This CRF toolkit is a fork of the CRFsuite: a fast implementation of Conditional Random Fields (CRFs) by enabling it to support partially annotated input training data.
For sequence labeling problems, we may access to a type of data: the labels for certain subsequence are known or constrainted to a smaller set, while the labels for the other part of the sequence is unknown. Figure 1 illustrate an example for such type of data.
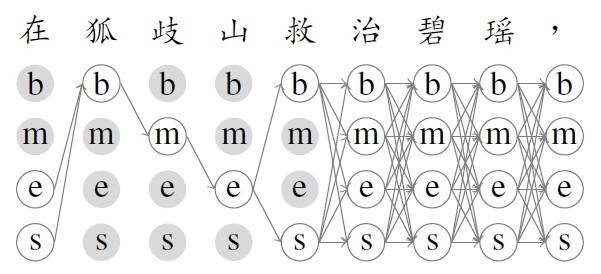
Figure 1
In character-based Chinese word segmentation (which is similar to the named entities recognition that label token with B, M, E, and S), if we know the subsequence of characters makes a word, their labels and labels on the boundary can be constrainted to a smaller set.
In the above example, the word 狐岐山(the Huqi Mountain) in the unannotated sentence is recognized as a word.
As a result, we obtain a partially-annotated sentence, in which the segmentation ambiguity of the characters 狐(fox), 岐(brandy road) and 山(mountain) are resolved (狐 being the beginning, 岐 being the middle and 山 being the end of the same word).
At the same time, the segmentation ambiguity of the surrounding characters 在(at) and 救(save) are reduced (在 being either a single-character word or the end of a multi-character word, and 救 being either a single-character word or the beginning of a multicharacter word).
For more details, please refer to the our emnlp 2014 paper.
Since this toolkit is a fork of the CRFsuite, compiling and executating are completely same with the original software. If you are not quite familiar with CRFsuite, you can refer to its offical website which provides fancy document.
The major difference between CRFsuite and partial-crfsuite is that the latter accepts training data with fuzzy or multiple labels.
In the input training data, labels come in the first column as CRFsuite.
To represent the multiple labels, all the possible labels are packed together by a | delimiter.
Take the partially annotated sentence in Figure 1 for example, the training data can be
e|s u[-1]=_bos_ u[0]=在 u[1]=狐
b u[-1]=在 u[0]=狐 u[1]=歧
m u[-1]=狐 u[0]=歧 u[1]=山
e u[-1]=歧 u[0]=山 u[1]=救
b|s u[-1]=山 u[0]=救 u[1]=治
b|m|e|s u[-1]=救 u[0]=治 u[1]=碧
b|m|e|s u[-1]=治 u[0]=碧 u[1]=瑶
b|m|e|s u[-1]=碧 u[0]=瑶 u[1]=,
b|m|e|s u[-1]=瑶 u[0]=, u[1]=_eos_
We have prepared an example training data in ./partial-data/train.crfsuite.
You can use it to train a model.
./frontend/crfsuite learn -m train.model -a lbfgs partial-data/train.crfsuite
Until now, only the lbfgs is supported by partial-crfsuite.
Other learning alogrithm was not tested in partial-crfsuite.
We also welcome any test and patch :-)
You can use the following commands to test the rained model in previous section. An evaluation script is also provides to test the segmentation performance.
./frontend/crfsuite tag -m train.model partial-data/test.crfsuite | ./partial-data/eval.py -r ./partial-data/test.reference
For license issue, please consult the LICENSE section in the original README file.