This repository is a MATLAB code of a simple text-dependent speaker-recognition system. The team implemented two approaches:
- LPCs averaging
- MFCC
The code is written by Michael Malak, Ziad Mansour, and Karim Rashidy for a Digital Speech Processing course in Spring 2018. It is important to mention that the MFCC code is cloned from Mike Brook's Voicebox github repository which is made available under the terms of the GNU Public License as mentioned in his documentation. The cloned files are the following:
disteusq.menframe.mfrq2mel.mkmeanlbg.mkmeans.mmel2frq.mmelbankm.mmelcepst.mrdct.mrfft.mrnsubset.mvoicebox.mwinenvar.m
Speaker recognition aims to identify the person who is making a speech or talking by the use of certain tools and processes. A summary of a typical speaker/speech recognition system is based on four functional stages of processing. The four stages are mainly data acquisition, feature extraction, data modeling and finally the decision based on the previous stages. Meanwhile, speaker verification is the idea of accepting or rejecting a certain identity. In fact, when an unknown voice is being checked/processed, the system compares the features of this identity with the already saved models and tries to find a match for it. This process, however, needs a huge and rich training data set in order to be able to correctly model the characteristics of the speaker’s voice and to be able to cover the phonetic space as much as possible.
LPC is a tool used mostly in audio signal processing and speech processing for representing the spectral envelope of a digital signal of speech in compressed form, using the information of a linear predictive model. It is one of the most powerful speech analysis techniques, and one of the most useful methods for encoding good quality speech at a low bit rate and provides extremely accurate estimates of speech parameters.
The advantages of this technique is the ease of construction and the low complexity of the code. In fact, it might take very small time to train and test the samples and have somehow a valid outcome. But on the other hand, the performance compared to other techniques might be low.
Implemented in Main_Phase1.m.
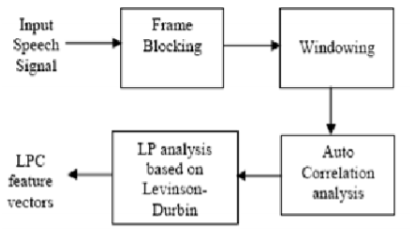
The FRAME_LENGTH parameter is chosen to be 20ms as it best fits our audio recordings. Each .wav file is framed using the functions previously written in our course labs, and the energy and the zero-crossings rate is measured to enable us to get the start and end point of each audiofile. Here is a block diagram for what generally happens in the LPC method.
The training is done on several audio samples, and the LPCs are calculated for each sample and at the end, we calculate the average of this matrix to get the final LPC parameters for every speaker.
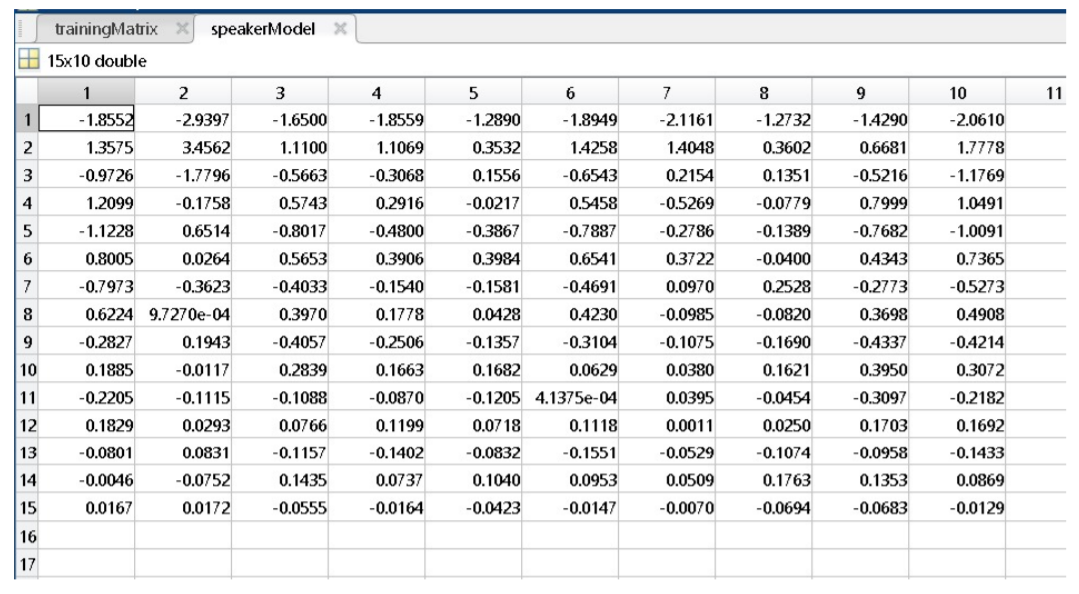
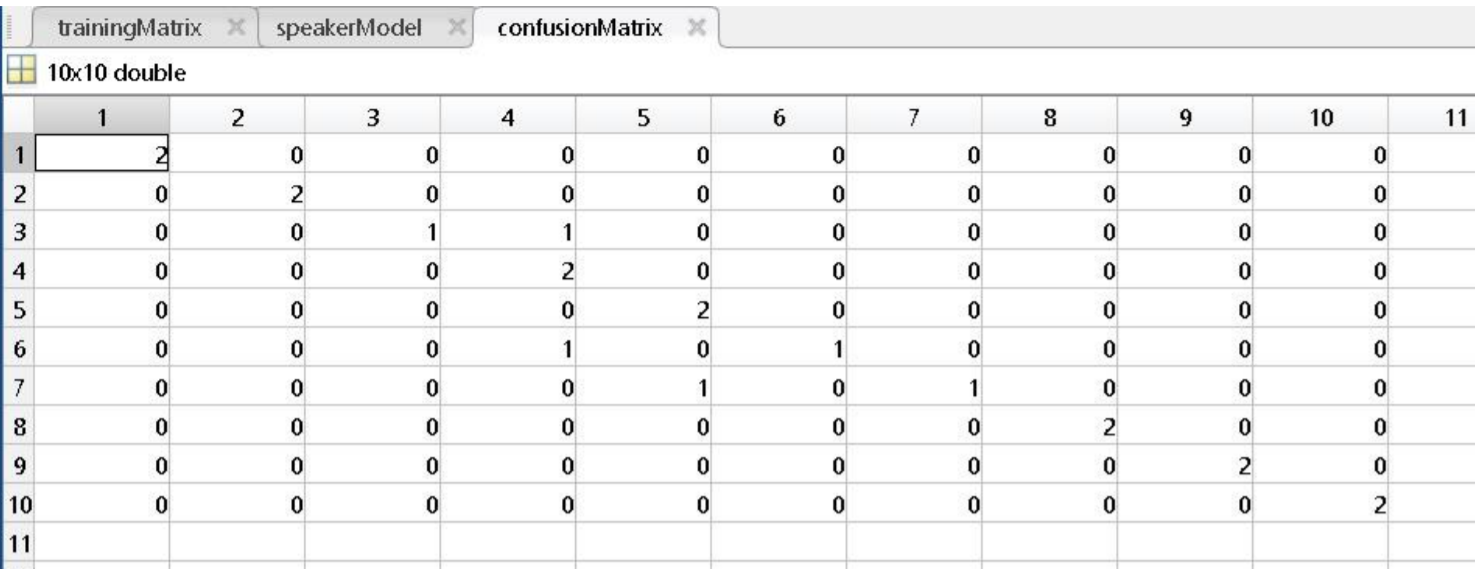
A speaker model at the end is a matrix containing the average LPCs of all the speakers. Each column represents only one speaker. For instance, in the screenshots below, there are 10 speakers and 15 LPCs.
Implemented in Main_Phase1.m.
The test is done in a similar way to the training on different audio samples than of the training. After finishing those steps, Euclidean distance rule is applied. The Euclidean distance is applied to all the LPCs to all the speakers, and then observing the minimum one. The minimum distance corresponds to the identified speaker which is then represented in the confusion matrix to find the accuracy percentage in the end.
In sound processing, the Mel-frequency Cepstrum (MFC) is a representation of the shortterm power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear Mel scale of frequency.
Mel-frequency cepstral coefficients (MFCCs) are coefficients that collectively make up an MFC. They are derived from a type of cepstral representation of the audio clip (a nonlinear "spectrum-of-aspectrum"). The difference between the cepstrum and the mel-frequency cepstrum is that in the MFC, the frequency bands are equally spaced on the mel scale, which approximates the human auditory system's response more closely than the linearly-spaced frequency bands used in the normal cepstrum. This frequency warping can allow for better representation of sound.
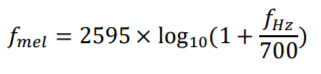
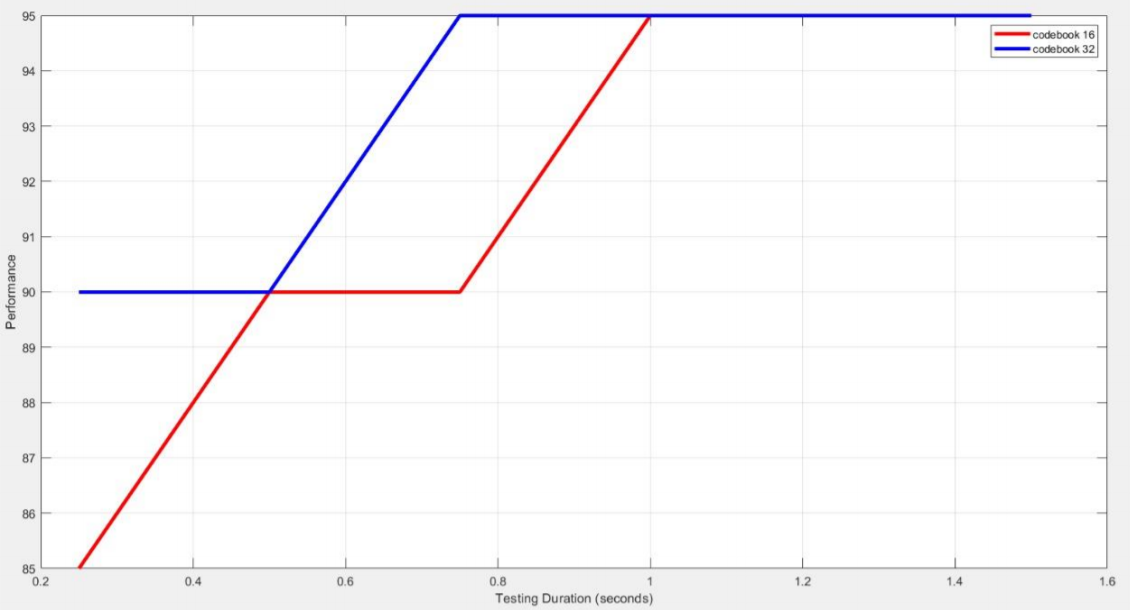
This technique is rather complex but more accurate. Overall, this performance has higher complexity than that of the LPC, but when comparing the ones of the codebook-number 16 with that of 32 it is less complex. So we need to take into considerations the trade-offs before implementing the technique.
Implemented in Main_Phase2_Train.m.
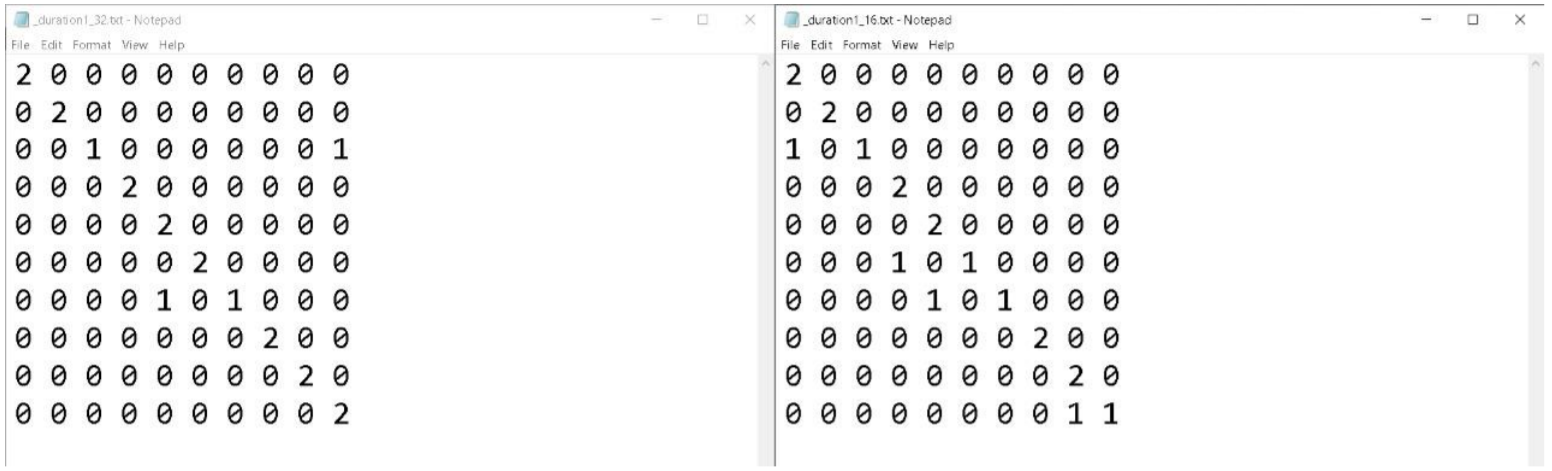
In the MFCC, we need firstly to use training samples to get the matrix features for each speaker. Depending on the codebook-number whether being 16 or 32, each speaker will have to unique text files including his/her centroids for time saving.
Implemented in Main_Phase2_Test.m.
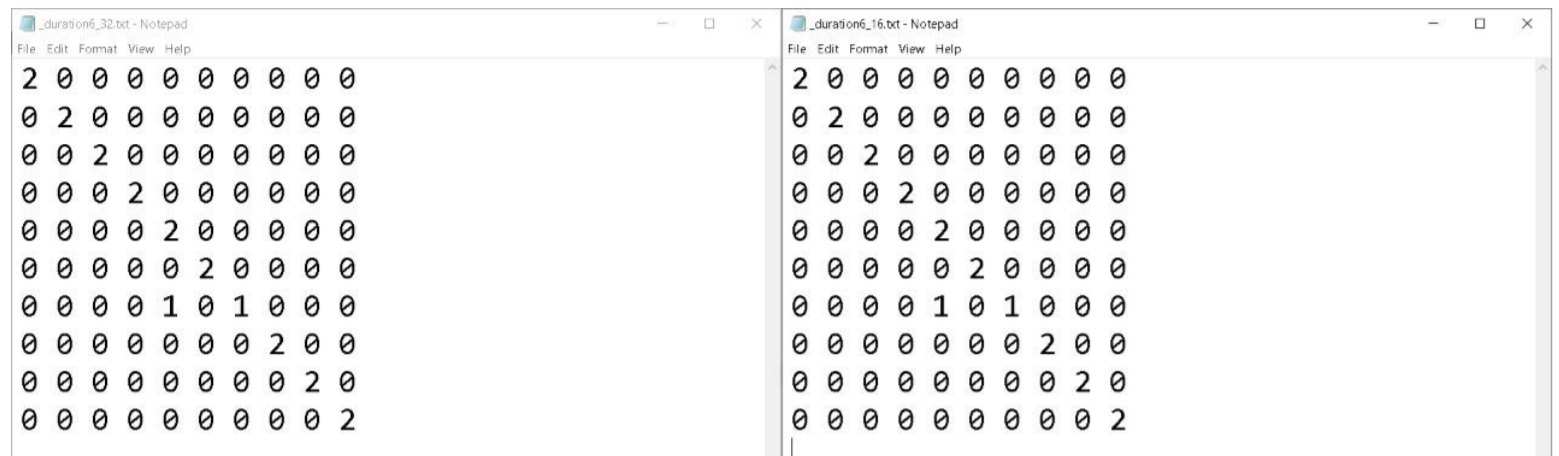
In the MFCC, we loop the two codebooks (16 & 32) and then we loop on the test frames as required (0.25, 0.5, 0.75 and 1 sec) and then forming the MFC coefficients matrix. In this case, the distance is computed between the features matrices and the minimum distance
is calculated again, and a score for each speaker is calculated which is an indication of the speaker. The minimum is then recorded in the confusion matrix for accuracy calculation.
To conclude our work, both solutions proposed are of a good performance. However, higher performance of the 32 codebook-number meant that whenever the codebook-number increases the performance increases, however, the complexity also increases.
So to sum up, if performance is a crucial factor in the project, then use MFCC and increase the order and the codebook-number. On the other hand, if the complexity of the code is an important factor then LPC will work well, or otherwise decrease the codebook-number of the MFCC.
For sure, we will never reach a performance as a human ear and there will always be trade-offs between complexity and performance, so it needs a perfect analysis before starting any voice recognition project and decide whether very high performance is needed or just a moderate performance with moderate complexity can do the job.
In addition, LPC gives us a very good model of the vocal tract and is useful in various speech analysis techniques, but MFCC as mentioned is the most commonly used technique, and with MEL filters which tries to model the human auditory system. So as a final conclusion, the performance in case of VQ using MFCC is higher than LPC.
- The Speaker Model
- The confusion matrix
- 16 Codebook of of a random speaker

- 32 Codebook of of the same speaker

- Confusion Matrix after training for a fraction of a second
- Confusion Matrix after training for more than a second
- Performace Versus Testing Duration in seconds