Image similarity? #1
Comments
|
Thanks! I believe image similarities will work, although we haven't experimented/evaluated tasks using image similarity measures specifically. |
|
Thank you! I'll try it out and see |
|
I tried it and it seems to work pretty well. (actually better than using a pretrained on classification efficientnet for example) |
|
I've also tried it and it works well. Once you have an image and sentence embedding, all that CLIP does is a dot product. This essentially means that both the image latents and the text latents are embedded in the same space (and that space is a good one!). |
Just to be clear: when you say that it works well (and even "better" than another embedding), you mean that you have this feeling based on visual inspection of a few examples, or is it based on an image dataset which you had built beforehand to assess the different embeddings? I would not have any issue with any of the evaluation methods, but it is just out of curiosity (and clarity). By the way, I am reading your nice blog post: https://rom1504.medium.com/image-embeddings-ed1b194d113e |
|
Visual inspection for now (putting a few thousands image embeddings from clip in a faiss index and trying a few queries), but I also intend to do a more extensive evaluation later on. I know there are also image retrieval research dataset and tasks where evaluating this model would give the most reliable and comparable results. |
|
Results are interesting, but one has to be careful because the model likes to pick text from images. For instance, here, I suspect that images are similar because the word "story" appears. Similarly, here, it is the word "empire" which seems to drive the matching between these images. Here, the word "forest". Etc. It is both impressive... and a bit disappointing if I want to use the model for retrieving similar images. |



|
Maybe that is because the words (e.g., "story") appear in the text.. |
There is zero text. I use the pre-trained model, and I only show the images to it. By the way, if you want to see more results by yourself, you can refresh this page: If you find some interesting results, feel free to post about it here. |
|
Thanks for the clarification. Then the model might have learned attentions to the embedded text regions during the training. It is very interesting, in both of the cases. |
|
I have added a search engine to look for specific Steam games: I am still having fun with this. |
|
I made an app to explore how image similarity works in CLIP by tying it to the closest images in Unsplash. Like @woctezuma noted, it seems to latch onto images with matching text, but in generally there is a lot more going on:
|



|
Anyone has any experience on using CLIP image encoding to compare two images in a loss function (instead pixel loss like MSE, perceptional loss like LPIPS or structural similar like SSIM) to guide image generation (for instance, using generating images matching both text and a given image) or, for example, VAE training. My experiments with this have not been successful, it either does not converge, or does not result in anything like the given image. I wonder if it is the case that CLIP image encoding is strictly semantic and does not contain enough visual features to properly guide training to produce images which resemble, for instance, compositionally to a given image. EDITED to clarify that comparing two image embedding is meant. |
|
@htoyryla there is an active community on twitter trying to do just that! I found an interesting point about the text vectors vs image vectors -- they aren't colocated! |
|
Thanks... my problem at the moment seems BTW more like finding the image from the image encoding. If the loss converges, the resulting image is nowhere near the reference. I am leaning towards the assumption that CLIP encoding is not suitable for this, but I've heard others say I should not put the blame on CLIP. |
https://github.com/orpatashnik/StyleCLIP
|
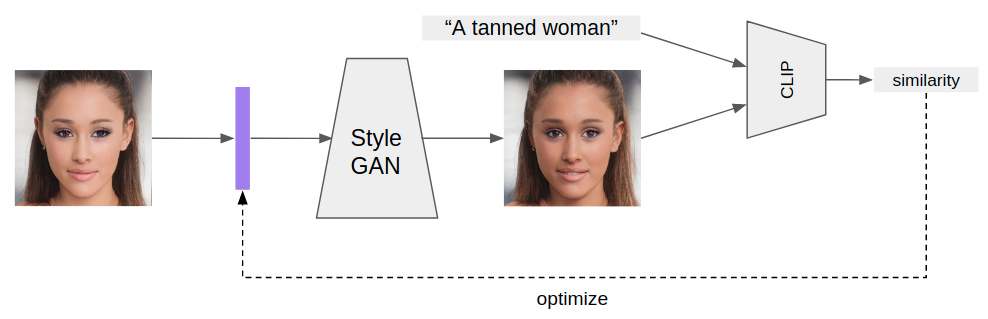
|
Oh, sorry, it looks like I formulated my question ambiguously. I am specifically looking for a case which uses CLIP to compare similarity between two images, i.e. loss calculated from two image embeddings instead of using a more conventional image loss (MSE, LPIPS or SSIM), possibly together with CLIP to compare text with image. The above arrangement uses CLIP in the normal way to compare text and image embeddings. In the most simple form, the problem can be formulated: can you use CLIP to find the image if you have the image embedding. A practical application I have done is to generate an image with a loss function that combines SSIM(generated_image, reference_image) and CLIP cosine distance between embeddings of generated image and a prompt text, for structural or compositional control. Then, somebody suggested to use CLIP also for comparing the two images, and to me it looks like it does not work. Maybe cosine similarity between two image embeddings simply does not make a good loss function to guide image generation (while it is obvious that cosine distance between a text and image embedding does work). |
|
Relevant to some discussion earlier in the thread (and at least an interesting read): |
You can actually remove text (via some text detector) from those images before feeding them to clip and see how it goes. |
|
Hello, I just want to know the L2-norm and cos will be working in the case which between the image and image ? |
Hi @htoyryla, I am working on the same thing as you, I aim to use the CLIP model for the problem of image retrieval. Basically, I am trying to reach similar images to the specific image that I fed into the CLIP model. Since my image pool comprises just highway images, I have done some transfer learning experiments with autonomous vehicle datasets (I re-trained the pre-trained CLIP model on the autonomous vehicle dataset) but this does not work well. |
|
Slightly relevant: this figure in the
Reference [20] is the one which was linked in this post. |

|
can anyone post a fully working code sample (a google colab notebook would be amazing) that will take image A and image B and calculate their image similarity? Thank you so much @woctezuma @iremonur @matrixgame2018 @Sxela @htoyryla @thoppe @scorpionsky @rom1504 @youssefavx @jongwook |
|
First, you extract features as shown in the README: import torch
import clip
from PIL import Image
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)Then you compute similarity between features, e.g. as in the original post or as in the README: # Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) |
thanks a lot for answer i did come up with this way what you think? also do you think clip is the best available method atm for such task? |
|
Sorry, I don't have any authority on this subject. I cannot help more or recommend a method over another. 😅 That being said, out of curiosity, I would probably try
If you have more questions, it would be better to create a new "issue", so that you get more visibility and people are not pinged. |
Incredible work as always you guys! In looking at the Colab, it seems it's possible to do image-to-text similarity but I'm curious if it's possible to compare image similarity as well.
For instance, if I just replace 'text_features' with 'image_features' would that work / be the best way to do this?
The text was updated successfully, but these errors were encountered: