Project for the course Machine Learning in Bioinformatics, at Aalto University.
![Sakurambo [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0/)]](https://upload.wikimedia.org/wikipedia/commons/3/3f/Stem-loop.svg)
Sakurambo [CC BY-SA 3.0 (http://creativecommons.org/licenses/by-sa/3.0/)]
This project aims to tackle a simplified version of the RNA folding (secondary structure) problem using reinforcement learning. To achieve the mentionated goal it will be necessary to build the entire environment from scratch, including rewards, states and other necessary utilities.
- RNA
- Environment
- Policy
All those components are further explained below.
- Python 2.7 or 3
- Pytorch
git clone https://github.com/NetoPedro/RNAFoldingDeepRL.git
cd RNAFoldingDeepRL
python main.py
The RNA component has the main intention to model the behaviour of a RNA sequence and respective structure. This model is created in a simplified way.
The sequence is a string of the characters "A", "C", "U", "G" that represent the bases present on the RNA.

The structure representation is not unique, in a way that the secondary structure of a RNA sequence can be represented by a myriad of ways. Some representations are better to detect pseudoknots, others are better to feed to a policy.
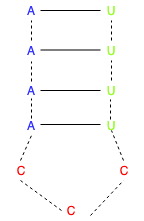
Above it is possible to see a common representation of the secondary structure of a RNA sequence. Below it is possible to see a ar diagram representation of other sequence.
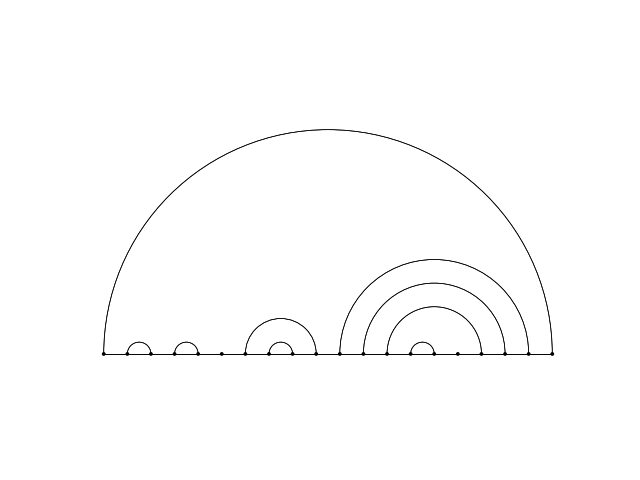
The folding proposed is constrained by the following rules:
- Pseudoknot or crossing are not allowed
- A certain base must belong to at most one pair
- A-U pairing is permitted
- C-G pairing is permitted
The structure has a myriad of representations, although for the purpose of this project only three representations are going to be considered. The first, attending to the rules above, is a dot matrix. This is a very good visualization approach, although verifying crosses is expensive. To second representation is a pairing list, a much simpler approach to verify crosses and pseudoknots. Finally the last representation is an One-Hot Encoded matrix detailed on the Policy subsection below.
The state represents the system at a given step. In this project, the state is defined as the RNA structure at that given step. For example, when the system is initialized the RNA structure does not have any pair, at each step a pairing function tries to update the state to the next step. The state has all the information needed to act on the system.
Actions are applied over the current state of the system generating another state (sometimes the state remains equal). An action in this problem is characterized by and attempt to pair/unpair two given bases together. It is possible that an action is not possible to be performed, resulting on a similar state.
The state of the system, and all the necessary functions to perform a step are packed in the environment. It is responsible to initialize all the necessary components to the system and is one of the most crucial components. Every step call performs an action, generating a new state, a reward value and an indication if it is possible to further improve from that step to the next ones. It should also include a reset function to reestablish the state of the system.
When an action is performed over a state, the action generates a possible change on the state. From this change it will result a value representing how good was the action performed. The value is usually known as the reward given by some action. Rewards can be positive, negative or just 0 (for example if the state does not change). Regarding this problem, the reward is the difference of connected bases on the statet and statet+1.
Exploitation is based on the current knowledge about the problem. To generate actions it is necessary to have a representation of the current knowledge. This representation is usually a mathematical function that predicts what should be done next, given a state as input. At the beginning the knowledge represented by the policy is much similar to a random exploration, but during the training process given some rewards the function parameters are updated to approximate the function to the optimal representation of the system dynamics.
The policy can be any mathematical technique able to represent a complex enough representation of the dynamics present on the system. In this paper, a deep convolutional neural network represents the policy as seen on the figure below. These networks were popularized by image recognition and other image-related tasks. Nevertheless, they perform generally good with most matrix-based inputs.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Aphex34 [CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0)]
As the input for the network, the state is represented by an 8*n matrix, where n stands for the size of the sequence. This representation simulates for each position from 0 to n and hot-encoding on the following categories:
- Base A unpaired
- Base A paired
- Base U unpaired
- Base U paired
- Base C unpaired
- Base C paired
- Base G unpaired
- Base G paired
Monte Carlo updates can be viewed as an episode-based update. With this method, the policy must be updated once at the end of each episode based on the obtained reward. This approach requires low computational power since the policy updates are not that frequent. Hence, it also originates some dumb initial guesses and possible slow convergence (depending on the initialized weights). Furthermore, since the updates are only at the end of the episode it does not give any detailed information regarding particular actions. For example, if a set of 100 actions is taken, with one of them being really bad, but an overall positive reward, the monte carlo update will not address that bad action.
Differently from the previous approach, temporal difference, also known as TD(0), updates the policy at each time step. These frequent updates lead to a faster convergence and a specific feedback on each action. Unfortunately, it introduces two other disadvantages, as the computational cost of updating the network, sometimes hundreds of times per episode and the introduction of a bias and reduction of the variance.
Usually state-space is too big to be search on reinforcement learning methods, or even infinite. Training the policy on states generated by previous policy actions is called exploitation, and the exclusive use of this tech- nique to select new actions, train the policy and back again to select new actions, can be problematic. Not only this may lead to a strictly narrow search of the state-space, but it can be responsible for being stuck on a local minimum. To solve this, it is necessary to understand the trade-off between exploitation and exploration (selecting an uniform random action). On initial episodes the exploration must be more frequent, with the further episodes, exploitation must become increasingly more frequent since the policy has been gathering information through the random exploration of the state space. It is worth noting that different environments and different problems require different trade-offs.
A prediction is considered correct if its reward matches the upperbound. Nevertheless there are maximal foldings that are lower than the upperbound. Because of this detail the following results must be considered as approximations with some error margin.
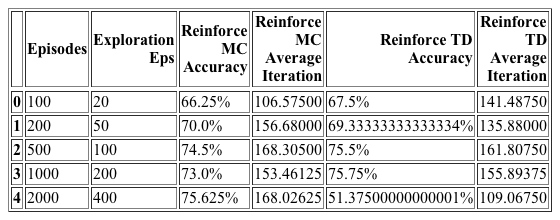
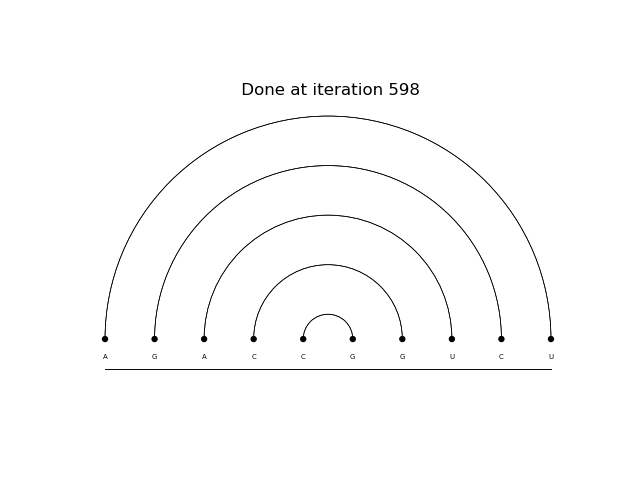
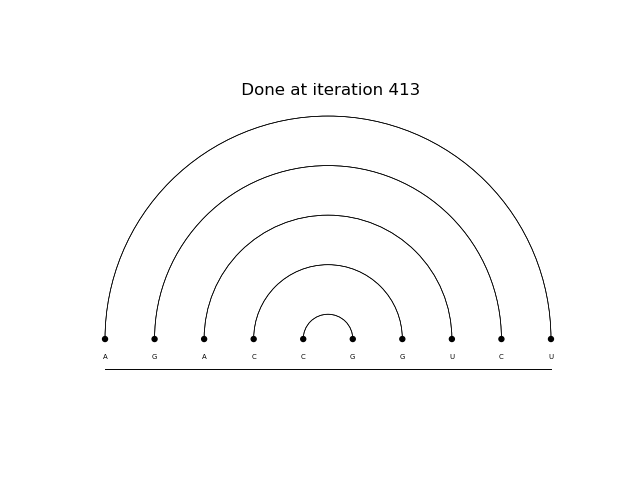
Above it is possible to see 2 predicted structures. The first is done by a monte carlo reinforce method after 2000 epochs. The second is done by a td(0) reinforce after 500 epochs.
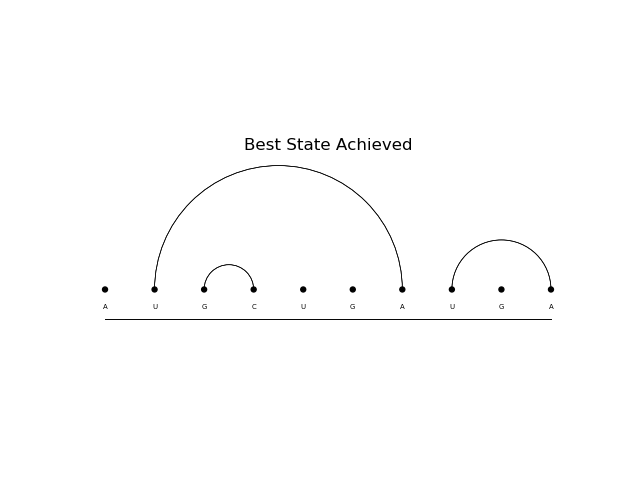
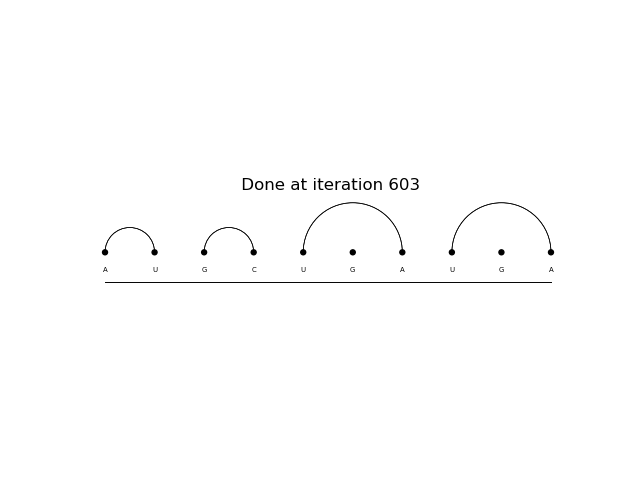
Above it is possible to see 2 predicted structures. The first is done by a monte carlo reinforce method after 2000 epochs. The second is done by a td(0) reinforce after 1000 epochs.