user interface
NTEE's frontend is a Streamlit app running on a local server on port 8501 accessible with a browser at http://localhost:8501. Streamlit comes with an internal Cache, which can be cleared, if any runtime error occurs. Furthermore a screencast recorder is available, delivering the opportunity to create video recordings (with or without audio) of the running app. Both features can be accessed pressing the menu button ≡ in the upper right corner of the user interface.
When reading or writing a TEI file, NTEE basically processes the content of the <text> element mandatory in the TEI standard. With a TEI Reader Configuration, you can exclude the content of certain XML elements within this <text> element. You can also specify which XML elements contain notes, since the note text must be processed separately from the main text so that the consistency of the two texts, i.e. the meaningful order of the sentences, does not get lost.

The screen consists of 3 expander elements:
-
"Existing TEI Reader Configs" shows an overview of the existing TEI Reader Configurations. In any case, you can see here the settings that are available as templates. These templates are examples of which XML elements could usefully be excluded from processing, e.g. the contents of
<sic>if your TEI files also include a corrected variant of the text passage in question, usually in an adjacent<corr>element. So in this case, the content of<corr>would be processed and that of<sic>ignored, resulting in an overall coherent sentence order. - "Add or edit existing TEI Reader Config" allows you to add a new configuration or copy, delete and edit an existing one. Template configurations cannot be edited or deleted. If you want to change one of them, duplicate it and edit the copy.
- "Test TEI Reader Config" offers the possibility to view the plain textual content of a TEI file filtered by a selected TEI Reader Configuration.
Under this menu item the entity classes are defined that are to be learned and predicted in the later course of the NTEE workflow. The definition here is still TEI-independent, i.e. without reference to XML elements. (This reference between the entity classes and their associated XML elements is established under the menu item TEI Read Entity Mapping.) In addition to the entity definition itself, a "Link Suggestion Category" can also be assigned here for each of the individual entity classes. These are categories refering to classes of the Wikidata Knowledge Graph ontology that are used in the course of Named Entity Linking (NEL) during postprocessing. More information on these topics can be found here: Link Suggestion Categories, Postprocessing.

The screen consists of 2 expander elements:
- "Existing Entity Definitions" shows an overview of the existing Entity Definitions. In any case, you can see here the settings that are available as templates.
- "Add or edit existing Entity Definition" allows you to add a new definitions or copy, delete and edit an existing one. Template definitions cannot be edited or deleted. If you want to change one of them, duplicate it and edit the copy.
In order for NTEE to recognize the entities of an Entity Definition in TEI files, a mapping between the entities and XML elements of a TEI file is necessary. Such mappings, which are essentially for reading XML files in the course of groundstruth building, can be created here.

The screen consists of 3 expander elements:
- "Existing TEI Read Entity Mappings" shows an overview of the existing TEI Read Entity Mappings. In any case, you can see here the settings that are available as templates.
- "Add or edit existing TEI Read Entity Mapping" allows you to add a new mappings or copy, delete and edit an existing one. Template mappings cannot be edited or deleted. If you want to change one of them, duplicate it and edit the copy.
- "Test TEI Read Entity Mapping" offers the possibility to view the textual content of a TEI file filtered by a selected TEI Reader Configuration and TEI Read Entity Mapping, with recognized entities highlighted in color.
A prerequisite for training an entity tagger is a Groundtruth, i.e., annotated data against which a neural network can be trained to recognize the desired entities according to an Entity Definition and mapping in TEI files (NER Trainer).
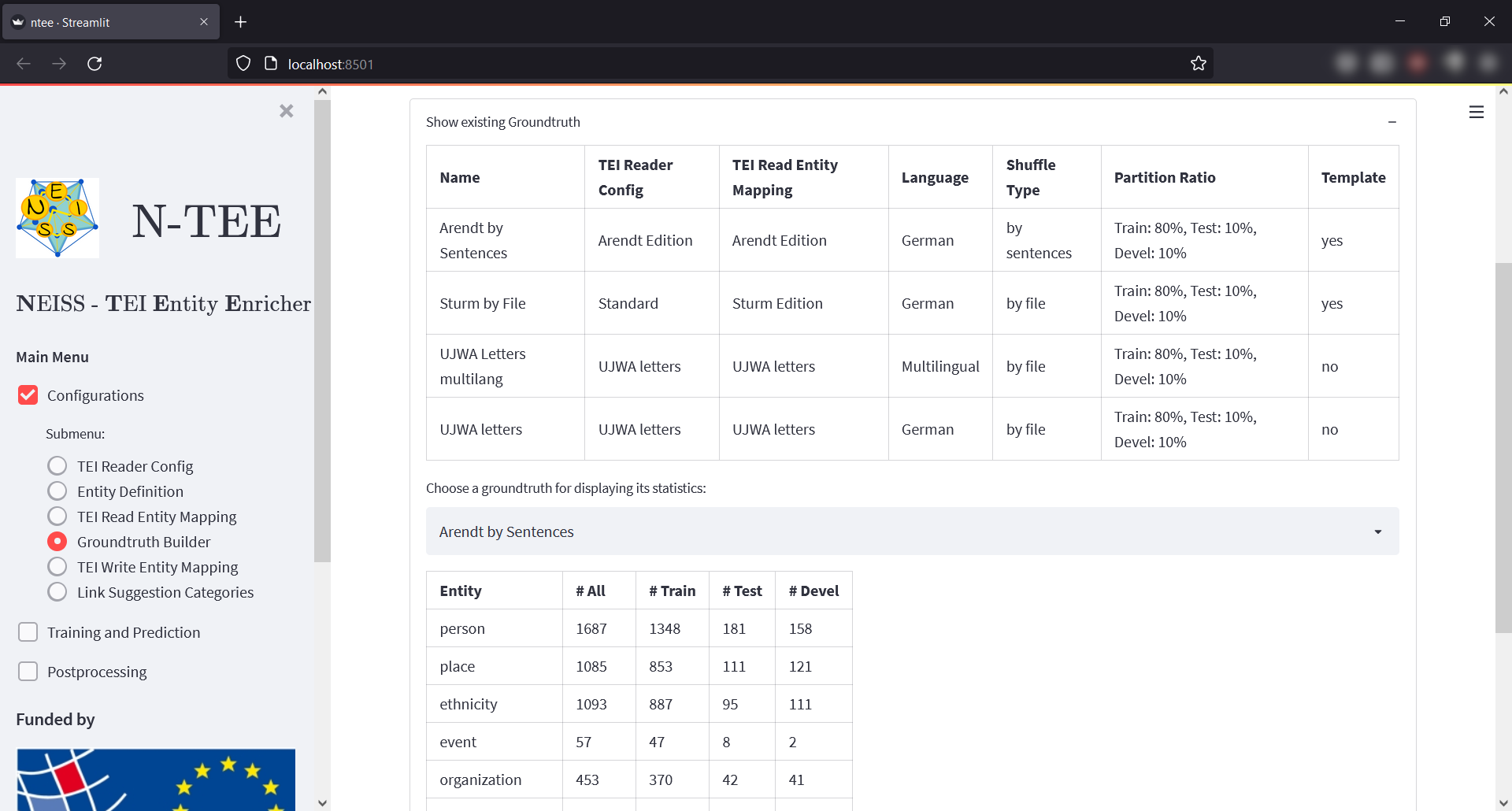
The screen consists of 3 expander elements:
- "Build new Groundtruth" allows to convert TEI files into a Groundtruth definition (internally saved in a JSON format), which can be used in the NER Trainer. Besides a TEI Reader Configuration and an Entity Read Mapping, a language has to be selected and a ratio of training, validation and test data has to be defined. The language selection is relevant to ensure the correct sentence separation in the processing of the training data. The split of the training data into training, validation and test data is necessary to evaluate the performance of the trained entity tagger during and after the training process. During training, the validation set is used to measure performance. After training, a trained model can be evaluated using the test set in the Evaluate Training menu item. In addition, the shuffle options "Shuffle By TEI File" and "Shuffle By Sentence" are available in the Groundtruth Builder: The former is recommended when multiple TEI files are used as input data for Groundtruth building. The latter is suitable for the case when only a few TEI files are available. The shuffle process randomly distributes the input data among the three datasets mentioned (Training, Validation, Test). Depending on the selected shuffle option, this is then done either using entire TEI files or individual sentences out of all files provided as input.
- "Delete existing Groundtruth" allows you to delete a given Groundtruth.
- "Show existing Groundtruth" shows an overview of the existing Groundtruths. In any case, you can see here the datasets that are available as templates. The summary table lists the number of entity instances of a Groundtruth broken down by the three datasets. "Devel"(opment) here refers to the validation set.
Analogous to TEI Read Entity Mappings, it must be defined how recognized entities are written back to TEI files. A TEI Write Entity Mapping is therefore only necessary for the prediction process.

The screen consists of 3 expander elements:
- "Existing TEI Write Entity Mappings" shows an overview of the existing TEI Write Entity Mappings. In any case, you can see here the settings that are available as templates.
- "Add or edit existing TEI Write Entity Mappings" allows you to add a new mappings or copy, delete and edit an existing one. Template mappings cannot be edited or deleted. If you want to change one of them, duplicate it and edit the copy.
- "Test TEI Write Entity Mapping" offers the possibility to view the textual content of a TEI file filtered by a selected TEI Reader Configuration and TEI Write Entity Mapping, with recognized entities highlighted in color.
Part of the postprocessing is the so-called Named Entity Linking (NEL), the process in which Uniform Resource Identifiers (URI) are assigned to the individual recognized entities, for example "https://d-nb.info/gnd/4005728-8" to the city and state of Berlin. For the manual, user-executed NEL process, NTEE provides database access to the Wikidata Knowledge Graph as support. The Link Suggestion Categories defined here in this menu are each associated with one or more classes of the Wikidata ontology. This mapping can be used in postprocessing to narrow down the entity identification suggestions determined by NTEE to those entities that are directly or indirectly part of the Wikidata ontology class(es) specified here. Example: If you are looking for a "person" in terms of the template Link Suggestion Category of the same name, then only entities will be suggested to you, which belongs to the Q5 class (= human being) or a subclass of Q5 at any level below. If multiple Wikidata classes are specified in a Link Suggestion Category, the associated boolean query to the database is positive as soon as the entity in question is directly or indirectly part of at least one of the specified Wikidata classes. Practical note: Link Suggestion Categories defined here still need to be assigned to individual entities in an Entity Definition (Entity Definition) in order to be usable in postprocessing.

The screen consists of 2 expander elements:
- "Existing Link Suggestion Category Definitions" shows an overview of the existing Link Suggestion Categories. In any case, you can see here the categories that are available as templates.
- "Add or edit existing Link Suggestion Categories" allows you to add a new categories or copy, delete and edit an existing one. Template categories cannot be edited or deleted. If you want to change one of them, duplicate it and edit the copy.
Here the training of an individual NER tagger can be started. The easiest way to do this is to use a groundtruth created in NTEE (see Groundtruth Builder).
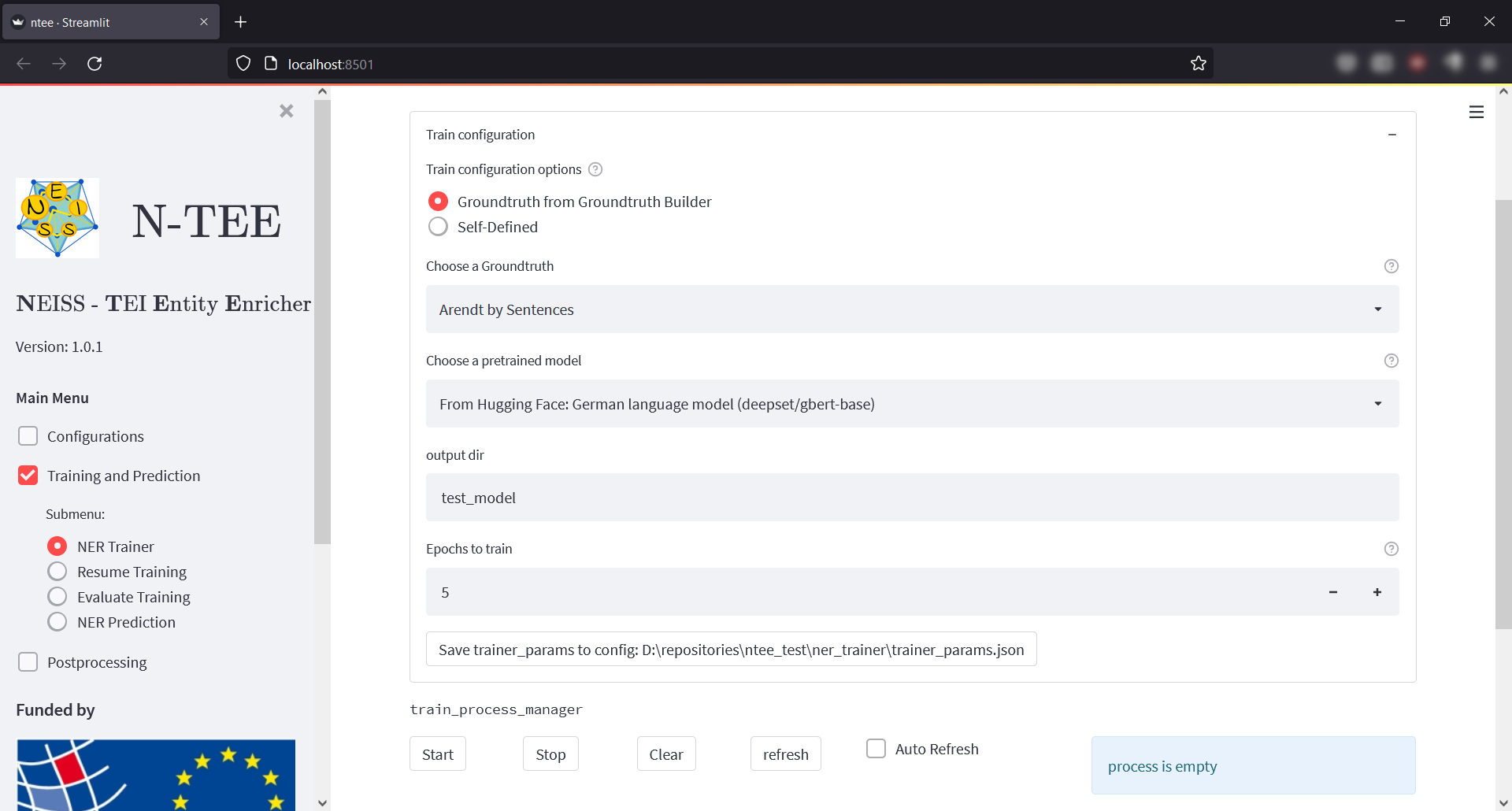
The screen consists of the expander element "Train Configuration" and a "Train Process Manager":
- "Train Configuration" offers various setting options for a training to be performed. In any case, a pretrained language model must be selected under "Choose a pretrained model". Here, NTEE offers the possibility to choose between models from the online platform Hugging Face. In addition to models that are specialized for certain languages, a multilingual model can also be selected there. These models are optionally downloaded automatically by NTEE from Hugging Face, depending on their use. Furthermore, a name or output directory as well as the number of epochs to be trained must be specified for the NER tagger to be trained. In addition, the data with which the tagger is to be trained can be provided via two variants. On the one hand via a Groundtruth created in NTEE (recommended variant) or on the other hand "Self-defined" via an Entity Definition and self-created training data in a JSON format specified by NTEE.
- "Train Process Manager" manages a running training. A training is always performed in the background in NTEE and the training process manager displays current information as well as the output logging of the training process. The "Start" and "Stop" buttons can be used to start or stop a training session for the current configuration. The "Clean" button can be used to completely reset the current training process. With "Refresh" or "Auto-Refresh" the current status display of the manager can be updated manually or automatically (every 5 seconds).
Under the menu item "Resume Training" you can view the training history of NER taggers trained under NER Trainer to decide whether it makes sense to continue the training of a tagger for further epochs. This can then be done in a separate "Resume" process manager.

The screen consists of a dropdown element, an expander element, a number input widget and a "Resume Process Manger":
- Dropdown element "Choose a NER Model to resume" indicates which previously trained NER tagger is currently being considered.
- Expander element "Training course" shows in a diagram the progressions over the training epochs of the entity-wise F1 score as well as the training loss of the current validation (also called development) set. In addition, the exact values can be displayed via a slider for a specific epoch. On this basis, one can decide whether it seems reasonable to continue a training by further epochs. This is the case if it looks like either the F1 score could increase further or the loss could decrease further. Even while a training or resume is running, the training course up to the last completely executed epoch can be viewed here.
- Number input "Resume Training until epoch" allows to set up to which epoch a training should be continued.
- "Resume Process Manager" manages the resume training of an NER Tagger. A resume training is always performed in the background in NTEE and the resume process manager displays current information as well as the output logging of the resume process. The "Start" and "Stop" buttons can be used to start or stop a resume training session for exactly the same training configuration for which these taggers where originally trained (except the number of epochs). The "Clean" button can be used to completely reset the current resume process. With "Refresh" or "Auto-Refresh" the current status display of the manager can be updated manually or automatically (every 5 seconds).
The menu item is used to evaluate an NER tagger over test sets completely independent of the data previously used for training. It is important not to use the validation (also called development) set already used in the training process, as this was used to determine the best model from the best epoch up to that point with regard to the F1 score. This means that these sets already have an influence on the training of the previous tagger in addition to the training sets.

The screen consists of a dropdown element, an expander element, another dropdown element and a "Evaluate Process Manger":
- Dropdown element "Choose a NER Model for evaluation" indicates which previously trained NER tagger is currently being considered.
- Expander element "Existing evaluations" shows the results of evaluations performed to date on test sets of Groundtruthes created in NTEE. This is done in terms of the entity-wise F1 score.
- Dropdown element "Choose a Groundtruth for a new evaluation" allows to select a Groundtruth whose test set should be evaluated on the previously chosen model. This does not have to be the same Groundtruth that was used to train the tagger.
- "Evaluate Process Manager" manages the evaluation of an NER Tagger. An evaluation is always performed in the background in NTEE and the evaluate process manager displays current information as well as the output logging of the evaluation process. The "Start" and "Stop" buttons can be used to start or stop an evalauation process. The "Clean" button can be used to completely reset the current evaluation process. With "Refresh" or "Auto-Refresh" the current status display of the manager can be updated manually or automatically (every 5 seconds).
This menu item is used to use the taggers trained in NTEE for a prediction.

The screen consists of some basic configuration elements, an expander element for choosing the data to predict and a "Prediction Process Manager":
- In the "Basic Configuration" you have to specify which NER tagger should be used for prediction, a directory where the prediction results should be stored and which kind of data you want to predict ("Prediction options").
- Data choosing Expander allows you to choose the data which you want to predict depending on the selected prediction option. Either one makes a prediciton to a self-defined JSON file or the prediction can be executed directly on one or more TEI files. In the latter case, a TEI Reader Config and a TEI Write Entity Mapping must be specified accordingly.
- "Prediction Process Manager" manages the prediction process with an NER Tagger. A prediction is always performed in the background in NTEE and the prediction process manager displays current information as well as the output logging of the prediction process. The "Start" and "Stop" buttons can be used to start or stop an prediction process. The "Clean" button can be used to completely reset the current prediction process. With "Refresh" or "Auto-Refresh" the current status display of the manager can be updated manually or automatically (every 5 seconds).
Description
(IMAGE tba)
The screen consists of X expander elements:
- ""