
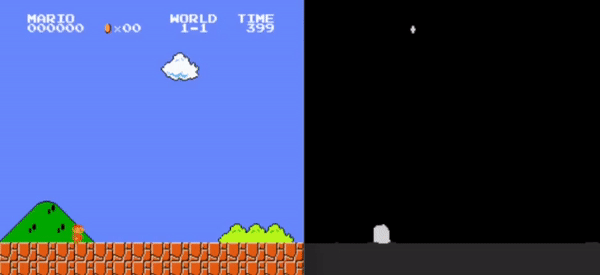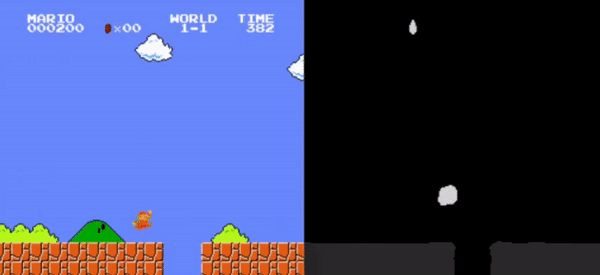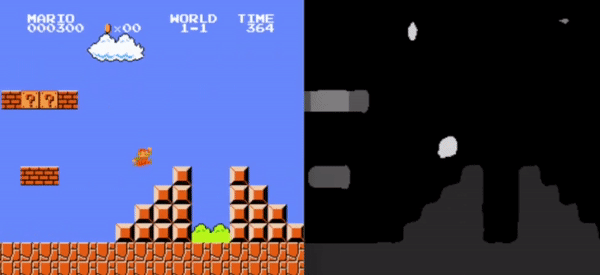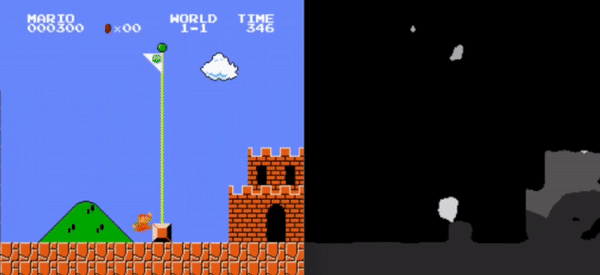
Left: Original Frame, Right: Segmented frame used as input for the RL model.
Code can be found inside Semantic-Segmentation-Boost-Reinforcement-Learning folder (links to our organization repository)
More results and details about the different tests can be found in the complete paper.
This work is part of the preliminary tasks related to the Harvesting Visual Data (HVD) project (PID2021-125051OB-I00) funded by the Ministerio de Ciencia e Innovación of the Spanish Government.