Traning large-scale language model like Yuan is difficult because it requires not only massive computing resources, but also complex training methods to efficiently process a large number of parameters. We complete Yuan Large Language Model Chanllenge in 67.75h using 4 32GB Tesla V100 DGXS, ZeRO parallel strategy and various acceleration training methods.We use parallel strategy and various acceleration training methods to complete Yuan Challenge, the current largest singleton language model(2022.2) with 246B parameters, which achieved excellent performance on thousands GPUs, and state-of-the-art results on different natural language processing tasks.

The Yuan Large Language Model Challenge must be finished with Pytorch.The software mainly used in this challenge is listed as below:
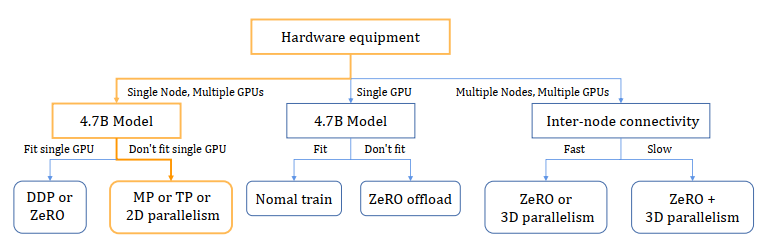
Based on our environment and investigation, how we narrow down the choice of parallel strategies is shown in Figure . The yellow line is our chosen path. Our candidates are MP, TP and 2D parallelism.
We build GPT2 on Megatron-LM as the baseline, use DeepSpeed engine to add ZeRO optimized memory management, and use General, GPU specific, and ZeRO optimizations. The training time required by different methods is shown in the Figure. Our final traning time is 66.75h. The reason why we did not reach 33.87h is explained below.
DefaultCPUAllocator can’t allocate memory occurs during training of 1B tokens by using the same parameters. To analyze the cause of this problem, we use htop [18] to observe the CPU usage during training. It was found that during the training process, the CPU memory usage showed an increasing trend until it crashed.
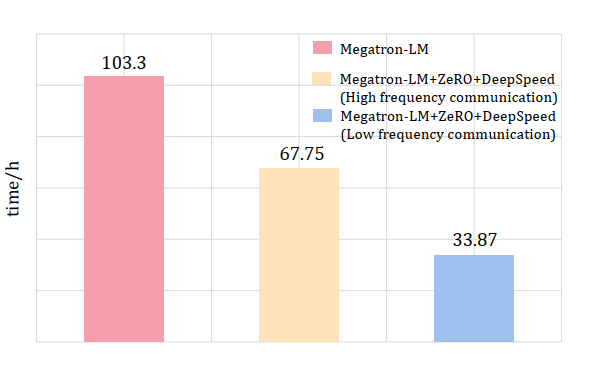
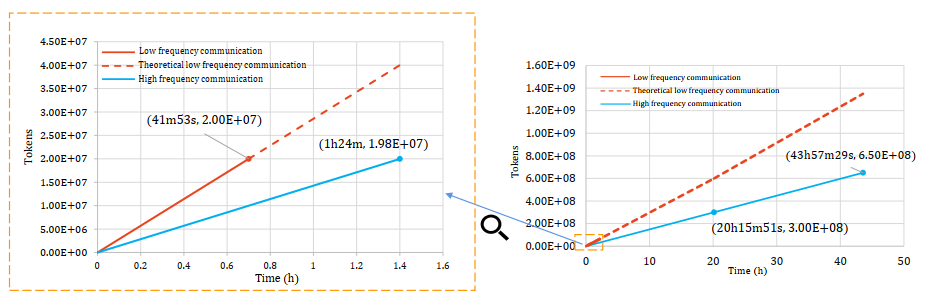
Our main contribution is to build GPT2 on Megatron-LM as the baseline, use DeepSpeed engine to add ZeRO optimized memory management, and use General, GPU specific, and ZeRO optimizations, the final training of 1B tokens takes 67.75h. If we have extra CPU memory, we can reduce this time to 33.87h.
Thanks a lot to Nanchang University Supercomupter Student Competition Cluster in 2022.All rights reserved @NCUSCC.
If you have any problems, please contact congruiyin@email.ncu.edu.cn.