TileDB Tutorials
- Overview
- Physical Organization
- Writing to an Array
- Reading from an Array
- Workspaces and Groups
- Metadata
- Directory Management
- Parallel Programming
- Advanced I/O
- Compression Methods
This tutorial explains the internals and basic operations of the TileDB storage manager.
TileDB is a storage management system for data that is naturally represented as multi-dimensional arrays. An array in TileDB consists of dimensions and attributes. Each dimension has a domain, and all dimension domains collectively orient the logical space of the array. A combination of dimension domain values, referred to as coordinates, uniquely identifies an array element, called cell. Dimensions and attributes may have various types, but all dimension domains have the same type. The table below shows the currently supported dimension and attribute types.
| Types | Dimensions | Attributes |
|---|---|---|
| char (character) | ✘ | ✔ |
| int8 (8-bit integer) | ✔ | ✔ |
| uint8 (unsigned 8-bit integer) | ✔ | ✔ |
| int16 (16-bit integer) | ✔ | ✔ |
| uint16 (unsigned 16-bit integer) | ✔ | ✔ |
| int32 (32-bit integer) | ✔ | ✔ |
| uint32 (unsigned 32-bit integer) | ✔ | ✔ |
| int64 (64-bit integer) | ✔ | ✔ |
| uint64 (unsigned 64-bit integer) | ✔ | ✔ |
| float32 (32-bit floating point) | ✔ | ✔ |
| float64 (64-bit floating point) | ✔ | ✔ |
A cell may either be empty (NULL) or contain a tuple of attribute values. Each attribute is either a primitive type (one of those shown in the table above), or a fixed or variable-sized vector of a primitive type. For instance, consider an attribute representing complex numbers. Each cell may then store two float32 values for this attribute, one for the real part and one for the imaginary part. As another example, a string can be represented as a variable vector of characters.
Observe that this is sufficient to capture many applications, as long as each data item can be uniquely identified by a set of coordinates. For example, in an imaging application, each image can be modeled by a 2D matrix, with each cell representing the RGB values for that pixel. Another application is Twitter, where geo-tagged tweets can be stored in a 2D array whose cells are identified by float32 geographical coordinates, with each tweet stored in a variable-length char attribute.
Arrays in TileDB can be dense, where every cell contains an attribute tuple, or sparse, where some cells may be empty; all TileDB operations can be performed on either type of array, but the choice of dense vs. sparse can significantly impact storage requirements and application performance. Typically, an array is stored in sparse format if more than some threshold fraction of cells are empty. An example of a dense array is an image, whereas an example of a sparse array is the geo-tagged tweets from Twitter described above.
Figure 1 shows two example arrays, one dense one sparse. Both arrays have two dimensions, rows and columns. Both dimensions have domain [1,4] (in general, the arrays do not need to have square shape, and domains may be real-valued). The arrays have two attributes, a1 of type int32 and a2 of type variable char. Every cell is identified by its coordinates, i.e., a pair of rows, columns. In our examples throughout this tutorial, empty cells are shown in white, and non-empty cells in gray. Hence, in the dense array, every cell has an attribute tuple, e.g., cell (4,4) contains (15, {pppp}), whereas several cells in the sparse array are empty, e.g., cell (4,1).
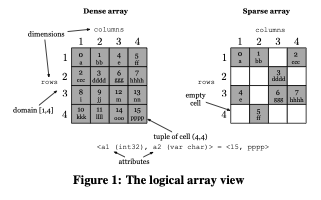
Note: Although TileDB does not support (variable) char dimension domains (i.e., string coordinates), it does support arbitrary metadata that can be attached to the dimension domains that can act as axes labels. See the Metadata section for more details on how TileDB supports arbitrary metadata. In the future, TileDB will seamlessly integrate char dimension types so that the user can directly query on string coordinates.
Whenever multi-dimensional data is stored to disk or memory it must be laid out in some linear order, since these storage media are single-dimensional. This choice of ordering can significantly impact application performance, since it affects which cells are near each other in storage. In TileDB, we call the mapping from multiple dimensions to a linear order the global cell order.
A desirable property is that cells that are accessed together should be co-located on the disk and in memory, to minimize disk seeks, page reads, and cache misses. The best choice of global cell order is dictated by application-specific characteristics; for example, if an application reads data a row-at-a-time, data should be laid out in rows. A columnar layout in this case will result in a massive number of additional page reads.
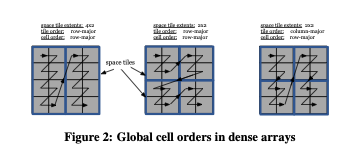
TileDB offers various ways to define the global cell order for an array, enabling the user to tailor the array storage to his or her application for maximum performance. For dense arrays, the global cell order is specified in three steps. First, the user decomposes the dimensional array domain into space tiles by specifying a tile extent per dimension (e.g., (2 times 2) tiles). This effectively creates equi-sized hyper-rectangles (i.e., each containing the same number of cells) that cover the entire logical space. Second, the user determines the cell order within each space tile, which can be either row-major or column-major. Third, the user determines a tile order, which is also either row-major or column-major. Figure 2 shows the global cell orders resulting from different choices in these three steps (the space tiles are depicted in blue).
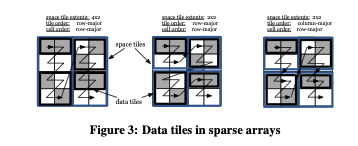
The notion of a global cell order also applies to sparse arrays. However, creating sparse tiles is somewhat more complex because simply using tiles of fixed logical size could lead to many empty tiles. Even if we suppressed storage of empty tiles, skew in many sparse datasets would create tiles of highly varied capacity, leading to ineffective compression, bookkeeping overheads, and some very small tiles where seek times represent a large fraction of access cost. Therefore, to address the case of sparse tiles, we introduce the notion of data tiles.
A data tile is a group of non-empty cells. It is the atomic unit of compression (as discussed below), and has a crucial role during reads. Similarly to a space tile, a data tile is enclosed in logical space by a hyper-rectangle. For the dense array case, each data tile has a one-to-one mapping to a space tile, i.e., it encompasses the cells included in the space tile.
For the sparse case, TileDB instead allows the user to specify a data tile capacity, and creates the data tiles such that they all have the same number of non-empty cells, equal to the capacity. To implement this, assuming that the fixed capacity is denoted by (c), TileDB simply traverses the cells in the global cell order imposed by the space tiles and creates one data tile for every (c) non-empty cells. A data tile of a sparse array is represented in the logical space by the tightest hyper-rectangle that encompasses the non-empty cells it groups, called the minimum bounding rectangle (MBR). Figure 3 illustrates various data tiles resulting from different global cell orders, assuming that the tile capacity is 2. The space tiles are depicted in blue color and the (MBR of the) data tiles in black. Note that data tiles in the sparse case may overlap, but each non-empty cell corresponds to exactly one data tile.
TileDB employs tile-based compression. Additionally, it allows the user to select different compression schemes on a per-attribute basis, as attributes are stored separately (as discussed below). See Section Compression Methods for more details.
A fragment is a timestamped snapshot of a batch of array updates, i.e., a collection of array modifications carried out via write operations and made visible at a particular time instant. For instance, the initial loading of the data into the array constitutes the first array fragment. If at a later time a set of cells is modified, then these cells constitute the second array fragment, and so on. In that sense, an array is comprised of a collection of array fragments, each of which can be regarded as a separate array, whose collective logical overlap composes the current logical view of the array. A fragment can be either dense or sparse. Dense fragments are used only with dense arrays, but sparse fragments may be applied to both dense and sparse arrays.
Figure 4 shows an example of an array with three fragments; the first two are dense and the third is sparse. Observe that the second fragment is dense within a hyper-rectangular subarray, whereas any cell outside this subarray is empty. The figure also illustrates the collective logical view of the array; the cells of the most recent fragments overwrite those of the older ones.
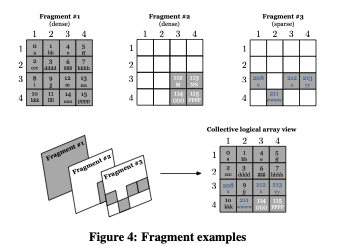
The fragments are the key concept that enables TileDB to perform rapid writes. If the number of fragments is reasonable, then their presence does not significantly affect the read performance. In the event that numerous fragments are created and the read performance becomes unsatisfactory, TileDB employs an efficient consolidation mechanism that coalesces fragments into a single one. Consolidation can happen in parallel in the background, while reads and writes continue to access the array. The concept of fragments and their benefits are explained later in this tutorial.
TileDB stores two types of metadata about an array: the array schema and the fragment bookkeeping. The array schema contains information about the definition of the array, such as its name, the number, names and types of dimensions and attributes, the dimension domain, the space tile extents, data tile capacity, and the compression types. The bookkeeping contains summary information about the physical organization of the stored array data in a fragment.
Note that the array metadata constitute internal information managed solely by TileDB. This is different from the arbitrary metadata that the user can attach to an array, explained in section Metadata.
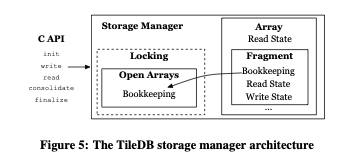
TileDB is a storage manager that exposes an API to users. The system architecture is described in Figure 5. The basic array operations are init, write, read, consolidate and finalize. Note that, depending on the API, these operations may be named slightly differently (e.g., in the TileDB C API, init is called tiledb_array_init). The storage manager keeps in-memory state for the open arrays, i.e., arrays that have been initialized and not yet finalized. This state keeps the bookkeeping metadata for each fragment of every open array in memory; this is shared between multiple threads that access the same array at the same time. Locks are used to mediate access to the state (covered in detail in Parallel Programming). Each thread has its own array object, which encapsulates a read state and one fragment object with its own read write state.
An array in TileDB is physically stored as a directory in the underlying file system. The array directory contains one sub-directory per array fragment, whose name is comprised of the MAC address of the machine and the id of the thread that created it, as well as a timestamp indicating when the fragment was created. Every fragment directory contains one file per fixed-sized attribute, and two files per variable-sized attribute. The attribute files store cell values in the global cell order in a binary representation. Storing a file per attribute is a form of "vertical partitioning", and allows efficient subsetting of the attributes in read requests. Each fragment directory also contains a file that stores the bookkeeping metadata of the fragment in binary, compressed format. We explain the physical storage for dense and sparse arrays with examples below.
Figure 6 shows the physical organization of the dense array of Figure 1, assuming that it follows the global cell order illustrated in the middle array of Figure 2. The cell values along the fixed-sized attribute a1 are stored in a file called a1.tdb, always following the specified global cell order. Attribute a2 is variable-sized and, thus, TileDB uses two files to physically store its values. Specifically, file a2_var.tdb stores the variable-sized cell values (again serialized along the global cell order), whereas a2.tdb stores the starting offsets of each variable-sized cell value in file a2_var.tdb. This enables TileDB to efficiently locate the actual cell value in file a2_var.tdb during read requests. For instance, cell (2,3) appears 7th in the global cell order. Therefore, TileDB can efficiently look-up the 7th offset in file a2.tdb (since the offsets are fixed-sized), which points to the beginning of the cell value {ggg} in a2_var.tdb.

Using this organization, TileDB does not need to maintain any special bookkeeping information. It only needs to record the subarray in which the dense fragment is constrained, plus some extra information in the case of compression (explained below).
An example of a fragment name is __00332a0b8c6426153_1458759561320, where 00332a0b8c64 is the uuid (represented as a 12-character hexadecimal string), 26153 is the thread id that created the fragment, and 1458759561320 is the timestamp of the creation in milliseconds.
Observe that, in the file organization of the array depicted in Figure 6, there are also four more files. File __array_schema.tdb contains information about the array definition (this file is typically very small). File __consolidation_lock.tdb is used to achieve process-safety in fragment consolidation (consolidation is covered in section Writing to an Array, whereas process-safety is explained in section Parallel Programming). File __book_keeping.tdb.gz contains the necessary bookkeeping information about a specific fragment (this is also a small, gzip-compressed file). Finally, __tiledb_fragment.tdb is an empty file indicating that the enclosing folder corresponds to a TileDB fragment.
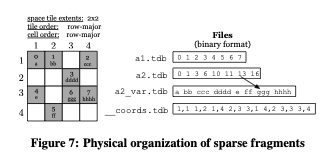
Figure 7 illustrates the physical organization of the sparse array of Figure 1, assuming that it follows the global cell order of the middle array of Figure 3. The attribute files of sparse arrays are organized in the same manner as those of dense, except that they contain only non-empty cells. That is, the cell values follow the global cell order in the attribute files, and there is an extra file for variable-sized attributes storing the starting offsets of the variable-sized cell values. Unlike dense arrays where the offset of each cell value can be directly computed, the same is not possible in sparse arrays, since the exact distribution of the non-empty cells is unknown. In order to locate the non-empty cells, TileDB stores an additional file with the explicit coordinates of the non-empty cells (__coords.tdb in the figure), which are once again serialized based on the global cell order. Note that the coordinates follow the order of the dimensions, as specified in the array schema upon array creation.
In order to achieve efficient reads, TileDB stores two types of bookkeeping information about the data tiles of a sparse array. Recall that a data tile is a group of non-empty cells of fixed capacity, associated with an MBR. TileDB stores the MBRs of the data tiles in the bookkeeping metadata, which facilitate the search for non-empty cells during a read request. In addition, it stores bounding coordinates, which are the first and last cell of the data tile along in the global cell order. These are important for reads as well.
A final remark on physical storage concerns compression. As mentioned earlier, TileDB compresses each attribute data tile separately, based on the compression type specified in the array schema for each attribute. In other words, for every attribute file, TileDB compresses the data corresponding to each tile separately prior to writing them into the file. Note that different tiles may be compressed into blocks of different size, even for fixed-sized attributes (since the compression ratio depends on the actual data contained in each tile). TileDB maintains bookkeeping information in order to be able to properly locate and decompress each tile upon a read request, such as the start offsets of each tile in each file, as well as the original size of each tile for the variable-sized tiles. This is illustrated in Figure 8 for an arbitrary file called file.tdb. Note that, typically, the bookkeeping information is many orders of magnitude smaller than the entire array size, and highly compressible.

The write operation loads and updates data in TileDB arrays. Each write session writes cells sequentially in batches, creating a separate fragment. A write session begins when an array is initialized in write mode (with init), comprises one or more write calls, and terminates when the array is finalized (with finalize). Depending on the way the array is initialized, the new fragment may be dense or sparse. A dense array may be updated with dense or sparse fragments, while a sparse array is only updated with sparse fragments. We explain the creation of dense and sparse fragments separately below, as well as the consolidation operation.
Upon array initialization, the user specifies the subarray region in which the dense fragment is constrained (it can be the entire domain). Then, the user populates one buffer per fixed-sized array attribute, and two buffers per variable-sized attribute, storing the cell values respecting the global cell order. This means the user must be aware of the tiling, as well as the tile and cell order specified upon the array creation. The buffer memory is managed solely by the user. The write function simply appends the values from the buffers into the corresponding attribute files, writing them sequentially, and without requiring any additional internal buffering (i.e., it writes directly from the user buffers to the files). Note that the user may call write repeatedly with different buffer contents, in the event that memory is insufficient to hold all the data at once. Each write invocation results in a series of sequential writes to the same fragment, one write per attribute file.
Figure 9 shows how the user can populate the dense array of the example of Figure 4. The user provides two items to the write API: buffers, a vector of binary buffers storing the array data, and buffer_sizes, a vector with the corresponding sizes (in bytes) of the buffers in buffers. Figure 9 demonstrates the contents of these two items in the case the user populates the array with a single write command, assuming that the user has initialized the array with attributes a1 and a2 (in this order). The first buffer corresponds to a1 and contains the attribute values in the same order as that of the global cell order. The second and third buffers correspond to a2; for any variable-sized attribute, the first of its corresponding buffers should always store the offsets of the cell values stored in the second buffer, as shown in the figure. Finally, buffer_sizes simply stores the sizes of the three buffers in bytes (in the figure we assume that an offset, which in TileDB is stored as size_t, consumes 4 bytes). Note that buffers should always correspond to the attributes used upon the initialization of the array prior to the write operation, respecting also their specified order.

TileDB also enables the user to populate an array via multiple write operations. Figure 9 shows the contents of the buffers in the case the user wishes to carry out the loading of the dense array in two separate write API invocations. Observe that the attribute buffers need not be synchronized; in the first write, the first 6 cells are written for attribute a1, whereas the first 8 cells are written for attribute a2. What is important is (i) inside each buffer, the cell values must be whole (e.g., the user should not split a 4-byte integer into two 2-byte values in each write operation), and (ii) the two buffers of each variable-sized attribute must be synchronized (i.e., there should always be a one-to-one correspondence between an offset and a variable-sized cell value in the provided buffers). Finally, observe in the second write in Figure 9 that the offsets buffer always contains offsets relative to the current variable-sized cell buffer; TileDB will handle the appropriate shifting of relative offsets to absolute offsets prior to writing the data in their respective files. TileDB does so by maintaining some lightweight write state throughout the write operations. The feature of multiple writes, coupled with the fact that the user is the one defining the subset of attributes and amount of data to write per write operation, provides great flexibility to the user in main memory management.
In addition, TileDB allows a user to write only to a subarray of a dense array, i.e., to a subset of the entire array domain. A subarray in TileDB is expressed by a low/high pair for each dimension. Writing to a subarray is particularly useful when loading data to an array with parallel threads or processes focusing on disjoint parts of the array, as well as for efficient updates. Figure 10 demonstrates an example, using the same dense array as Figure 9, but assuming that now the user wishes to focus only on subarray ([3,4], [2,4]) (i.e., focusing on rows 3 and 4, and columns 2, 3 and 4). This is depicted in Figure 10 where the meaningful cells are shown in grey. TileDB expects from the user to provide values for the expanded subarray that tightly encompasses their subarray, coinciding though with the array space tile boundaries. In the example, this means that TileDB expects values in the buffers for the expanded subarray ([3,4], [1,4]), where the cells ((3,1)) and ((4,1)) falling outside of the user's subarray should receive empty values. TileDB offers a special empty value for each type, namely TILEDB_EMPTY_*, where * is substituted by the type (e.g., TILEDB_EMPTY_INT32). Figure 10 shows the contents that the user should provide in her buffers when invoking the write API. Observe that the user must provide values for all cells in the expanded subarray (i.e., even for the two redundant cells). In the figure, the E stands for TILEDB_EMPTY_INT32 (of size 4 bytes) in the first buffer and TILEDB_EMPTY_CHAR (of size 1 byte) in the third buffer.

The previous write mode (refered to as TILEDB_ARRAY_WRITE) leads to the best performance, because TileDB receives the cell values from the user in exactly the same order as the one it stores them on the disk. Therefore, no additional internal cell re-organization is required to sort the cell values in the native array cell order. However, this mode is cumbersome for the user, since they need to be aware of the space tiling and be responsible for properly adding the special empty cell values.
Fortunately, TileDB supports two additional write modes, called TILEDB_ARRAY_WRITE_SORTED_ROW and TILEDB_ARRAY_WRITE_SORTED_COL. Essentially, these modes allow the user to provide the cell values in their buffers in row- or column-major, respectively, sorted with respect to their specified subarray. This is a more natural way to write to TileDB, as there is no need to know the space tiling, but rather focus is on the subarray to be written. Although this does require some internal cell re-organization (in order to map the cells from the subarray order to the native array cell order), TileDB performs this very efficiently (employing a linear algorithm for re-organization, as well as mixing asynchronous I/O with the CPU computations for the cell re-arrangement).
Figure 11 shows the same example as Figure 10, but now observe that the user does not add any special empty cell values. Moreover, they provide the values in row-major order within the target subarray [3,4], [2,4]. Note that TileDB always writes integral tiles on disk. Therefore, TileDB in fact writes 8 cells instead of the given 6 cells on disk, with the two extra cells being special empty cells. In other words Figure 11 produces an identical result to Figure 10 on the disk.

There are two different modes for creating sparse fragments. In the first, the user provides cell buffers to write. These buffers must be sorted in the global cell order. There are three differences with the dense case.
- The user provides values only for the non-empty cells.
- The user includes an extra buffer with the coordinates of the non-empty cells. The coordinates must be defined as an extra attribute upon the initialization of the array prior to writing, with the special name TILEDB_COORDS.
- Third, TileDB maintains some extra write state information for each created data tile (recall that a data tile may be different from a space tile). Specifically, it counts the number of cells seen so far and, for every (c) cells (where (c) is the data tile capacity specified upon array creation), TileDB stores the minimum bounding rectangle (MBR) and the bounding coordinates (first and last coordinates) of the data tile. Note that the MBR initially includes the first coordinates in the data tile, and expands as more coordinates are seen. For each data tile, TileDB stores its MBR and bounding coordinates into the fragment bookkeeping.
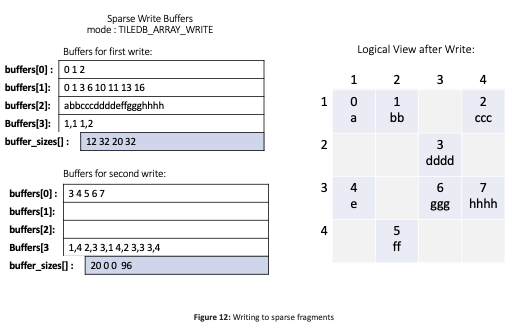
Figure 12 illustrates an example, using the same sparse array as Figure 7, and assuming that the user has specified the coordinates as the last attribute after a1 and a2. The figure shows the logical view of the array, as well as the contents of the buffers when the user populates the array with a single write operation. Similar to the dense case, the user may populate the array with multiple write API calls.
Sparse fragments are typically created when random updates arrive at the system, and it may be cumbersome for the user to sort the random cells along the global order. To handle this, TileDB also enables the user to provide unsorted cell buffers to write. This mode is called TILEDB_ARRAY_WRITE_UNSORTED in the C API (whereas the mode for writing sorted cells is called TILEDB_ARRAY_WRITE). TileDB internally sorts the buffers (using multiple threads), and then proceeds as explained above for the sorted case. Due to this internal sorting, write call in unsorted mode creates a separate fragment. Therefore, the write operations in this mode are not simple append operations as in the sorted cell mode, but they are rather similar to the sorted runs of the traditional Merge Sort algorithm. We will soon explain that TileDB can effectively merge all the sorted fragments into a single one.
Figure 13 demonstrates the unsorted mode of operation for the same array as in Figure 12. The figure displays the contents of the user's buffers. Observe that the cell coordinates in buffers[3] are not sorted on the array global cell order. Also observe that there is a one-to-one correspondence between the coordinates and the cell values in the rest of the buffers. TileDB will internally sort all the values properly, prior to writing the data to the files. Eventually, the written data will correspond to the logical view of Figure 12, and the physical storage will be identical to that of Figure 7.
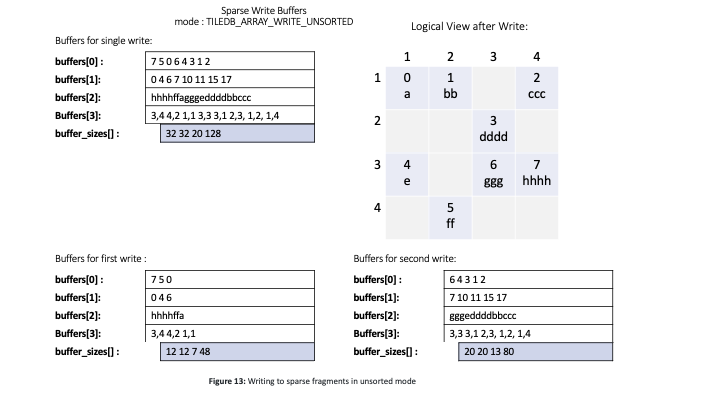
The unsorted mode of operation allows multiple writes as well. However, there are two differences as compared to the multiple writes in the sorted cell mode. The lower part of Figure 13 depicts the contents of the buffers for two writes. The first difference is that the attribute buffers must be synchronized, i.e., there must be a one-to-one correspondence between the values of each cell across all attributes. The second difference is that each write will create a new fragment, i.e., a new sub directory under the array directory, as shown in the figure.
Note that the TILEDB_ARRAY_WRITE mode for sparse arrays is much more efficient than TILEDB_ARRAY_WRITE_UNSORTED. This is becuase the latter involves an in-memory sorting. Therefore, if the user is certain that the data in their buffers follow the array cell order, they must always use TILEDB_ARRAY_WRITE.
TileDB supports efficient updates for both dense and sparse arrays. An array is updated by a new write operation (or sequence of write operations), which create a new fragment. At any given time instant, an array consists of a set of sorted fragments (in ascending order of timestamps, breaking ties arbitrarily using the thread id). The logical view of the array (i.e., its actual contents) is comprised of the union of the updates, with the cell conflicts being resolved by retaining the cell values of the most recent fragment. In other words, more recent cell values overwrite older ones. In this sub section we focus on the dense case, and in the following one we discuss the sparse case.
Figure 14 illustrates an example. The top part shows the initial load, which is the same as that of Figure 9. Recall that this loading can be accomplished by any number of writes, as long as the following sequence of operations takes place: (i) initialize the array, (ii) perform any number of writes, (iii) finalize the array. The figure also depicts two updates; the first is dense in subarray ([3,4], [3,4]), whereas the second is sparse and accounts for a set of random cell updates. This is one of the most interesting features in TileDB; random updates in dense arrays are expressed as sparse fragments. In our example, the cells are given in random order, but TileDB sorts them so that they follow the cell order specified in the array schema, namely row-major tile order with tile extent 2 on both dimensions, row-major cell order, and assuming that the user has specified data tile capacity equal to 2. These cells could have been given in sorted order as explained in Figure 12 for sparse arrays. Observe that there are three fragments, where the earliest timestamp corresponds to the first fragment and the latest to the third fragment. The lower part of the figure depicts the final logical view of the array, as well as its final file organization (observe that there are three sub-directories, one per fragment). Observe that the most recent updates overwrite the older ones, e.g., as in cell ((3,4)).
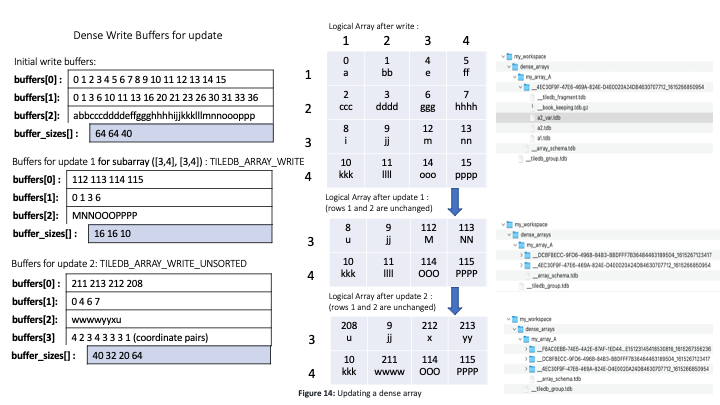
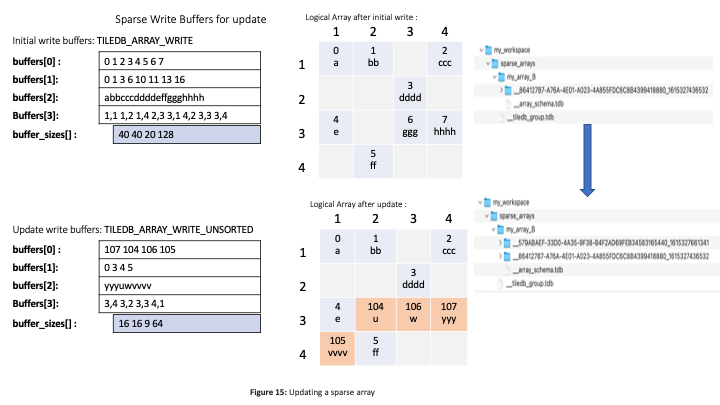
Figure 15 shows how sparse arrays can be updated. The top part depicts the initial load, which is identical to that of Figure 13. The figure also illustrates an update via a new write operation with unsorted cells. This creates a new fragment, which is tiled independently following the array schema. There are two insertions for cells ((3,2)) and ((4,1)), and two overwrites for cells ((3,3)) and ((3,4)). The lower part of the figure shows the final logical view of the sparse array, as well as the final file organization. There are two fragments, each having a separate sub directory under the array directory.
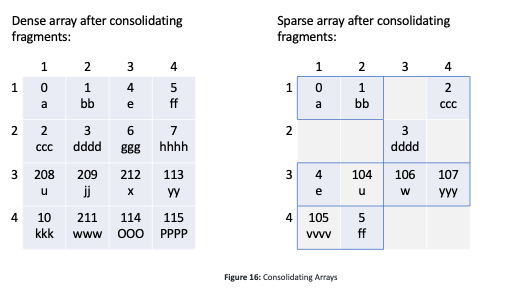
If an excessive number of update operations occurs, numerous fragments are created, which may naturally impact the performance of future reads. TileDB offers a consolidation feature, which merges all fragments into a single one. In other words, consolidation creates a new fragment sub directory under the array directory containing all the most up-to-date cell values, deleting the old fragment sub directories. Figure 16 depicts the dense array of Figure 14 and the sparse array of Figure 15 after their consolidation. Each array now consists of a single fragment. Moreover, observe in Figure 16 that the cells of the sparse array are properly re-tiled based on the tile and cell order (both row-major) and the data tile capacity that is equal to 2.
Note: Consolidating many small fragments with a few large ones can be costly, since the total consolidation time is dominated by reading and writing the large fragments. Informally, this suggests consolidation should be applied on fragments of approximately equal size. Moreover, read performance degrades when many data tiles of different fragments overlap in the logical space (this will become apparent in section Reading from an Array). Thus, it is important to consolidate those fragments before others. To address these issues, TileDB will soon enable the user to run consolidation on a specific subset of fragments. An additional benefit of selective consolidation applies specifically for the case where all the fragments have approximately the same size. In particular, the user can implement a hierarchical consolidation mechanism similar to that employed in LSM-Trees.
TileDB currently handles deletions (meaningful mostly for sparse arrays), as insertions of TILEDB_EMTPY_* values on all attributes of the cell to be deleted. It is the responsibility of the user to check for empty values upon reading (see the Reading from an Array section for more details).
Note: In the future, TileDB will offer an option to the user to omit the deleted values in a subarray read, or purge them completely in consolidation. This may come at some performance cost, but it will lead to easier subarray reads and effective storage space reclaimation in consolidation.
The read operation returns the values of any subset of attributes inside a user-supplied subarray. By default, the result is sorted on the global cell order within the subarray. The user specifies the subarray and attributes in the init call. During initialization, TileDB loads the bookkeeping data of each array fragment from the disk into main memory (which is generally very small).
The user calls read one or more times providing his or her own buffers that will store the results, one per fixed-length attribute, two per variable-lengths attribute, along with their sizes. TileDB populates the buffers with the results, following the global cell order within the specified subarray. For variable-sized attributes, the second buffer contains the starting cell offsets of the variable-sized cells in the first buffer. Note that, specifically for variable-length attributes and sparse arrays, the result size may be unpredictable, or exceed the size of the available main memory. To address this issue, TileDB handles buffer overflow gracefully. If the read results exceed the size of some buffer, TileDB fills in as much data as it can into the buffer and returns. The user can then consume the current results, and resume the process by invoking read once again. TileDB can achieve this by properly maintaining read state that captures the location where reading stopped.
The main challenge of reads is the fact that there may be multiple fragments in the array. This is because the results must be returned some sorted order (the global cell order by default), and read cannot simply search each fragment individually. The reason is that, if a recent fragment overwrites a cell of an older fragment, no data should be retrieved from the old fragment for this cell, but the old fragment should be used for adjacent cells. TileDB implements a read algorithm that allows it to efficiently access all fragments, skipping data that does not qualify for the result (the technical details of this algorithm are explained in an upcoming research paper). Independently of the number of fragments in the array, the user always sees the final array logical view as shown in the examples above.
Figure 17 depicts the logical view of the array from Figure 14 or Figure 16, i.e., it may contain three fragments or a single consolidated one; from the user's perspective when reading data, it makes no difference if the array is consolidated or not. Upon array initialization, suppose the user specifies as her query the subarray ([3,4], [2,4]), which is depicted as a blue rectangle in the figure. Also suppose that they specify all attribute values to be retrieved for this subarray. The user invokes a (single) read operation passing an array buffers of three empty buffers, with sizes 100 bytes each specified in buffer_sizes. It is the responsibility of the user to allocate memory for these buffers, which must be at least as big as specified in buffer_sizes. TileDB retrieves the relevant data and places them into the user's buffers as shown in the figure (after read). Observe that (by default) the cell values are written in the global cell order of the array schema (this leads to the best read performance). In addition, the offsets of buffers[1] for attribute a2 are always relative to the variable-sized cell values in buffers[2]. Finally, TileDB alters the sizes in buffer_sizes to reflect the size of the useful data written in the corresponding buffers.

Note that, if the array has only a subset of its domain populated (with the remainder being empty), TileDB returns TILEDB_EMPTY_* values for the empty cells intersecting the subarray query.
Similar to sorted writes, TileDB supports also sorted reads, which are efficiently implemented via a linear time re-arrangement algorithm and interleaved asynchronous I/O and CPU processing. Observe that, returning the cell values in the array global cell order requires the user to know the space tiling (and the cell/tile orders) in order to make sense of them. This mode was TILEDB_ARRAY_READ. TileDB provides two additional read modes, namely TILEDB_ARRAY_READ_SORTED_ROW and TILEDB_ARRAY_READ_SORTED_COL. These modes return the cell values sorted in row- or column-major order with repsect to the user subarray. Figure 18 shows the same example as Figure 17, but now observe that the cells are returned in row-major order within subarray [3,4], [2,4].

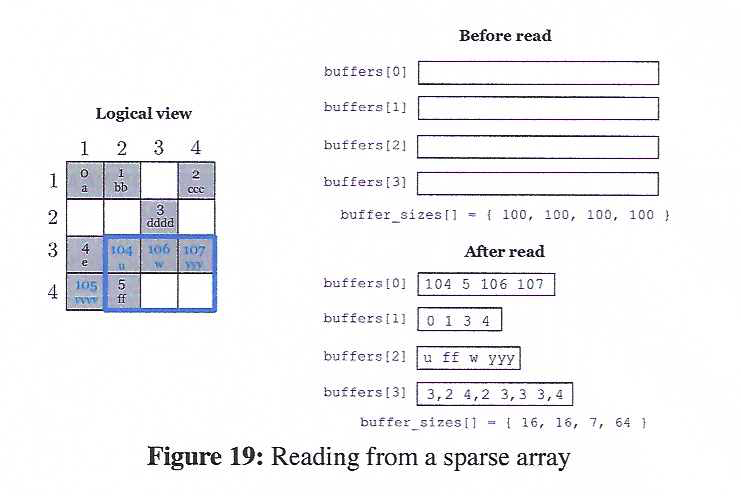
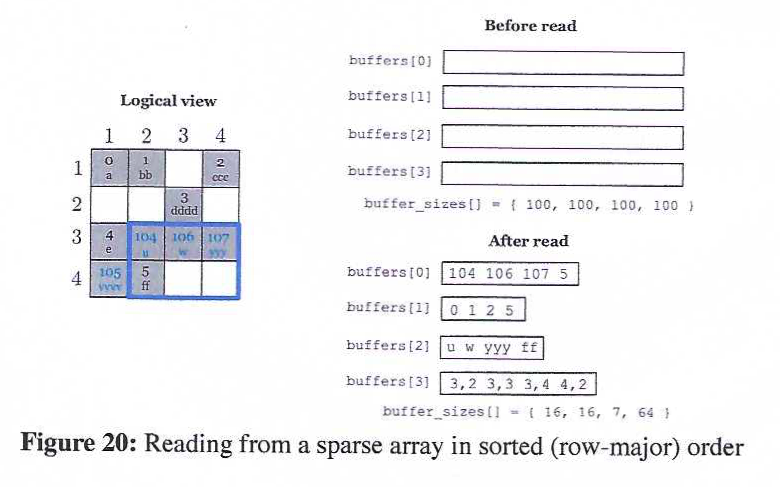
Figure 19 demonstrates how reads are performed in sparse arrays. The figure shows the logical view of the array used in the examples of Figure 15 and Figure 16. Once again, from the user's perspective, it does not make a difference if the array is consolidated or not. The query subarray is depicted as a blue rectangle. The idea is very similar to the dense case. The only difference is that the user may specify the coordinates as an extra attribute called TILEDB_COORDS if she wishes to retrieved the coordinates as well (but this is optional). The resulting buffers after the read are shown in the lower part of the figure. Observe that TileDB returns only the values of the non-empty cells inside the subarray. Moreover, assuming that the array was initialized in TILEDB_ARRAY_READ mode, the values are sorted in the global cell order.
Similar to the case of dense arrays, the user can read from a sparse array in TILEDB_ARRAY_READ_SORTED_ROW or TILEDB_ARRAY_READ_SORTED_COL mode, in order to get the cell values into their buffers in sorted row- or column-major order within the specified subarray query. This is illustrated in Figure 20, which is the same example as Figure 19, but now the cell values are returned sorted in row-major order within subarray [3,4], [2,4].
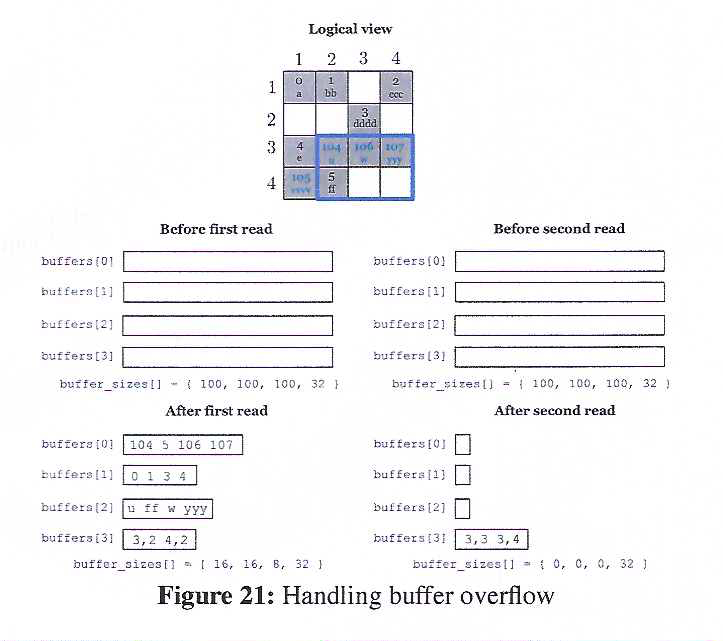
TileDB enables easy and flexible memory management at the user's side during reads, by gracefully handling buffer overflow. Specifically, the user does not need to carry out the subarray query in a single read API invocation, especially if she does not have enough available main memory to do so. Given buffers that cannot contain the entire result, instead of crashing, TileDB simply fills as much data as it can in the provided buffers, maintaining some read state about where exactly it stopped. Then, if the user invokes the read API once again providing the same or different buffers, TileDB resumes the query execution from the point it stopped, filling the remainder of the result data in the buffers. The read invocations for a particular subarray query must always occur after the array initialization, and before the array finalization (which flushes the read state).
TileDB handles buffer overflow in the same manner for both dense and sparse arrays. We explain it with an example using Figure 21, which focuses on the sparse array of Figure 20 (the approach is similar for dense arrays). The figure shows that the subarray query is answered with two read operations. Observe in the first read that, although the buffers have enough space to hold all values for attributes a1 and a2, the coordinates buffer can hold only 4 coordinates at a time. Therefore, the first read retrieves all attributes values, but only the first 4 coordinates. The second read retrieves the last 4 coordinates. Moreover, it does not retrieve any value for the other two attributes, since TileDB knows that these have been already retrieved.
TileDB also supports iterators, i.e., a means to retrieve the result values one by one via appropriate API functions. The iterators work for both dense and sparse arrays. They can also be constrained in a subarray of the domain, as well as any subset of attributes, while they also work with all read modes. They work very similarly to reads. The user initializes an iterator providing a subarray and a subset of attributes. She then invokes certain functions for getting the current value for any attribute, advancing the iterator, and checking if it has reached the end. An interesting feature of the TileDB iterators is that the user has full control over the utilized main memory. Specifically, upon array initialization, the user also provides buffers similar to the read operation. These buffers are used internally by TileDB for prefetching result data as the iterator advances. The size of the buffers (also controlled by the user) essentially can determine the performance of the iterators for the given application.
A final remark on reads regards deletions. Recall that deletions in TileDB are treated as insertions. Therefore, these should be taken into account when reading from arrays where deletions have occurred and handled at the user side. Moreover, note that the deletions persist even after consolidation in the current TileDB version. As we mentioned above, this will change in the upcoming TileDB versions.
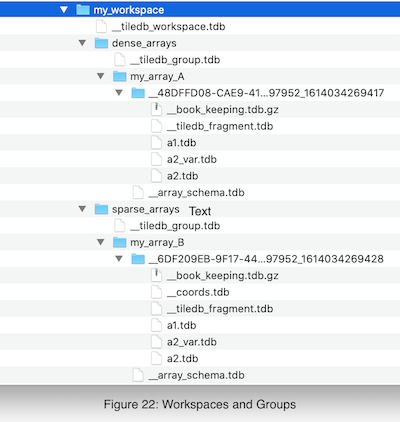
TileDB enables the user to hierarchically organize her arrays, very similar to the way she organizes her directories in the file system. This is done by creating workspaces and groups. A workspace is a directory that contains any number of groups and arrays, whereas a group is also a directory that contains any number of other groups and arrays. The difference between workspaces and groups is that a workspace is catalogued, so that TileDB can keep track of which directories are TileDB-related in the file system, whereas a group is not (see Directory Management for more details). Note that a workspace cannot be contained in any other TileDB-related directory (workspace, group, or array).
We explain further with an example. Suppose that the user wishes to create a workspace called my_workspace. Moreover, suppose she wishes to create two groups in the workspace, called dense_arrays and sparse_arrays. Finally suppose that she wishes to create array my_array_A in the first group, and my_array_B in the second. Figure 22 depicts the hierarchical file organization for this example. Special files __tiledb_workspace.tdb and __tiledb_group.tdb indicate that the parent folder is a TileDB workspace or group, respectively.
TileDB enables the user to associate any workspace, group, or array with metadata. To do so, the user can create a TileDB metadata object inside a workspace, group or array directory, respectively. A TileDB metadata object essentially stores key-value pairs, where the key is a string, and the value is any complex tuple. The user specifies the characteristics of the metadata (e.g., the number and types of elements in the value tuple) by populating a metadata schema, similar to the array schema for arrays. In fact, internally, TileDB implements the metadata as a 4-dimensional array, where the key is converted into a 16-byte MD5 hash, which is used to represent a 4-dimensional set of integer coordinates. Then the actual key along with the value tuple are implemented as the array attributes. Therefore, the TileDB API for metadata resembles that of arrays.
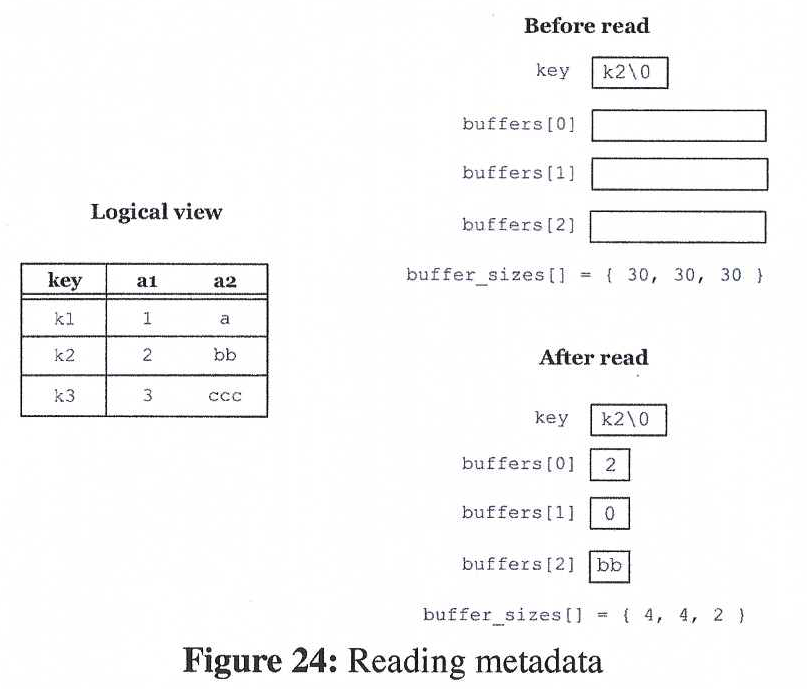
We explain the usage of the TileDB metadata with the example of Figure 23. We assume that the user has specified in the metadata schema that the value tuple consists of two attributes, a1 and a2, similar to the array cases we describe above (i.e., the types of the attributes are int32 and variable char, respectively). The metadata write API expects from the user buffers and buffer_sizes for the value attributes, as with the case of arrays. The difference here is that the API also expects an extra buffer called keys, along with its size in bytes, namely keys_size. The keys buffer holds the key strings of the metadata. The figure depicts the logical view of the metadata that the user wishes to create. Specifically, there are three key-value pairs, namely (k1, (1, a)), (k2, (2, bb)) and (k3, (3, ccc)). The user places the key strings in the keys buffer as shown in the figure. Observe that the user must also include the null character (\0) after each key. The value tuples are placed in buffers, as with the case of arrays.

Reading metadata is also similar to reading arrays. The user may specify any subset of attributes she wishes to retrieve upon metadata initialization. Instead of specifying a subarray though, the user here searches based on a key. Figure 24 demonstrates an example, which continues that of Figure 23. We assume that the user wishes to retrieve attributes a1 and a2 for key k2. As with the case of arrays, the user is the one managing her own buffers, which she provides to the read API. Buffer key holds the key string to be searched. The figure shows the buffer contents before and after the read call.
Note that the user is responsible for storing the actual keys as an extra attribute called TILEDB_KEY, by properly defining it in the attributes argument (or using NULL, which automatically includes it as an extra attribute at the end of the complete attribute list), and providing the corresponding buffers in the write API. This is similar to the coordinates attribute in the case of arrays, but note that the keys attribute is variable-sized. In addition, note that the same principle is followed for buffer overflow to the case of arrays. Finally, TileDB provides the feature of deletions, iterators and consolidation, in an identical manner to arrays.
TileDB allows the user to perform typical file system operations on the TileDB objects (i.e., workspaces, groups, arrays, metadata), such as move and delete. In addition, it offers an operation called clear, which deletes all the contents of the targeted object, but the object still exists after the operation. For instance, if an array is cleared, then all its fragment sub directories are deleted, but the array directory and its array schema file are untouched, which effectively means that the array remains defined. The same holds for the other objects, i.e., they remain defined after the clear operation.
Finally, TileDB enables the user to list the various existing TileDB objects. The user simply provides a directory, and TileDB returns the TileDB objects contained in that directory, along with their types. If the user does not know which directory may be a TileDB directory, she can ask TileDB to first list the workspaces, and she can navigate from that point and onwards until she finds what she is looking for. Therefore, TileDB keeps track of all the created workspaces. It does so by maintaining a system catalog, stored by default under directory ~/.tiledb/master_catalog/. This is practically implemented as a TileDB metadata object, which is properly updated whenever there is a file system operation on a workspace.
A single TileDB array can be read or written by multiple threads (with either pthreads or OpenMP) or processes (e.g., with MPI). TileDB allows both concurrent reads and writes (i.e., it supports mulitple-writer/multiple-reader access patterns), providing thread-/process-safety and atomic reads and writes. In addition, it enables consolidation to be performed in the background without obstructing concurrent reads and writes. Fragments enable all of these features as writes happen to independent fragments, and partial fragments are not visible to readers.
Concurrent writes are achieved by having each thread or process create a separate fragment. No internal state is shared and, thus, no locking is necessary at all. Note that each thread/process creates a fragment with a unique name, using its id and the current timestamp. Therefore, there are no conflicts even at the file system level.
Reads from multiple processes are independent and no locking is required. Every process loads its own bookkeeping data from the disk, and maintains its own read state. For multi-threaded reads, TileDB maintains a single copy of the fragment bookkeeping data, utilizing locking to protect the open arrays structure so that only one thread modifies the bookkeeping data at a time. Reads themselves do not require locking.
Concurrent reads and writes can be arbitrarily mixed. Each fragment contains a special file in its sub directory that indicates that this fragment should be visible. This file is not created until the fragment is finalized, so that fragments under creation are not visible to reads. Fragment-based writes make it so that reads simply see the logical view of the array without the new fragment.
Finally, consolidation can be performed in the background in parallel with other reads and writes. Locking is required only for a very brief period. Specifically, consolidation is performed independently of reads and writes. The new fragment that is being created is not visible to reads before consolidation is completed. The only time when locking is required is after the consolidation finishes, when the old fragments are deleted and the new fragment becomes visible. TileDB enforces its own file locking at this point. After all current reads release their shared lock, the consolidation function gets an exclusive lock, deletes the old fragments, makes the new fragment visible, and releases the lock. After that point, any future reads see the consolidated fragment.
For the case of multi-processing programs, note the following:
- Only one process must define/create an array/metadata without conflicts.
- After an array/metadata is created, any number of processes can read from or write to the array/metadata simultaneously.
- If reads and writes are interleaved, each read focuses only on the fragments that are already created at the time the array/metadata is initalized, disregarding the fragments that are in the process of being created by simultaneous writes.
For the case of multi-threaded programs, TileDB offers thread-safety and, thus, the same points hold for concurrent threads as those explained above for concurrent processes. The only additional requirement is the following:
- Every thread must initialize/finalize the array/metadata it will read from or write to after it is spawned. TileDB makes sure that no bookkeeping structures get replicated or overwritten while multiple threads are reading from or writing to an array/metadata. However, each thread has its own read state and, thus, the array must be initialized separately for each thread.
TileDB provides various I/O methods, such as POSIX read/write, memory map (mmap), and MPI-IO. TileDB by default uses POSIX write for writes and mmap for reads. We have experimentally observed the following, which may help the user choose the most appropriate I/O method for a given application:
- mmap is better than POSIX read when there are multiple small random reads on a hard disk (HDD). On the other hand, if a solid state drive (SSD) is used, read is a better choice for random small reads. If there are large sequential reads involved (on either HDD or SSD), these two methods perform the same.
- MPI-IO is beneficial when a parallel file system (e.g., Lustre) is used to store an array, and there are multiple processes reading from the same array files. In this case, MPI-IO attempts to optimize the accesses from the multiple processes, in a way that the locality (and hence performance) of the I/O is maximized.
Moreover, TileDB provides API for asynchronous I/O. In asynchronous I/O, the TileDB read or write operation returns control to the caller function immediately after its invocation, and performs the I/O in the background. The caller function may either pass a callback function to the asynchronous I/O, or check a flag set by the asynchronous I/O operation that indicates whether the process is in progress, completed, or caused an error. Figure 25 shows the difference between a synchronous and an asynchronous I/O operation.
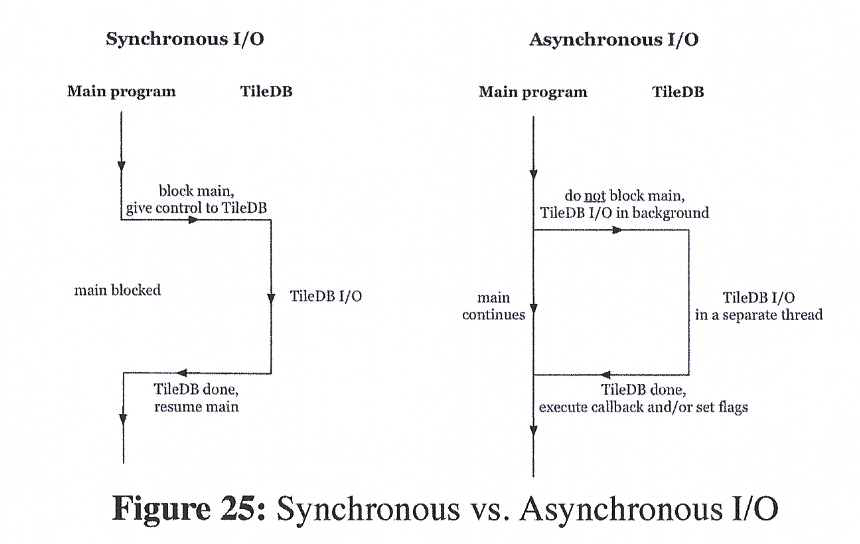
Asynchronous I/O is particularly useful in CPU-bound applications. Specifically, it can be used to fetch data from the disk in the background, while the program is executing in parallel a CPU-intensive operation. This can effectively eliminate the I/O cost from the total program time.
Recall that TileDB provides attribute-based compression, and compresses each tile separately for each attribute. TileDB suppports a wide variety of compression methods, listed in the table below (the C API constant is used in the definition of the schema of the array upon its creation, whereas recall that TileDB can admit a different compression method per attribute):
| Method | C API Constant |
|---|---|
| No compression | TILEDB_NO_COMPRESSION |
| GZIP with Zlib | TILEDB_GZIP |
| Zstandard | TILEDB_ZSTD |
| LZ4 | TILEDB_LZ4 |
| BloscLZ (default Blosc) | TILEDB_BLOSC |
| Blosc + LZ4 | TILEDB_BLOSC_LZ4 |
| Blosc + LZ4HC | TILEDB_BLOSC_LZ4HC |
| Blosc + Snappy | TILEDB_BLOSC_SNAPPY |
| Blosc + Zlib | TILEDB_BLOSC_ZLIB |
| Blosc + Zstandard | TILEDB_BLOSC_ZSTD |
| RLE | TILEDB_RLE |
Note that Blosc comes with multiple compressors; BloscLZ is the default one, but it works also in combination with LZ4, LZ4HC, Snappy, Zlib, and Zstandard.
For GZIP, Zstandard, and Blosc, TileDB allows the user to optionally define the compression level upon compilation time (if no level is provided, TileDB uses the default level of the corresponding libarary). See the TileDB GitHub Wiki for more information on setting various flags at compilation time.
Recall that TileDB writes the coordinates of all dimensions in a single file, treating them as tuples (c_1, c_2, ldots, c_d), where (d) is the number of dimensions. To make compression more effective, prior to compressing a coordinate tile, TileDB splits the coordinate values into (d) vectors, such that the coordinates of each dimension are stored consecutively in a single vector. This is because the coordinates are always written sorted in row- or column-major and, thus, it is highly likely that the coordinates of one dimension are highly repetitive, considerably facilitating the compressor.
TileDB offers its own RLE implementation. For attributes, the algorithm is quite straightforward. For instance, let [1,1,3,3,3,3,3,3,3,4] be the values of an array on some attribute. TileDB compresses these values into [(1,2), (3,7), (4,1)], where the first value of each pair is the attribute value being compressed, and the second value is the number of times it appears contiguously in the array. Decompression in this case is also very simple. Note that TileDB stores the second values (i.e., the lengths of each run) as 2-byte values. Note also that, in the case of fixed-sized attributes with multiple values per cell, TileDB makes sure that it considers all the values of the cell as a single value to be compressed. For instance, if some attribute admits two integers per cell and the attribute values are [(1,2), (1,2), (1,2)], then TileDB compresses this to ((1,2),3), i.e., cell value (1,2) appears three times. Finally, for the variable-sized attributes, TileDB considers only a single value per cell when compressing. For instance, for a string attribute with cell values [aaa, ab, cd], TileDB will compress to [(a,4), (b,1), (c,1), (d,1)], i.e., as if the attribute was char of fixed size 1 value per cell.
The case of compressing the coordinates with RLE is more interesting. We make two observations, both of which depend on the cell order: (i) Some dimension coordinates are repetitive, (ii) some are less so. Consider for example a 2-dimensional array with row-major cell order, and coordinates [(1,1), (1,3), (1,4), (2,2), (2,4), (2,5)]. Naively applying RLE here leads essentially to inflating the storage size rather than deflating it. Observing that the coordinates of the first dimension, when considered alone, do indeed feature repetition in contiguous coordinates, whereas those of the second do not, we split the coordinates based on the dimension first. In other words, we produce two cooordinate vectors, [1,1,1,2,2,2] for the first dimension, and [1,3,4,2,4,5] for the second. Now observe that the first vector is nicely compressible with RLE to [(1,3), (2,3)], whereas the second not at all. TileDB in this case compresses only the first dimension vector, leaving the second one intact. In the general case of a d-dimensional array with row-major cell order, TileDB splits and compresses with RLE the first (d-1) coordinate vectors, leaving the d-th intact. For the case of column-major order. TileDB compresses the last (d-1) coordinate vectors, leaving the first one intact.
Note that the compression method must be selected based on the application, as well as the nature of the data for each attribute. With support for a wide variety of compressions, TileDB provides flexibility and enables the user to explore and choose the most appropriate one for her use case. Moreover, note that TileDB allows the user to set the compression level (for the compression methods that admit one, e.g., GZIP, Blosc, and Zstandard). Please see the TileDB GitHub Wiki for more details on setting the compression level upon compilation time.
- Constants
- Configuration
- Context
- Creating Workspaces and Groups
- Creating an Array
- Primitive Array Operations
- Writing to an Array
- Reading from an Array
- Array Iterator
- Creating Metadata
- Primitive Metadata Operations
- Writing Metadata
- Reading Metadata
- Metadata Iterator
- Directory Management
- Asynchronous I/O
- Examples
This tutorial explains the TileDB C API. It also contains many examples, whose code can be found at our TileDB GitHub repo. Throughout the tutorial, we assume you have properly built the examples, whose binaries are located in directory examples/bin/release/ (or examples/bin/debug/ if you built them in debug mode) of your locally cloned TileDB repo. The TileDB GitHub Wiki contains instructions for building TileDB, and also for linking the TileDB C library to your own future code. In case you wish to skip the C API descriptions, you can navigate directly to the examples.
The TileDB version.
#define TILEDB_VERSION "0.6.0"
Return codes.
#define TILEDB_OK 0
#define TILEDB_ERR -1
Array modes.
#define TILEDB_ARRAY_READ 0
#define TILEDB_ARRAY_READ_SORTED_COL 1
#define TILEDB_ARRAY_READ_SORTED_ROW 2
#define TILEDB_ARRAY_WRITE 3
#define TILEDB_ARRAY_WRITE_SORTED_COL 4
#define TILEDB_ARRAY_WRITE_SORTED_ROW 5
#define TILEDB_ARRAY_WRITE_UNSORTED 6
Metadata modes.
#define TILEDB_METADATA_READ 0
#define TILEDB_METADATA_WRITE 1
The TileDB home directory. If it is set to the empty string (""), then the home directory is set to the current working directory.
#define TILEDB_HOME ""
TileDB object types.
#define TILEDB_WORKSPACE 0
#define TILEDB_GROUP 1
#define TILEDB_ARRAY 2
#define TILEDB_METADATA 3
The TileDB I/O (read and write) methods.
#define TILEDB_IO_MMAP 0
#define TILEDB_IO_READ 1
#define TILEDB_IO_MPI 2
#define TILEDB_IO_WRITE 0
Asynchronous I/O (AIO) codes.
#define TILEDB_AIO_ERR -1
#define TILEDB_AIO_COMPLETED 0
#define TILEDB_AIO_INPROGRESS 1
#define TILEDB_AIO_OVERFLOW 2
The maximum length for the names of TileDB objects.
#define TILEDB_NAME_MAX_LEN 4096
Size of the buffer used during consolidation ~10MB.
#define TILEDB_CONSOLIDATION_BUFFER_SIZE 10000000
Special empty cell values.
#define TILEDB_EMPTY_INT8 INT8_MAX
#define TILEDB_EMPTY_UINT8 UINT8_MAX
#define TILEDB_EMPTY_INT16 INT16_MAX
#define TILEDB_EMPTY_UINT16 UINT16_MAX
#define TILEDB_EMPTY_INT32 INT32_MAX
#define TILEDB_EMPTY_UINT32 UINT32_MAX
#define TILEDB_EMPTY_INT64 INT64_MAX
#define TILEDB_EMPTY_UINT64 UINT64_MAX
#define TILEDB_EMPTY_FLOAT32 FLT_MAX
#define TILEDB_EMPTY_FLOAT64 DBL_MAX
#define TILEDB_EMPTY_CHAR CHAR_MAX
Special values indicating a variable number or size.
#define TILEDB_VAR_NUM INT_MAX
#define TILEDB_VAR_SIZE (size_t)-1
Data types.
#define TILEDB_INT32 0
#define TILEDB_INT64 1
#define TILEDB_FLOAT32 2
#define TILEDB_FLOAT64 3
#define TILEDB_CHAR 4
#define TILEDB_INT8 5
#define TILEDB_UINT8 6
#define TILEDB_INT16 7
#define TILEDB_UINT16 8
#define TILEDB_UINT32 9
#define TILEDB_UINT64 10
Tile or cell orders.
#define TILEDB_ROW_MAJOR 0
#define TILEDB_COL_MAJOR 1
Compression types.
#define TILEDB_NO_COMPRESSION 0
#define TILEDB_GZIP 1
#define TILEDB_ZSTD 2
#define TILEDB_LZ4 3
#define TILEDB_BLOSC 4
#define TILEDB_BLOSC_LZ4 5
#define TILEDB_BLOSC_LZ4HC 6
#define TILEDB_BLOSC_SNAPPY 7
#define TILEDB_BLOSC_ZLIB 8
#define TILEDB_BLOSC_ZSTD 9
#define TILEDB_RLE 10
Special attribute names.
#define TILEDB_COORDS "__coords"
#define TILEDB_KEY "__key"
Special TileDB file name suffices.
#define TILEDB_FILE_SUFFIX ".tdb"
#define TILEDB_GZIP_SUFFIX ".gz"
Chunk size in GZIP compression.
#define TILEDB_GZIP_CHUNK_SIZE 131072
Special TileDB file names.
#define TILEDB_ARRAY_SCHEMA_FILENAME "__array_schema.tdb"
#define TILEDB_METADATA_SCHEMA_FILENAME "__metadata_schema.tdb"
#define TILEDB_BOOK_KEEPING_FILENAME "__book_keeping.tdb"
#define TILEDB_FRAGMENT_FILENAME "__tiledb_fragment.tdb"
#define TILEDB_GROUP_FILENAME "__tiledb_group.tdb"
#define TILEDB_WORKSPACE_FILENAME "__tiledb_workspace.tdb"
Sizes of buffers used for sorting.
#define TILEDB_SORTED_BUFFER_SIZE 10000000
#define TILEDB_SORTED_BUFFER_VAR_SIZE 10000000
Compression levels (set to default, usually set in the array schema)
#define TILEDB_COMPRESSION_LEVEL_GZIP Z_DEFAULT_COMPRESSION
#define TILEDB_COMPRESSION_LEVEL_ZSTD 1
#define TILEDB_COMPRESSION_LEVEL_BLOSC 5
typedef struct TileDB_Config {
const char* home_;
MPI_Comm* mpi_comm_;
int read_method_;
int write_method_;
} TileDB_Config;
Members
home_ The TileDB home directory.
If it is set to "" (empty string) or NULL, then the default home directory will be used, which is ~/.tiledb/.
mpi_comm_ The MPI communicator.
Use NULL, if no MPI is used.`
read_method_ The method for reading data from a file. It can be one of the following:
TILEDB_IO_MMAP (use of memory map)
TILEDB_IO_READ (standard OS read)
TILEDB_IO_MPI (use of MPI-IO)
write_method_ The method for writing data to a file. It can be one of the following:
TILEDB_IO_WRITE (standard OS write)
TILEDB_IO_MPI> (use of MPI-IO)
typedef struct TileDB_CTX TileDB_CTX;
The TileDB context encapsulates the various TileDB modules (which are implemented in C++), and constitutes the state maintained throughout the subsequent TileDB C API calls. The user must initialize a TileDB context prior to using any other TileDB C API (via tiledb_ctx_init), and always finalize it when done using the API (via tiledb_ctx_finalize).
/**
* Initializes the TileDB context.
*
* @param tiledb_ctx The TileDB context to be initialized.
* @param tiledb_config TileDB configuration parameters. If it is NULL,
* TileDB will use its default configuration parameters.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_ctx_init(
TileDB_CTX** tiledb_ctx,
const TileDB_Config* tiledb_config);
/**
* Finalizes the TileDB context, properly freeing-up memory.
*
* @param tiledb_ctx The TileDB context to be finalized.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_ctx_finalize(TileDB_CTX* tiledb_ctx);/**
* Creates a new TileDB workspace.
*
* @param tiledb_ctx The TileDB context.
* @param workspace The directory of the workspace to be created in the file
* system. This directory should not be inside another TileDB workspace,
* group, array or metadata directory.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_workspace_create(
const TileDB_CTX* tiledb_ctx,
const char* workspace);
/**
* Creates a new TileDB group.
*
* @param tiledb_ctx The TileDB context.
* @param group The directory of the group to be created in the file system.
* This should be a directory whose parent is a TileDB workspace or another
* TileDB group.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_group_create(
const TileDB_CTX* tiledb_ctx,
const char* group);/** The array schema. */
typedef struct TileDB_ArraySchema {
/**
* The TileDB workspace. It is a directory.
*/
char* array_workspace_;
/**
* The array name. It is a directory, whose parent must be a TileDB workspace,
* or group.
*/
char* array_name_;
/** The attribute names. */
char** attributes_;
/** The number of attributes. */
int attribute_num_;
/**
* The tile capacity for the case of sparse fragments. If it is <=0,
* TileDB will use its default.
*/
int64_t capacity_;
/**
* The cell order. It can be one of the following:
* - TILEDB_ROW_MAJOR
* - TILEDB_COL_MAJOR
* - TILEDB_HILBERT.
*/
int cell_order_;
/**
* Specifies the number of values per attribute for a cell. If it is NULL,
* then each attribute has a single value per cell. If for some attribute
* the number of values is variable (e.g., in the case off strings), then
* TILEDB_VAR_NUM must be used.
*/
int* cell_val_num_;
/**
* The compression type for each attribute (plus one extra at the end for the
* coordinates). It can be one of the following:
* - TILEDB_NO_COMPRESSION
* - TILEDB_GZIP
* - TILEDB_ZSTD
* - TILEDB_LZ4
* - TILEDB_BLOSC
* - TILEDB_BLOSC_LZ4
* - TILEDB_BLOSC_LZ4HC
* - TILEDB_BLOSC_SNAPPY
* - TILEDB_BLOSC_ZLIB
* - TILEDB_BLOSC_ZSTD
* - TILEDB_RLE
*
* If it is *NULL*, then the default TILEDB_NO_COMPRESSION is used for all
* attributes.
*/
int* compression_;
/** Specifies the compression level */
int* compression_level_;
/** Compression type for the offsets for variable number of cells TILEDB_VAR_NUM for attribute */
int* offsets_compression_;
/** Compression level for the offsets for variable number of cells TILEDB_VAR_NUM for attribute */
int* offsets_compression_level_;
/**
* Specifies if the array is dense (1) or sparse (0). If the array is dense,
* then the user must specify tile extents (see below).
*/
int dense_;
/** The dimension names. */
char** dimensions_;
/** The number of dimensions. */
int dim_num_;
/**
* The array domain. It should contain one [low, high] pair per dimension.
* The type of the values stored in this buffer should match the coordinates
* type.
*/
void* domain_;
/**
* The tile extents. There should be one value for each dimension. The type of
* the values stored in this buffer should match the coordinates type. It
* can be NULL only for sparse arrays.
*/
void* tile_extents_;
/**
* The tile order. It can be one of the following:
* - TILEDB_ROW_MAJOR
* - TILEDB_COL_MAJOR.
*/
int tile_order_;
/**
* The attribute types, plus an extra one in the end for the coordinates.
* The attribute type can be one of the following:
* - TILEDB_INT32, TILEDB_UINT32
* - TILEDB_INT64, TILEDB_UINT64
* - TILEDB_FLOAT32
* - TILEDB_FLOAT64
* - TILEDB_CHAR, TILEDB_INT8, TILEDB_UINT8
* - TILEDB_INT16, TILEDB_UINT16
*
* The coordinate type can be one of the following:
* - TILEDB_INT32
* - TILEDB_INT64
* - TILEDB_FLOAT32
* - TILEDB_FLOAT64
*/
int* types_;
} TileDB_ArraySchema;
/**
* Populates a TileDB array schema object.
*
* @param tiledb_array_schema The array schema to be populated.
* @param array_name The array name.
* @param attributes The attribute names.
* @param attribute_num The number of attributes.
* @param capacity The tile capacity.
* @param cell_order The cell order.
* @param cell_val_num The number of values per attribute per cell.
* @param compression The compression type for each attribute (plus an extra one
* in the end for the coordinates).
* @param compression_level The compression level associated with the compression type per attribute
* @param dense Specifies if the array is dense (1) or sparse (0).
* @param dimensions The dimension names.
* @param dim_num The number of dimensions.
* @param domain The array domain.
* @param domain_len The length of *domain* in bytes.
* @param tile_extents The tile extents.
* @param tile_extents_len The length of *tile_extents* in bytes.
* @param tile_order The tile order.
* @param types The attribute types (plus one in the end for the coordinates).
* @return TILEDB_OK for success and TILEDB_ERR for error.
* @see TileDB_ArraySchema
*/
TILEDB_EXPORT int tiledb_array_set_schema(
TileDB_ArraySchema* tiledb_array_schema,
const char* array_name,
const char** attributes,
int attribute_num,
int64_t capacity,
int cell_order,
const int* cell_val_num,
const int* compression,
const int* compression_level,
const int* offsets_compression,
const int* offsets_compression_level,
int dense,
const char** dimensions,
int dim_num,
const void* domain,
size_t domain_len,
const void* tile_extents,
size_t tile_extents_len,
int tile_order,
const int* types);/** A TileDB array object. */
typedef struct TileDB_Array TileDB_Array;
/**
* Initializes a TileDB array.
*
* @param tiledb_ctx The TileDB context.
* @param tiledb_array The array object to be initialized. The function
* will allocate memory space for it.
* @param array The directory of the array to be initialized.
* @param mode The mode of the array. It must be one of the following:
* - TILEDB_ARRAY_WRITE
* - TILEDB_ARRAY_WRITE_SORTED_COL
* - TILEDB_ARRAY_WRITE_SORTED_ROW
* - TILEDB_ARRAY_WRITE_UNSORTED
* - TILEDB_ARRAY_READ
* - TILEDB_ARRAY_READ_SORTED_COL
* - TILEDB_ARRAY_READ_SORTED_ROW
* @param subarray The subarray in which the array read/write will be
* constrained on. It should be a sequence of [low, high] pairs (one
* pair per dimension), whose type should be the same as that of the
* coordinates. If it is NULL, then the subarray is set to the entire
* array domain. For the case of writes, this is meaningful only for
* dense arrays, and specifically dense writes.
* @param attributes A subset of the array attributes the read/write will be
* constrained on. Note that the coordinates have special attribute name
* TILEDB_COORDS. A NULL value indicates **all** attributes (including
* the coordinates as the last attribute in the case of sparse arrays).
* @param attribute_num The number of the input attributes. If *attributes* is
* NULL, then this should be set to 0.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_init(
const TileDB_CTX* tiledb_ctx,
TileDB_Array** tiledb_array,
const char* array,
int mode,
const void* subarray,
const char** attributes,
int attribute_num);
/**
* Finalizes a TileDB array, properly freeing its memory space.
*
* @param tiledb_array The array to be finalized.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_finalize(
TileDB_Array* tiledb_array);
/**
* Retrieves the schema of an array from disk.
*
* @param tiledb_ctx The TileDB context.
* @param array The directory of the array whose schema will be retrieved.
* @param tiledb_array_schema The array schema to be retrieved.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_array_load_schema(
const TileDB_CTX* tiledb_ctx,
const char* array,
TileDB_ArraySchema* tiledb_array_schema);
/**
* Retrieves the schema of an already initialized array.
*
* @param tiledb_array The TileDB array object (must already be initialized).
* @param tiledb_array_schema The array schema to be retrieved.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_array_get_schema(
const TileDB_Array* tiledb_array,
TileDB_ArraySchema* tiledb_array_schema);/**
* Performs a write operation to an array.
* The array must be initialized in one of the following write modes,
* each of which has a different behaviour:
* - TILEDB_ARRAY_WRITE: \n
* In this mode, the cell values are provided in the buffers respecting
* the cell order on the disk (specified in the array schema). It is
* practically an **append** operation,
* where the provided cell values are simply written at the end of
* their corresponding attribute files. This mode leads to the best
* performance. The user may invoke this function an arbitrary number
* of times, and all the writes will occur in the same fragment.
* Moreover, the buffers need not be synchronized, i.e., some buffers
* may have more cells than others when the function is invoked.
* - TILEDB_ARRAY_WRITE_SORTED_COL: \n
* In this mode, the cell values are provided in the buffer in column-major
* order with respect to the subarray used upon array initialization.
* TileDB will properly re-organize the cells so that they follow the
* array cell order for storage on the disk.
* - TILEDB_ARRAY_WRITE_SORTED_ROW: \n
* In this mode, the cell values are provided in the buffer in row-major
* order with respect to the subarray used upon array initialization.
* TileDB will properly re-organize the cells so that they follow the
* array cell order for storage on the disk.
* - TILEDB_ARRAY_WRITE_UNSORTED: \n
* This mode is applicable to sparse arrays, or when writing sparse updates
* to a dense array. One of the buffers holds the coordinates. The cells
* in this mode are given in an arbitrary, unsorted order (i.e., without
* respecting how the cells must be stored on the disk according to the
* array schema definition). Each invocation of this function internally
* sorts the cells and writes them to the disk in the proper order. In
* addition, each invocation creates a **new** fragment. Finally, the
* buffers in each invocation must be synchronized, i.e., they must have
* the same number of cell values across all attributes.
*
* @param tiledb_array The TileDB array object (must be already initialized).
* @param buffers An array of buffers, one for each attribute. These must be
* provided in the same order as the attribute order specified in
* tiledb_array_init() or tiledb_array_reset_attributes(). The case of
* variable-sized attributes is special. Instead of providing a single
* buffer for such an attribute, **two** must be provided: the second
* holds the variable-sized cell values, whereas the first holds the
* start offsets of each cell in the second buffer.
* @param buffer_sizes The sizes (in bytes) of the input buffers (there should
* be a one-to-one correspondence).
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_array_write(
const TileDB_Array* tiledb_array,
const void** buffers,
const size_t* buffer_sizes);
/**
* Syncs all currently written files in the input array.
*
* @param tiledb_array The array to be synced.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_sync(
TileDB_Array* tiledb_array);
/**
* Syncs the currently written files associated with the input attribute
* in the input array.
*
* @param tiledb_array The array to be synced.
* @param attribute The name of the attribute to be synced.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_sync_attribute(
TileDB_Array* tiledb_array,
const char* attribute);
/**
* Consolidates the fragments of an array into a single fragment.
*
* @param tiledb_ctx The TileDB context.
* @param array The name of the TileDB array to be consolidated.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_consolidate(
const TileDB_CTX* tiledb_ctx,
const char* array);/**
* Performs a read operation on an array.
* The array must be initialized in one of the following read modes,
* each of which has a different behaviour:
* - TILEDB_ARRAY_READ: \n
* In this mode, the cell values are stored in the buffers respecting
* the cell order on the disk (specified in the array schema). This mode
* leads to the best performance.
* - TILEDB_ARRAY_READ_SORTED_COL: \n
* In this mode, the cell values are stored in the buffers in column-major
* order with respect to the subarray used upon array initialization.
* - TILEDB_ARRAY_READ_SORTED_ROW: \n
* In this mode, the cell values are stored in the buffer in row-major
* order with respect to the subarray used upon array initialization.
*
* @param tiledb_array The TileDB array.
* @param buffers An array of buffers, one for each attribute. These must be
* provided in the same order as the attributes specified in
* tiledb_array_init() or tiledb_array_reset_attributes(). The case of
* variable-sized attributes is special. Instead of providing a single
* buffer for such an attribute, **two** must be provided: the second
* will hold the variable-sized cell values, whereas the first holds the
* start offsets of each cell in the second buffer.
* @param buffer_sizes The sizes (in bytes) allocated by the user for the input
* buffers (there is a one-to-one correspondence). The function will attempt
* to write as many results as can fit in the buffers, and potentially
* alter the buffer size to indicate the size of the *useful* data written
* in the buffer. If a buffer cannot hold all results, the function will
* still succeed, writing as much data as it can and turning on an overflow
* flag which can be checked with function tiledb_array_overflow(). The
* next invocation will resume from the point the previous one stopped,
* without inflicting a considerable performance penalty due to overflow.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_array_read(
const TileDB_Array* tiledb_array,
void** buffers,
size_t* buffer_sizes);
/**
* Checks if a read operation for a particular attribute resulted in a
* buffer overflow.
*
* @param tiledb_array The TileDB array.
* @param attribute_id The id of the attribute for which the overflow is
* checked. This id corresponds to the position of the attribute name
* placed in the *attributes* input of tiledb_array_init(), or
* tiledb_array_reset_attributes() (the positions start from 0).
* If *attributes* was NULL in the
* above functions, then the attribute id corresponds to the order
* in which the attributes were defined in the array schema upon the
* array creation. Note that, in that case, the extra coordinates
* attribute corresponds to the last extra attribute, i.e., its id
* is *attribute_num*.
* @return TILEDB_ERR for error, 1 for overflow, and 0 otherwise.
*/
TILEDB_EXPORT int tiledb_array_overflow(
const TileDB_Array* tiledb_array,
int attribute_id);
/**
* Resets the attributes used upon initialization of the array.
*
* @param tiledb_array The TileDB array.
* @param attributes The new attributes to focus on. If it is NULL, then
* all the attributes are used (including the coordinates in the case of
* sparse arrays, or sparse writes to dense arrays).
* @param attribute_num The number of the attributes. If *attributes* is NULL,
* then this should be 0.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_reset_attributes(
const TileDB_Array* tiledb_array,
const char** attributes,
int attribute_num);
/**
* Resets the subarray used upon initialization of the array. This is useful
* when the array is used for reading, and the user wishes to change the
* query subarray without having to finalize and re-initialize the array.
*
* @param tiledb_array The TileDB array.
* @param subarray The new subarray. It should be a sequence of [low, high]
* pairs (one pair per dimension), whose type should be the same as that of
* the coordinates. If it is NULL, then the subarray is set to the entire
* array domain. For the case of writes, this is meaningful only for
* dense arrays, and specifically dense writes.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_reset_subarray(
const TileDB_Array* tiledb_array,
const void* subarray);/** A TileDB array iterator object. */
typedef struct TileDB_ArrayIterator TileDB_ArrayIterator;
/**
* Initializes an array iterator for reading cells, potentially constraining it
* on a subset of attributes, as well as a subarray. The cells will be read
* in the order they are stored on the disk, maximizing performance.
*
* @param tiledb_ctx The TileDB context.
* @param tiledb_array_it The TileDB array iterator to be created. The function
* will allocate the appropriate memory space for the iterator.
* @param array The directory of the array the iterator is initialized for.
* @param mode The read mode, which can be one of the following:
* - TILEDB_ARRAY_READ\n
* Reads the cells in the native order they are stored on the disk.
* - TILEDB_ARRAY_READ_SORTED_COL\n
* Reads the cells in column-major order within the specified subarray.
* - TILEDB_ARRAY_READ_SORTED_ROW\n
* Reads the cells in column-major order within the specified subarray.
* @param subarray The subarray in which the array iterator will be
* constrained on. It should be a sequence of [low, high] pairs (one
* pair per dimension), whose type should be the same as that of the
* coordinates. If it is NULL, then the subarray is set to the entire
* array domain.
* @param attributes A subset of the array attributes the iterator will be
* constrained on. Note that the coordinates have special attribute name
* TILEDB_COORDS. A NULL value indicates **all** attributes (including
* the coordinates as the last attribute in the case of sparse arrays).
* @param attribute_num The number of the input attributes. If *attributes* is
* NULL, then this should be set to 0.
* @param buffers This is an array of buffers similar to tiledb_array_read().
* It is the user that allocates and provides buffers that the iterator
* will use for internal buffering of the read cells. The iterator will
* read from the disk the relevant cells in batches, by fitting as many
* cell values as possible in the user buffers. This gives the user the
* flexibility to control the prefetching for optimizing performance
* depending on the application.
* @param buffer_sizes The corresponding size (in bytes) of the allocated
* memory space for *buffers*. The function will prefetch from the
* disk as many cells as can fit in the buffers, whenever it finishes
* iterating over the previously prefetched data.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_iterator_init(
const TileDB_CTX* tiledb_ctx,
TileDB_ArrayIterator** tiledb_array_it,
const char* array,
int mode,
const void* subarray,
const char** attributes,
int attribute_num,
void** buffers,
size_t* buffer_sizes);
/**
* Retrieves the current cell value for a particular attribute.
*
* @param tiledb_array_it The TileDB array iterator.
* @param attribute_id The id of the attribute for which the cell value
* is retrieved. This id corresponds to the position of the attribute name
* placed in the *attributes* input of tiledb_array_iterator_init()
* (the positions start from 0).
* If *attributes* was NULL in the above function, then the attribute id
* corresponds to the order in which the attributes were defined in the
* array schema upon the array creation. Note that, in that case, the extra
* coordinates attribute corresponds to the last extra attribute, i.e.,
* its id is *attribute_num*.
* @param value The cell value to be retrieved. Note that its type is the
* same as that defined in the array schema for the corresponding attribute.
* Note also that the function essentially returns a pointer to this value
* in the internal buffers of the iterator.
* @param value_size The size (in bytes) of the retrieved value. Useful mainly
* for the case of variable-sized cells.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_iterator_get_value(
TileDB_ArrayIterator* tiledb_array_it,
int attribute_id,
const void** value,
size_t* value_size);
/**
* Advances the iterator by one cell.
*
* @param tiledb_array_it The TileDB array iterator.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_iterator_next(
TileDB_ArrayIterator* tiledb_array_it);
/**
* Checks if the the iterator has reached its end.
*
* @param tiledb_array_it The TileDB array iterator.
* @return TILEDB_ERR for error, 1 for having reached the end, and 0 otherwise.
*/
TILEDB_EXPORT int tiledb_array_iterator_end(
TileDB_ArrayIterator* tiledb_array_it);
/**
* Finalizes an array iterator, properly freeing the allocating memory space.
*
* @param tiledb_array_it The TileDB array iterator to be finalized.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_array_iterator_finalize(
TileDB_ArrayIterator* tiledb_array_it);
/** Specifies the metadata schema. */
typedef struct TileDB_MetadataSchema {
/**
* The metadata name. It is a directory, whose parent must be a TileDB
* workspace, group, or array.
*/
char* metadata_name_;
/** The attribute names. */
char** attributes_;
/** The number of attributes. */
int attribute_num_;
/**
* The tile capacity. If it is <=0, TileDB will use its default.
*/
int64_t capacity_;
/**
* Specifies the number of values per attribute for a cell. If it is NULL,
* then each attribute has a single value per cell. If for some attribute
* the number of values is variable (e.g., in the case off strings), then
* TILEDB_VAR_NUM must be used.
*/
int* cell_val_num_;
/**
* The compression type for each attribute (plus one extra at the end for the
* key). It can be one of the following:
* - TILEDB_NO_COMPRESSION
* - TILEDB_GZIP
* - TILEDB_ZSTD
* - TILEDB_LZ4
* - TILEDB_BLOSC
* - TILEDB_BLOSC_LZ4
* - TILEDB_BLOSC_LZ4HC
* - TILEDB_BLOSC_SNAPPY
* - TILEDB_BLOSC_ZLIB
* - TILEDB_BLOSC_ZSTD
* - TILEDB_RLE
*
* If it is *NULL*, then the default TILEDB_NO_COMPRESSION is used for all
* attributes.
*/
int* compression_;
int* compression_level_;
/**
* The attribute types.
* The attribute type can be one of the following:
* - TILEDB_INT32
* - TILEDB_INT64
* - TILEDB_FLOAT32
* - TILEDB_FLOAT64
* - TILEDB_CHAR.
*/
int* types_;
} TileDB_MetadataSchema;
/**
* Populates a TileDB metadata schema object.
*
* @param tiledb_metadata_schema The metadata schema C API struct.
* @param metadata_name The metadata name.
* @param attributes The attribute names.
* @param attribute_num The number of attributes.
* @param capacity The tile capacity.
* @param cell_val_num The number of values per attribute per cell.
* @param compression The compression type for each attribute (plus an extra one
* in the end for the key).
* @param types The attribute types.
* @return TILEDB_OK for success and TILEDB_ERR for error.
* @see TileDB_MetadataSchema
*/
TILEDB_EXPORT int tiledb_metadata_set_schema(
TileDB_MetadataSchema* tiledb_metadata_schema,
const char* metadata_name,
const char** attributes,
int attribute_num,
int64_t capacity,
const int* cell_val_num,
const int* compression,
const int* compression_level,
const int* types);
/**
* Creates a new TileDB metadata object.
*
* @param tiledb_ctx The TileDB context.
* @param metadata_schema The metadata schema.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_metadata_create(
const TileDB_CTX* tiledb_ctx,
const TileDB_MetadataSchema* metadata_schema);
/** A TileDB metadata object. */
typedef struct TileDB_Metadata TileDB_Metadata;
/**
* Initializes a TileDB metadata object.
*
* @param tiledb_ctx The TileDB context.
* @param tiledb_metadata The metadata object to be initialized. The function
* will allocate memory space for it.
* @param metadata The directory of the metadata to be initialized.
* @param mode The mode of the metadata. It must be one of the following:
* - TILEDB_METADATA_WRITE
* - TILEDB_METADATA_READ
* @param attributes A subset of the metadata attributes the read/write will be
* constrained on. Note that the keys have a special attribute name
* called TILEDB_KEYS. A NULL value indicates **all** attributes (including
* the keys as an extra attribute in the end).
* @param attribute_num The number of the input attributes. If *attributes* is
* NULL, then this should be set to 0.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_init(
const TileDB_CTX* tiledb_ctx,
TileDB_Metadata** tiledb_metadata,
const char* metadata,
int mode,
const char** attributes,
int attribute_num);
/**
* Finalizes a TileDB metadata object, properly freeing the memory space.
*
* @param tiledb_metadata The metadata to be finalized.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_finalize(
TileDB_Metadata* tiledb_metadata);
/**
* Retrieves the schema of a metadata object from disk.
*
* @param tiledb_ctx The TileDB context.
* @param metadata The directory of the metadata whose schema will be retrieved.
* @param tiledb_metadata_schema The metadata schema to be retrieved.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_metadata_load_schema(
const TileDB_CTX* tiledb_ctx,
const char* metadata,
TileDB_MetadataSchema* tiledb_metadata_schema);
/**
* Frees the input metadata schema struct, properly deallocating memory space.
*
* @param tiledb_metadata_schema The metadata schema to be freed.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_metadata_free_schema(
TileDB_MetadataSchema* tiledb_metadata_schema);
/**
* Retrieves the schema of an already initialized metadata object.
*
* @param tiledb_metadata The TileDB metadata object (must already be
* initialized).
* @param tiledb_metadata_schema The metadata schema to be retrieved.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_metadata_get_schema(
const TileDB_Metadata* tiledb_metadata,
TileDB_MetadataSchema* tiledb_metadata_schema);/**
* Performs a write operation to a metadata object. The metadata must be
* initialized with mode TILEDB_METADATA_WRITE. This function behave very
* similarly to tiledb_array_write() when the array is initialized with mode
* TILEDB_ARRAY_WRITE_UNSORTED.
*
* @param tiledb_metadata The TileDB metadata (must be already initialized).
* @param keys The buffer holding the metadata keys. These keys must be
* strings, serialized one after the other in the *keys* buffer.
* @param keys_size The size (in bytes) of buffer *keys*.
* @param buffers An array of buffers, one for each attribute. These must be
* provided in the same order as the attributes specified in
* tiledb_metadata_init() or tiledb_metadata_reset_attributes(). The case of
* variable-sized attributes is special. Instead of providing a single
* buffer for such an attribute, **two** must be provided: the second
* holds the variable-sized values, whereas the first holds the
* start offsets of each value in the second buffer.
* @param buffer_sizes The sizes (in bytes) of the input buffers (there is
* a one-to-one correspondence).
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_metadata_write(
const TileDB_Metadata* tiledb_metadata,
const char* keys,
size_t keys_size,
const void** buffers,
const size_t* buffer_sizes);
/**
* Consolidates the fragments of a metadata object into a single fragment.
*
* @param tiledb_ctx The TileDB context.
* @param metadata The name of the TileDB metadata to be consolidated.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_consolidate(
const TileDB_CTX* tiledb_ctx,
const char* metadata);/**
* Performs a read operation on a metadata object, which must be initialized
* with mode TILEDB_METADATA_READ. The read is performed on a single key.
*
* @param tiledb_metadata The TileDB metadata.
* @param key The query key, which must be a string.
* @param buffers An array of buffers, one for each attribute. These must be
* provided in the same order as the attributes specified in
* tiledb_metadata_init() or tiledb_metadata_reset_attributes(). The case of
* variable-sized attributes is special. Instead of providing a single
* buffer for such an attribute, **two** must be provided: the second
* will hold the variable-sized values, whereas the first holds the
* start offsets of each value in the second buffer.
* @param buffer_sizes The sizes (in bytes) allocated by the user for the input
* buffers (there should be a one-to-one correspondence). The function will
* attempt to write the value corresponding to the key, and potentially
* alter the respective size in *buffer_sizes* to indicate the *useful*
* data written. If a buffer cannot
* hold the result, the function will still succeed, turning on an overflow
* flag which can be checked with function tiledb_metadata_overflow().
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_metadata_read(
const TileDB_Metadata* tiledb_metadata,
const char* key,
void** buffers,
size_t* buffer_sizes);
/**
* Checks if a read operation for a particular attribute resulted in a
* buffer overflow.
*
* @param tiledb_metadata The TileDB metadata.
* @param attribute_id The id of the attribute for which the overflow is
* checked. This id corresponds to the position of the attribute name
* placed in the *attributes* input of tiledb_metadata_init(), or
* tiledb_metadata_reset_attributes(). The positions start from 0.
* If *attributes* was NULL in the
* above functions, then the attribute id corresponds to the order
* in which the attributes were defined in the metadata schema upon the
* metadata creation.
* @return TILEDB_ERR for error, 1 for overflow, and 0 otherwise.
*/
TILEDB_EXPORT int tiledb_metadata_overflow(
const TileDB_Metadata* tiledb_metadata,
int attribute_id);
/**
* Resets the attributes used upon initialization of the metadata.
*
* @param tiledb_metadata The TileDB metadata.
* @param attributes The new attributes to focus on. If it is NULL, then
* all the attributes are used.
* @param attribute_num The number of the attributes. If *attributes* is NULL,
* then this should be 0.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_reset_attributes(
const TileDB_Metadata* tiledb_metadata,
const char** attributes,
int attribute_num);/** A TileDB metadata iterator. */
typedef struct TileDB_MetadataIterator TileDB_MetadataIterator;
/**
* Initializes a metadata iterator, potentially constraining it
* on a subset of attributes. The values will be read in the order they are
* stored on the disk (which is random), maximizing performance.
*
* @param tiledb_ctx The TileDB context.
* @param tiledb_metadata_it The TileDB metadata iterator to be created. The
* function will allocate the appropriate memory space for the iterator.
* @param metadata The directory of the metadata the iterator is initialized
* for.
* @param attributes A subset of the metadata attributes the iterator will be
* constrained on. Note that the keys have a special value called
* TILEDB_KEYS. A NULL value indicates **all** attributes.
* @param attribute_num The number of the input attributes. If *attributes* is
* NULL, then this should be set to 0.
* @param buffers This is an array of buffers similar to tiledb_metadata_read().
* It is the user that allocates and provides buffers that the iterator
* will use for internal buffering of the read values. The iterator will
* read from the disk the values in batches, by fitting as many
* values as possible in the user buffers. This gives the user the
* flexibility to control the prefetching for optimizing performance
* depending on the application.
* @param buffer_sizes The corresponding sizes (in bytes) of the allocated
* memory space for *buffers*. The function will prefetch from the
* disk as many values as can fit in the buffers, whenever it finishes
* iterating over the previously prefetched data.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_iterator_init(
const TileDB_CTX* tiledb_ctx,
TileDB_MetadataIterator** tiledb_metadata_it,
const char* metadata,
const char** attributes,
int attribute_num,
void** buffers,
size_t* buffer_sizes);
/**
* Retrieves the current value for a particular attribute.
*
* @param tiledb_metadata_it The TileDB metadata iterator.
* @param attribute_id The id of the attribute for which the overflow is
* checked. This id corresponds to the position of the attribute name
* placed in the *attributes* input of tiledb_metadata_init(), or
* tiledb_metadata_reset_attributes(). The positions start from 0.
* If *attributes* was NULL in the
* above functions, then the attribute id corresponds to the order
* in which the attributes were defined in the metadata schema upon the
* metadata creation.
* @param value The value to be retrieved. Note that its type is the
* same as that defined in the metadata schema. Note also that the function
* returns a pointer to this value in the internal buffers of the iterator.
* @param value_size The size (in bytes) of the retrieved value.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_iterator_get_value(
TileDB_MetadataIterator* tiledb_metadata_it,
int attribute_id,
const void** value,
size_t* value_size);
/**
* Advances the iterator by one position.
*
* @param tiledb_metadata_it The TileDB metadata iterator.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_iterator_next(
TileDB_MetadataIterator* tiledb_metadata_it);
/**
* Checks if the the iterator has reached its end.
*
* @param tiledb_metadata_it The TileDB metadata iterator.
* @return TILEDB_ERR for error, 1 for having reached the end, and 0 otherwise.
*/
TILEDB_EXPORT int tiledb_metadata_iterator_end(
TileDB_MetadataIterator* tiledb_metadata_it);
/**
* Finalizes the iterator, properly freeing the allocating memory space.
*
* @param tiledb_metadata_it The TileDB metadata iterator.
* @return TILEDB_OK on success, and TILEDB_ERR on error.
*/
TILEDB_EXPORT int tiledb_metadata_iterator_finalize(
TileDB_MetadataIterator* tiledb_metadata_it);
/**
* Clears a TileDB directory. The corresponding TileDB object (workspace,
* group, array, or metadata) will still exist after the execution of the
* function, but it will be empty (i.e., as if it was just created).
*
* @param tiledb_ctx The TileDB context.
* @param dir The TileDB directory to be cleared.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_clear(
const TileDB_CTX* tiledb_ctx,
const char* dir);
/**
* Deletes a TileDB directory (workspace, group, array, or metadata) entirely.
*
* @param tiledb_ctx The TileDB context.
* @param dir The TileDB directory to be deleted.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_delete(
const TileDB_CTX* tiledb_ctx,
const char* dir);
/**
* Moves a TileDB directory (workspace, group, array or metadata).
*
* @param tiledb_ctx The TileDB context.
* @param old_dir The old TileDB directory.
* @param new_dir The new TileDB directory.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_move(
const TileDB_CTX* tiledb_ctx,
const char* old_dir,
const char* new_dir);
/**
* Lists all TileDB workspaces, copying their directory names in the input
* string buffers.
*
* @param tiledb_ctx The TileDB context.
* @param workspaces An array of strings that will store the listed workspaces.
* Note that this should be pre-allocated by the user. If the size of
* each string is smaller than the corresponding workspace path name, the
* function will probably segfault. It is a good idea to allocate to each
* workspace string TILEDB_NAME_MAX_LEN characters.
* @param workspace_num The number of allocated elements of the *workspaces*
* string array. After the function execution, this will hold the actual
* number of workspaces written in the *workspaces* string array. If the
* number of allocated elements is smaller than the number of existing
* TileDB workspaces, the function will return an error.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_ls_workspaces(
const TileDB_CTX* tiledb_ctx,
const char* parent_dir,
char** workspaces,
int* workspace_num);
/**
* Counts the number of TileDB workspaces.
*
* @param tiledb_ctx The TileDB context.
* @param workspace_num The number of TileDB workspaces to be returned.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_ls_workspaces_c(
const TileDB_CTX* tiledb_ctx,
const char* parent_dir,
int* workspace_num);
/**
* Lists all the TileDB objects in a directory, copying their names into the
* input string buffers.
*
* @param tiledb_ctx The TileDB context.
* @param parent_dir The parent directory of the TileDB objects to be listed.
* @param dirs An array of strings that will store the listed TileDB objects.
* Note that the user is responsible for allocating the appropriate memory
* space for this array of strings. A good idea is to allocate for each
* string TILEDB_NAME_MAX_LEN characters.
* @param dir_types The types of the corresponding TileDB objects in *dirs*,
* which can be the following:
* - TILEDB_WORKSPACE
* - TILEDB_GROUP
* - TILEDB_ARRAY
* - TILEDB_METADATA
* @param dir_num The number of elements allocated by the user for *dirs*. After
* the function terminates, this will hold the actual number of TileDB
* objects that were stored in *dirs*. If the number of
* allocated elements is smaller than the number of existing TileDB objects
* in the parent directory, the function will return an error.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_ls(
const TileDB_CTX* tiledb_ctx,
const char* parent_dir,
char** dirs,
int* dir_types,
int* dir_num);
/**
* Counts the TileDB objects in a directory.
*
* @param tiledb_ctx The TileDB context.
* @param parent_dir The parent directory of the TileDB objects to be listed.
* @param dir_num The number of TileDB objects to be returned.
* @return TILEDB_OK for success and TILEDB_ERR for error.
*/
TILEDB_EXPORT int tiledb_ls_c(
const TileDB_CTX* tiledb_ctx,
const char* parent_dir,
int* dir_num);
/** Describes an AIO (read or write) request. */
typedef struct TileDB_AIO_Request {
/**
* An array of buffers, one for each attribute. These must be
* provided in the same order as the attributes specified in
* tiledb_array_init() or tiledb_array_reset_attributes(). The case of
* variable-sized attributes is special. Instead of providing a single
* buffer for such an attribute, **two** must be provided: the second
* holds the variable-sized cell values, whereas the first holds the
* start offsets of each cell in the second buffer.
*/
void** buffers_;
/**
* The sizes (in bytes) allocated by the user for the
* buffers (there is a one-to-one correspondence). In the case of reads,
* the function will attempt
* to write as many results as can fit in the buffers, and potentially
* alter the buffer sizes to indicate the size of the *useful* data written
* in the corresponding buffers.
*/
size_t* buffer_sizes_;
/** Function to be called upon completion of the request. */
void *(*completion_handle_) (void*);
/** Data to be passed to the completion handle. */
void* completion_data_;
/**
* Applicable only to read requests.
* Indicates whether a buffer has overflowed during a read request.
* If it is NULL, it will be ignored. Otherwise, it must be an array
* with as many elements as the number of attributes specified in
* tiledb_array_init() or tiledb_array_reset_attributes().
*/
bool* overflow_;
/**
* The status of the AIO request. It can be one of the following:
* - TILEDB_AIO_COMPLETED
* The request is completed.
* - TILEDB_AIO_INPROGRESS
* The request is still in progress.
* - TILEDB_AIO_OVERFLOW
* At least one of the input buffers overflowed (applicable only to AIO
* read requests)
* - TILEDB_AIO_ERR
* The request caused an error (and thus was canceled).
*/
int status_;
/**
* The subarray in which the array read/write will be
* constrained on. It should be a sequence of [low, high] pairs (one
* pair per dimension), whose type should be the same as that of the
* coordinates. If it is NULL, then the subarray is set to the entire
* array domain. For the case of writes, this is meaningful only for
* dense arrays, and specifically dense writes.
*/
const void* subarray_;
} TileDB_AIO_Request;
/**
* Issues an asynchronous read request.
*
* @param tiledb_array An initialized TileDB array.
* @param tiledb_aio_request An asynchronous read request.
* @return TILEDB_OK upon success, and TILEDB_ERR upon error.
*
* @note If the same input request is in progress, the function will fail.
* Moreover, if the input request was issued in the past and caused an
* overflow, the new call will resume it IF there was no other request
* in between the two separate calls for the same input request.
* In other words, a new request that is different than the previous
* one resets the internal read state.
*/
TILEDB_EXPORT int tiledb_array_aio_read(
const TileDB_Array* tiledb_array,
TileDB_AIO_Request* tiledb_aio_request);
/**
* Issues an asynchronous write request.
*
* @param tiledb_array An initialized TileDB array.
* @param tiledb_aio_request An asynchronous write request.
* @return TILEDB_OK upon success, and TILEDB_ERR upon error.
*/
TILEDB_EXPORT int tiledb_array_aio_write(
const TileDB_Array* tiledb_array,
TileDB_AIO_Request* tiledb_aio_request);
Below we provide a wide set of examples for using the TileDB C API. The examples assume that your current working directory contains all the example binaries. Moreover, each example is stand-alone, i.e., it does not assume that any other example was run before it.
- Example #1: Creating Workspaces and Groups
- Example #2: Creating a Dense Array
- Example #3: Creating a Sparse Array
- Example #4: Primitive Array Operations
- Example #5: Writing to a Dense Array (1/2)
- Example #6: Writing to a Dense Array (2/2)
- Example #7: Writing to a Dense Array in Sorted Mode
- Example #8: Writing to a Sparse Array (1/4)
- Example #9: Writing to a Sparse Array (2/4)
- Example #10: Writing to a Sparse Array (3/4)
- Example #11: Writing to a Sparse Array (4/4)
- Example #12: Updating a Dense Array (1/2)
- Example #13: Updating a Dense Array (2/2)
- Example #14: Updating a Sparse Array (1/2)
- Example #15: Updating a Sparse Array (2/2)
- Example #16: Writing to a Dense Array in Parallel (1/2)
- Example #17: Writing to a Dense Array in Parallel (2/2)
- Example #18: Writing to a Sparse Array in Parallel (1/2)
- Example #19: Writing to a Sparse Array in Parallel (2/2)
- Example #20: Consolidating Arrays
- Example #21: Reading from a Dense Array (1/3)
- Example #22: Reading from a Dense Array (2/3)
- Example #23: Reading from a Dense Array (3/3)
- Example #24: Reading from a Dense Array in Sorted Mode
- Example #25: Reading from a Dense Array With Empty Cells
- Example #26: Reading from a Sparse Array (1/2)
- Example #27: Reading from a Sparse Array (2/2)
- Example #28: Reading from a Sparse Array in Sorted Mode
- Example #29: Using a Dense Array Iterator
- Example #30: Using a Sparse Array Iterator
- Example #31: Reading from a Dense Array in Parallel (1/2)
- Example #32: Reading from a Dense Array in Parallel (2/2)
- Example #33: Reading from a Sparse Array in Parallel (1/2)
- Example #34: Reading from a Sparse Array in Parallel (2/2)
- Example #35: Consolidating a Dense Array in Parallel
- Example #36: Consolidating a Sparse Array in Parallel
- Example #37: Creating Metadata
- Example #38: Primitive Metadata Operations
- Example #39: Writing Metadata
- Example #40: Updating Metadata
- Example #41: Consolidating Metadata
- Example #42: Reading Metadata
- Example #43: Using a Metadata Iterator
- Example #44: Clearing, Deleting and Moving TileDB objects
- Example #45: Listing the TileDB Workspaces
- Example #46: Listing the TileDB Objects in a Directory
- Example #47: Changing the TileDB Configuration
- Example #48: Reading an Array in Parallel with MPI and MPI-IO
- Example #49: Writing to an Array Asynchronously
- Example #50: Reading from an Array Asynchronously
- Example #51: Catching Errors
tiledb_workspace_group_create.cc
This shows how to create a workspace called my_workspace inside the current working directory, and two groups inside it, called dense_arrays and sparse_arrays.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory.
Program execution:
(directories are depicted in blue, and files in green)

This example shows how to create a dense array called my_array_A inside group my_workspace/dense_arrays. The array has similar schema to the dense array used in the examples of TileDB Mechanics 101. Specifically, it assumes the tile and cell orders depicted in Figure 6. Moreover, it has an extra attribute a3, which is used to demonstrate how TileDB handles fixed-sized attributes admitting multiple values per cell (2 in this example for a3).
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace and group:

Program execution:
(directories are depicted in blue, and files in green)

This example shows how to create a sparse array called my_array_B inside group my_workspace/sparse_arrays. The array has similar schema to the sparse array used in the examples of TileDB Mechanics 101. Specifically, it assumes the tile and cell orders depicted in Figure 7. Moreover, it has an extra attribute a3, which is used to demonstrate how TileDB handles fixed-sized attributes admitting multiple values per cell (2 in this example for a3).
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace and group:
Program execution:
(directories are depicted in blue, and files in green)

This example demonstrates how to initialize/finalize an array. Moreover, it shows the two ways with which one can get the schema of an array, depending on whether the array is initialized or not.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and arrays:

Program execution:

This example demonstrates how to write to a dense array.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:

Program execution:

This example demonstrates how to write to a dense array, invoking the write function multiple times. This will have the same effect as Example #5. The only difference is that most likely a different thread will create the array fragment, and at a new timestamp. Therefore, the created fragment directory will have a different name this time.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:
Program execution:

tiledb_array_write_dense_sorted.cc
This example demonstrates how to write to a subarray of a dense array, providing the cell values sorted in row-major order withing the specified subarray. This will have the same effect as Example #11.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:
Program execution:

tiledb_array_write_sparse_1.cc
This example demonstrates how to write to a sparse array.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:

Program execution:
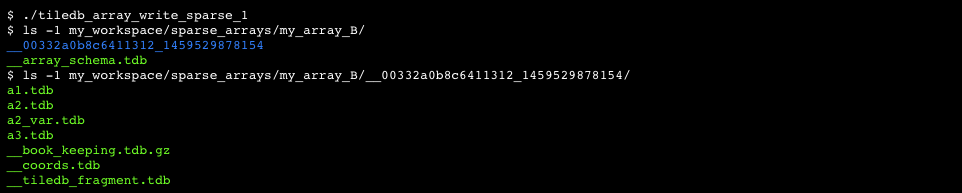
tiledb_array_write_sparse_2.cc
This example demonstrates how to write to a sparse array with two sorted batch writes. This will have the same effect as Example #8. The only difference is that most likely a different thread will create the array fragment, and at a new timestamp. Therefore, the created fragment directory will have a different name this time.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:
Program execution:
tiledb_array_write_sparse_3.cc
This example demonstrates how to write unsorted cells to a sparse array. This will have the same effect as Example #8. The only difference is that most likely a different thread will create the array fragment, and at a new timestamp. Therefore, the created fragment directory will have a different name this time.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:
Program execution:
tiledb_array_write_sparse_4.cc
This example demonstrates how to write unsorted cells to a sparse array with two batch writes. This will not have the same effect as Example #8, since there are two separate fragments created. However, the logical view of this array remains the same.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:
Program execution:
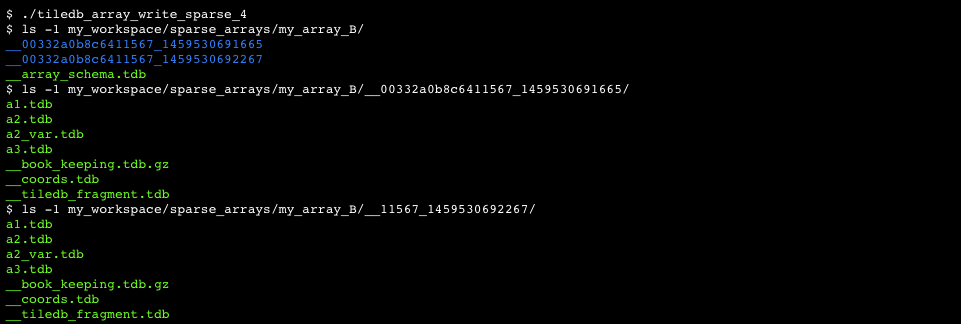
tiledb_array_update_dense_1.cc
This example demonstrates how to update a dense array, writing into a subarray of the entire array domain. Observe that updates are carried out as simple writes.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, as well as populate the array with the initial data:

Program execution:
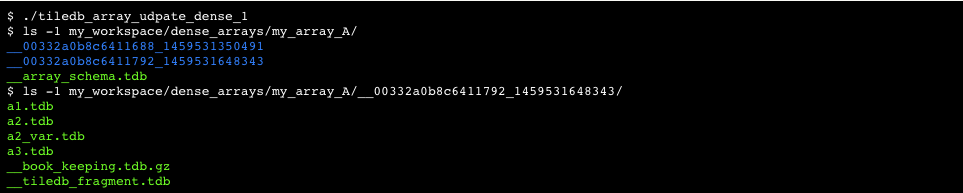
<a name="example_13>
tiledb_array_update_dense_2.cc
This example demonstrates how to update a dense array, writing random sparse updates. Observe that the created fragment is sparse, i.e., it contains a coordinates file.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, as well as populate the array with the initial data:
Program execution:

tiledb_array_update_sparse_1.cc
This example demonstrates how to update a sparse array. Observe that updates are carried out as simple writes.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, as well as populate the array with the initial data:
Program execution:
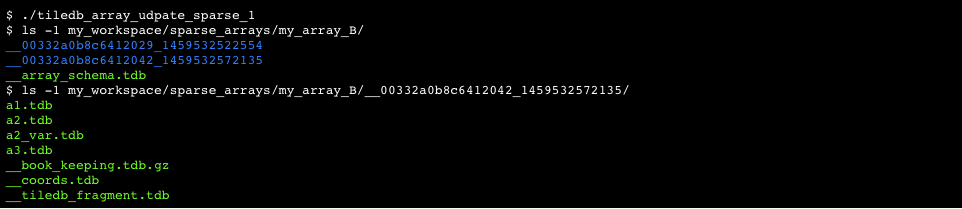
tiledb_array_update_sparse_2.cc
This example demonstrates how to update a sparse array, including how to handle deletions. Observe that updates (even deletions) are carried out as simple writes.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, as well as populate the array with the initial data:
Program execution:
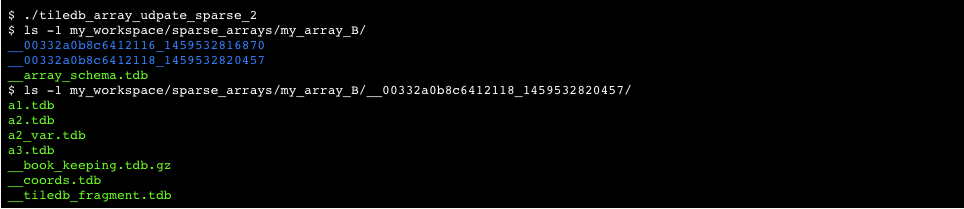
tiledb_array_parallel_write_dense_1.cc
This example demonstrates how to write to a dense array in parallel with pthreads. It spawns four threads, each of which creates a separate fragment. Observe that the fragments are created at the same time instant (second number in the fragment names), but each fragment name carries a different thread id (first number in the fragment names). The logical view of this array is the same as that of Example #5.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:

Program execution:

tiledb_array_parallel_write_dense_2.cc
This example is equivalent to that of Example #16. The only difference is that it utilizes OpenMP instead of pthreads.
Preparation:
Make sure to compile TileDB with flag OPENMP=1. Also make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:
Program execution:
tiledb_array_parallel_write_sparse_1.cc
This example demonstrates how to write to a sparse array in parallel with pthreads. It spawns two threads, each of which creates a separate fragment. Observe that the fragments are created at the same time instant (second number in the fragment names), but each fragment name carries a different thread id (first number in the fragment names). The logical view of this array is the same as that of Example #8.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:
Program execution:

tiledb_array_parallel_write_sparse_2.cc
This example is equivalent to that of Example #18. The only difference is that it utilizes OpenMP instead of pthreads.
Preparation:
Make sure to compile TileDB with flag OPENMP=1. Also make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:
Program execution:

This example demonstrates how to consolidate arrays. After array consolidation, there will exist a single fragment in the array. Observe also that, for the dense array, its single fragment is always dense (there is no coordinates file).
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups/arrays, populate the arrays with the initial data, and perform some updates:
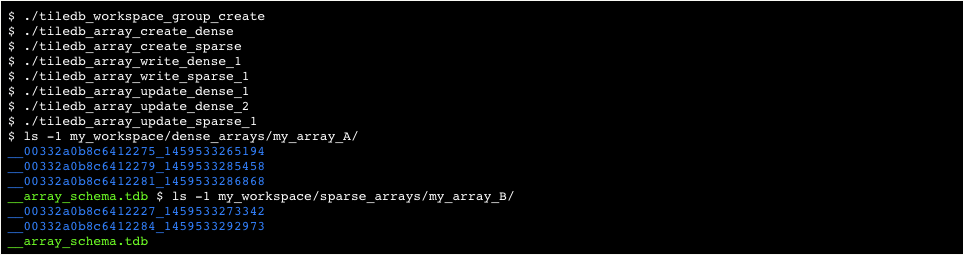
Program execution:
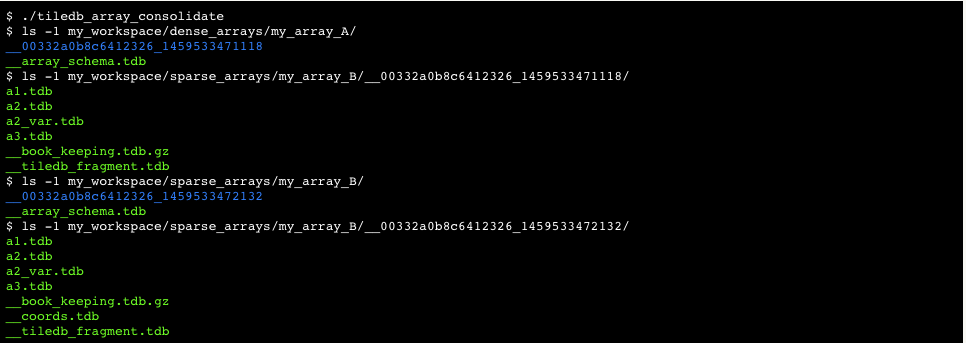
This example demonstrates how to read a complete dense array. Observe that the contents of the array (printed in the global cell order) are the same as those depicted in the collective logical view of Figure 14 in the TileDB Mechanics 101.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, populate the array with the initial data, and perform some updates:

Program execution:

This example demonstrates how to read a subarray from a dense array. Moreover it shows how to subset over the attributes, and how to handle overflow. Observe that the result is the same as that depicted in Figure 17 in the TileDB Mechanics 101.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, populate the array with the initial data, and perform some updates:

Program execution:

This example demonstrates how to read from a dense array, resetting the selected attributes and subarray.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, populate the array with the initial data, and perform some updates:

Program execution:

tiledb_array_read_dense_sorted.cc
This example demonstrates how to read a subarray from a dense array, retrieving the cells in row-major order within the specified subarray. This example is essentially identical to Example #22 with the difference that the order of the returned cells now changes. Observe that the result is the same as that depicted in Figure 18 in the TileDB Mechanics 101.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, populate the array with the initial data, and perform some updates:

Program execution:

This example demonstrates how to read a subarray from a dense array that contains empty cells. This example is identical to Example #22, with the difference that we only write a single tile (the lower right one) in the array. Therefore, now the subarray overlaps also with empty cells.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, populate the array with the initial data, and perform some updates:

Program execution:

This example demonstrates how to read a complete sparse array. Observe that the contents of the array (printed in the global cell order) are the same as those depicted in the collective logical view of Figure 15 in the TileDB Mechanics 101.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, populate the array with the initial data, and perform some updates:

Program execution:

This example demonstrates how to read from a sparse array, constraining the read to a specific subarray and subset of attributes. Moreover, it shows how to handle deletions and detect buffer overflow. Observe that the result of the first execution (printed in the global cell order) is the same as that depicted in Figure 19 in the TileDB Mechanics 101.
Preparation #1:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, populate the array with the initial data, and perform some updates:

Program execution #1:

Preparation #2:
Now delete my_workspace in your current working directory and ~/.tiledb, and run the following to create the workspace/groups and sparse array, populate the array with the initial data, and perform some updates that include deletions:

Program execution #2:
(Observe that the a1 value of deleted cell (3,3) is not printed now)

tiledb_array_read_sparse_sorted.cc
This example demonstrates how to read from a sparse array, constraining the read to a specific subarray and subset of attributes and returning the cells in row-major order within the specified subarray. This example is identical to the first part of Example #27, but now the order of the results changes. Observe that the result is the same as that depicted in Figure 20 in the TileDB Mechanics 101.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, populate the array with the initial data, and perform some updates:

Program execution:

tiledb_array_iterator_dense.cc
This example demonstrates how to use an iterator for a dense array. Observe that the result is the same as that of Example 22.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array, populate the array with the initial data, and perform some updates:

Program execution:

tiledb_array_iterator_sparse.cc
This example demonstrates how to use an iterator for a sparse array. Observe that the result is the same as that of the second program execution in Example 27.
Preparation #1:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, populate the array with the initial data, and perform some updates:

Program execution:

tiledb_array_parallel_read_dense_1.cc
This example demonstrates how to read from a dense array in parallel with pthreads. It spawns four threads, each of which reads a separate part of the array. The program outputs the number of values on attribute a1 that are larger than 10.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:

Program execution:

tiledb_array_parallel_read_dense_2.cc
This example is equivalent to that of Example #31. The only difference is that it utilizes OpenMP instead of pthreads.
Preparation:
Make sure to compile TileDB with flag OPENMP=1. Also make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:

Program execution:

tiledb_array_parallel_read_sparse_1.cc
This example demonstrates how to read from a sparse array in parallel with pthreads. It spawns two threads, each of which reads a separate part of the array. The program outputs the number of values on attribute a1 that are larger than 5.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:

Program execution:

tiledb_array_parallel_read_sparse_2.cc
This example is equivalent to that of Example #33. The only difference is that it utilizes OpenMP instead of pthreads.
Preparation:
Make sure to compile TileDB with flag OPENMP=1. Also make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:

Program execution:

tiledb_array_parallel_consolidate_dense.cc
This example demonstrates how to consolidate a dense array, while performing 4 concurrent reads. This program uses pthreads, but it is straightforward to modify it to use OpenMP instead.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and dense array:

Program execution:

tiledb_array_parallel_consolidate_sparse.cc
This example demonstrates how to consolidate a sparse array, while performing 2 concurrent reads. This program uses pthreads, but it is straightforward to modify it to use OpenMP instead.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array:

Program execution:

This example shows how to create metadata associated with sparse array my_workspace/sparse_arrays/my_array_B.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups and sparse array, as well as populate the sparse array (optional):

Program execution:
(directories are depicted in blue, and files in green)

This example shows how to initialize/finalize a metadata object. Moreover, it shows the two ways one can get the schema of a metadata object, depending on whether the metadata object is initialized or not.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups, sparse array, and metadata.

Program execution:

This example shows how to write metadata. This creates the metadata shown in Figure 23 in the TileDB Mechanics 101.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups, sparse array, and metadata.

Program execution:
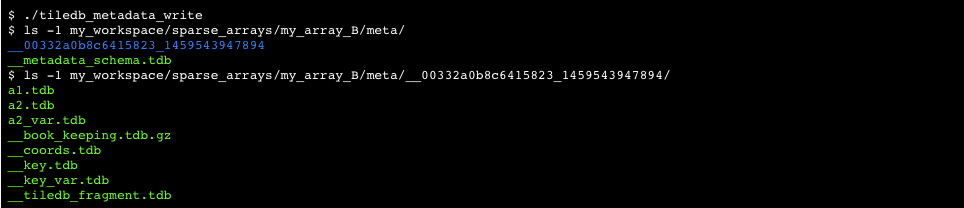
This example shows how to modify or delete a metadata item.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups, sparse array, and metadata, as well as populate the metadata with some initial data.

Program execution:
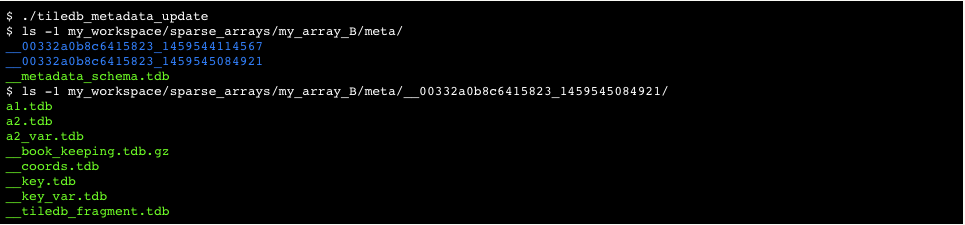
tiledb_metadata_consolidate.cc
This example shows how to consolidate metadata.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups, sparse array, and metadata, as well as populate the metadata with some initial data and perform some updates.

Program execution:

This example shows how to read metadata, demonstrating how to detect buffer overflow. Observe also that after the metadata update, the metadata item with key k2 is deleted.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups, sparse array, and metadata, as well as populate the metadata with some initial data.

Program execution:
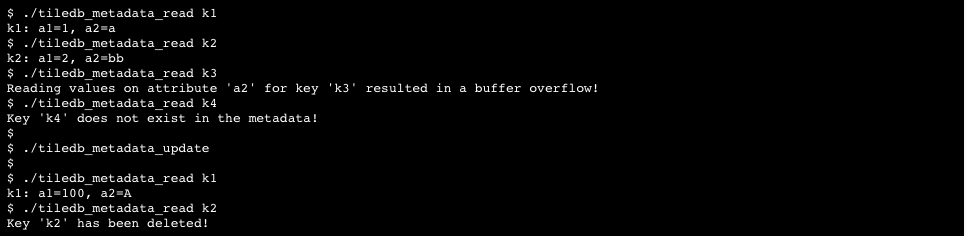
This example shows how to use a metadata iterator. Observe in the results of the program execution that the metadata items are stored in a random order (determined by an MD5 hash on the key).
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups, sparse array, and metadata, as well as populate the metadata with some initial data.

Program execution:

This example shows how to clear, delete and move TileDB objects. Specifically, it clears array my_workspace/sparse_arrays/my_array_B, deletes group my_workspace/dense_arrays/ and renames workspace my_workspace to my_workspace_2.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups/arrays/metadata, as well as populate the arrays and metadata with some initial data.

Program execution:

This example shows how to list the TileDB workspaces.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace and groups.

$ ./tiledb_workspace_group_create

This example shows how to explore the contents of a TileDB directory.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to create the workspace/groups/arrays/metadata.

Program execution:

Obsolete currently!!!
This example shows how to change the TileDB configuration parameters.
Preparation:
Program execution:
tiledb_array_parallel_read_mpi_io_dense.cc
This example shows how to read an array in parallel with MPI, activating also the MPI-IO read mode. The program focuses on a dense array, but the case of sparse arrays is very similar. Moreover, the MPI-IO read mode is optional - the user can alternative use mmap or standard OS read (i.e., MPI-IO is not obligatory when using MPI for parallelism). The example spawns 4 processes, each reading a separate tile and reporting the number of a1 values that are greater than 10.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to prepare a dense array.

Program execution:

tiledb_array_aio_write_dense.cc
This example shows how to write to an array asynchronously. The effect of this example is the same as Example #5. The difference is that the write command returns immediately control to the main function, and performs the write operation in the background. As soon as the write completes, it sets a flag and invokes a user defined function. Note that this example focuses on a dense array, but the case of sparse arrays is similar.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to prepare a dense array.

Program execution:

tiledb_array_aio_read_dense.cc
This example shows how to read a subarray of an array asynchronously. Observe that the read command returns immediately control to the main function, and performs the read operation in the background. As soon as the read completes, it sets a flag and invokes a user defined function. Note that this example focuses on a dense array, but the case of sparse arrays is similar.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory. Moreover, run the following to prepare a dense array.

Program execution:
Note that the message "AIO request completed" may be interleaved with the subarray print out. This is because this message is printed by another thread working in parallel in the background.

This shows how to catch TileDB errors. The program initially creates a workspace successfully. Then it attempts to create the same workspace, and TileDB returns an error. The code shows how to catch and print this error to standard output.
Preparation:
Make sure that there is no directory called my_workspace in your current working directory.
Program execution:
