it also works as a roadmap, we'll keep nudging it along - just don't read too much (or anything, really) into those dates. We never did.


Binaries
You can download binaries from either Bintray or GitHub, as per Table 1. All binaries are 64-bit. For all other architectures and/or operative systems, you will need to build Dogen from source. Source downloads are available in zip or tar.gz format.
| Operative System | Format | BinTray | GitHub |
|---|---|---|---|
| Linux Debian/Ubuntu | Deb | dogen_1.0.27_amd64-applications.deb | dogen_1.0.27_amd64-applications.deb |
| OSX | DMG | DOGEN-1.0.27-Darwin-x86_64.dmg | DOGEN-1.0.27-Darwin-x86_64.dmg |
| Windows | MSI | DOGEN-1.0.27-Windows-AMD64.msi | DOGEN-1.0.27-Windows-AMD64.msi |
Table 1: Binary packages for Dogen.
Note: The OSX and Linux binaries are not stripped at present and so are larger than they should be. We have an outstanding story to address this issue, but sadly CMake does not make this a trivial undertaking.
Next Sprint
The goals for the next sprint are:
- to finish PMM generation;
- to implement locator and dependencies via PMM.
That's all for this release. Happy Modeling!