NExT-Chat: An LMM for Chat, Detection and Segmentation
Ao Zhang, Yuan Yao, Wei Ji, Zhiyuan Liu, and Tat-Seng Chua
National University of Singapore, Tsinghua University
Project page with demo: NExT-Chat

- 2023.2.5 Add deepspeed training
- 2023.12.12 Initial code released
- Introduction
- Installation
- Model Zoo
- Data Preparation
- Demo
- Evaluation
- Training
- Examples
- Acknowledgement
An LMM for chat with detection and segmentation results.
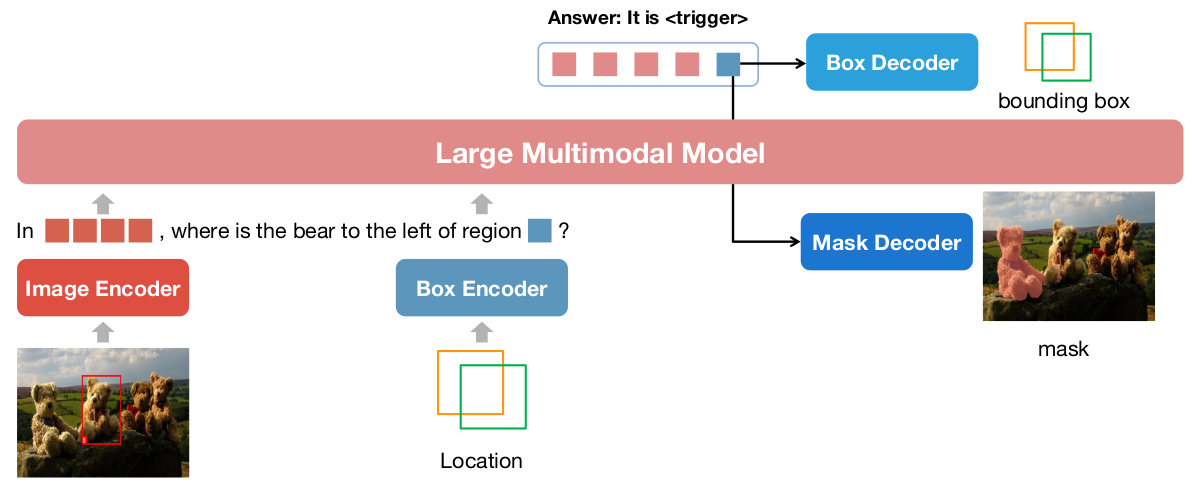
The framework is shown:
Please clone the repo:
git clone https://github.com/NExT-ChatV/NExT-Chat.git
cd NExT-ChatThen install requirements:
pip install -r requirements.txtCurrently, we totally have 3 models:
| Version | ckpt | LM Size | ViT Res. | GPU Mem. | Comment |
|---|---|---|---|---|---|
| v1 | nextchat-7b-336 | 7B | 336x336 | ~32G | recommended |
| v0 | nextchat-7b-224 | 7B | 224x224 | ~24G | not recommended |
| v0 | nextchat-13b-224 | 7B | 224x224 | ~35G | not recommended |
We recommend to use the nextchat-7b-336-v1, which can achieve better performance.
Moreover, we also update the training templates for nextchat-7b-336-v1 to make it easier to use.
You can refer to templates for details in eliciting concrete abilities.
Some examples:
- Localize a object:
| Version | Template |
|---|---|
| v0 | Where is XXX in the |
| v1 | Where is XXX in the image? |
- Grounded Caption:
| Version | Template |
|---|---|
| v0 | Can you provide a description of the image |
| v1 | Can you describe the image and include object locations? |
- VQA+Localization
| Version | Template |
|---|---|
| v0 | Please include object locations and explain. |
| v1 | Please mention related object locations. |
Please refer to DATA.md.
Please first download the model weights from huggingface or our link.
We also use OpenAI CLIP ViT model as the visual encoder. Please make sure that you can connect to huggingface or you can download it to your local directory.
Then, download the SAM and modify sam_path in config/base/model/nextchat.py to your sam path.
Web Demo Please run:
CUDA_VISIBLE_DEVICES="0" python mllm/demo/web_demo.py --model_path path/to/model_weights --vit_path path/to/openai-clip-vit-large-patch14-336If you can connect to huggingface, just run:
CUDA_VISIBLE_DEVICES="0" python mllm/demo/web_demo.py --model_path AoZhang/nextchat-7b-336 --vit_path openai/clip-vit-large-patch14-336Bash Demo
CUDA_VISIBLE_DEVICES="0" python mllm/demo/bash_demo.py path/to/model_weights path/to/openai-clip-vit-large-patch14-336If you can connect to huggingface, just run:
CUDA_VISIBLE_DEVICES="0" python mllm/demo/bash_demo.py AoZhang/nextchat-7b-336 openai/clip-vit-large-patch14-336You can also initialize the model by yourself:
from mllm.demo.demo_util import NextChatInference
model = NextChatInference(model_weight_path, vit_path, 576)You will get into the IPython mode. Then use the model like:
input = {"text": "What is the possible relationship between the two people? Please include object locations.", "image": "./COCO_val2014_000000222628.jpg"}
response, boxes, masks, ret_img = model(input)We have our old models (v0 versions) in the modelscope.
Please first install pip install modelscope.
Then run:
from modelscope import pipeline
pipe = pipeline('my-nextchat-task', 'ZhangAo6/nextchat', model_size="7b") # 7b model takes around 21G GPU mem, 13b takes around 35G GPU mem
response, ret_image = pipe({"text": "xxxx?", "image": "xxx.jpg"})
# response: the text answer
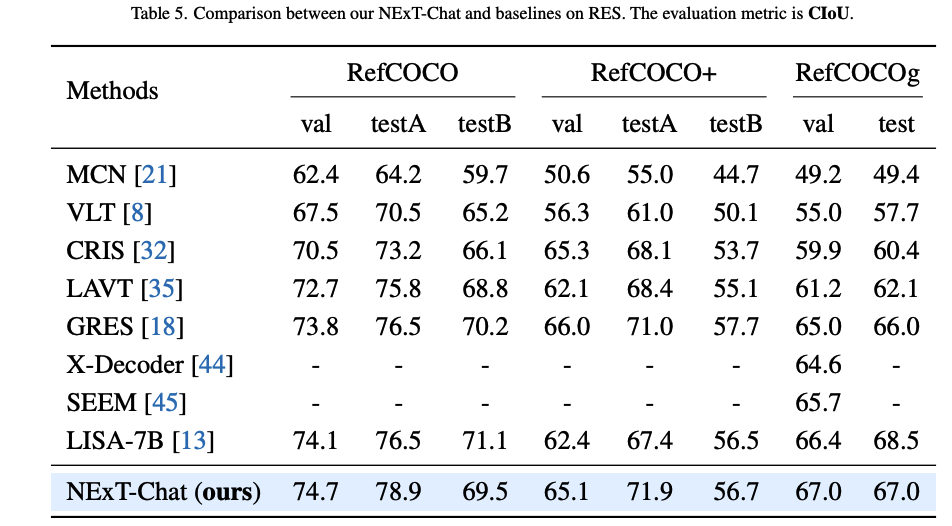
# ret_image: image annotated with boxes and masksThe final result have not been updated to the arxiv. We show the results here:
Please config the vision_tower in the config/base/model/nextchat.py to the path of OpenAI CLIP, if you can not connect to huggingface.
Make sure to download the SAM and modify sam_path in config/base/model/nextchat.py to your sam path.
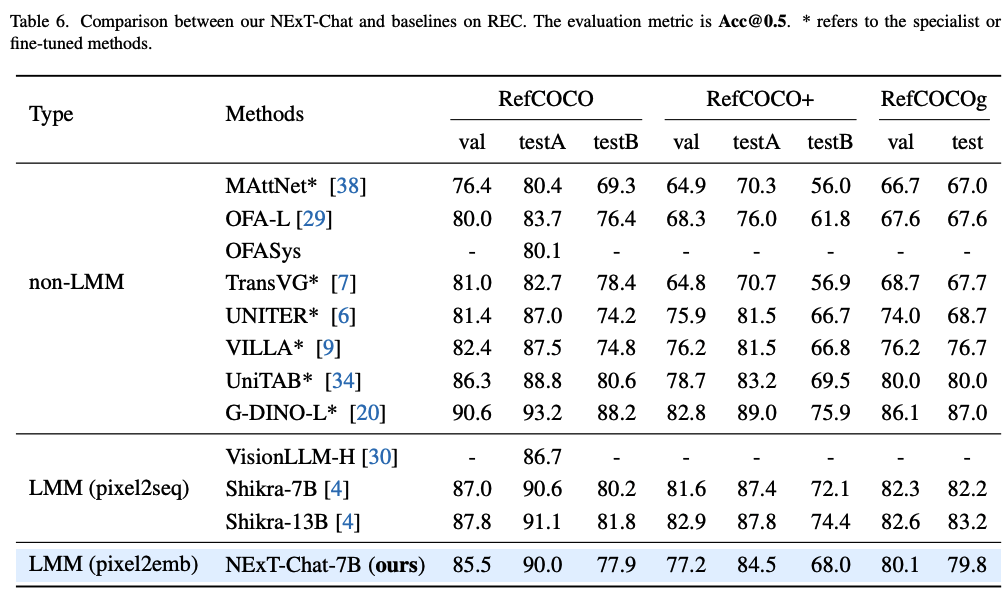
bash eval_res.sh /path/to/checkpointAlthough it seems to be better by modeling the localization as a regression task (also validated by toy experiments), we find that pixel2emb now is hard to beat top-tier pixel2seq models on REC (like Shikra) in the pre-training setting. We guess the key factors might be to find a balance between the localization loss and LM loss, which will significantly affect the REC performance. We are still working on this interesting finding and tune the model. If you have some insights, welcome to discuss.
Please config the vision_tower in the config/base/model/nextchat.py to the path of OpenAI CLIP, if you can not connect to huggingface.
Make sure to download the SAM and modify sam_path in config/base/model/nextchat.py to your sam path.
bash eval_rec.sh /path/to/checkpoint
Please config the vision_tower in the config/base/model/nextchat.py to the path of OpenAI CLIP, if you can not connect to huggingface.
Make sure to download the SAM and modify sam_path in config/base/model/nextchat.py to your sam path.
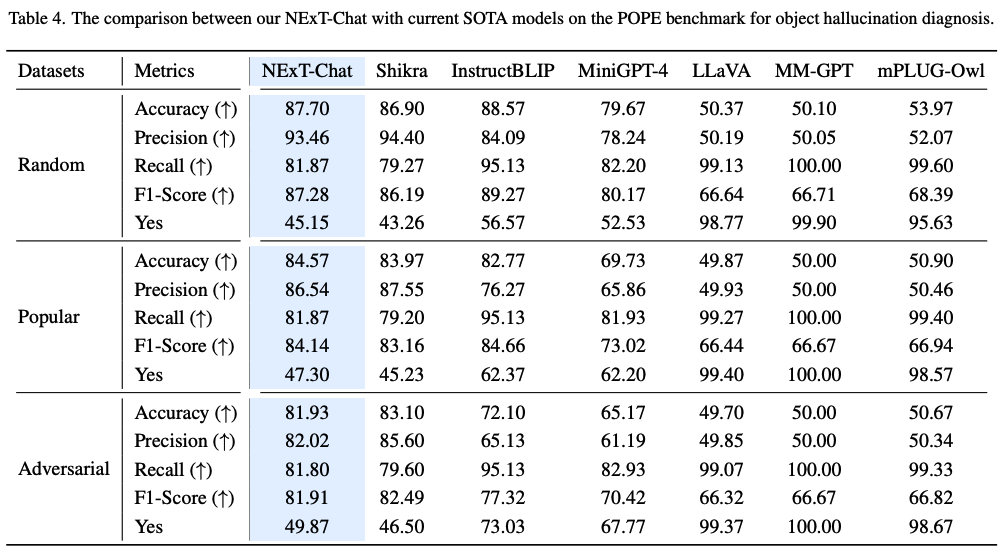
bash eval_pope.sh /path/to/checkpoint
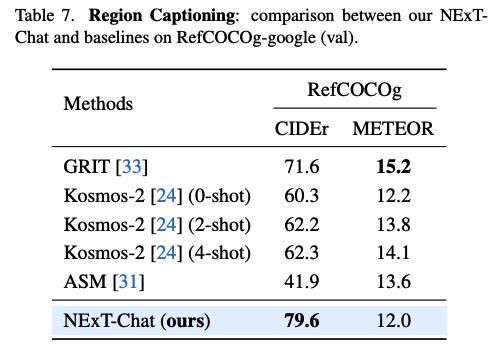
Please config the vision_tower in the config/base/model/nextchat.py to the path of OpenAI CLIP, if you can not connect to huggingface.
Make sure to download the SAM and modify sam_path in config/base/model/nextchat.py to your sam path.
bash eval_reg_cap.sh /path/to/checkpointPlease config the vision_tower in the config/base/model/nextchat.py to the path of OpenAI CLIP, if you can not connect to huggingface.
Make sure to download the SAM and modify sam_path in config/base/model/nextchat.py to your sam path.
Our training consists of 3 stages:
- VL+Detection Pre-training
bash run_stage1.shIf you want to use deepspeed, please modify the config in run_stage1.sh from config/nextchat_stage1.py to config/nextchat_stage1_deepspeed.py.
- VL+Detection Instruction Following
bash run_stage2.sh output/stage1/checkpoint-65000 # or other path to your stage1 model, we use 65000 for stage2If you want to use deepspeed, please modify the config in run_stage2.sh from config/nextchat_stage2.py to config/nextchat_stage2_deepspeed.py.
- VL+Detection+Segmentation
bash run_stage3.sh output/stage2/checkpoint-4950 # or other path to your stage2 modelIf you want to use deepspeed, please modify the config in run_stage3.sh from config/nextchat_stage3.py to config/nextchat_stage3_deepspeed.py.
Examples generated by our nextchat-13b-v0 models:




Thanks to Shikra, LLaVA, CogVLM for their excellent codes.
Our bibtex:
@misc{zhang2023nextchat,
title={NExT-Chat: An LMM for Chat, Detection and Segmentation},
author={Ao Zhang and Yuan Yao and Wei Ji and Zhiyuan Liu and Tat-Seng Chua},
year={2023},
eprint={2311.04498},
archivePrefix={arXiv},
primaryClass={cs.CV}
}