This is the code for Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos. This code was developed using python 3.8.5 with pytorch 1.13.1 on a CUDA 11.3 machine.
A suitable conda environment named vidm can be created
and activated with:
conda env create -f environment.yaml
conda activate vidm
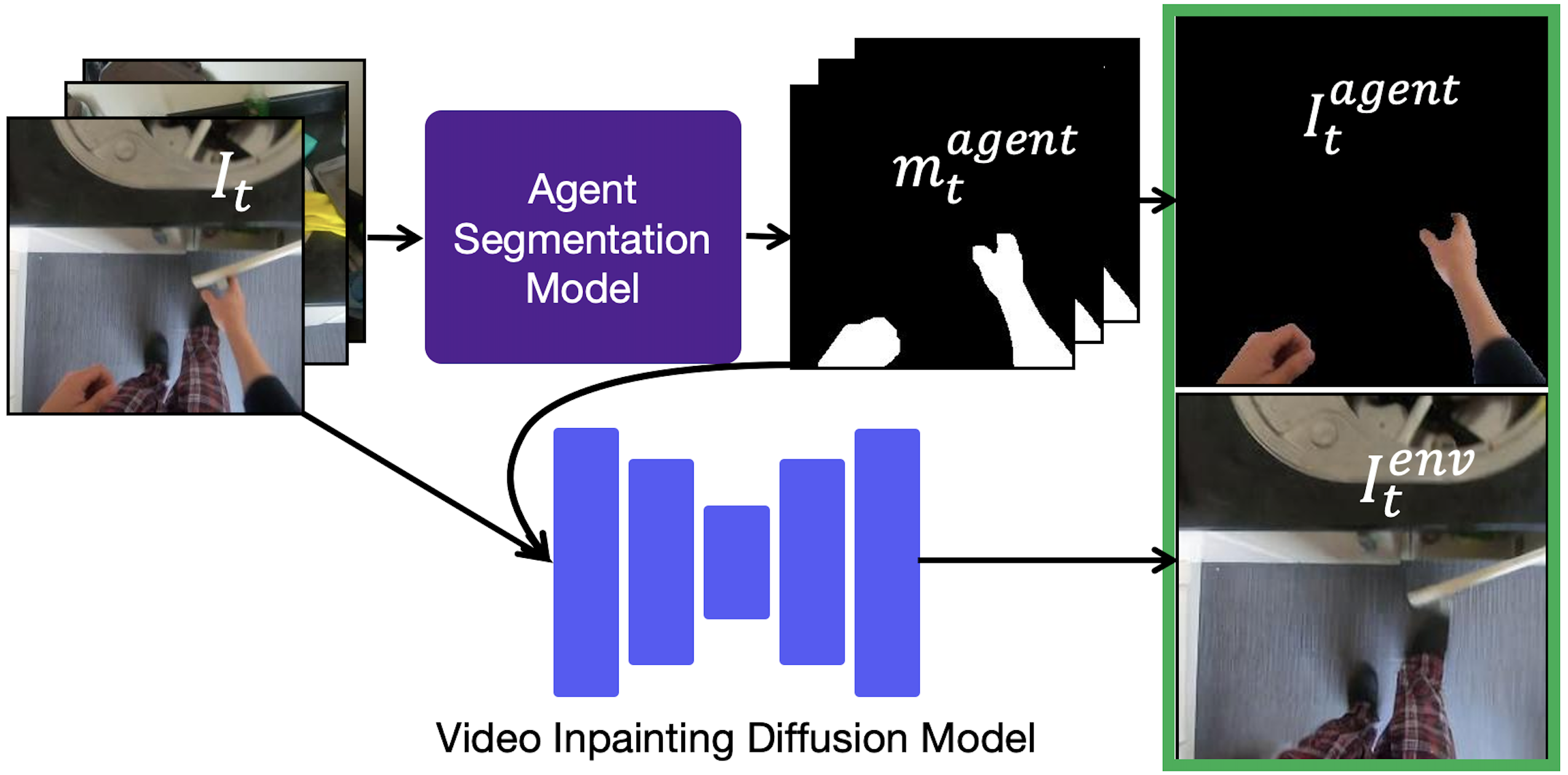
We have included some demo images and a script to perform inference using pre-trained weights to remove the human hands.
Pre-trained weights can be downloaded from here. This file nohands_weights.ckpt should be place in models/nohands_weights.ckpt.
You can run the demo script with
python demo_script.py demo_data
This script will write output.png showing the inputs and inpainting results.
This model was trained using data from three sources. Images from EPIC-KITCHENS, EGO4D, and annotations for EPIC-KITCHENS images from EPIC-KITCHENS VISOR. Download instructions for each of these sources can be found on their respecrive project pages.
For EGO4D we only downloaded data for the sequnences specified in data/ego4d_kitchen_ids.txt. These are all sequences which contain the word 'kitchen' in the narration summary text.
For the hardware stack used in training these models, we processed raw images into larger HDF5 files to reduce the number of files on disk. If this is not necessary it may be more expediant to skip the below steps and modify the dataloaders as necessary.
For hand detection on EGO4D, we used the models trained for 100 days of hands (100DOH) here. This model (config and weights) should be installed to a folder called 100doh in the root of this project.
python scripts/ego4d_to_hdf5.py [EGO4D_FULL_SCALE_LOCATION] [EGO4D_HDF5_LOCATION]
where [EGO4D_FULL_SCALE_LOCATION] is the location of the full-scale video downloads from EGO4D and [EGO4D_HDF5_LOCATION] is the output location for HDF5 files.
For compressing the EPIC-KITCHENS data to HDF5s run
python scripts/epic_to_hdf5.py [EPIC_DOWNLOAD_LOCATION] [EPIC_HDF5_LOCATION]
where [EPIC_DOWNLOAD_LOCATION] should be replaced with the path to the root of the EPIC-KITCHENS data and [EPIC_HDF5_LOCATION] is the folder to output the HDF5 files to.
For visor data first we need to unzip the dense annotations. Run
python scripts/unzip_visor.py [VISOR_DOWNLOAD_LOCATION]/Interpolations-DenseAnnotations
where [VISOR_DOWNLOAD_LOCATION] should be replaced with the path to the root of the visor annotations. This will unzip the dense annotations in place. Then for compressing the VISOR annotation data to HDF5s
python scripts/visor_to_hdf5.py [EPIC_DOWNLOAD_LOCATION] [VISOR_DOWNLOAD_LOCATION] [VSIOR_HDF5_LOCATION]
where [VSIOR_HDF5_LOCATION] is the output destination for the VISOR HDF5s.
First you need to download the inpainting_big model from LatentDiffusion into models/ldm/inpainting_big. This is the base for finetuning
wget -O models/ldm/inpainting_big/last.ckpt https://heibox.uni-heidelberg.de/f/4d9ac7ea40c64582b7c9/?dl=1
Training can be launched by
EGO4D_LOCATION=[EGO4D_HDF5_LOCATION] EPIC_ROOT=[EPIC_HDF5_LOCATION] DATA_LOCATION=[VSIOR_HDF5_LOCATION] python main.py --logdir [YOUR_OUTPUT_DIR] --base configs/inpaint_4frame.yaml -t --gpus 0,1,2,3
where the --gpus argument specifies the GPU ids to run training on.
@inproceedings{chang2023look,
title={Look Ma, No Hands! Agent-Environment Factorization of Egocentric Videos},
author={Matthew Chang and Aditya Prakash and Saurabh Gupta},
year={2023},
booktitle={Advances in Neural Information Processing Systems},
}