[BUG] Significant drop in performance of DH / ð phoneme #440
Comments
|
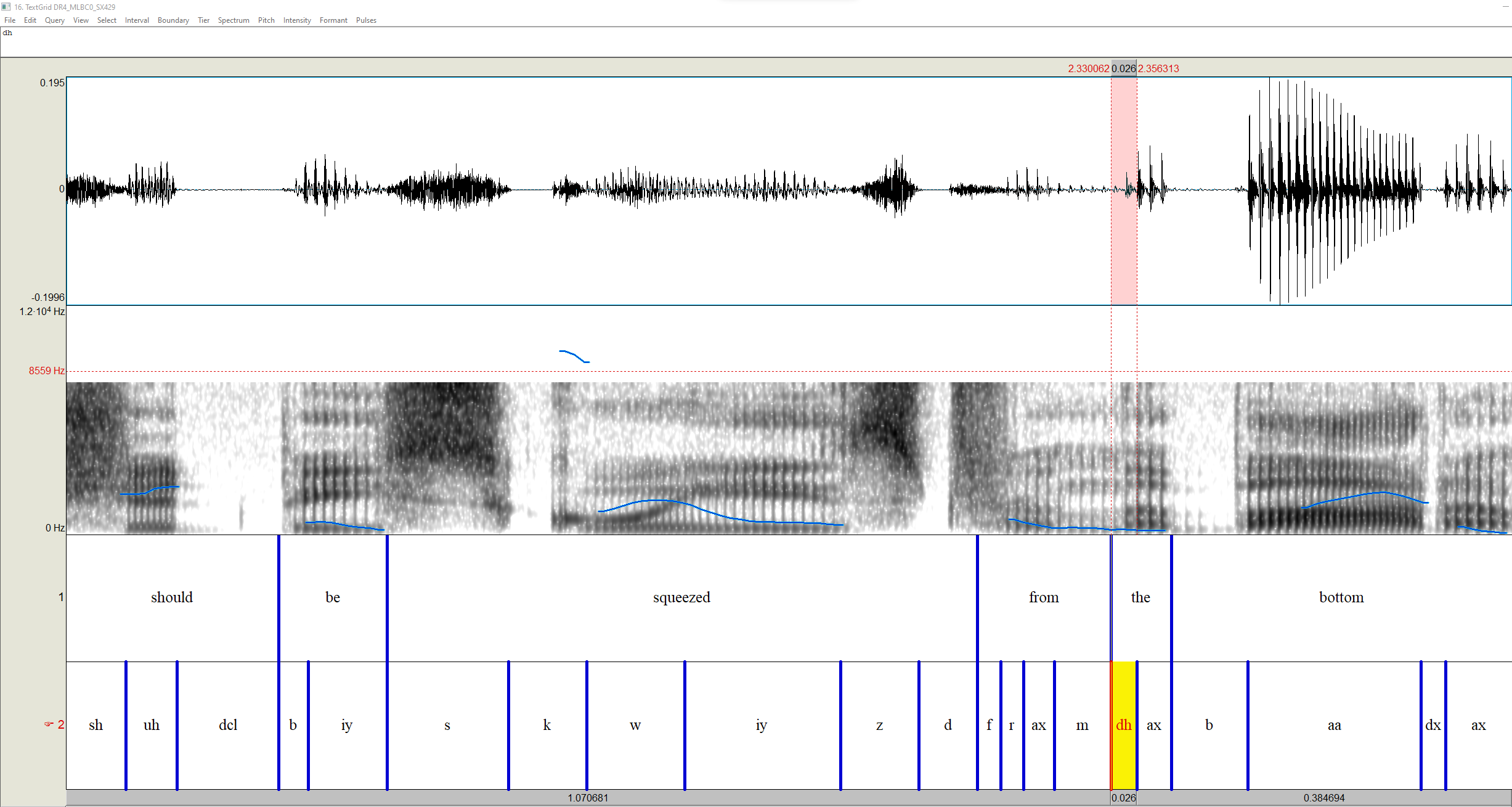
After looking back through TIMIT, I'm actually not surprised, I think this is mostly an issue with TIMIT's annotation guidelines. They treat "dh" as not really having any pronunciation variants, other than if it is really stopped, they recommend Here are some examples across a range of files:
In general, I don't think a lot of tokens of /ð/ in "the" should be transcribed with [ð] as a rule, if they exist, they're an assimilation/gemination or [d̪]. I'll try a round of training having the stopped realization as explicitly a dental [d̪] separate from the alveolar [d], that might help with the over-generalization to [d], since the stopped realization is much more frequent than the fricative version in the training data. But I really don't think that TIMIT is a good benchmark for ASR in general, let alone for alignment. All the sentences are so stilted because they tried to phonetically balance it, and that's just an impossible task in natural language. Trying to have the same amount of /t/ as /ʒ/ just really doesn't make sense. And then if you take a look at their speaker info section: https://catalog.ldc.upenn.edu/docs/LDC93S1/SPKRINFO.TXT, hooo boy, biases abound if you look at those notes (and more concretely, of the 630 speakers, 578 were marked as White, 26 as Black, 3 as Asian, 2 as Native American, 4 as Hispanic, and 17 as ???). With that said, most of my benchmarking and analysis has been on Buckeye, which does have its own fair share of issues that I've correct over the years. Anyway, I have thoughts and opinions about TIMIT, but my point is that they are encoding an analysis of English that I have not adhered to with the dictionaries that I've written and have no desire to replicate. Here are some benchmarks I've done. I'm not surprised if ARPA models outperform IPA-based, because the benchmarks of both TIMIT and Buckeye are inspired by ARPAbet (and Buckeye transcription set is directly inspired from a reduced set of TIMIT's phone set), but again, I'm really not interested in models that work well on American English ARPAbet in particular.
You can see the scripts that generated these here: https://github.com/mmcauliffe/memcauliffe-blog-scripts/tree/main/aligning/mfa_2.0_evaluations, along with https://github.com/mmcauliffe/corpus-creation-scripts/blob/main/buckeye/create_buckeye_benchmark.py and https://github.com/mmcauliffe/corpus-creation-scripts/blob/main/timit/create_timit_benchmark.py. Let me know if I've done something wrong, but otherwise I'll close this out. |







|
Updated models (2.0.0a, available here: https://github.com/MontrealCorpusTools/mfa-models/releases) are live now for all languages, should show some improvements in performance across the board including for [ð], but again for the reasons listed above, I wouldn't be surprised if the MFA phone set models do not predict a fricatives in places that TIMIT has one transcribed |
Debugging checklist
[x] Have you updated to latest MFA version?
Running 2.0.0rc6
[x] Have you tried rerunning the command with the
--cleanflag?Yes
Describe the issue
For both the arpa and the mfa phone set, the performance of DH phoneme has deteriorated significantly between the current acoustic models and the one with the
meta.yamlfile below:On the new version, most phonemes perform similarly to the 0.9.0 version (albeit a little worse) but the DH / ð phoneme's recall and precision is severely affected. Running
classification_reportfromscikit-learn, we are looking at 0.09 precision and 0.11 recall. In 0.9.0, running the same test using the same dictionary (librispeech-lexicon), the scores were 0.45 precision and 0.83 recall.For Reproducing your issue
Please fill out the following:
Standard TIMIT corpus
Using the librispeech-lexicon (but the issue persists on both the english_us_mfa and english_us_arpa dictionaries
Using the english_us_arpa and the english_us_mfa acoustic models .
Additional context
Implementation of #439 can help in the future for catching such issues earlier.
The text was updated successfully, but these errors were encountered: