Implementation of demo from "PKF: online state estimation under a perfect perceptual quality constraint" (Freirich et al., 2023) (Arxiv: https://arxiv.org/abs/2306.02400) (Poster: https://neurips.cc/media/PosterPDFs/NeurIPS%202023/71479.png?t=1699544143.6985004)
{kind=link}
to execute run:
python ./run_osc_demo.pyor
./run_demo.shIf you find our work inspiring, please cite us using the following Bibtex entry:
@article{freirich2023perceptual,
title={Perceptual Kalman Filters: Online State Estimation under a Perfect Perceptual-Quality Constraint},
author={Freirich, Dror and Michaeli, Tomer and Meir, Ron},
journal={arXiv preprint arXiv:2306.02400},
year={2023}
}

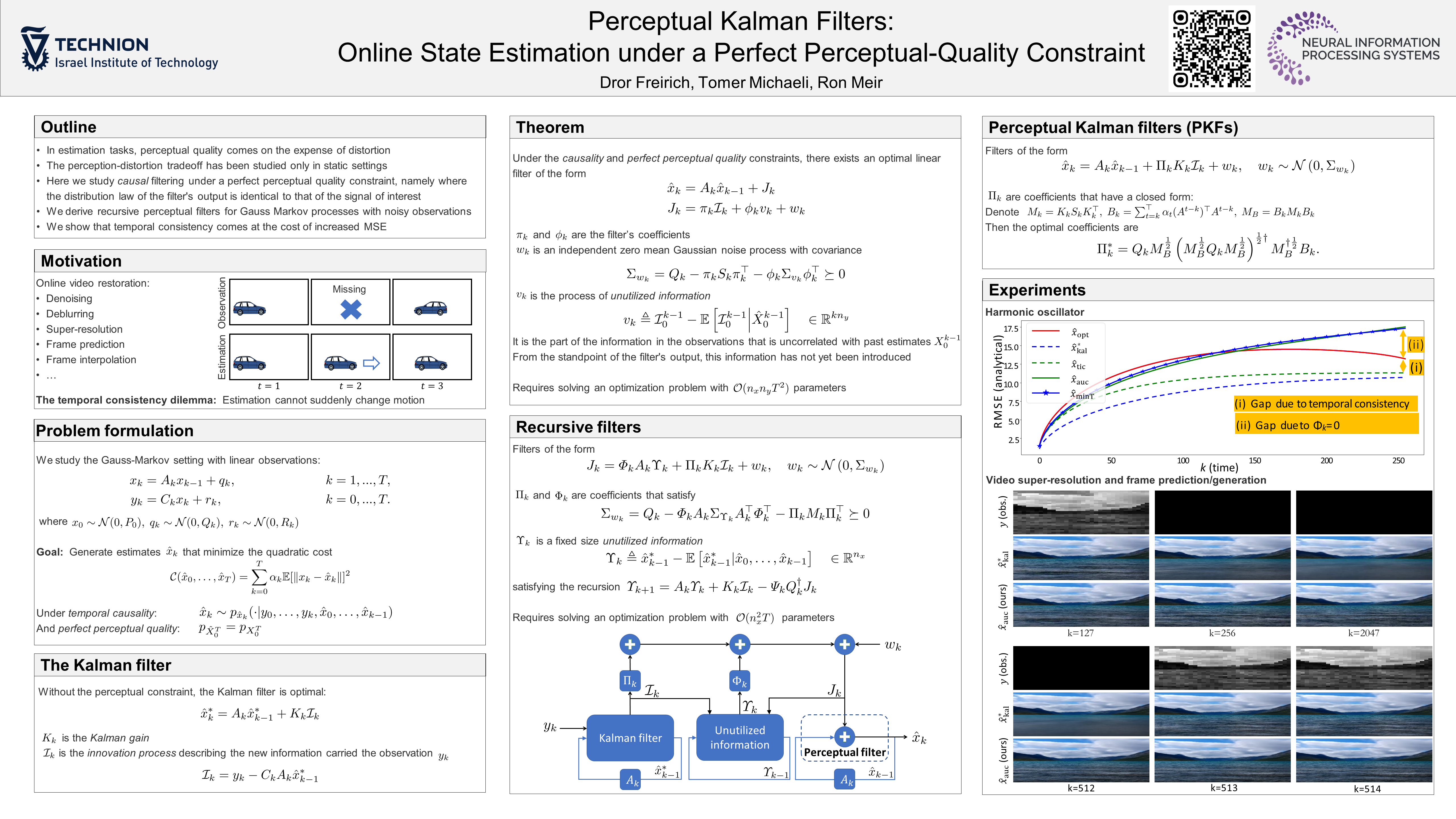
Example: real time video streaming

Sensory data from the scene might be compressed/corrupted/missing.
Reconstruction to the viewer must be done in real-time.
reconstructed scene must look natural.
The latter demand for realism means that not only each frame should look as a natural image, but motion should look natural too. That makes us face the Temporal Consistency dilemma: Estimation cannot suddenly change the motion in the output video, because such an abrupt change would deviate from natural video statistics. Thus, although the method is aware of its mistake, it may have to stick to its past decisions.

We study the theoretic Gauss-Markov setting with linear observations:
The problem is to minimize the Quadratic cost under the Temporal causality and Perfect perceptual quality constraints:.
Without the perceptual constraint, the Kalman state is a MSE-optimal causal estimator.
We present the following formalism for linear perceptual filters with coefficients

given by the recursion
We suggest the simplified form
Now, the optimal coefficients are given explicitly (see full details in our paper)
Algorithm - Perceptual Kalman Filter (PKF):
FOR k=1 to T DO:
calculate:
compute optimal gain:
sample:
update state:
Watch the video:
