Add simple turbine clustering functionality to SciPy yaw optimization #261
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…bines from the optimization if the lower bound is equal to the upper bound. Also, I took particular care for allowing a non-zero fixed value for special situations, such as having an upstream turbine fixed at a yaw offset or mimicking non-zero vane bias. This functionality significantly speeds up optimizations since one can eliminate turbines beforehand, reducing the dimensionality of the optimization problem.
…. Now one can use a full farm model to optimize only for a subset of turbines. Doing this, one includes the wake effects of other turbines without caring about them in terms of power capture.
…or a select number of yaw angles through specifying the yaw angle bounds. For yaw angles of turbines that should be excluded as control variables, the lower bound should be specified as equal to the upper bound. This lb==ub does not necessarily have to be 0.0, but can also be a nonzero number, if one desires to keep that turbine fixed at that misalignment. Secondly, I implemented a turbine weighing function with which the floris-produced turbine power production values are multiplied in the calculation of the objective/cost function. This allows one to remove turbines from contributing to the cost function. This is particularly useful if one a subset of turbines takes part in a wake steering experiment, whereas the other turbines should be modeled for their wake effects.
…re the most downstreamturbines (i.e., their wakes have no effect on other turbines/the power of the farm). Then, these turbines are excluded in the optimization if exclude_downstream_turbines=True. This allows the user to easily reduce the number of variables to optimize without any loss in performance, potentially leading to significant reductions in computation time.
…in yaw_wind_rose.py (see previous commit)
…dimension did not match because the optimization variables were only reduced if bnds was not None. However, even with bnds=None, we can only be optimizing a subset of turbines due to exclude_downstream_turbines=True. Hence, always reduce variables. Worst case scenario, variables stay the same, negligible computational cost.
… Needs verification.
…so, this facilitates a bug fix where initially the downstream turbines were only calculated for the first wind direction in the array (for _wind_rose.py), while it should be calculated and the solution space is to be modified for every optimization call.
…cified for a downstream machine
…on for exclude_downstream_turbines in yaw.py
…lude_downstream_turbines=True. Also, ensure initial conditions and predicted farm outputs are weighted appropriately with self.turbine_weights.
…e floris when passed to the optimization class. This variable is used to calculate the baseline power production and can differ from the initial guess in the optimization, self.x0. Also, self.x0 is now no longer changed within the optimization class. Rather, the user is forced to specify an appropriate array for self.x0 that meets the bounds.
…default wake slope to ensure validity for high turbulence cases
…mplement changes to yaw_wind_rose_parallel.py
…re all np.nan, besides for downstream turbines which are assigned a value closest to 0.0 constraint-allowing, and for equality-constrained turbines which have their value equal to their lower bound (=upper bound). This clarifies which values are assigned to downstream and equality-assigned turbines
…for situations such as where ws > ws_max or ws < ws_min. Namely, in that situation, we should just fall back to the baseline situation where we put every turbines yaw angle as close to 0.0 as possible.
…ose_parallel.py. Specifically, we now create a yaw_angles_template variable that is the default yaw angle array, meeting the equality constraints and also setting the right values for downstream turbines. In optimization, values for the turbines still be to optimized will be overwritten, and the remaining values (for equality-constrained and downstream turbines, if applicable) are unchanged. These changes clarify the default values for turbines, different from x0 (initial guess) and different from yaw_angles_baseline (baseline values for initial power evaluation).
…t is a wrapper around the regular YawOptimization class in yaw.py which clusters turbines and then optimizes their yaw angles sequentially. In simple test cases with 10-20 turbines, this cuts down the computation time by about 50% while sometimes also increasing accuracy due to better convergence.
added 2 commits
September 17, 2021 11:47
…de the clustering algorithm
…timization in scipy
bayc
approved these changes
Sep 23, 2021
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This pull request is not yet ready to be merged. PR #245 needs to be approved and merged first. Also, may want to write example cases on how to use these new functions. Then, the
README.rst,docs/index.rstandfloris/VERSIONmust be updated accordingly.Feature or improvement description
This PR adds a "clustering" option to the yaw optimization classes in
.tools.optimization.controls_optimization.scipy. Essentially, this functionality uses a very simplified wake model to estimate which turbines affect one another and clusters the turbines based on this, for a particular wind direction. Thus, essentially, it splits the wind farm up into several smaller farms ("clusters") at no loss in accuracy, assuming this simplified wake model is accurate. Then, the yaw angles for each cluster are optimized separately. This addresses the curse of dimensionality in yaw optimizations by reducing the problem from a e.g. 100-degrees-of-freedom optimization problem into two 50-degrees-of-freedom optimization problems. This cuts down computational cost significantly and can also improve optimization performance.Related issue, if one exists
The default SciPy yaw optimization algorithm can converge to suboptimal solutions. This PR does not resolve this issue but does improve its performance and reduces the chance of getting stuck early in a local minimum.
Impacted areas of the software
This only adds functionality and does not replace or adjust any existing functions. It presents a new feature in the SciPy yaw optimization suite.
Additional supporting information
I have found that clustering can reduce computation time by orders of magnitude, anything from a 10% reduction to a factor 10 reduction in computation time. The benefits become larger as the farm becomes larger and more sparse (i.e., more clusters). It can also lead to a higher power production because the optimization problem is better conditioned and a higher accuracy can be achieved in the same number of iterations. Also, because of the nature of the optimization, it may happen that some full-farm optimizations achieve a better result than its equivalent cluster-based optimization, due to the optimization wrongly converging. However, in almost all cases, cluster-based optimization will outperform full-farm optimization in both the achieved power gain and in computation speed.
Also, note that some turbines are too densely spaced to really allow clusterization. If all turbines are somehow interrelated, the algorithm falls back to a single cluster containing all turbines in the farm. The algorithm will then be equal in performance to a full-farm optimization.
Test results, if applicable
Calculation the turbine clusters takes in the order of milliseconds. I found an average
4ms computation time for a 30-turbine wind farm and this should scale linearly with the number of turbines. Thus, worst-case scenario, if the turbines are all connected in some way, one a single cluster is identified and the results will be equivalent to a full-farm optimization.Here is a simple code demonstrating the clustered yaw optimization vs. the default full-farm optimizations:
For a random 8-turbine farm:
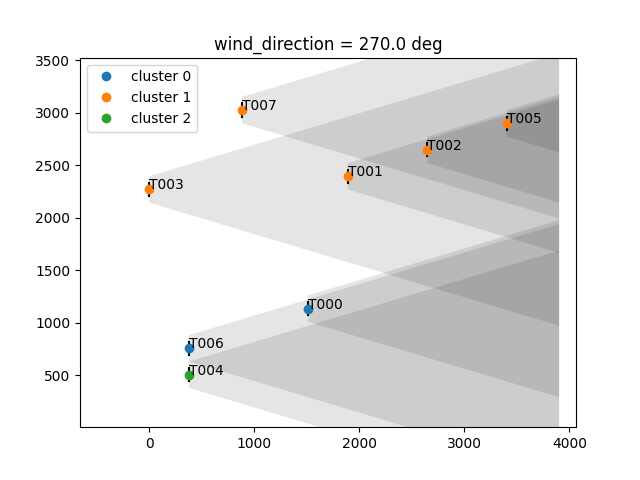
And another 8-turbine wind farm:
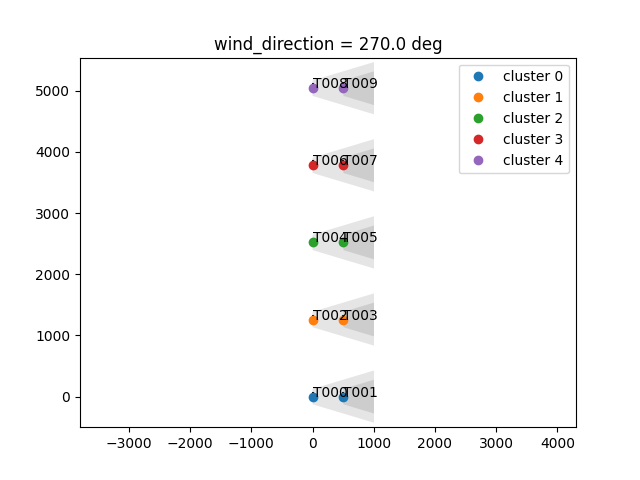
For a random 15 turbine wind farm:
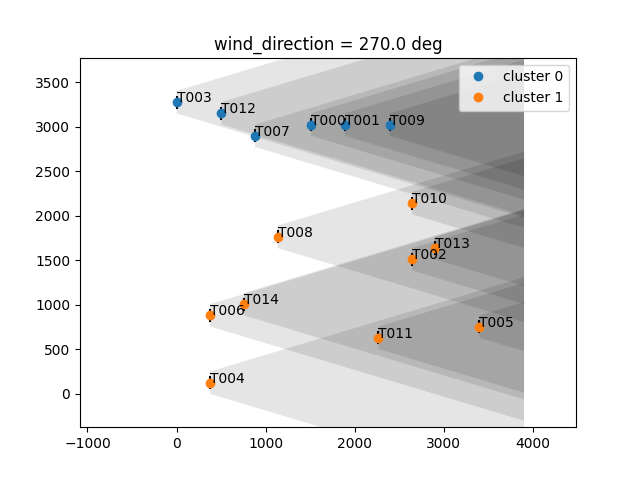
For a random 20 turbine wind farm:
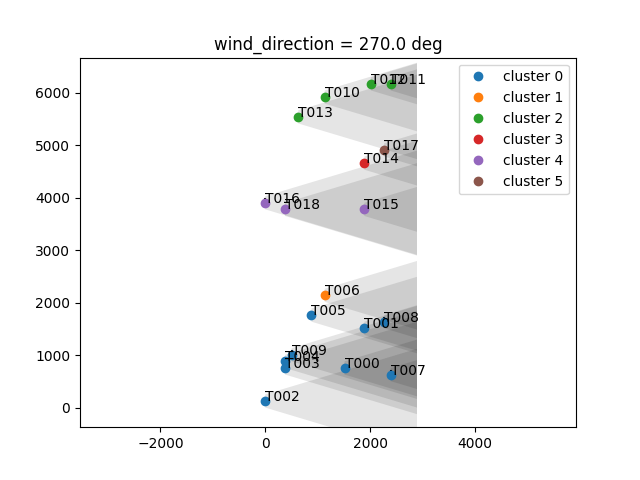
By far most cases show an equal or increased power production for the clustered optimization. In some situations, the cluster-based optimization may take longer than the full-farm optimization. This is when the baseline case converges to a local minimum very early and get stuck there, thereby exiting the optimization prematurely. Similarly, the optimization may also exit prematurely for the clustered optimization algorithm and yield a lower power production that the baseline case, by stroke of luck.
Something I may add later on is a quick check to see if the clustering algorithm was valid. This could be achieved by comparing the FLORIS power productions of all turbines in the clusters with those in the full farm. If they are all identical, then the clustering algorithm was successful.