A comprehensive collection of Japanese and Chinese dictionaries for Yomichan/Yomitan, including terms, kanji/hanzi info, frequency, and variants with both monolingual and bilingual dictionaries available.
This repository contains dictionaries for Yomichan/Yomitan, a Japanese dictionary browser extension for Chrome, Firefox, and Edge. The repository was originally created to host the dictionaries I created, but I have since adapted this repository to serve as a hub for other dictionaries as well. If you have a dictionary you would like to share, please open an issue or pull request.
Please check here for information on what dictionaries to install.
My related dictionary resources:
- How Do I Make A Yomichan Dictionary?
- Yomitan Dictionary Stats - Information such as metadata and entry counts for many Yomichan dictionaries.
- Yomichan Dictionary Builder - A node package I built to help with making dictionaries. It greatly simplifies the process of making dictionaries, please try it out if you use TypeScript or JavaScript.
- Dictionary Collection
- Japanese
- Yomitan CSS for Non-Japanese CJK Languages
- Mandarin Chinese
- Cantonese
- Japanese-German
- Indonesian-English
- Japanese-Mongolian
- Korean
- Vietnamese-English
- Other
Here is a folder containing all the Japanese, Mandarin, and Cantonese dictionaries that I personally use and would recommend. I usually keep up to date with the latest versions of the dictionaries, and the folder is configured to automatically download and import the regularly updating dictionaries such as Jitendex, JMnedict, and KANJIDIC. If there is a dictionary in the folder that is outdated, please let me know!
Important
The collection is not complete as there are some dictionaries I feel are outdated or unnecessary or have simply chosen not to install. For these as well as older and alternate versions of dictionaries, I recommend checking out Shoui's Dictionary Collection.
If you're a beginner, I recommend following Shoui's Yomichan Setup. I would say the bare minimum is:
- Bilingual:
- [JA-EN] jitendex-yomichan
- [JA-EN] NEW 斎藤和英大辞典
- [JA-EN] 新和英
- Grammar:
- [JA Grammar] dojg-consolidated-v1_01
- Frequency:
- [JA Freq] JPDB_2022-05-10T03_27_02.930Z
- [JA Freq] Freq_CC100
- [JA Freq] BCCWJ-LUW
- Monolingual but still useful for coverage to a beginner! If a word shows up in one of these
dictionaries but not an English one, you can just web search/translate to find out more
information.
- [JA-JA] 実用日本語表現辞典
- [JA-JA] デジタル大辞泉
- [JA-JA Encyclopedia] Pixiv
- Kanji information
- [Kanji] KANJIDIC_english
- [Kanji] JPDB Kanji
- Pitch accent
- [Pitch] 大辞泉
If you're a bit more familiar with the language, I highly recommend following Kuri's Yomichan Setup which goes in depth with the technical setup process and recommends you install around thirty dictionaries, with a lot of thought having been put into the selections.
My personal recommendation is to install everything. With every dictionary installed, you know that any (actual) word you come across will almost certainly be in your Yomitan installation, and that you will have a good selection of definitions for almost any word. Most dictionaries on their own do not that high of a breadth of coverage so having less dictionaries installed means you may run into confusion when you fail to look up a word. Some of the dictionaries cover quite different subject areas as well - hover a cultural reference and you will be more likely to find it in the Pixiv dictionary than any other.
If you install a lot of dictionaries and/or sync your dictionary collection across multiple devices, it can be quite the ordeal to change the sort order with the way Yomitan's UI is set up. I have written a script that will automatically sort your dictionaries for you. You can find it here: Yomitan Dictionaries Sort Script.
To use it, simply copy the script, open the Yomitan options page, open the console, paste the script, and press enter. It will automatically sort your dictionaries for you.
By default, the sort order used is the one that I use and it supports all the dictionaries in the
folder. If you want to use a different sort order, you can edit the script to change the order
variable at the top.
For an easy download of the dictionaries I use, check out this folder.
Do check out yomichan-dict-css for CSS that colors some term dictionaries to make them more immediately distinguishable.
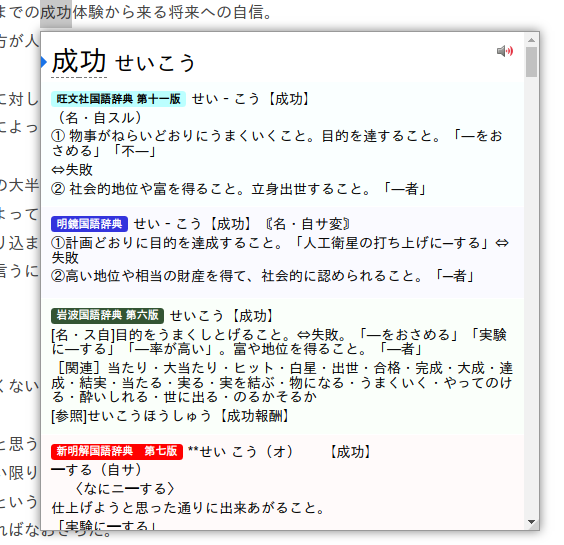
Jitendex is a free and openly licensed Japanese-to-English dictionary built upon data from JMdict and other projects. It is the successor to JMdict for Yomichan.
The most extensive JP-EN dictionary using data from the EDRDG Project created by Jim Breen. It is recommended you use Jitendex unless you need a legacy version of the dictionary for technical reasons.
A dictionary of Japanese proper names. The linked version is advantageous over the one linked on the Yomichan homepage as it clutters the search page much less when searching, so it's highly recommended.
There are various bilingual dictionaries in Shoui's bilingual folder. Check the readme in the folder for further information.
- 新和英 (Recommended)
- Same as the 研究社 新和英大辞典 第5版 with better deconjugation but lacking some additional sentences.
- 研究社 新和英大辞典 第5版
A bilingual dictionary by an anon, with lots of example sentences. You may want to limit the amount of example sentences to avoid cluttering the search page by using the following CSS, where the number 5 can be changed:
[data-dictionary='NEW斎藤和英大辞典'] ul.gloss-sc-ul > li:nth-child(n + 5) {
display: none;
}There are various monolingual dictionaries in Shoui's monolingual folder, authored by various people. Check the readme in the folder for further information, and check the explanation on learnjapanese.moe on how to use them. Currently contains:
- 広辞苑 第七版
- Converted by Thermosphere and shoui.
- 三省堂国語辞典 第七版 (Recommended)
- 実用日本語表現辞典 (Recommended)
- 新明解国語辞典 第七版 (Recommended)
- 明鏡国語辞典 第二版 (Recommended)
- 旺文社国語辞典 第十一版 (Recommended)
- Converted by irhello and shoui.
- Weblio 古語辞典
- Scraped/converted by 昔男/mk68.
- 精選版 日本国語大辞典
- 明鏡国語辞典
- 旺文社国語辞典 第十一版 画像無し
- 新明解国語辞典 第五版
- 故事ことわざの辞典
- Converted by Thermosphere with Yomichan Import
- 広辞苑 第六版
- 岩波国語辞典 第六版
- 大辞林 第三版
- ハイブリッド新辞林 v2
- デジタル大辞泉
- Converted by ッツ.
- 新明解四字熟語辞典
- Converted by ッツ.
- 学研 四字熟語辞典
- Converted by ッツ.
- 日本語俗語辞書
- Scraped/converted by Kartoffel.
- 漢字源
A monolingual dictionary made by an anon, with very nice formatting and links for related terms.
Images



There are many dictionaries available at 辞典オンライン and using stephenmk's jitenbot, some of these have been scraped for use as Yomichan dictionaries. There are quite a few entries that aren't in other dictionaries, so I'd recommend installing this.
Includes the following dictionaries:
Images (click to expand)


Converted by Malte using stephenmk's jitenbot.
Converted by Malte using stephenmk's jitenbot.
Converted by Malte using stephenmk's jitenbot.
Converted by dictionary anon, this dictionary has nice modern formatting.
Images (click to expand)




Converted by dictionary anon, this dictionary has nice modern formatting.
Recommended custom CSS:
li[data-dictionary^='新選国語辞典'] th,
span[data-sc-shinsenkoku10='warichu'] {
white-space: nowrap;
}
span[data-sc-shinsenkoku10='red'] {
color: #e5007f;
}Images (click to expand)




Scraped by Malte from the online goo.ne thesaurus.
Images (click to expand)

Scraped by Malte from the online goo.ne dialect dictionary.
Note
Note: This version has some (~650) entries formatted like そーだ instead of そうだ which can be annoying.
Scraped from http://www.breaking-news-words.com/ by Malte.
「新語時事用語辞典」は、ニュースで今最も話題になっている最新のキーワードを時流に即して紹介する、速 報・辞書サイトです。新聞で、テレビで、ネットで話題になっているキーワードや流行語をいち早く紹介しま す。
Scraped from http://www.practical-japanese.com/ by Malte. Updated version of the old yomichan dictionary.
Scraped by Julian and converted by Malte, sourced from Kanjipedia.
This dictionary differentiates the usages of words with the same reading but different kanji, for example 越える・超える・逾える・踰える.
A collection of grammar dictionaries scraped and converted by aiko-tanaka. A lot of manual work was put in to creating them to make them parse well, I'd recommend you install all of them. Contains:
- Nihongo no sensei 毎日のんびり日本語教師
- E de wakaru 絵でわかる日本語
- Nihongo Kyoshi JLPT 文法解説まとめ
- Donna Toki どんなときどう使う 日本語表現文型辞典
- DoJG 日本語文法辞典(全集)
A conversion of the DBPedia short-abstract dumps of JA Wikipedia for Yomitan. This dictionary features over 1.2 million entries with each entry containing the abstract and a link to the Wikipedia article. Unfortunately there are no dumps of DBPedia after December 2022, so regular updates will not be possible until DBPedia starts updating again.
Last Updated: 2023-11-24
Download Pixiv | Download PixivLight
A complete scrape of the public dic.pixiv.net encyclopedia of over 500,000 entries, containing a brief summary and links to related articles for each entry. This dictionary is quite extensive and contains entries for a vast amount of terms that would not be in traditional dictionaries. For instance, 和泉妃愛 has an entry as does likely every notable VTuber, media franchise, and mountain in Japan.
Important
This dictionary is quite large and may take a long time to import.
- If performance of your device is an issue and you are unable to import the full Pixiv dictionary, you can use the PixivLight version which has most of the extra information like categorization and related articles stripped out, leaving behind only the short summary and a link to the main Pixiv article. This version is much smaller and should import without crashing Yomichan on mobile phones and ereaders.
- For CSS to convert the links to plaintext in Anki see MarvNC#31.


Click to expand (obsolete)
Using the information gathered by ncaq for use in an IME, this is a dictionary that can help parse terms that are in both niconico and pixiv's online dictionaries. These online dictionaries are sort of like encyclopedias of the internet, so many terms such as proper nouns not in traditional dictionaries will be found.
ルールベースで IME 辞書の役に立たなそうな単語を除外しています。
%E3%81%A8%E3%81%AF%E3%80%90%E3%83%94%E3%82%AF%E3%82%B7%E3%83%96%E7%99%BE%E7%A7%91%E4%BA%8B%E5%85%B8%E3%80%91_-_httpsdic.pixiv.net_2022-08-21_17-22-10.png)
A dictionary of onomatopoeia from surasura.com. Contains some onomatopoeia that are not in any other dictionaries. Credit to stephenmk for the idea to mark information using those emojis with his improved JMDict.
For each entry, it contains:
- A few definitions
- An extended explanation if available, marked with the ℹ️ emoji
- A few example sentences marked with the 🇯🇵 flag emoji

Compound kunyomi word origins/etymology, for example 陥る -> 落ち入る(おち|いる). Information comes from anonymous forum posts, so it may not be 100% accurate.

Sources:
語源由来辞典 etymology information parsed from https://gogen-yurai.jp/ by Seikou. Contains information about the origins of words.
A frequency dictionary based on information scraped from https://jpdb.io in May of 2022. More information can be found here.
Due to the way the data was scraped, some terms are missing frequencies and the jpdb dictionary itself is limited to terms in JMDict. For example, 経緯 only has an entry for the いきさつ reading so it should not be used as a dictionary for sorting (the more common/correct reading is けいい). However, the corpus of JPDB is quite good for immersion learners as it covers anime, dramas, light novels, visual novels, and web novels so the frequencies will be relatively accurate to what you're actually reading. This dictionary is notable for displaying the frequencies of kana readings separately, so you can often get a sense of how often a word is written with kanji or not.
A frequency dictionary created using data collected by vrtm based on the Aozora Bunko. Due to the methodology used, this dictionary does not cover words with kana in them but it covers many rare 熟語 not covered by other frequency dictionaries, such as 睽乖. The number in parentheses is the number of times the word appears in the corpus.
Made by the mind behind arujisho, this uses the CC100 dataset which was made by crawling the web. Coverage is very wide, and there is reason behind the way readings are differentiated which is why I use this as my Yomichan sort dictionary.
Original message by Seikou
Hello everyone! Recently I tokenized the CC-100 Japanese dataset (which is a high quality dataset filtered from Commoncrawl web crawl data, and is about 70GB large) as a corpus using mecab(fugashi) and sudachi, resulting a frequency rank list of about 900k words. After filtering it using several monolingual dictionaries, I got a freq rank list of roughly 160k words.
From the publication:
The balanced corpus of contemporary written Japanese (BCCWJ) is Japan’s first 100 million words balanced corpus. It consists of three subcorpora (publication subcorpus, library subcorpus, and special-purpose subcorpus) and covers a wide range of text registers including books in general, magazines, newspapers, governmental white papers, best-selling books, an internet bulletin-board, a blog, school textbooks, minutes of the national diet, publicity newsletters of local governments, laws, and poetry verses.
It has extremely wide coverage with most terms you'll encounter having an entry in this list even if other frequency lists don't. In addition, it differentiates between readings quite well. Make sure to install the LUW version as it has more terms.
The Innocent Corpus from the Yomichan page but reordered to be sorted by rank. It is based on data from 5000+ novels. A weakness is that it does not differentiate based on reading, so all readings of a term will show the same value.
A frequency dictionary created using monolingual dictionary definitions as the corpus, so it might be useful for those who really like reading dictionaries. Made by Avratzzz.
Dictionaries used:
- ハイブリッド新辞林 v2
- 故事ことわざの辞典
- 漢字源
- 精選版 日本国語大辞典
- 新明解四字熟語辞典
- 学研 四字熟語辞典
- 実用日本語表現辞典
- 明鏡国語辞典
- 旺文社国語辞典 第十一版
- 新明解国語辞典 第五版
- 大辞林 第三版
- デジタル大辞泉
- 岩波国語辞典 第六版
- 広辞苑 第六版
Download the full Youtube Frequency Dictionary
Download all domain-specific dictionaries
Using data from 40k manually transcribed YouTube videos we have created 16 domain specific frequency lists for YomiChan. Enjoy and feel free to share around. Created by @Zetta @Vexxed @Anonymous
Domain-specific frequency lists from Youtube Videos:
Domains:
- Vlogs
- Vehicles
- Travel
- TEDx
- Sports
- SciTech
- Pets/Animals
- Nonprofits
- News
- Music
- HowtoStyle
- Gaming
- Film/Anime
- Entertainment
- Education
- Comedy
Important
Due to the limited nature of the original data set, this frequency list only goes up to around 20,000 in frequency. It is still useful to know the relative frequency of words in conversation, but the frequency values should not be compared to those from other more expansive frequency dictionaries. For a more complete list that is somewhat conversational, I recommend trying the Youtube frequency list.
This Yomichan frequency dictionary based on the Corpus of Everyday Japanese Conversation was converted by forsakeninfinity.
The Corpus of Everyday Japanese Conversation (CEJC) is a vocabulary and word count table based on 200 hours of recorded data (approximately from April 2016 to 2020).
Our project will develop a large-scale corpus of Japanese everyday conversation in a balanced manner. Since informants record their conversations in everyday situations by themselves, naturally occurring conversations can be collected. To build an empirical foundation for the corpus design, we conducted a survey of ordinary conversational behavior of about 250 adults."
Some other miscellaneous frequency dictionaries in the Shoui Dictionaries Collection.
- Anime & J-drama
- Narou Freq
- Novels
- VN Freq v2
- Wikipedia v2
- 国語辞典
- Nier
Some frequency dictionaries made by this YouTuber OhTalkWho オタク.
- Netflix
- Top 100 Shonen
- Top 100 Slice of Life
- JLPT Level Tags
- Novel 5k
- This might just be innocent corpus with stars?
- Visual Novels
- Might be based off vnstats? It's different than the VN Freq v2 in Shoui's Dictionaries Collection.
Some frequency dictionaries made by Anacreon that are not rank-based, but rather percentage-based where the displayed value is the percent of that corpus you would be able to read if you knew every word with that percentage or lower. They are somewhat redundant with other previously mentioned dictionaries, but some people may prefer the percentage-based approach.
Frequency is displayed as a number between MOST frequent 0 and LEAST frequent 100. Check out this graph, essentially the number in these dicts are the Y axis of this graph. So if you were aiming for understanding 95% of words you come across the most efficient way would be to mine all the words with a freq less than or equal 95.
Yomichan and KANJIDIC by default have a lot of bloat in the kanji dictionary viewer, like repeating the kanji stroke order image, frequency information, and unused table rows for every entry. For using multiple kanji dictionaries, you can use some CSS to make the kanji display more compact like it is for terms.

In Settings -> Popup Appearance -> Configure custom CSS... input the following CSS for more
compact display of entries.
/* remove misc dict classifications/codepoints/stats */
.kanji-glyph-data > tbody > tr:nth-child(n + 3) {
display: none;
}
/* remove stroke diagram, freq, header for next entries */
div.entry[data-type='kanji']:nth-child(n + 2) .kanji-glyph-container,
div.entry[data-type='kanji']:nth-child(n + 2) [data-section-type='frequencies'],
div.entry[data-type='kanji']:nth-child(n + 2) table.kanji-glyph-data > tbody > tr:first-child {
display: none;
}
/* remove 'No data found' */
.kanji-info-table-item-value-empty {
display: none;
}
/* reduce extra padding */
.kanji-glyph-data,
div.entry[data-type='kanji'],
div.entry[data-type='kanji']:nth-child(n + 2) .kanji-glyph-data > tbody > tr > *,
.kanji-glyph-data dl.kanji-readings-japanese,
div.entry[data-type='kanji']:nth-child(n + 2)
.kanji-glyph-data
dl.kanji-readings-chinese[data-count='0'] {
padding-top: 0 !important;
padding-bottom: 0 !important;
margin-bottom: 0em;
margin-top: 0 !important;
}
/* remove horizontal lines */
.entry + .entry[data-type='kanji'],
div#dictionary-entries > div.entry:nth-child(n + 2) .kanji-glyph-data > tbody > tr > * {
border-top: none !important;
}
/* change decimal list */
.kanji-gloss-list {
list-style-type: circle;
}The KANJIDIC Project's KANJIDIC is the primary English kanji dictionary used in Yomichan and contains information about most kanji, notably English definitions, readings, and some other statistics like stroke count, JLPT, grade level.
Kanji information of around 18,000 characters from Wiktionary, notably:
- 呉音, 漢音, 唐音, 宋音, 慣用音 onyomi readings of kanji (further reading)
- 字源 - information about how and why a kanji is composed the way it is, including the type of composition it is
- The meaning of the kanji (in Japanese)
- The various 異体字 of the kanji

Kanji information of around 6,000 characters from https://jpdb.io:
- The 15 most common vocab applicable
- The kanji decomposition according to jpdb (has inaccuracies because it's meant for memorizing keywords)
- 漢字検定 level
- 旧字体/新字体/拡張新字体 character form

Download | List of possible phonetic components
Information from TheKanjiMap:
- Radical information for all radicals
- Kanji decomposition (more accurate than JPDB)
- List of all kanji that contain a kanji/component/radical
- Reading hints based on possible phonetic components (computed based on information from KANJIDIC and the decomposition here)


The online 漢字辞典オンライン kanji dictionary is an extensive Japanese kanji dictionary. It was converted into a Yomichan kanji dictionary by eurusdagr.
(Click to expand) Example image

{kind=link}
A kanji dictionary made from the kanji variant information in Google's mozc Japanese IME. Includes information about:
- 異体字
- 印刷標準字体
- 簡易慣用字体
- 旧字体
- 略字
- 正字
- 俗字
- 別字
- 本字

A kanji dictionary made using the data from jitai. This allows you to see information about 旧字体, 新字体, 拡張新字体, and 標準字体 variants from the kanji page in Yomichan.

A kanji frequency dictionary created using data collected by vrtm based on the Aozora Bunko. The number in parentheses is the number of times the kanji appears in the corpus.
Uses the innocent corpus frequency list that is distributed with Yomichan to create a rank-based kanji frequency dictionary. This was created because the existing one is an occurence-based list and does not display ranks.
- The displayed frequency in Yomichan will contain the frequency rank followed by the occurence
count, for example
4686 (57)for 壟 indicating it's the 4686th most common kanji and appeared 57 times total in the 5000+ novels in Innocent Corpus.
Rank-based kanji frequency data from a May 2015 dump of Japanese Wikipedia, containing around 2 万 kanji. Data gathered by scriptin.
Kanji frequency data from https://jpdb.io as a Yomichan frequency dictionary.
Yomitan by default renders everything in Japanese leading to incorrect glyphs being rendered when using Yomitan with non-Japanese CJK languages. This can be fixed with some CSS.
/* Set Render Language */
* {
/*
Optionally set the version(s) of Noto Sans or another font you want in your preferred order.
e.g. JP, TC, SC, HK
*/
/* prettier-ignore */
font-family:
'Noto Sans HK',
'Noto Sans TC',
'Noto Sans SC',
'Noto Sans JP',
sans-serif;
/*
ja (Japanese)
zh-Hans (Simplified)
zh-Hant (Traditional)
zh-Hant-HK (Traditional Hong Kong)
*/
-webkit-locale: 'zh-Hant-HK' !important;
}
/* In Hanzi popups and the search box, override the font */
.kanji-glyph,
#search-textbox {
font-family: unset !important;
}
/* Set Render Language End */Simply copy this CSS into Settings -> Popup Appearance -> Configure custom CSS... and change the
font-family and -webkit-locale variables to the language you want.
- Setting the font family here is optional; setting the
webkit-localeshould be enough to fix the issue. However your default system fonts may look bad so I recommend installing Noto Sans.- In the above CSS, the order of the fonts means that when a glyph is not found in the Noto Sans TC font, it would then try to find it in the Noto Sans SC font, and so on.
- Note that Firefox users need to set the
font-language-override
property instead of the
-webkit-localeproperty as it is not supported in Firefox.
For an easy download of the dictionaries I use, check out this folder.
For CSS to fix the rendering of non-Japanese characters in Yomitan, see this section.
CC-CEDICT dictionary for Yomichan
There was a previous version but the formatting wasn't as great and it was kind of outdated. So I created this repository with some more modern formatting and also added proper hanzi functionality. The repository automatically updates every day from the newest data at MDBG.
Shoui's Chinese Yomichan Setup
These Chinese Yomichan dictionaries are hosted in Shoui's guide to setting up Yomichan for Chinese, includes:
[ZH-EN] CEDICT(Outdated) (converted by an anon)[ZH-JA] 中日大辞典 第二版(converted by an anon)[ZH-ZH] 兩岸詞典(converted by Chrono7 on the Refold ZH Discord server)[ZH-ZH] 漢語大詞典(converted by Chrono7 on the Refold ZH Discord server)[ZH-ZH] 萌典国语辞典 (简体字)(converted by Chrono7 on the Refold ZH Discord server)
Simplified Chinese Versions
Michel converted some of the above dictionaries to simplified Chinese.
- Download
汉语大词典- The Hanyu Da Cidian is the most comprehensive Chinese dictionary, comparable to the Oxford English Dictionary.
- Download
两岸词典- The Cross-Straits dictionary is a small mainland dictionary focusing on contemporary usage and the differences between Taiwan and Mainland Chinese.
A conversion of the DBPedia short-abstract dumps of ZH Wikipedia for Yomitan. This dictionary features over 1.2 million entries with each entry containing the abstract and a link to the Wikipedia article. Unfortunately there are no dumps of DBPedia after December 2022, so regular updates will not be possible until DBPedia starts updating again.
These miscellaneous Chinese Yomichan dictionaries were made by lix on the Refold ZH Discord server. Includes:
- 萌典.pinyin
- 萌典
- 牛津英汉汉英词典
- 现代汉语规范词典
- 譯典通英漢雙向字典
- 五南國語活用辭典
Published in July 2003 and revised through 2005, the Wenlin ABC Chinese-English Comprehensive Dictionary was produced by the Wenlin Institude in cooperation with the ABC Chinese Dictionary Series Project at the University of Hawaii. It contains over 196,000 entries. This file was converted by rduwjjnh.
| Title | Corpus | Download |
|---|---|---|
BLCUmixed |
A Balanced Mix from Magazines, Literature, Weibo, Tech | Link |
BLCUlit |
Literature (Foreign and Domestic) | Link |
BLCUnews |
Newspapers《厦门日报》、《厦门商报》、《厦门晚报》等 | Link |
BLCUsci |
Scientific and Technological Academic Journals | Link |
BLCUcoll |
Dialogue (Weibo and Movie/TV Subtitles) | Link |
A Yomichan frequency list made from the comprehensive Beijing Language and Culture University Corpus Center (BLCU BCC)'s corpus containing over 9 billion characters. Thanks to nadavspi and Michel who converted it for Yomichan.
This is a subtitles frequency list based on over 6,000 simplified Chinese movies and TV shows from the SUBTLEX frequency list, which was compiled by Ghent University. Thanks to nadavspi and Michel who converted it for Yomichan.
This Yomichan HSK Levels frequency list is based on the official HSK word list from the Chinese Ministry of Education released in 2021, which was then OCRed and neatly formatted thanks to Andy Burke . Thanks to Michel who converted it for Yomichan.
A general Chinese frequency dictionary that is likely based off of "the chinese internet, movies, books, etc as a whole" according to its author Kamui.
See Yomichan CSS for Kanji Dictionaries for CSS used to reduce the clutter included by default in Yomichan.
Note
The default kanji stroke order font included with Yomichan is made for kanji stroke orders, and as thus will contain incorrect glyphs and stroke orders for Chinese that may be misleading. You can change this by using some CSS:
.kanji-glyph {
font-family: sans-serif; /* or a whatever font you prefer for Chinese */
}Hanzi information of nearly 100,000 characters from ZH Wiktionary. Due to the complexity of the wiktionary pages, it will display most of the text on the page, excluding tables and such so the pinyin readings may not be included for many characters. In addition, do note that for some uncommonly used characters there is little information available as the wiki pages often consist of just unicode information and code points, which was stripped from the dictionary.

For an easy download of the dictionaries I use, check out this folder.
For CSS to fix the rendering of non-Japanese characters in Yomitan, see this section.
CantoDict was a Cantonese-English dictionary created and maintained by Adam Sheik and public contributors. It was abandoned, but the data was archived thanks to awong-dev at https://github.com/awong-dev/cantodict-archive. This dictionary is based off of the archived data.


Thanks to richter_belmont on the Refold Cantonese Discord:
I converted all of the Migaku dictionaries from the "Learn Cantonese!" shared folder on Google Drive into Yomichan dictionaries. List of dictionaries available are:
- Canto CEDICT
- CC-Canto
- CE Wiktionary
- Words.hk C-C
- Words.hk C-E
Spoken and written Cantonese frequency dictionaries for Yomitan from Cifu.
-
Spoken data from
HKCanCor (Luke and Wong, 2015), HKCAC (Leung and Law, 2001), CantoMap (Lai and Winterstein, 2019) -
Written data from 3,841 chapters of amateur novels from the website https://www.shikoto.com/.
Paper with more information about their methodology:
Lai, Regine and Winterstein, Grégoire (2020) "Cifu: a Frequency Lexicon of Hong Kong Cantonese", in Proceedings of The 12th Language Resources and Evaluation Conference, Marseille: European Language Resources Association, p. 3062--3070.
Converted by Julian, 和独辞典 is a Japanese-German Yomichan dictionary based on the Wadoku dictionary.
Converted by Julian from the 和独大辞典.
- Über 130.000 Stichwörter der modernen japanischen Sprache (frühe Meiji-Zeit bis Gegenwart) mit zahllosen Zusammensetzungen und Anwendungsbeispielen
- Lateinumschrift aller Stichwörter und der Zusammensetzungen mit Kanji
- ca. 70.000 Satzbelege aus Zeitungen, Zeitschriften, Werbung, Wissenschaft und Literatur mit Quellenangaben
- Markierter Grund- und Aufbauwortschatz
- Historische und fachsprachliche Erläuterungen
- Herkunftsangaben und gesicherte Etymologien
- Sprichwörter und idiomatische Wendungen
- Fach- und Sondersprachen (Kinder- und Jugendsprache, Gaunersprache, Dialektismen)
- Auflösungen von Abkürzungen
- Fachvokabular u. a. aus den Bereichen Architektur · Astronomie · Biologie und Biochemie · Chemie · Computertechnologie · Elektrotechnik · Flora und Fauna (mit Angabe der wissenschaftlichen Nomenklatur) · Geowissenschaften · Linguistik · Mathematik · Medizin · Musik · Physik · Recht · Sport · Technik · Wirtschaft und Finanzen
![NOTE] Relatively rough conversion, more or less the entries as you'd find them on the website ^^ - might get updated in the future (converting the "tags" to actual tags etc.) . It ups the coverage that you'd get from only using Jmdict German and can be a great tool to use alongside other dicts - may it be as a source for example sentences etc.
Kamata created a Indonesian Yomichan dictionary that shows the English definition of Indonesian words. The data is from Wiktionary.
Download | No example sentences version
A Japanese to Mongolian dictionary scraped from 栗林均's site. It contains about 19,000 entries.
現代日・モ辞典橋本勝、エルデネ・プレブジャブ『現代日本語モンゴル語辞典』春風社、2001.

See Yomichan For Korean for a fork of Yomichan that supports Korean.
On that repository the following dictionaries are listed:
- KRDICT (KR-EN / KR-JP / Monolingual)
- Naver (KR-JP)
Note that there is an alternative krdict-yomichan but this dictionary is no longer necessary due to the conjugation support added in Lyroxide's fork of Yomichan.
VNEDICT by Paul Denisowski converted by Marsh Nguyễn for Yomichan.
From OVDP (Open Vietnamese Dictionary Project).
The Yomichan fork Yezichak has support and custom dictionaries for the following languages:
- Albanian
- Arabic
- Ancient Greek
- English
- French
- German
- Greek
- Indonesian
- Italian
- Japanese
- Latin
- Persian
- Polish
- Portuguese
- Russian
- Serb-Croatian
- Spanish