JavaScript (Node.js) implementation #29
Conversation
|
It´s about 20 times faster than a properly optimized pure python solution, about 30% faster than C#, but about half the speed of JIT´d python and C++. I am quite impressed by NodeJS´ JIT, it seems to do great work. (We should all know that V8 is a beast) Question: I found during optimizing Python, that inlining GetBit caused quite noticeable performance gains. Did you profile your code to see where the slowdowns currently are? |
|
I actually hadn't. What do you mean by inlining GetBit? |
Remove the GetBit function and directly write all the code in the place where GetBit is used. Although, now I think about it, it will probably not make as much as a difference as it did using Python. |
|
Holy cow; It made a HUGE difference. Way more than I expected. Switching GetBit out and making it inline brought the performance from ~1900 iterations to being close to on par with yours - around 6600 iterations for me. |
…ing them inline instead
|
Interestingly, after investigating the timing, I discovered that around 20% of the time taken in the new version is just allocating memory for the UInt8Array. I'm not quite sure if there's a way to improve upon that, though. |
Cool! As I said, I also didn´t expect much improvement. I guess inlining this simple operation is not something V8 can do. TIL!
20% is quite a lot for just allocation, but keep in mind that it´s a 1MB array. That´s quite significant. On my system, that would take 256 memory pages (my pagesize is |
I thought about that, but in the case of this drag race, I think it may be unfaithful to the format. I think that there's a point where I have to accept that this is a limitation of JS, as all the other implementations perform the same steps (Loop as many times as possible, and in each loop, re-create the Primes object and re-run it) |
|
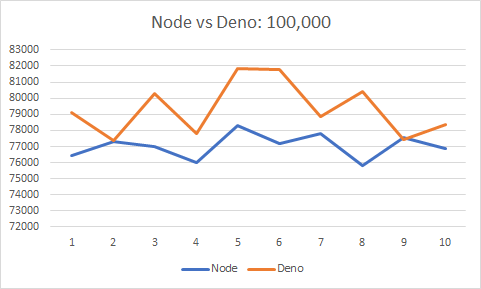
For the curious, I ran the benchmark 10 times each on the Node.js and Deno runtimes, to see if there is any performance difference. 10 seconds of 100,000: 10 seconds of 1,000,000: 10 seconds of 10,000,000: Make of it what you will! It appears that for larger prime sets, i.e. 1M and 10M, Deno was more consistent. I wonder if that has to do with its garbage collection. as it uses Rust instead of C/C++. Not sure. |


|
@davepl may you merge it and try it? Can you try to make an episode with coolest and unexpected results? |
|
@JL102 Getting rid of the class implementation and just using the direct functions will help a bit... the number of prototype lookups is likely a bit of an impact on the implementation. |
Hmm, I hadn't even thought of that. I can do some tests to see the performance difference. But since all of the original implementations utilized creating a PrimeSieve class, I think the specifics of this benchmark would require doing the same in order to be fair. I would say that the only exception would be for languages that don't support classes and constructors. |
|
I can't speak to that portion... simply that the use of |
|
I can always make a second version w/ the modifications 🙂 |
Was thinking about that like BUT I am not sure if this is cheating in a way. |
So when I tested using direct functions w/o classes, I gave that a shot as well. It turns out that, unsurprisingly, looping through the entire structure to reset it takes about the same amount of time as re-allocating a new instance of the structure. Additionally, the functional implementation had pretty much the exact same performance as the class implementation. I have a feeling that even if there is a performance improvement from using direct functions, it's overshadowed by the bottleneck of all the other computation. If I kept the GetBit and ClearBit functions, maybe the performance difference would be more noticeable - but I doubt that it would be anywhere near as fast as not having them at all. |
|
Node didn't give me any optimization bailouts either with the code. I did try few things with partially weird results and found very minor improvements which I share later once I confirmed everything adequately. |
|
Ooh, I just had a thought - WebAsembly would be an interesting addition to the pile. I've never done it before, but it might be reeeeeeelatively simple to compile the Rust or C++ implementations into WASM? |
|
Yeah, I thought of WASM too but would split that as secondary option as it isn't "pure" js imho. Compiling from Rust would be preferred here. I do remember something that compiling from Rust creates a more light weight binary. |
|
Oh, yeah, it would absolutely have to be separate from JS. 🙂 |
|
@JL102 I did created a PR to your implementation. |
|
Please add a Docker image for this so we can include it in the CI and Benchmark workflows |
|
Some minor comments on your code, which was 10 times faster than my attempt, just because of the Uint8Array instead of a normal one. That's a very nice discovery! You say: There actually is: That would take away the need for inverted logic. Another thing I noticed that could give you a minor performance improvement is this: The second part is a bit involved with the negation: That piece of code runs a lot. Last, I was surprised that you use a parseInt for The code is fine if q remains a double. The Edit: ran into another thing. Your comparison table has this: The entry for 10 should be 4. Also, when you compare the entries for validation, you do this: Which is functionally exactly the same as: There is no need to check for undefined as that will never equal the primes count Second edit: I am quite surprised you did not see any difference between the Class and function with prototype implementation. The Class implementation is about 12% slower (reproducible) on my Mac Pro i5: 4475 versus 3927. That's a very significant difference. And it's an exact copy, just with functions assigned to the prototype. |
|
I'm curious if the TypeScript compiler can do some of these optimizations automatically. |
That could be a fun one! I'd say Rust is the easier option given the tooling: https://rustwasm.github.io/docs/book/introduction.html Staying on the more JS side, have you tried AssemblyScript? |
|
On a WASM version, would be cool to see... Rust is probably the best option, as mentioned, it's a very clean path to WASM with the available tooling. Would probably want to run with Node and the other couple WASM runtimes available. Definitely interested in any results there. |
|
@JL102 If you want to move towards including your solution in the drag-race, it would need to comply with the contribution guidelines. Amongst other things, that means that the PR needs to be opened on the drag-race branch of this repo, not original (formerly main). Do note that we do have another Node.js solution in place. You could take a look to see if yours is sufficiently different from that one before you compose the PR. |
|
Closing this due to another Node.js solution being in place. |
Created a Nodejs implementation, primarily copied from the C# version.
JS supports bitwise operations for integers, which vastly improves performance compared to using parseInt(index / 2).
(I'm pleasantly surprised that it performs significantly better than the Python implementation.)
NOTE: To run using Node.js: run
node PrimeJS.js