在此教程中,我们将通过fork样例仓 MindSpore/lenet5_demo,快速体验在昇思大模型平台实现AI全流程开发——训练、推理和评估。
LeNet是1998年提出的一种典型的卷积神经网络。它被用于数字识别并取得了巨大的成功。
论文: Y.Lecun, L.Bottou, Y.Bengio, P.Haffner.Gradient-Based Learning Applied to Document Recognition.Proceedings of the IEEE.1998.
LeNet非常简单,包含5层,由2个卷积层和3个全连接层组成。

基于公开的模型仓库 MindSpore/lenet_mnist 下的MindSpore预训练文件 lenet-1_1875.ckpt 和公开的数据集 wesley/mnist 实现迁移学习,在昇思大模型平台体验训练、评估和推理可视化全流程AI开发体验。
项目地址
- 预训练模型:MindSpore/lenet_mnist
- 数据集:wesley/mnist
- 项目:MindSpore/lenet5_demo
.
├── inference # 推理可视化相关代码
│ ├── app.py # 推理核心启动文件
│ ├── config.json # 推理权重文件配置
│ └── requirements.txt # 推理可视化相关依赖文件
└── train # 训练可视化相关代码
└── trainDir # 训练代码
├── pip-requirements.txt # 训练相关依赖文件,必须和启动文件同一级
├── train_customize_aim.py # 自定义Aim训练代码,支持自定义评估
├── train_gridsearch.py # grid search + LossMonitor 训练代码,支持标准评估
|── train_valaccmonitor.py # ValAccMonitor训练代码,支持标准评估
└── train.py # LossMonitor训练代码,支持标准评估
注:建议将推理可视化相关的代码放在
inference文件夹下,训练相关的代码放在train文件夹下。注意该项目下不能有lfs文件,否则会调度失败。
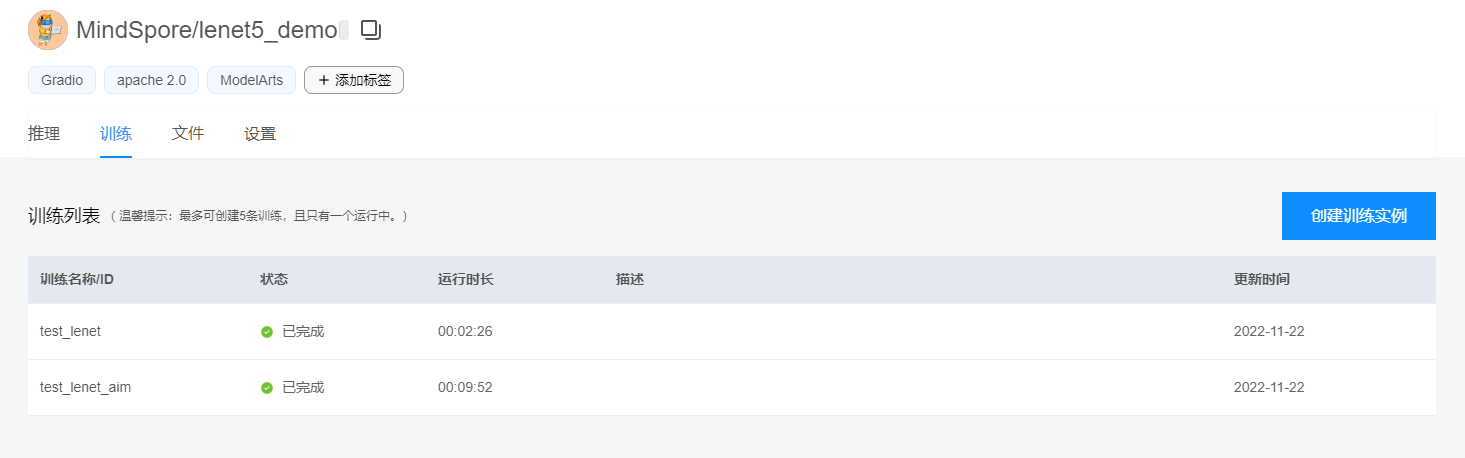
训练列表
训练日志
由上图可知,同样的轮次,当batch_size为64,momentum为0.9时,leanring_rate为0.1的loss最小
1.在项目搜索页中,搜索样例仓 MindSpore/lenet5_demo,或直接点击链接。

2.点击Fork

1.选择不同的评估方式,您需要适配的更改训练文件(训练代码在train/trainDir下)。
-
评估方式1——训练日志可视化
# train.py,支持标准评估 ... from mindvision.engine.callback import LossMonitor ... # 训练网络模型 model.train(10, dataset_train, callbacks=[ckpoint, LossMonitor(0.01, 1875)]) ...
注意目前仅支持
LossMonitor和ValAccMonitor,为了增加不同参数下的对比效果,你也可以使用grid search+Monitor,具体代码可参考train_gridsearch.py# train_gridsearch.py,支持标准评估 ... # 训练代码 def train(args_opt): # grid search batch_size_choice = [32, 64, 128] learning_rate_choice = [0.01, 0.001, 0.0001] momentum_choice = [0.9, 0.99] for batch_size in batch_size_choice: for learning_rate in learning_rate_choice: for momentum in momentum_choice: ... # LossMonitor or ValAccMonitor model.train(20, dataset_train, callbacks=[ckpoint, LossMonitor(learning_rate, steps)]) ...
-
评估方式2——自定义评估
评估方式1的评估指标有限,你也可以自己写评估代码,跟踪你想要关注的指标。比如下例
train_customize_aim.py中以自定义Callback+Aim 跟踪指标 的方式跟踪每个epoch之后训练集和测试集的acc。# train_customize_aim.py ... from aim import Run ... # 自定义Callback class AimCallback(Callback): def __init__(self, model, dataset_test, aim_run): super(AimCallback, self).__init__() self.aim_run = aim_run # 传入aim实例 self.model = model # 传入model,用于eval self.dataset_test = dataset_test # 传入dataset_test, 用于eval test def step_end(self, run_context): """step end""" cb_params = run_context.original_args() # loss epoch_num = cb_params.cur_epoch_num step_num = cb_params.cur_step_num loss = cb_params.net_outputs run1 = self.aim_run.track(float(str(loss)), name='loss', step=step_num, epoch=epoch_num, context={"subset": "train"}) def epoch_end(self, run_context): """epoch end""" cb_params = run_context.original_args() # loss epoch_num = cb_params.cur_epoch_num step_num = cb_params.cur_step_num loss = cb_params.net_outputs train_dataset = cb_params.train_dataset train_acc = self.model.eval(train_dataset) test_acc = self.model.eval(self.dataset_test) print("【Epoch:】", epoch_num, "【Step:】", step_num, "【loss:】", loss, "【train_acc:】", train_acc['accuracy'], "【test_acc:】", test_acc['accuracy']) self.aim_run.track(float(str(loss)), name='loss', epoch=epoch_num, context={"subset": "train"}) self.aim_run.track(float(str(train_acc['accuracy'])), name='accuracy', epoch=epoch_num, context={"subset": "train"}) self.aim_run.track(float(str(test_acc['accuracy'])), name='accuracy', epoch=epoch_num, context={"subset": "test"}) ... # Aim aim_run = Run(repo=args_opt.aimrepo_url, experiment=f{args_opt.output_url}/bs{batch_size}_lr{learning_rate}_mt{momentum}") # Log run parameters aim_run['learning_rate'] = learning_rate aim_run['momentum'] = momentum aim_run['batch_size'] = batch_size # 训练网络模型 model.train(2, dataset_train, callbacks=[ckpoint, AimCallback(model, dataset_test, aim_run)]) ...
2.选择训练页签,点击创建训练实例按钮

注:一个仓库同时只能有一个运行中的训练实例,且训练实例最多只能5个
3.填写相关配置
选择不同的评估方式,需要更改启动文件,样例中支持的评估方式参考目录结构的注释。
注意若选择自定义评估,需打开自定义评估按钮。若不选择评估,需将此按钮关闭。

4.查看训练列表和训练日志
4.1查看训练列表
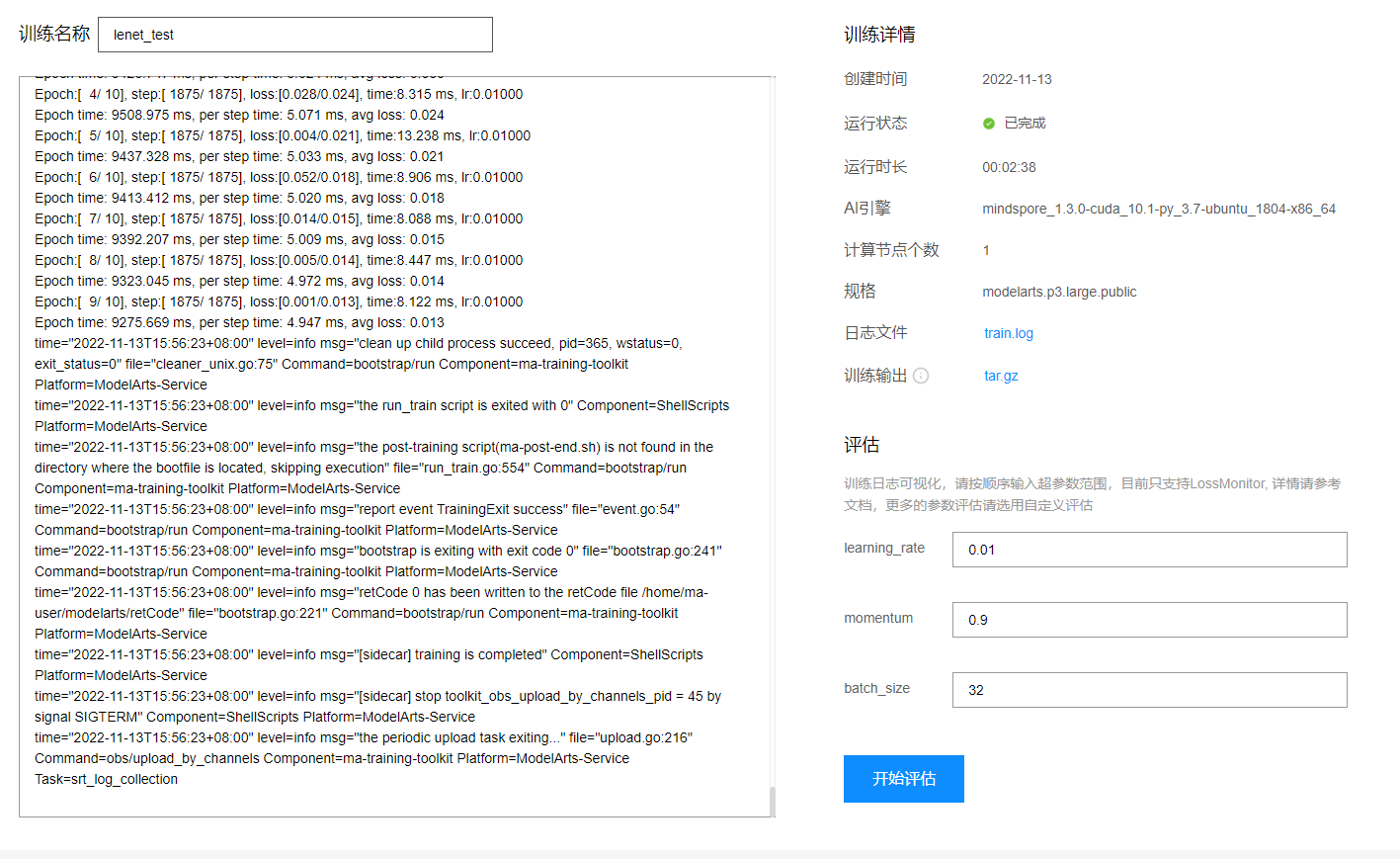
4.2点击训练名称查看训练日志
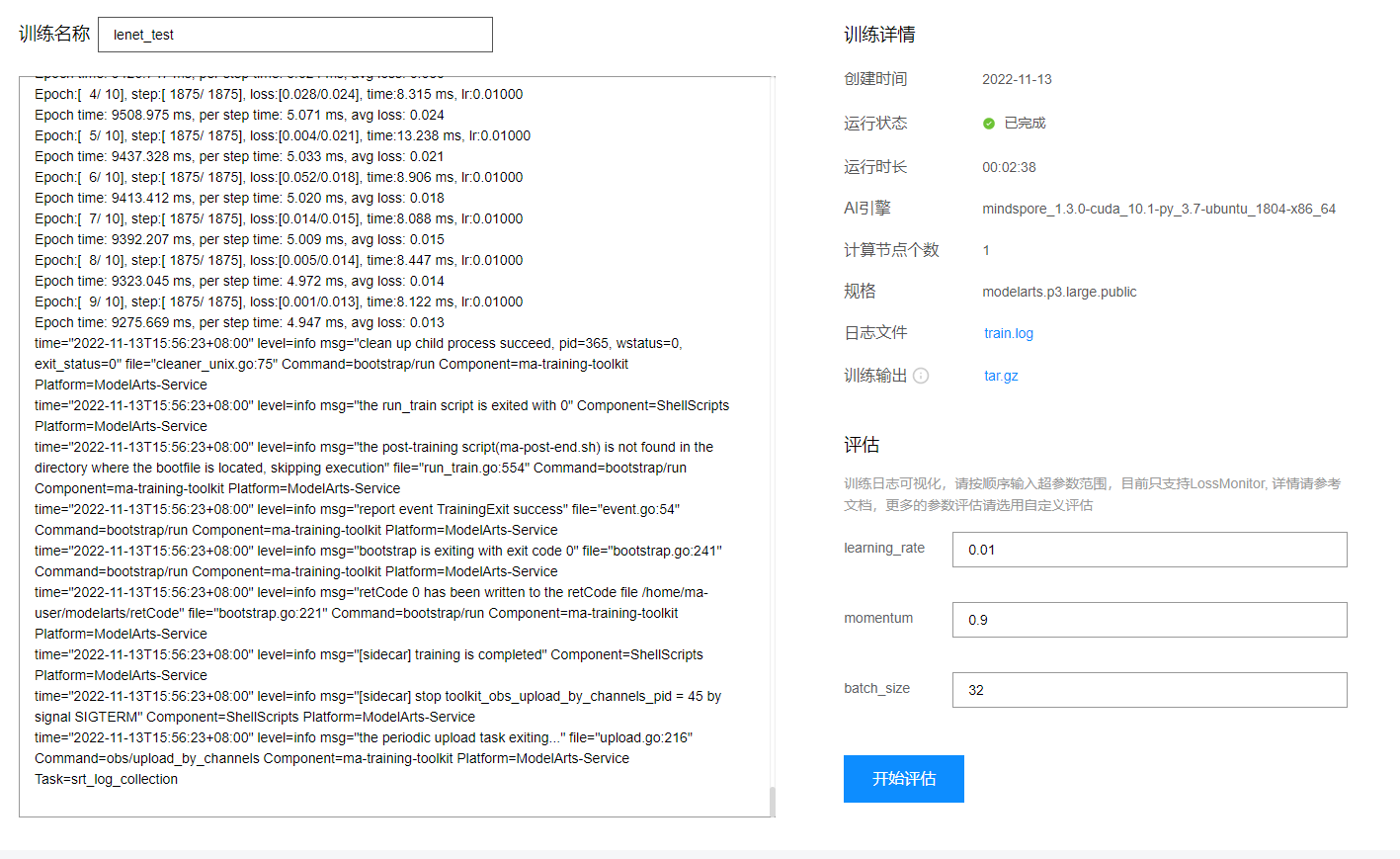
点击日志文件或训练输出可以下载输出的日志和训练输出。
5.评估
-
评估方式1——训练日志可视化
以启动文件
train.py为例:以启动文件
train_gridsearch.py为例(输入的顺序跟grid search输入的顺序范围一致): -
评估方式2——自定义评估



5.1点击开始评估按钮
点击开始评估,按钮会转到评估中状态,此时按钮是不可用,且自定义评估方式等待时间会较长,请您耐心等待。
5.2查看报告
-
评估方式1——训练日志可视化
点击查看报告(启动脚本为
train_gridsearch.py),进入如下页面,您也可以在左侧导航栏右键打开一个新页面点击左侧导航栏Runs,可以查看对比组列表。
点击某一个Runs,可以查看一种实验下的走势图。
比如点击第一个Run,learning_rate为0.0001,momentum为0.99,batch_size 为128。
选择
Metrics页签,可以查看此超参数下不同监测指标的走势图。点击左侧导航栏Metrics,可以查看所有metrcis的走势图汇总
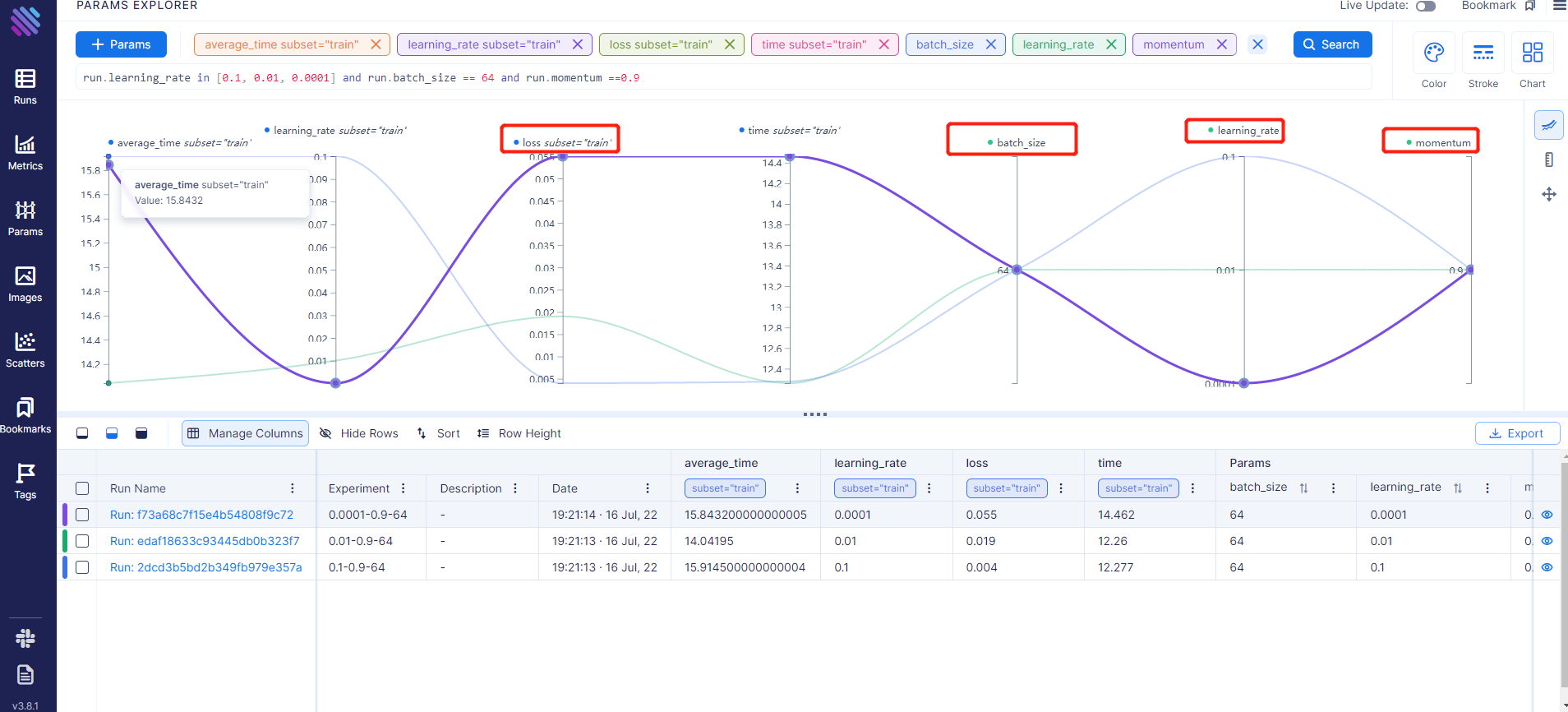
点击左侧导航栏Params,可以查看对比图,可以直接看出哪个超参数下有最好的metrics。
比如下图我们使用控制变量法,查看在batch_size为64,momentum为0.9时,哪个leanring_rate为那个loss最小。由下图可知,learning_rate为0.1时最小。
注:若您想要获取更多监控指标,建议您自定义Aim代码,选择自定义评估的方式,详情参考 自定义评估
-
评估方式2——自定义评估
此案例(启动脚本为
train_customize_aim.py)增加了一个测试数据集的acc,其中一个实验(Run)实例的效果图如下:分析loss走势图,随着epoch的增加,loss反而往上,且在2.4左右反复震荡,可以猜测,loss陷入到了一个局部最优点,需要设置一个更大的learning_rate冲出局部最优点。
由此得出一个简单的结论,可以设置一个更大的learning_rate、momentum或者选择自适应优化器等。
注:生成报告的时间需要几分钟,请耐心等待。






选择推理页签,点击启动按钮,启动过程会比较慢,请耐心等待,一般为5分钟以内,若时间过长,请检查推理代码。
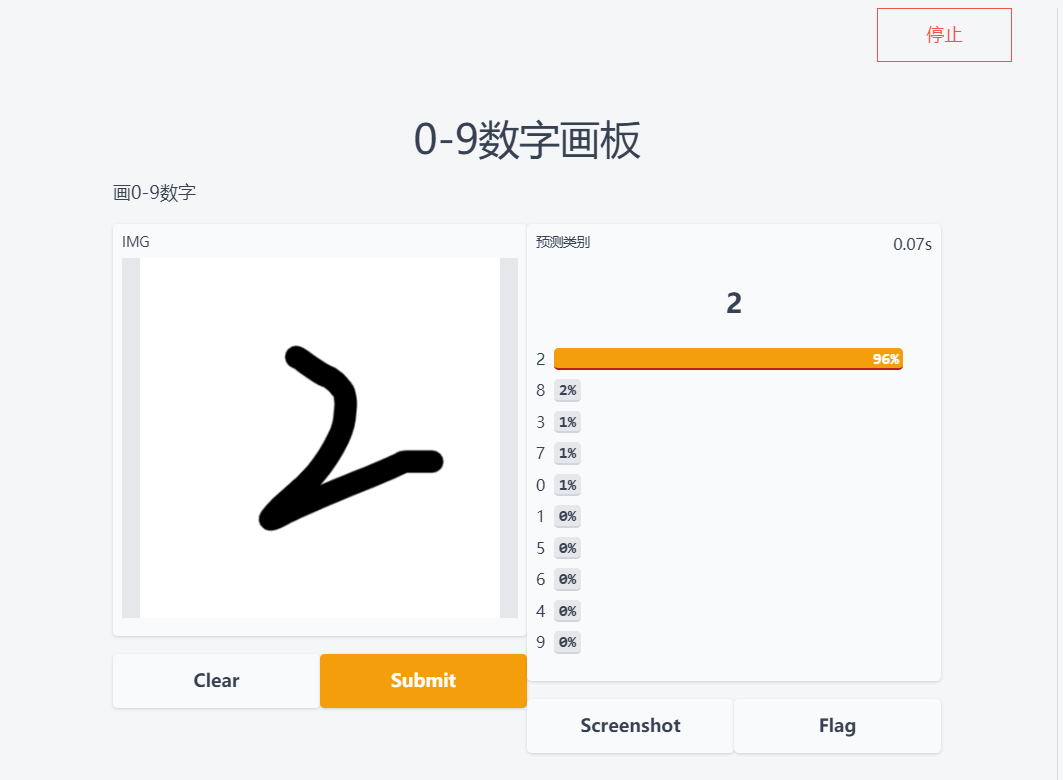
MNIST画板效果展示
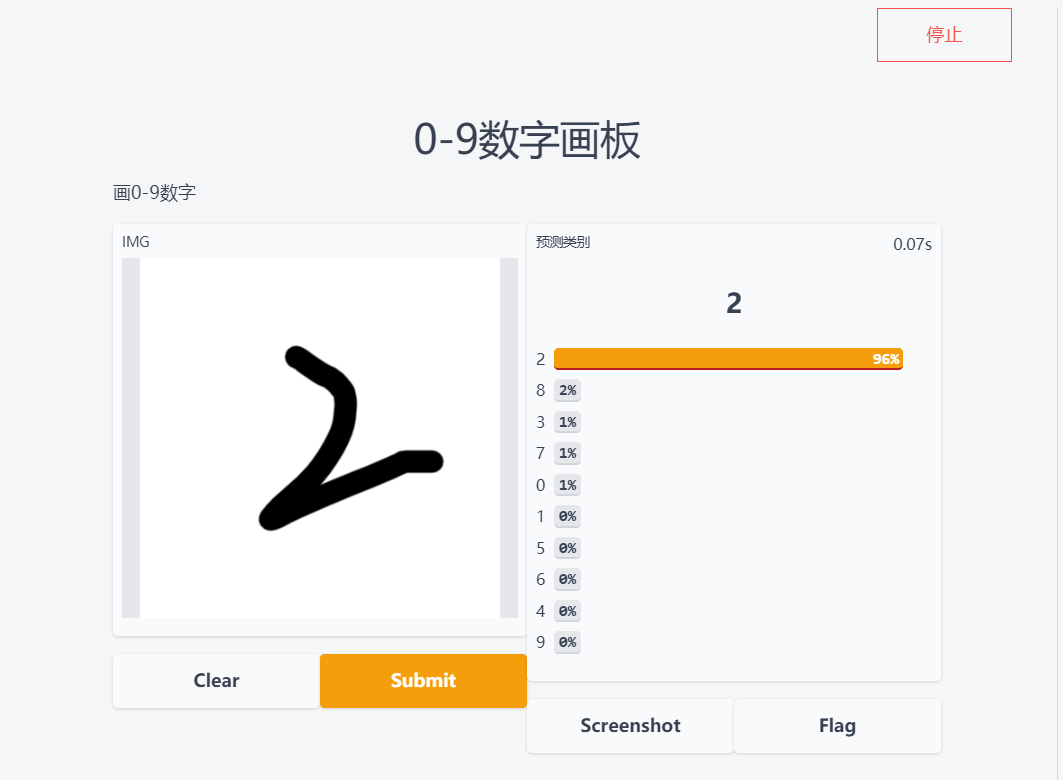
若你想在昇思大模型平台中从0到1创建自己的训练实例、评估和推理可视化,可以参考教程篇的内容
您如果按照教程操作过程中出现任何问题,您可以联系我们的邮箱contact@mindspore.cn,我们会及时回复您。如果您有任何建议,也可以添加官方助手小猫子(微信号:mindspore0328),我们非常欢迎您的宝贵建议,如被采纳,会受到MindSpore官方精美礼品哦!