The data consists of sequences of digits from the MNIST dataset padded vertically with random pixels then randomly shifted vertically within a given range. The goal is to correctly recognize the sequence.

There is a readme.html which is converted from this markdown file for demonstration.
CTCLoss.py
- Pytorch implementation of Connectionist Temporal Classification (CTC) loss function by extending
torch.autograd
model_2scnn_2bilstm_scaled.py
- A Pytoch based CNN+LSTM+CTC model
main.py
- Main routine
Two best models:
- Model-6-normal: 0.647% LER on normal testing dataset
- Model-6-random: 2.538% LER on random testing dataset
For the sake of convenience, a test shell script test.sh is provided for testing the pretrained model on test set. Simply run the shell scropt below, and it will help set up the environment, download and generate the dataset and then load and fit the model automatically:
sh test.shThe running environment is set up in Python 2.7.10.
By running virtualenv, it could help set up the environment based on the requirements.txt easily:
# Create and activate new virtual environment
virtualenv venv
source venv/bin/activate
# Install requirements
pip install -r requirements.txtDifferent models are encapsulated as subclasses of Pytorch nn.Module, with forward function implemented. To change the model to train, only need to import different model modules in main.py. E.g.:
from model_bilstm import *The scrip main.py allows to train the model from the beginning or pretrained model, fit the samples based on pretrained model, and plot figures. The detailed usage is as follows:
usage: main.py [-h] [--batch-size N] [--validate-batch-size N] [--epoch N]
[--lr LR] [--momentum M] [--cuda] [--seed S] [--log-interval N]
[--eval] [--model-path MP] [--id ID] [--train-len TRLEN]
[--test-len TELEN] [--new]
Sequence MNIST Recognition
optional arguments:
-h, --help show this help message and exit
--batch-size N input batch size for training (default: 32)
--validate-batch-size N
input batch size for validating (default: 256)
--epoch N number of epochs to train (default: 20)
--lr LR learning rate (default: 0.01)
--momentum M SGD momentum (default: 0.5)
--cuda enables CUDA training
--seed S random seed (default: 1)
--log-interval N how many batches to wait before logging training
status
--eval evaluate a pretrained model
--model-path MP path to the model to evaluate/resume
--id ID id of each training instance
--train-len TRLEN number of digits in each sequence image (training)
--test-len TELEN number of digits in each sequence image (testing)
--new whether to save a new modelThe main.py script also supports checkpoint mechanism (which saves the best model after each epoch) and log function (logs loss and edit distance on training set after each batch and those on validation set after each epoch).
Two best models:
- Model-6-normal: 0.647% LER on normal testing dataset
- Model-6-random: 2.538% LER on random testing dataset
The following code loads the pretrained model and then fits the test data:
python main.py --cuda --model-path 2scnn_2bilstm_scaled_100_best_model.pt --eval
# monitor every 0.1 sec
watch -n 0.1 nvidia-smiDue to the nature of the sequence recognition, accuracy is not appropriate here as an evaluation metric since for example only one different digit in one hundred digits will result in accuracy 0 even if all the other 99 are matched with the target. In this case, label error rate (LER) combined with edit distance is used.
Edit distance is a way of quantifying how dissimilar two strings (e.g., words) are to one another by counting the minimum number of operations required to transform one string into the other. Different definitions of an edit distance use different sets of string operations. The Levenshtein distance operations are the removal, insertion, or substitution of a character in the string. Being the most common metric, the Levenshtein distance is usually what is meant by "edit distance". In our experiments, Levenshtein distance is used.
Given a test set
where
This is a natural measure for tasks (such as speech or handwriting recognition) where the aim is to minimise the rate of transcription mistakes.
Given the probability distribution
Computing the most likely
Traditionally, decoding is done in one of following two ways.
The first traditional decoding strategy is best path decoding, which assumes that the most likely path corresponds to the most likely label. This is not necessarily true: suppose we have one path with probability
Best path decoding is fairly simple to compute; simply look at the most active output at every timestep, concatenate them, and convert them to a label (via removing blanks and duplicates). Since at each step we choose the most active output, the resulting path is the most likely one.
Basically, the images are first processed by a CNN to extract features, then these extracted features are fed into a RNN. Then, the output from RNN are fed into a softmax layer to convert each output to a probability distribution over 11 classes (i.e. 10 digits and 1 blank). Finally, the probability distribution is the input to the final CTC layer.
The architecture of CNN is just Convolution + Batch Normalization + Relu activation + Max Pooling for simplicity and specifically LSTM is used as RNN units.
The second model uses a kernel size with the same height as the image. This is required by the write-up.
| Model-1: lCNN (CNN with large kernei size) + LSTM + CTC | |
|---|---|
| Conv1 | 1 input channel, 36*2 kernel size, 10 feature map, stride = 1 |
| Maxpool1 | 10 input channel, 1*2 kernel size, stride = 1 |
| Conv2 | 10 input channel, 1*2 kernel size, 20 feature map, stride = 1 |
| Maxpool2 | 20 input channel, 1*2 kernel size, stride = 1 |
| Batchnorm | |
| LSTM | 32 hidden size, 1 hidden layer |
| Softmax | =>11 |
| CTC |
The third model uses a kernel size with the same height as the image. Rather than the typical LSTM, it uses bidirectional LSTM. Standard LSTM can only use past contextual information in one direction. However, in terms of the contiguous hand-written digit sequence recognition, bidirectional contextual knowledge may be neeeded. Bidirectional LSTM (BLSTM) can learn long-range context dynamics in both input directions and significantly outperform unidirectional networks.
| Model-1: lCNN (CNN with large kernei size) + BLSTM + CTC | |
|---|---|
| Conv1 | 1 input channel, 36*2 kernel size, 10 feature map, stride = 1 |
| Maxpool1 | 10 input channel, 1*2 kernel size, stride = 1 |
| Conv2 | 10 input channel, 1*2 kernel size, 20 feature map, stride = 1 |
| Maxpool2 | 20 input channel, 1*2 kernel size, stride = 1 |
| Batchnorm | |
| BLSTM | 32 hidden size, 1 hidden layer |
| Softmax | =>11 |
| CTC |
| Model-1: lCNN (CNN with large kernei size) + BLSTM + CTC | |
|---|---|
| Conv1 | 1 input channel, 36*2 kernel size, 10 feature map, stride = 1 |
| Maxpool1 | 10 input channel, 1*2 kernel size, stride = 1 |
| Conv2 | 10 input channel, 1*2 kernel size, 20 feature map, stride = 1 |
| Maxpool2 | 20 input channel, 1*2 kernel size, stride = 1 |
| Batchnorm | |
| BLSTM | 32 hidden size, 2 hidden layers |
| Softmax | =>11 |
| CTC |
The first model has the following architecture:
| Model-1: sCNN (CNN with samll kernei size) + LSTM + CTC | |
|---|---|
| Conv1 | 1 input channel, 5*5 kernel size, 10 feature map, stride = 1 |
| Maxpool1 | 10 input channel, 2*2 kernel size, stride = 2 |
| Conv2 | 10 input channel, 5*5 kernel size, 20 feature map, stride = 1 |
| Maxpool2 | 20 input channel, 2*2 kernel size, stride = 2 |
| Batchnorm | |
| Dropout | p = 0.5 |
| LSTM | 32 hidden size, 1 hidden layer |
| Softmax | =>11 |
| CTC |
| Model-1: lCNN (CNN with large kernei size) + BLSTM + CTC | |
|---|---|
| Conv1 | 1 input channel, 5*5 kernel size, 10 feature map, stride = 1 |
| Maxpool1 | 10 input channel, 2*2 kernel size, stride = 2 |
| Conv2 | 10 input channel, 5*5 kernel size, 20 feature map, stride = 1 |
| Maxpool2 | 20 input channel, 2*2 kernel size, stride = 2 |
| Batchnorm | |
| BLSTM | 32 hidden size, 2 hidden layers |
| Softmax | =>11 |
| CTC |
| Model-1: lCNN (CNN with large kernei size) + BLSTM + CTC | |
|---|---|
| Conv1 | 1 input channel, 3*3 kernel size, 10 feature map, stride = 1 |
| Conv2 | 10 input channel, 5*5 kernel size, 20 feature map, stride = 1 |
| Maxpool | 20 input channel, 3*3 kernel size, stride = 3 |
| Conv3 | 20 input channel, 5*5 kernel size, 25 feature map, stride = 1 |
| Batchnorm | |
| Dropout | p = 0.5 |
| BLSTM | 32 hidden size, 2 hidden layers |
| Softmax | =>11 |
| CTC |
Validation set (100-10000): Average loss: 2.6410, Average edit dist: 0.7509
-
Optimizer: Adam optimizer with
learning rate=0.01,betas=(0.9, 0.999),eps=1e-8,weight_decay=0. Batch size is set to16. -
Training set: 10000 samples with 100 digits in each sample
-
Validation set: 1000 samples with 100 digits in each sample
The experiment environment is in Python 2.7 and built upon AWS p2 instance - powered by Tesla K80 Accelerators,with one GPU that provides 12 GiB of memory.
-
normal training dataset: the overlap between each image is set to a fixed value of 15 pixels
-
random training dataset: the overlap between each image is set to a random value ranged from 15 pixels to 25 pixels
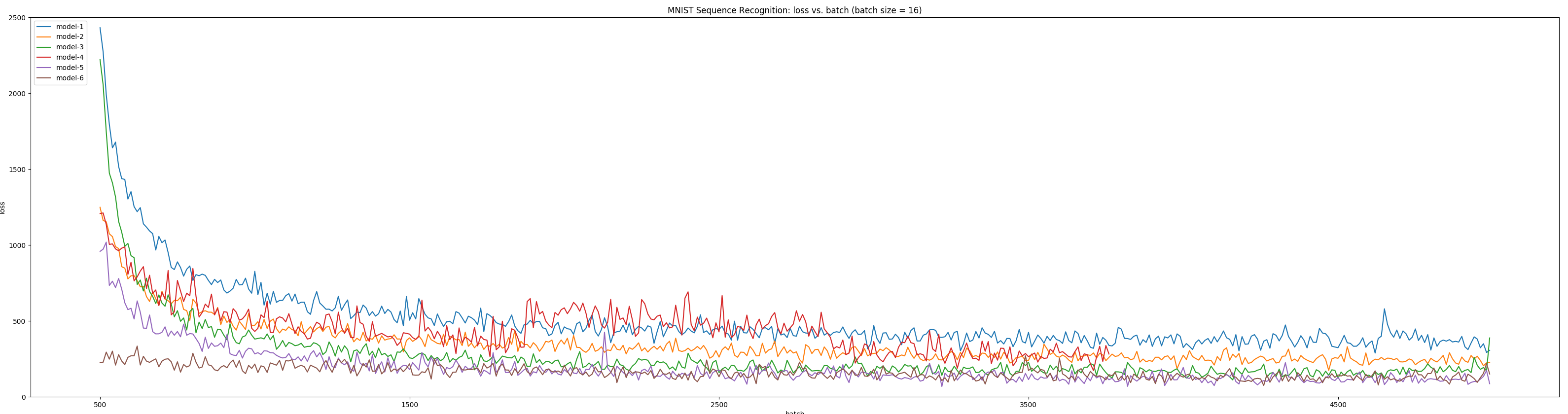 |
|---|
| Six models training on normal_10000_100 |
As shown above, model-6 converges fastest and achieves best performance. Furthermore, the detailed statistics of model-6 after 58 epochs is as followed:
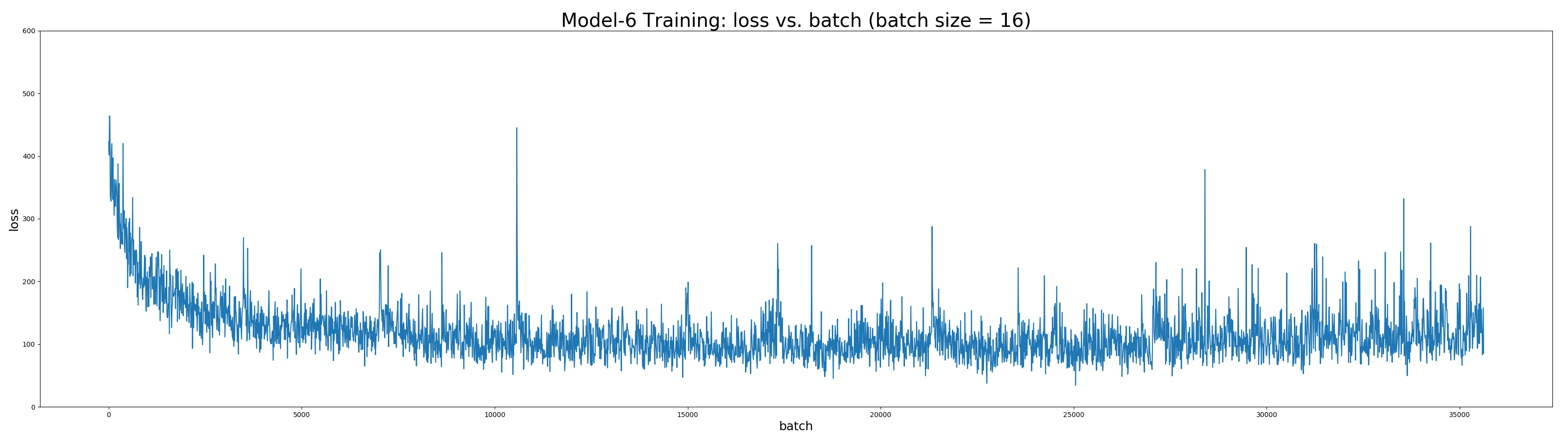
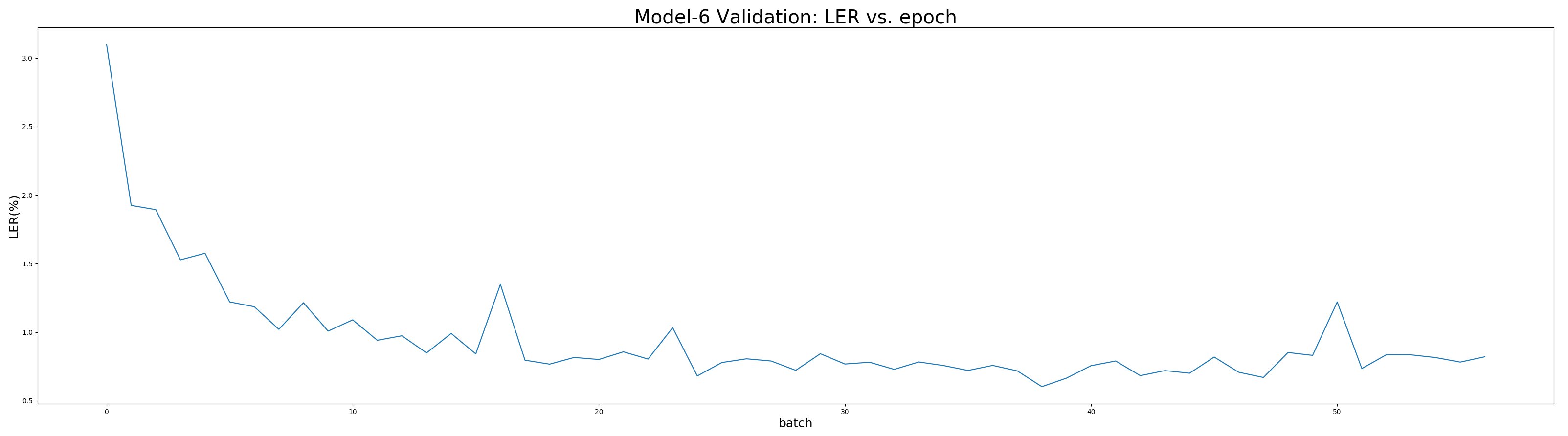
The best performance of model-6 is in epoch 40 with average LER 0.603% and loss 2.087 on validation set.
Model-6 trained on normal training dataset after 40 epochs (i.e. best model in first experiment) is further trained on new random training dataset for the other 82 epochs.
 |
|---|
| Model-6 Training on random_10000_100 |
 |
|---|
| Model-6 Validation on random_1000_100 |
The best model in epoch 105 (counting the 40 epochs for the pre-trained model) with average LER 2.538% and loss 8.893 on validation set.
The stability of the model is also tested. As show below, a simple model-1 trained after several epochs is used to test:
-
training(20)/test(5)
Validation set: Average loss: 0.4893, Average edit dist: 0.1348
-
training(20)/test(20)
Validation set: Average loss: 1.6601, Average edit dist: 0.4023
-
training(20)/test(100)
Validation set: Average loss: 16.9200, Average edit dist: 4.4844
It is observed that models tend to be more stable if trained on longer sequence (i.e. with more digits).
| LER_random | Loss_random | LER_normal | Loss_normal | |
|---|---|---|---|---|
| Model-6-random | 2.538% | 8.893 | 5.540% | 19.991 |
| Model-6-normal | 12.776% | 111.407 | 0.647% | 2.255 |
As shown the table above, the performance of the model trained on normal dataset degrades significanly when testing on random dataset. Meanwhile, the model trained on random dataset seems more stable, but appears overfitting on random dataset as the LER incrases when testing on normal dataset.