[hybrid performance] Optimize pipeline send wait #34086
Merged
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
Thanks for your contribution! |
Aurelius84
approved these changes
Jul 12, 2021
JZ-LIANG
approved these changes
Jul 12, 2021
gongweibao
reviewed
Jul 13, 2021
| assert dev_type == "gpu" or dev_type == 'npu', ( | ||
| "Now only gpu and npu devices are supported " | ||
| "for pipeline parallelism.") | ||
| if not device in device_list: | ||
|
|
||
| if device not in device_list: |
This was referenced Jul 17, 2021
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
PR types
Performance optimization
PR changes
Others
Describe
1、添加nop op,不作任何操作。主要作用有(静态图下有用,动态图不需要):
2、优化pipeline前向send的wait_comm,在保证完成send的情况下,使用nop替换sync_comm,减少不必要的同步。
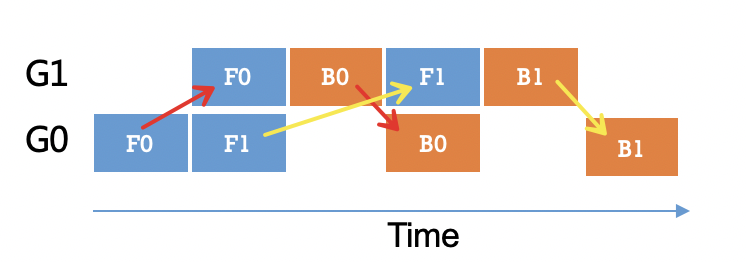
如下图,根据执行顺序可知,若当前stage反向recv完成,那么前向的send也一定完成了。则该场景下,send可以不需要加同步;
但send使用的变量如果没有op使用它,则会被gc回收,在send使用通信流场景下就会出错;所以为解决这个问题,在反向recv后面添加一个nop op,确保在recv完之后对应的变量才被回收。
V100 32G,gpt2-en模型测试