Speed up default.qubit by using permutations to apply some gates #772
Conversation
Codecov Report
@@ Coverage Diff @@
## master #772 +/- ##
==========================================
+ Coverage 93.42% 93.53% +0.10%
==========================================
Files 115 115
Lines 7044 7110 +66
==========================================
+ Hits 6581 6650 +69
+ Misses 463 460 -3
Continue to review full report at Codecov.
|

pennylane/devices/default_qubit.py
Outdated
| apply_func = self._ops_map.get(operation.name, None) | ||
| if apply_func: | ||
| self._state = apply_func(self._state, axes, inverse=operation.inverse) | ||
| return | ||
|
|
There was a problem hiding this comment.
This was partially motivated from pylint complaining about too many return statements, but also it seemed a bit bloated in the other approach which was:
if isinstance(operation, Gate):
self._state = self._apply_gate(self_state, axes)x9 times.
The downside of the current approach is that all the methods need a compatible signature, resulting in a **kwargs addition in some cases (which pylint also didn't like 😆, hence the ignore on line 157)
There was a problem hiding this comment.
👍
An alternate approach is to change them to methods, with a signature like:
def _apply_y(self, state, axes, roll_fn=np.roll, stack_fn=np.stack):e.g., you pass the functions to use for rolling and stacking. But, I don't think this is any cleaner then the current approach (it's probably worse).
There was a problem hiding this comment.
Nice, could also work if we want to make these methods functions, although not sure how it would scale if we want to add other array functions to the argument. I guess we could pass a container of array functions.
|
I did a second round of benchmarks, this time on a server rather than my laptop to minimize the influence of other running processes.
For me, this leaves the following gates up for discussion:
Luckily, CZ and PauliY are less commonly used, but Hadamard is pretty common. One thing we can do is prevent the special methods for these gates from occurring in For |



| del self._apply_ops["PauliY"] | ||
| del self._apply_ops["Hadamard"] | ||
| del self._apply_ops["CZ"] |
There was a problem hiding this comment.
😆 This is to give better benchmarks?
There was a problem hiding this comment.
How so? 😄 Edit: saw the benchmark files. Might be worth leaving a comment here describing that a poorer performance was observed for this gates.
|
|
||
|
|
||
| def _get_slice(index, axis, num_axes): | ||
| """Allows slicing along an arbitrary axis of an array or tensor. |
There was a problem hiding this comment.
Could be worth adding an example, would also help understanding the exact role of each argument.
There was a problem hiding this comment.
Also, in the quantum sense, is it fair to say that this is a _get_subsystem function? If so and didn't miss anything, might be worth a renaming, just because that it might make it more intuitive when reading how the operations are being applied
There was a problem hiding this comment.
Thanks, have added an example: 9efdbd5.
There was a problem hiding this comment.
is it fair to say that this is a _get_subsystem function?
No, it's slightly different. In a quantum sense, suppose we have a three qubit system with state tensor having shape (2, 2, 2). Then _get_slice(1, 1, 3) gives us all of the amplitudes that correspond to having a |1> state in qubit 1. Likewise, _get_slice(1, 2, 3) would be all the amplitudes with a |1> state in qubit 2, while _get_slice(0, 1, 3) would be all the amplitudes with a |0> state in qubit 1. So really what _get_slice() allows you to do is to slice into the state so that your selecting |0> or |1> for a given qubit. This is relevant when, for example, we want to do control or when we want to apply a phase on the |1> state.
Unfortunately, I'm not sure of the best name 😆
pennylane/devices/default_qubit.py
Outdated
| # If axis[1] is larger than axis[0], then state[sl_1] will have self.num_wires - 1 axes with | ||
| # the target axes shifted down by one. Otherwise, if axis[1] is less than axis[0] then its | ||
| # axis number in state[sl_1] remains unchanged. For example: state has axes [0, 1, 2, 3] and | ||
| # axis[0] = 1 and axis[1] = 3. Then, state[sl_1] has axes [0, 1, 2] so that the target axis | ||
| # has shifted from 3 to 2. If axis[0] = 2 and axis[1] = 1, then state[sl_1] has axes | ||
| # [0, 1, 2] but with the target axis remaining unchanged. | ||
| if axes[1] > axes[0]: | ||
| target_axes = [axes[1] - 1] | ||
| else: | ||
| target_axes = [axes[1]] |
There was a problem hiding this comment.
This part is not entirely clear to me when going for it for some time.
then state[sl_1] will have self.num_wires - 1 axes with
# the target axes shifted down by one
Why is it so?
One-piece that is missing is how the first wire is being the control (although the operation does seem to be equivalent). Might be worth explaining perhaps in the main docstring, how using slices and the axes we can end up with the same operation.
There was a problem hiding this comment.
🤔 I've tried to explain a bit better, and also add to the main docstring.
7059c50
| @@ -142,6 +180,148 @@ def _apply_operation(self, operation): | |||
| else: | |||
| self._apply_unitary(matrix, wires) | |||
|
|
|||
| def _apply_x(self, state, axes, **kwargs): | |||
| """Applies a PauliX gate by rolling 1 unit along the axis specified in ``axes``. | |||
There was a problem hiding this comment.
Might be worth elaborating on why this is equivalent to applying a PauliX
There was a problem hiding this comment.
Thanks, I tried to add an explanation, but I have to admit these things are hard to explain!
There was a problem hiding this comment.
Thanks @antalszava, good suggestions! I've had a go at making changes and it's ready for another look.
|
|
||
|
|
||
| def _get_slice(index, axis, num_axes): | ||
| """Allows slicing along an arbitrary axis of an array or tensor. |
There was a problem hiding this comment.
Thanks, have added an example: 9efdbd5.
|
|
||
|
|
||
| def _get_slice(index, axis, num_axes): | ||
| """Allows slicing along an arbitrary axis of an array or tensor. |
There was a problem hiding this comment.
is it fair to say that this is a _get_subsystem function?
No, it's slightly different. In a quantum sense, suppose we have a three qubit system with state tensor having shape (2, 2, 2). Then _get_slice(1, 1, 3) gives us all of the amplitudes that correspond to having a |1> state in qubit 1. Likewise, _get_slice(1, 2, 3) would be all the amplitudes with a |1> state in qubit 2, while _get_slice(0, 1, 3) would be all the amplitudes with a |0> state in qubit 1. So really what _get_slice() allows you to do is to slice into the state so that your selecting |0> or |1> for a given qubit. This is relevant when, for example, we want to do control or when we want to apply a phase on the |1> state.
Unfortunately, I'm not sure of the best name 😆
| @@ -142,6 +180,148 @@ def _apply_operation(self, operation): | |||
| else: | |||
| self._apply_unitary(matrix, wires) | |||
|
|
|||
| def _apply_x(self, state, axes, **kwargs): | |||
| """Applies a PauliX gate by rolling 1 unit along the axis specified in ``axes``. | |||
There was a problem hiding this comment.
Thanks, I tried to add an explanation, but I have to admit these things are hard to explain!
| del self._apply_ops["PauliY"] | ||
| del self._apply_ops["Hadamard"] | ||
| del self._apply_ops["CZ"] |
pennylane/devices/default_qubit.py
Outdated
| # If axis[1] is larger than axis[0], then state[sl_1] will have self.num_wires - 1 axes with | ||
| # the target axes shifted down by one. Otherwise, if axis[1] is less than axis[0] then its | ||
| # axis number in state[sl_1] remains unchanged. For example: state has axes [0, 1, 2, 3] and | ||
| # axis[0] = 1 and axis[1] = 3. Then, state[sl_1] has axes [0, 1, 2] so that the target axis | ||
| # has shifted from 3 to 2. If axis[0] = 2 and axis[1] = 1, then state[sl_1] has axes | ||
| # [0, 1, 2] but with the target axis remaining unchanged. | ||
| if axes[1] > axes[0]: | ||
| target_axes = [axes[1] - 1] | ||
| else: | ||
| target_axes = [axes[1]] |
There was a problem hiding this comment.
🤔 I've tried to explain a bit better, and also add to the main docstring.
7059c50
| # We will be slicing into the state according to state[sl_1], giving us all of the | ||
| # amplitudes with a |1> for the control qubit. The resulting array has lost an axis | ||
| # relative to state and we need to be careful about the axis we apply the PauliX rotation | ||
| # to. If axes[1] is larger than axes[0], then we need to shift the target axis down by | ||
| # one, otherwise we can leave as-is. For example: a state has [0, 1, 2, 3], control=1, | ||
| # target=3. Then, state[sl_1] has 3 axes and target=3 now corresponds to the second axis. |
Context:
This PR uses some array/tensor manipulation tricks such as roll, transpose and slicing to speed up the application of some gates:
For example,
PauliXcan be achieved simply usingnp.roll(state, 1, wire_axis). Currently in PL, these gates are applied using the_apply_diagonal_unitary()and_apply_unitary_einsum()methods, which both internally perform a contraction usingeinsum.Description of the Change:
Additional methods have been added to
DefaultQubitfor each of the above gates, e.g.,_apply_x()forPauliX. In the mainapply_operation()method, we then dispatch to each of the functions using a dictionary that maps from operation name to corresponding method.Benefits:
Increased speed. This can be checked using a benchmark script (see at the bottom). The script makes a trial circuit composed of a single gate that is repeatedly placed on each qubit and then repeated for a chosen depth. The script then times how long multiple runs take to complete. Using this, we can benchmark the new and old approaches in
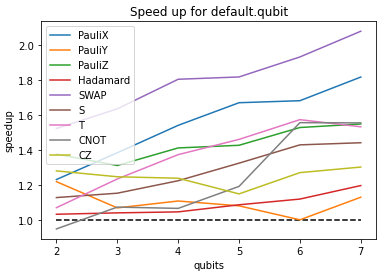
DefaultQubitand find the speedup as a function of qubit number:We see a speed up, with different gates performing better than others.
PauliYandHadamardare the worst performers, possibly because they combine two applications ofPauliXandPauliZ.Note that the changes in this PR are also compatible with
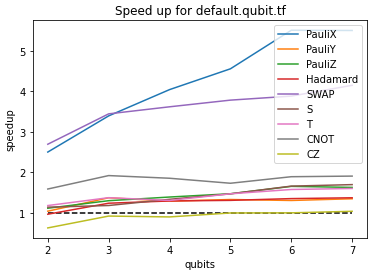
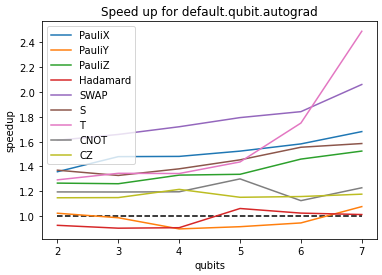
default.qubit.tfanddefault.qubit.autograd. The speedup plots are shown below:I'm not sure exactly why the
default.qubit.tfplot looks different. Also, these benchmarks are quite artificial in that we only restrict to the gates that we hope to have sped up - practical circuits may include other gates.Possible Drawbacks:
DefaultQubitfeels a bit busy now with a lot of methods. I couldn't pull out these methods as functions in a separateopsfile because we need access to, e.g.,self._rollfor the interface-correct function.DefaultQubit.Rot, which are quite common. I don't think there is any fundamental roadblock for doing this though, could be a follow up PR.Benchmark script: