最近看到我知乎很久以前收藏的一个文件,里面很多有图片的问题。一有心情就准备爬下来了,以防以后一页页的看。 但是基于我python很久没用,而且我主Java,不能总是瞎搞这些,于是决定用Java爬取。
随之而来的是想偷懒找个爬虫框架,但是很久都没有适合的,于是找了httpclient库来请求,处理结果使用fastjson,架包使用maven,目前具备爬取单个问题的全部图片,内部使用了线程池加快速度。
本来是想找找网上有过的python爬取知乎的逻辑,直接改用,但是发现这些项目都太久远了,知乎已经改版了部分,网页接口都变了很多,只能自己把逻辑写好了。
知乎改版真是很麻烦。我遇到的问题有不是所有的问题加上authorization请求头就可以访问,有些问题强制登陆,而知乎登录接口改版后很难写,更别说我用Java了,都说可以用登陆后的cookie避免登陆,但是我试了没什么用,不知道是不是方法不对,这部分留着等我学好了来写。
所以爬取问题前,确定你爬取的问题是可以直接访问而不用登陆的,我使用postman来模拟的。
json解析这里真是坑点满满,虽然也有很大部分是因为我对正则表达式不熟悉,都是边写边查的,但是Java中转义符号的坑也是很大的,就比如JSONObject对象调用getString返回的字符和toString的字符居然不一样,斜线有对应的转换,很坑啊。
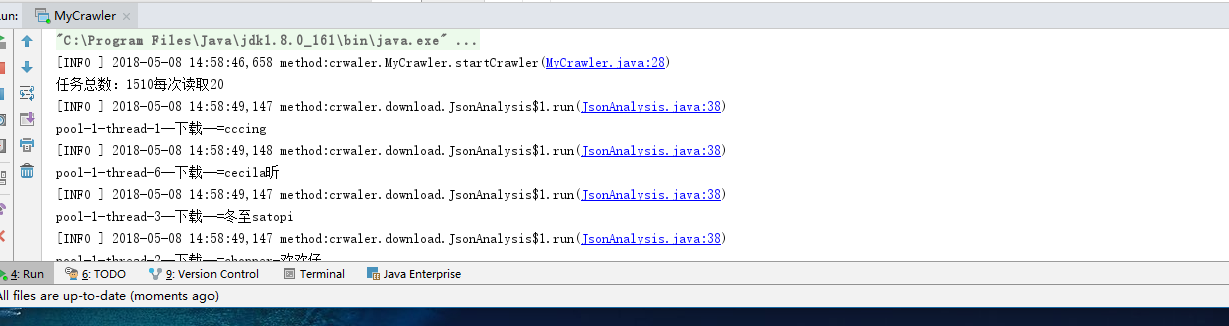
预计后期加入多问题爬取,如果有兴趣以及时间的话可以搞成一个spring boot项目,网页直接添加任务。
估摸了好几天终于搞定了知乎登陆的部分,可以爬取很多问题了。
还加上了保存cookie不用每次登陆了,下一步准备改造成web项目,在线添加任务。
知乎登陆的部分好像又有些许变化,原来的登陆有些问题,暂时搁置,直接爬虫问题就可以了,入口是MyCrawler.java的main函数,修改对应问题ID即可,线程数调整可以在JsonAnalysis.java里面修改,测试是可以运行的,之前需要登陆才能查看的问题现在好像都不需要了,可能知乎改了部分规则吧。