upload transformer in eng_spa #5391
Conversation
|
感谢你贡献飞桨文档,文档预览构建中,Docs-New 跑完后即可预览,预览链接:http://preview-pr-5391.paddle-docs-preview.paddlepaddle.org.cn/documentation/docs/zh/api/index_cn.html |
| "\n", | ||
| "\n", | ||
| "* Transformer:\n", | ||
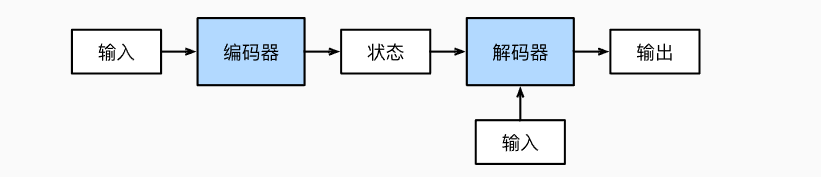
| "Transformer是Sequence-to-sequence架构的一种实例,其诞生于2017年的《Attention is all you need》,诞生之处该模型就展示出了强大的魅力,刷新了NLP领域的大部分SOTA。现如今在Transformer在CV领域应用也得到了十分广泛的应用。Transformer的框架图如下:\n", |
| "# inputs=paddle.rand([64,20,256])\n", | ||
| "# print(\"inputs.shape:\",inputs.shape)\n", | ||
| "# out=pencoder(inputs)\n", | ||
| "# print(\"out.shape:\",out.shape)" |
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "class PositionalEmbedding(paddle.nn.Layer):\n", |
There was a problem hiding this comment.
标题是基于 Transformer 的机器翻译的话,这里的 position embedding 和 Transformer 原论文对齐吧,采用 sin/cos 这种形式
| " metrics=paddle.metric.Accuracy())\n", | ||
| "\n", | ||
| "model.fit(train_data=train_loader, \n", | ||
| " epochs=epochs,\n", |
| "model=paddle.Model(trans)\n", | ||
| "\n", | ||
| "\n", | ||
| "model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001,parameters=model.parameters()),\n", |
| "\n", | ||
| " self.drop=paddle.nn.Dropout(p=0.5)\n", | ||
| "\n", | ||
| " self.lastLinear=paddle.nn.Linear(embed_dim,vocab_size)\n", |
There was a problem hiding this comment.
这里可以提供选项,是否和 embedding 共享同一套参数
| " encoder_input=paddle.unsqueeze(eng,axis=0)\n", | ||
| " decoded_sentence = \"[start]\"\n", | ||
| " \n", | ||
| " for i in range(sequence_length):\n", |
There was a problem hiding this comment.
生成这里是否可以使用 paddle 或是 paddlenlp 的 API 实现?dynamic_decode 以及 TransformerBeamSearchDecoder
| "with open('result.txt','r') as re:\n", | ||
| " pre=re.readlines()\n", | ||
| "\n", | ||
| "for i in range(5):\n", |
There was a problem hiding this comment.
| " positions = paddle.arange(start=0, end=length, step=1)\n", | ||
| " embedded_tokens = self.token_embeddings(inputs)\n", | ||
| " embedded_positions = self.position_embeddings(positions)\n", | ||
| " return embedded_tokens + embedded_positions\n", |
There was a problem hiding this comment.
类名是 PositionalEmbedding,但是计算了 word embedding 和 positional embedding?如果想要定义为 PositionalEmbedding,能否把这两部分分开
| "source": [ | ||
| "## 4.1 Encoder\n", | ||
| "Encoder部分主要包含了多头注意力机制、层归一化层以及前馈神经网络序列。\n", | ||
| "* MultiHeadAttention :使用`paddle.nn.MultiHeadAttention`实现多头注意力机制,需要注意其掩码attn_mask需要的shape是[batch_szie,num_heads,sequence_legth,sequence_legth]\n", |
|
@2017040264 请按照RD的意见好好修改一下,同时回复我们的审阅意见哈~ |
| "* 作者信息:\n", | ||
| " * Github:[2017040264](https://github.com/2017040264)\n", | ||
| " * AiStudio:[月光下的独孤亮](https://aistudio.baidu.com/aistudio/personalcenter/thirdview/689988)\n", | ||
| "* 更新日期:2022.10.31\n", |
| "import random\n", | ||
| "import matplotlib.pyplot as plt\n", | ||
| "from functools import partial\n", | ||
| "from collections import Counter" |
There was a problem hiding this comment.
展示一下paddle的版本, print(paddle.version)
| } | ||
| ], | ||
| "source": [ | ||
| "for _ in range(5):\n", |
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## 3.3划分数据集" |
There was a problem hiding this comment.
这里补充一下,“训练:验证:测试的比例分别是” ? 这些文字描述是意义的,便于读者理解
| }, | ||
| "outputs": [], | ||
| "source": [ | ||
| "train_eng_texts = [pair[0] for pair in train_pairs]\n", |
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## 3.6 用训练集分别构造英语和西班牙语的语料库" |
There was a problem hiding this comment.
这底下也加一下描述,
比如,**代表构造的英语语料库,**代表构造的西班牙语语料库,使用字典的方式,记录每个词的频率,等等的描述。
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## 3.7 输入向量化\n" |
There was a problem hiding this comment.
加一下描述,使用build_tensor构造向量,其大小,长度,纬度等。 (注意一定要加上基本的说明,方便读者理解)
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## 3.8 封装数据集" |
There was a problem hiding this comment.
加上:使用paddle.io.Dataset 封装数据集。定义 BATCH_SIZE 为 64 ,shape为??
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "# 4.模型组网\n", |
There was a problem hiding this comment.
可以的话,不妨加上模型的网络结构图。尤其是编码解码的流程。
| { | ||
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ |

There was a problem hiding this comment.
这个是在Ai studio里边运行产生的,好像去不掉
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "## 5.1 自定义loss函数" |
| "name": "stdout", | ||
| "output_type": "stream", | ||
| "text": [ | ||
| "The loss value printed in the log is the current step, and the metric is the average value of previous steps.\n", |
There was a problem hiding this comment.
就train的记录来看,loss有点大,acc小了。。(因为有点太明显,这个模型的效果-精确度-确实太好。)
| "\n", | ||
| "英语: They had fun with us.\n", | ||
| "真实的西班牙语: [start] ellas se entretuvieron con nosotras [end]\n", | ||
| "预测的西班牙语: [start] ellos se <unk> con nosotros [end]\n", |
There was a problem hiding this comment.
预测效果,还比较普通,预测的西班牙语有漏了词的。(是任务太复杂么?)
There was a problem hiding this comment.
就这个示例来看,应该是entretuvieron 未在构造的词库里边,所以预测称为了
| "metadata": {}, | ||
| "source": [ | ||
| "## 4.1 输入处理\n", | ||
| "Transformer的输入部分使用的是词嵌入(word embedding)和位置编码(positional encoding)的结合。Transformer模型并不包括任何的循环或卷积网络,所以模型添加了位置编码,为模型提供一些关于单词在句子中相对位置的信息。这个位置编码的具体计算方法有很多种,论文中的计算方法如下:\n", |
| " proj_output = self.dense_proj(out_2)\n", | ||
| " return self.layernorm_3(out_2 + proj_output)\n", | ||
| "\n", | ||
| " def get_causal_attention_mask(self, inputs):\n", |
There was a problem hiding this comment.
代码格式需要再进行调整,比如这里逗号后面是否有空格、前面的代码里面赋值语句等号两侧是否有空格并没有统一
There was a problem hiding this comment.
好嘞,我提交了一个新的版本,您一会再看下还有问题嘛
|
@ FrostML 请RD看看代码还有没有问题? |
| "source": [ | ||
| "# 使用我们提供的数据集\n", | ||
| "\n", | ||
| "text_file='data/data173968/spa.txt' # 数据集路径" |
There was a problem hiding this comment.
如果不使用 aistudio 这里的设置会直接出问题,这里还是期望能直接用当前的 Notebook 可以执行,不依赖具体的 aistudio project,这里直接使用上面自行下载的数据集的代码吧,这里 aistudio 的路径注释或是删去
|

| "metadata": {}, | ||
| "source": [ | ||
| "## 3.7 输入向量化\n", | ||
| "* maxlen是我们进行向量长度,超过该长度的向量被截断(弃尾);不足该长度的进行padding(padding值为0)\n" |
There was a problem hiding this comment.
补充以下内容
- 一句话说明该build_tensor函数的作用(不用加 *)
- 参数 & 返回值 的说明(可以加 *)
另外 "进行向量长度" 这句话的用词再斟酌一下,似乎不通顺
| " train_spa_texts_pre, spa2id_dict, sequence_length)\n", | ||
| "val_spa_tensor = build_tensor(val_spa_texts_pre, spa2id_dict, sequence_length)\n", | ||
| "test_spa_tensor = build_tensor(\n", | ||
| " test_spa_texts_pre, spa2id_dict, sequence_length)\n" |
There was a problem hiding this comment.
建议:能否截部分tensor输出展示,比较直观
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "* 为西班牙语添加`[start]`与 `[end]`\n", |
There was a problem hiding this comment.
不用给每句话前面都加* ,这里建议不加

| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "* 英语和添加`[start]`及`[end]`后的西班牙语展示:" |
| "cell_type": "markdown", | ||
| "metadata": {}, | ||
| "source": [ | ||
| "* 定义英语和西班牙语的预处理函数\n", |

| "* padid=0,0是`<pad>`字段的对应的值,与3.6中我们的字典设计对应\n", | ||
| "* 该函数返回值的含义:\n", | ||
| " - 第一个返回值:英语输入向量,shape=[batchsize,sequence_length]\n", | ||
| " - 第二个返回值:西班牙语输入向量,shape=[batchsize,sequence_length-1],第二个维度是`sequence_length-1`,因为我们使用`teacher force`技巧进行训练。实际上我是取的**前**`sequence_length-1`个向量。\n", |
There was a problem hiding this comment.
可以对 teacher force 进行简单说明,或者附上链接
| "source": [ | ||
| "## 4.2 Encoder\n", | ||
| "Encoder部分主要包含了多头注意力机制、归一化层以及前馈神经网络。输入会依次经过多头注意力模块、归一化层构成的残差模块、前馈神经网络模块、归一化层构成的残差模块。\n", | ||
| "* 多头注意力机制(MultiHeadAttention):使用`paddle.nn.MultiHeadAttention`实现多头注意力机制,需要注意其掩码attn_mask需要的shape是[batch_szie,num_heads,sequence_legth,sequence_legth]\n", |
There was a problem hiding this comment.
paddle.nn.MultiHeadAttention 该api附上相应api文档链接
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/MultiHeadAttention_cn.html#multiheadattention
| "source": [ | ||
| "## 5.1 自定义loss函数\n", | ||
| "* 自定义loss函数的目的是将消除填充位置对loss的影响\n", | ||
| "* softmax_with_cross_entropy是softmax交叉熵损失函数。该函数会将 softmax 操作、交叉熵损失函数的计算过程进行合并,从而提供了数值上更稳定的梯度值。" |
There was a problem hiding this comment.
softmax_with_cross_entropy 附上相应api文档链接
https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/nn/functional/softmax_with_cross_entropy_cn.html#softmax-with-cross-entropy
| "metadata": {}, | ||
| "source": [ | ||
| "# 6. 结果预测\n", | ||
| "使用测试集进行结果的预测,并计算BLEU得分。\n" |
There was a problem hiding this comment.
建议对bleu进行简短说明,如“bleu是一种对生成语句进行评估的指标。完美匹配的得分为1.0,而完全不匹配则得分为0.0。” 并附上相应链接:https://en.wikipedia.org/wiki/BLEU
| "## 5.2 训练与验证\n", | ||
| "* 定义训练的轮数epochs\n", | ||
| "* 实例化模型类并使用paddle.Model进行封装\n", | ||
| "* 实例化NoamDecay类,实现动态学习率\n", |
There was a problem hiding this comment.
|
@jzhang533 修改后的版本已经上传,请稍后审阅 |
| "metadata": {}, | ||
| "source": [ | ||
| " 定义对每个minibatch的数据集进行处理的函数\n", | ||
| "* 输入参数padid的默认值为0,0是字段的对应的值,与3.6中我们的字典设计对应\n", |
There was a problem hiding this comment.
不好意思,是我之前写修改意见少加了<pad>,话术应该是: 0是<pad>字段的对应的值
There was a problem hiding this comment.
针对以上typo的修复版本已重新pr,烦请审阅。
| "\n", | ||
| "\n", | ||
| "## Transformer:\n", | ||
| "Transformer是Sequence-to-sequence架构的一种实例,其诞生于2017年的[《Attention is all you need》]( https://arxiv.org/abs/1706.03762),诞生之初该模型就展示出了强大的魅力,刷新了NLP领域的大部分SOTA。现如今在Transformer在CV领域应用也得到了十分广泛的应用。Transformer的框架图如下:\n", |
There was a problem hiding this comment.
《Attention is all you need》 后的英文逗号改成中文逗号
| "* 输入参数padid的默认值为0,0是字段的对应的值,与3.6中我们的字典设计对应\n", | ||
| "* 该函数返回值的含义:\n", | ||
| " - 第一个返回值:英语输入向量,shape=[batchsize,sequence_length]\n", | ||
| " - 第二个返回值:西班牙语输入向量,shape=[batchsize,sequence_length-1],第二个维度是`sequence_length-1`,因为我们使用`teacher force`技巧进行训练。实际上我是取的**前**`sequence_length-1`个向量。\n", |
There was a problem hiding this comment.
这四个返回值的解释中,除代码外,将英文逗号均转成中文逗号。同时第一句话补充句号。
| "* 该函数返回值的含义:\n", | ||
| " - 第一个返回值:英语输入向量,shape=[batchsize,sequence_length]\n", | ||
| " - 第二个返回值:西班牙语输入向量,shape=[batchsize,sequence_length-1],第二个维度是`sequence_length-1`,因为我们使用`teacher force`技巧进行训练。实际上我是取的**前**`sequence_length-1`个向量。\n", | ||
| " - 第三个返回值:西班牙语目标向量,shape=[batchsize,sequence_length-1,1],第二个维度也是`sequence_length-1`,因为我们使用`teacher force`技巧进行训练(指在每一轮预测时,不使用上一轮预测的输出,而强制使用真实的标签序列,过这样的方法可以有效的避免因中间预测错误而对后续序列的预测,从而加快训练速度)。实际上我是取的**后**`sequence_length-1`个向量。此外,我们额外增加了一个维度,用于loss的计算。\n", |
There was a problem hiding this comment.
-
..过这样的方法可以...有typo,稍了个“通”,改成...通过这样的方法可以.. -
英文括号改成中文括号
| "metadata": {}, | ||
| "source": [ | ||
| "## 4.3 Decoder\n", | ||
| "编码器含有两个多头注意力模块,第一个是带序列掩码的多头注意力模块,用于处理西班牙语的输入;第二个多头注意力模块是用于处理编码器的输出和前一个多头注意力机制的输出。输入在编码器其中会依次经过带序列掩码的多头注意力模块、归一化层构成的残差模块、多头注意力模块、归一化层构成的残差模块、前馈神经网络模块、归一化层构成的残差模块。\n", |
There was a problem hiding this comment.
编码器含有两个多头..以及输入在编码器其中会依次经过...这两部分应该不是编码器而是解码器吧
| "metadata": {}, | ||
| "source": [ | ||
| "## 5.1 自定义loss函数\n", | ||
| "* 自定义loss函数的目的是将消除填充位置对loss的影响\n", |
upload transformer with eng_spa task