| branche | tests | coverage |
|---|---|---|
| master | ||
| develop |
Ce module permet d’importer des données depuis un fichier CSV dans GeoNature.
-
Télécharger puis renommer la version souhaitée du module :
cd wget https://github.com/PnX-SI/gn_module_import/archive/X.Y.Z.zip unzip X.Y.Z.zip rm X.Y.Z.zip mv gn_module_import-X.Y.Z gn_module_import -
Le module doit ensuite être installé comme suit :
source ~/geonature/backend/venv/bin/activate geonature install-gn-module ~/gn_module_import IMPORT deactivate sudo systemctl restart geonature sudo systemctl restart geonature-worker
Le module est installé et prêt à importer !
Il vous faut désormais attribuer des permissions aux groupes ou utilisateurs que vous souhaitez, pour qu'ils puissent accéder et utiliser le module (voir https://docs.geonature.fr/admin-manual.html#gestion-des-droits). Si besoin une commande permet d'attribuer automatiquement toutes les permissions dans tous les modules à un groupe ou utilisateur administrateur.
Vous pouvez modifier la configuration du module en créant un fichier
import_config.toml dans le dossier config de GeoNature, en vous inspirant
du fichier import_config.toml.example et en surcouchant les paramètres que vous souhaitez
(champs affichés en interface à l'étape 1, préfixe des champs ajoutés par le module,
répertoire d'upload des fichiers, SRID, encodage, séparateurs, etc).
Pour appliquer les modifications de la configuration du module, consultez la rubrique dédiée de la documentation de GeoNature.
Une autre partie se fait directement dans la base de données, dans les
tables dict_fields et dict_themes, permettant de masquer, ajouter,
ou rendre obligatoire certains champs à renseigner pour l'import. Un
champs masqué sera traité comme un champs non rempli, et se verra
associer des valeurs par défaut ou une information vide. Il est
également possible de paramétrer l'ordonnancement des champs (ordre,
regroupements dans des blocs) dans l'interface du mapping de champs. A
l'instar des attributs gérés dans TaxHub, il est possible de définir
des "blocs" dans la table gn_imports.dict_themes, et d'y attribuer
des champs (dict_fields) en y définissant leur ordre d'affichage.
La gestions des permissions dans le module d'import se fait via le réglage du CRUVED à deux niveaux : au niveau de l'objet "import" et au niveau de l'objet "mapping".
- Le CRUVED sur l'objet "import" permet de gérer l'affichage des imports. Une personne ayant un R = 3 verra tous les imports de la plateforme, un R = 2 seulement les siens et ceux de son organisme et un R = 1 seulement les siens.
- Les jeux de données selectionnables par un utilisateur lors de la création d'un import sont eux controlés par les permissions sur le C de l'objet "import" (combiné au R du module "Métadonnées).
- Les mappings constituent un "objet" du module d'import disposant de droits paramétrables pour les différents utilisateurs, indépendamment des permissions sur les imports. Le réglage des permissions se fait dans le module "Admin" de GeoNature ("Admin" -> "Permissions").
- Certains mappings sont définis comme "public" et sont vus par tout le monde. Seuls les administrateurs (U=3) et les propriétaires de ces mappings peuvent les modifier.
- Par exemple, avec un C = 1, R = 2, U = 1 sur les mappings, un utilisateur pourra créer des nouveaux mappings (des modèles d'imports), modifier ses propres mappings et voir les mappings de son organisme ainsi que les mappings "publics".
- Si vous modifiez un mapping sur lequel vous n'avez pas les droits, il vous sera proposé de créer un nouveau mapping vous appartenant avec les modifications que vous avez faites, mais sans modifier le mapping initial. Lorsqu'on a les droits de modification sur un mapping, il est également possible de ne pas enregistrer les modifications faites à celui-ci pour ne pas écraser le mapping inital (le mapping sera sauvegardé uniquement avec l’import).
-
Téléchargez la nouvelle version du module
wget https://github.com/PnX-SI/gn_module_import/archive/X.Y.Z.zip unzip X.Y.Z.zip rm X.Y.Z.zip -
Renommez l'ancien et le nouveau répertoire
mv ~/gn_module_import ~/gn_module_import_old mv ~/gn_module_import-X.Y.Z ~/gn_module_import -
Si vous avez encore votre configuration du module dans le dossier
configdu module, copiez le vers le dossier de configuration centralisée de GeoNature :cp ~/gn_module_import_old/config/conf_gn_module.toml ~/geonature/config/import_config.toml -
Lancez la mise à jour du module
source ~/geonature/backend/venv/bin/activate geonature install-gn-module ~/gn_module_import IMPORT sudo systemctl restart geonature
Note : le processus a un petit peu évoluer en v2 avec notamment une étape supplémentaire.
Le module permet de traiter un fichier CSV (GeoJSON non disponible dans la v2 pour le moment) sous toute structure de données, d'établir les correspondances nécessaires entre le format source et le format de la synthèse, et de traduire le vocabulaire source vers les nomenclatures SINP. Il stocke et archive les données sources et intègre les données transformées dans la synthèse de GeoNature. Il semble préférable de prévoir un serveur disposant à minima de 4 Go de RAM.
- Une fois connecté à GeoNature, accédez au module Imports. L'accueil du module affiche une liste des imports en cours ou terminés, selon les permissions de l'utilisateur connecté. Vous pouvez alors finir un import en cours, ou bien commencer un nouvel import.
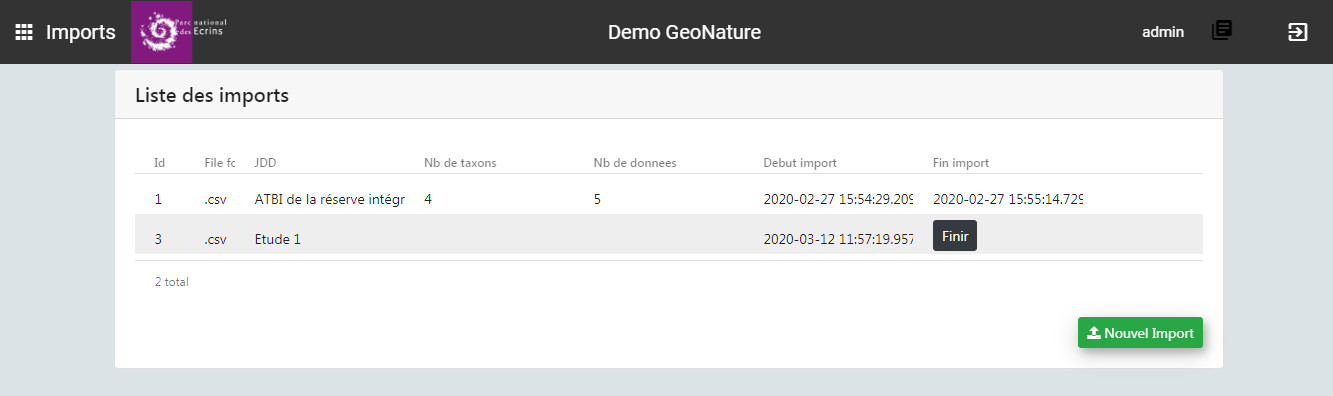
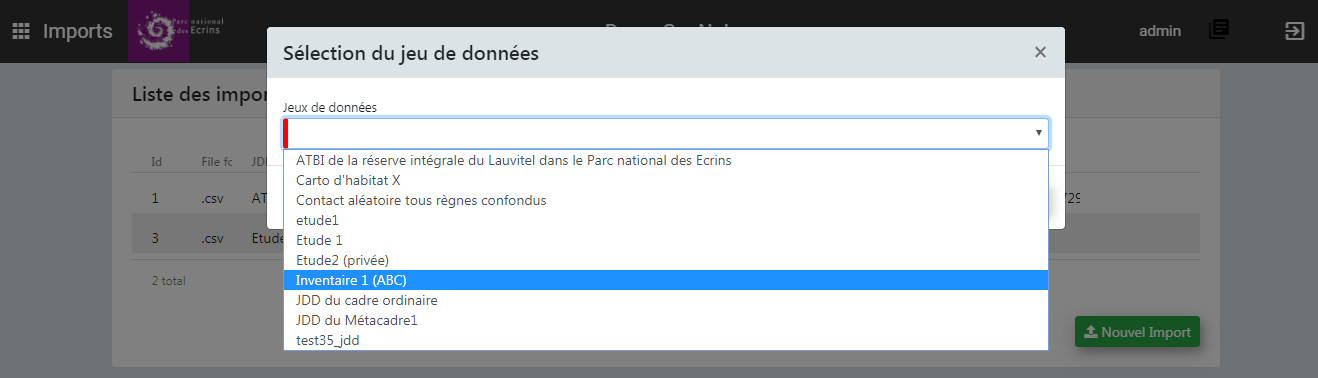
- Choisissez à quel JDD les données importées vont être associées. Si vous souhaitez les associer à un nouveau JDD, il faut l'avoir créé au préalable dans le module Métadonnées.
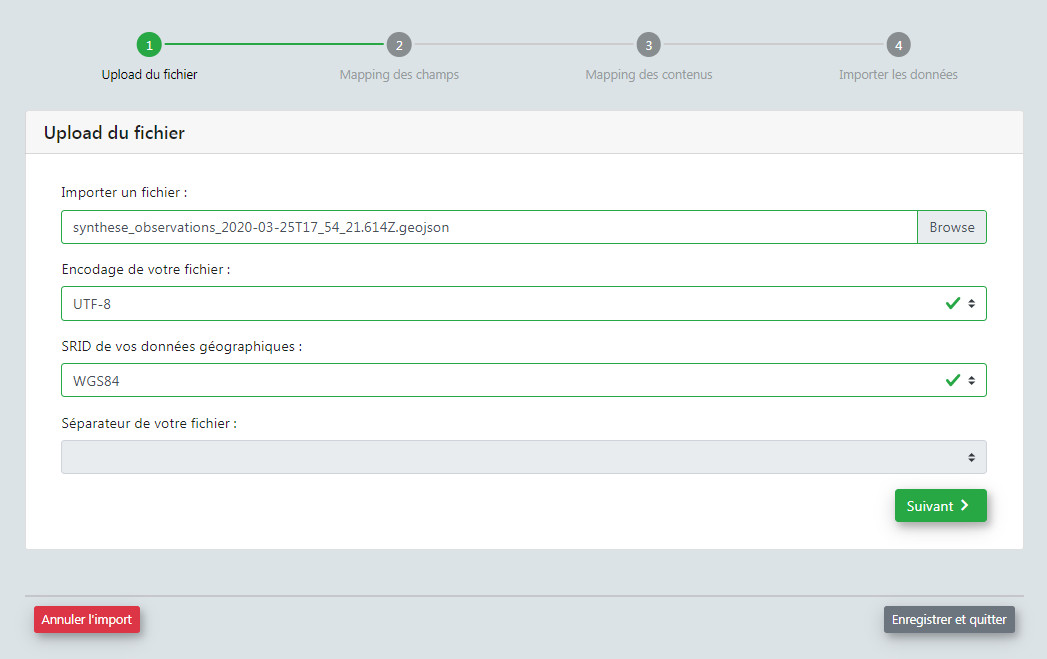
- Chargez le fichier CSV (GeoJSON non disponible dans la v2 pour le moment) à importer.
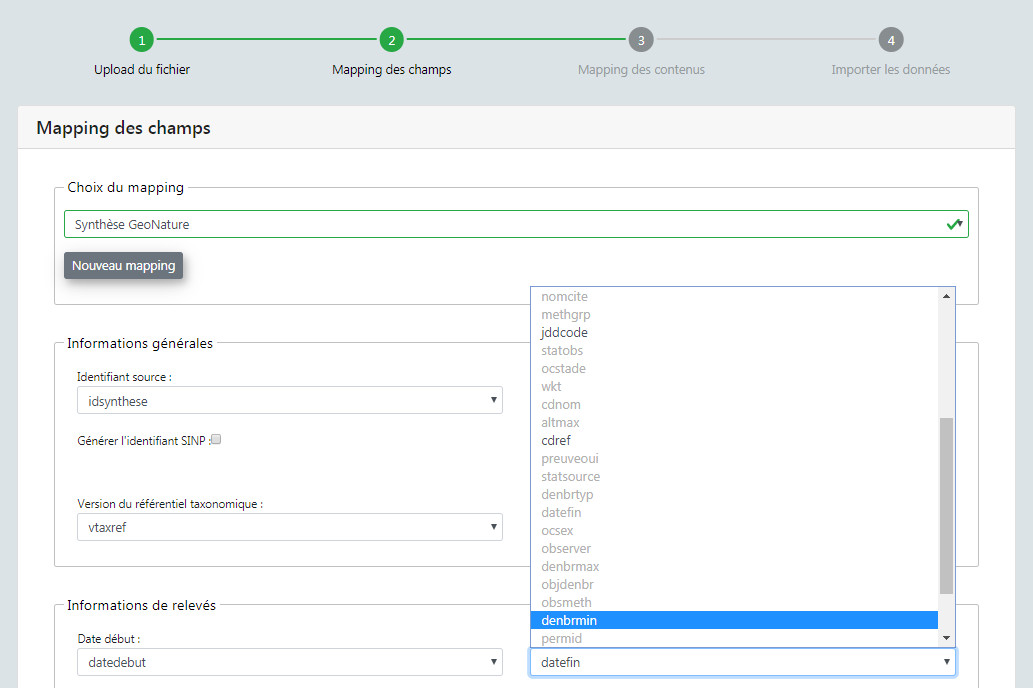
- Mapping des champs. Il s'agit de faire correspondre les champs du fichier importé aux champs de la Synthèse (basé sur le standard "Occurrences de taxons" du SINP). Vous pouvez utiliser un mapping déjà existant ou en créer un nouveau. Le module contient par défaut un mapping correspondant à un fichier exporté au format par défaut de la synthèse de GeoNature. Si vous créez un nouveau mapping, il sera ensuite réutilisable pour les imports suivants. Il est aussi possible de choisir si les UUID uniques doivent être générés et si les altitudes doivent être calculées automatiquement si elles ne sont pas renseignées dans le fichier importé.
- Une fois le mapping des champs réalisé, au moins sur les champs obligatoires, il faut alors valider le mapping pour lancer le contrôle des données. Vous pouvez ensuite consulter les éventuelles erreurs. Il est alors possible de corriger les données en erreurs directement dans la base de données, dans la table temporaire des données en cours d'import, puis de revalider le mapping, ou de passer à l'étape suivante. Les données en erreur ne seront pas importées et seront téléchargeables dans un fichier dédié à l'issue du processus.
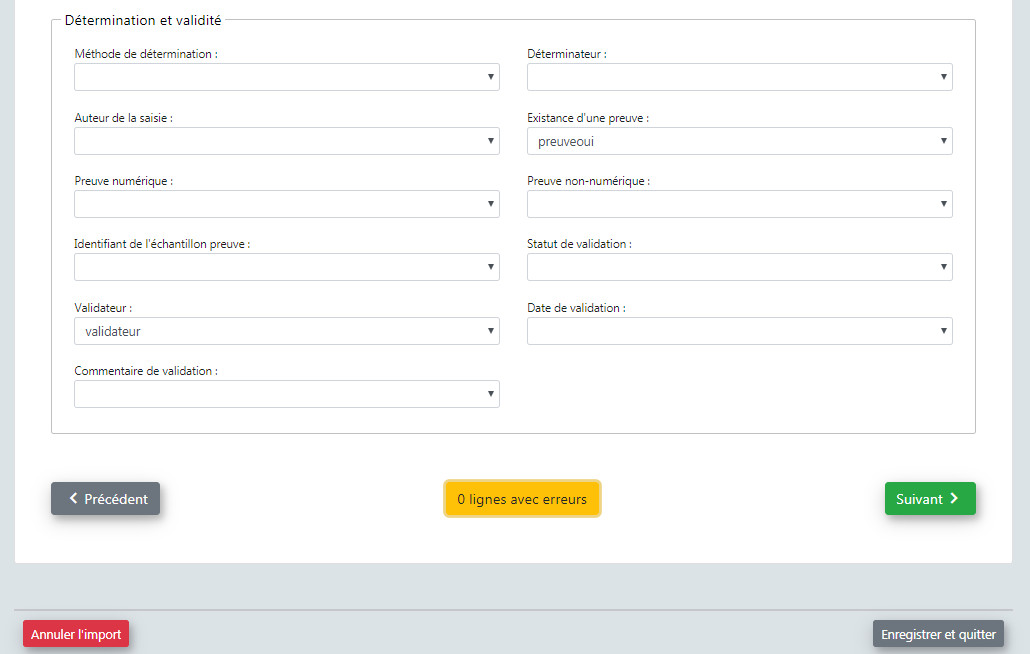
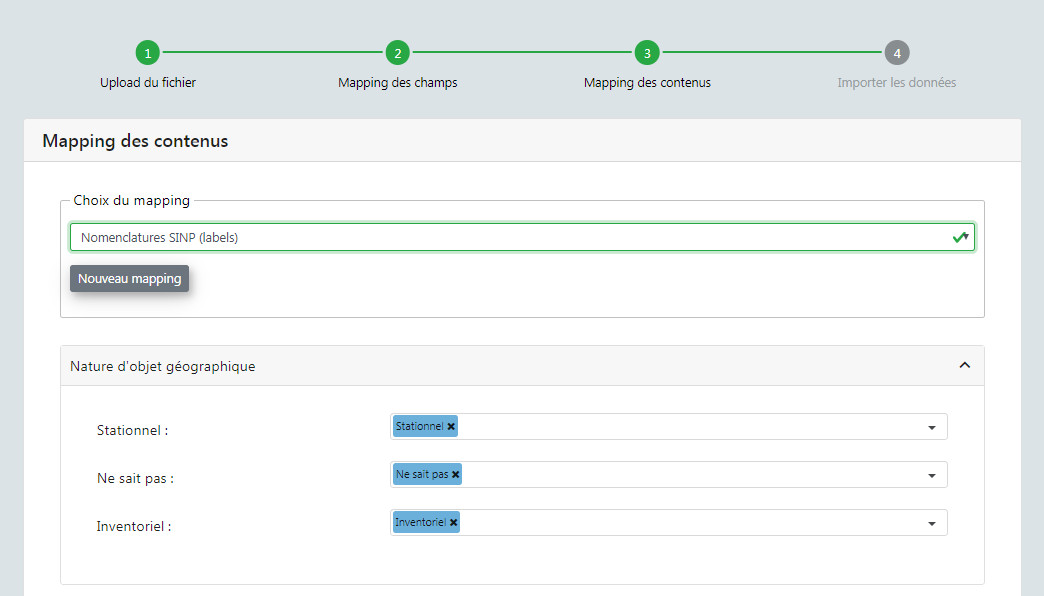
- Mapping des contenus. Il s'agit de faire correspondre les valeurs des champs du fichier importé avec les valeurs disponibles dans les champs de la Synthèse de GeoNature (basés par défaut sur les nomenclatures du SINP). Par défaut les correspondances avec les nomenclatures du SINP sous forme de code ou de libellés sont fournies.
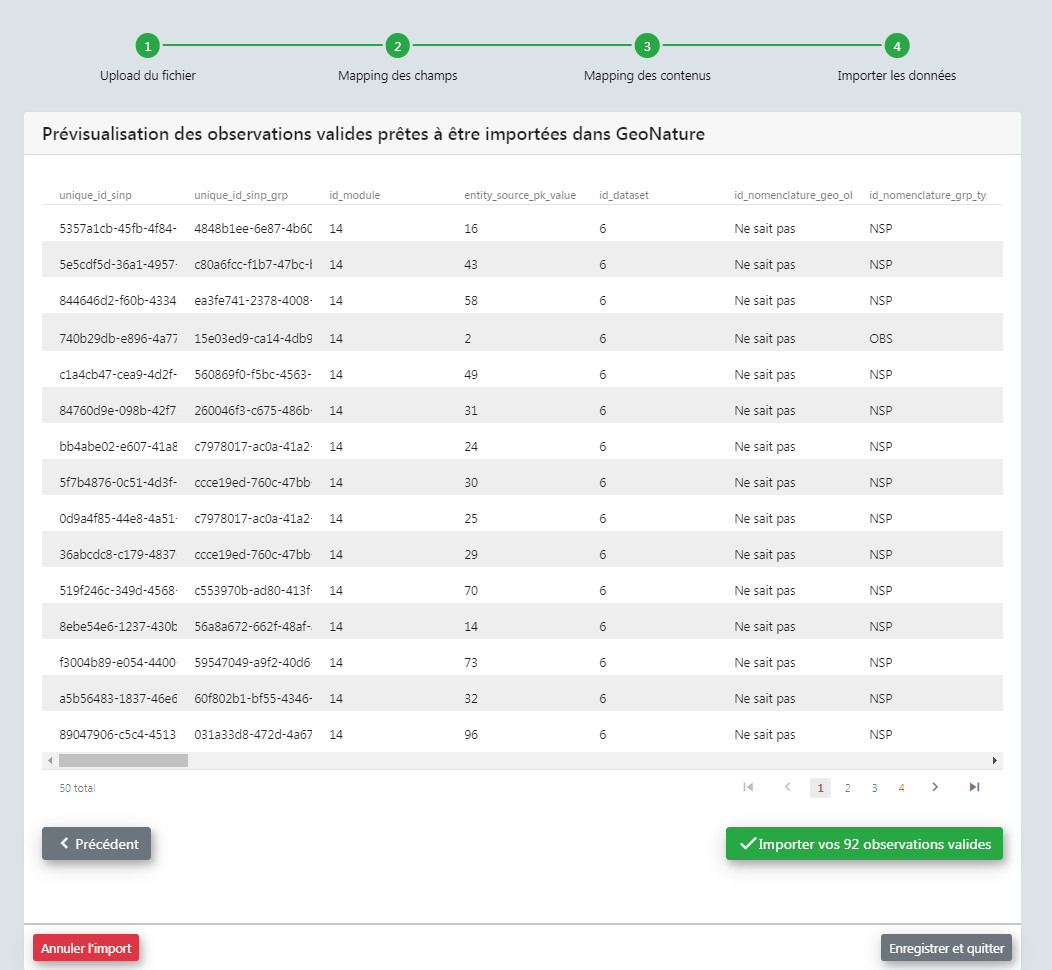
- La dernière étape permet d'avoir un aperçu des données à importer et leur nombre, avant de valider l'import final dans la Synthèse de GeoNature.
Pour chaque fichier importé, les données brutes sont importées
intialement et stockées en binaire dans le champs t_imports.source_file.
Elles sont aussi stockées
dans une table intermédiaire, enrichie au fur et à mesure des étapes de
l'import.
Liste des contrôles réalisés sur le fichier importé et ses données : #17
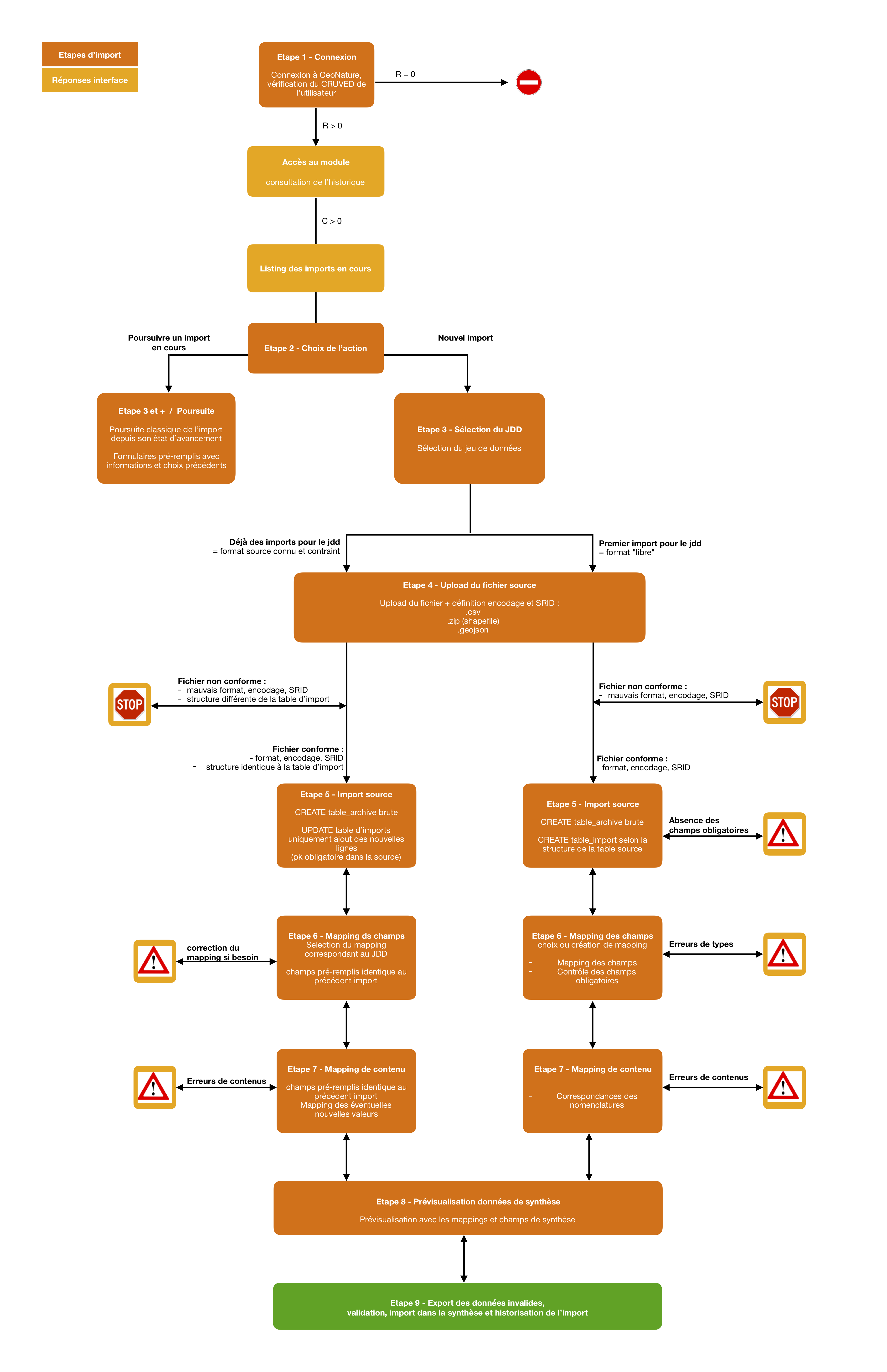
Schéma (initial et théorique) des étapes de fonctionnement du module :
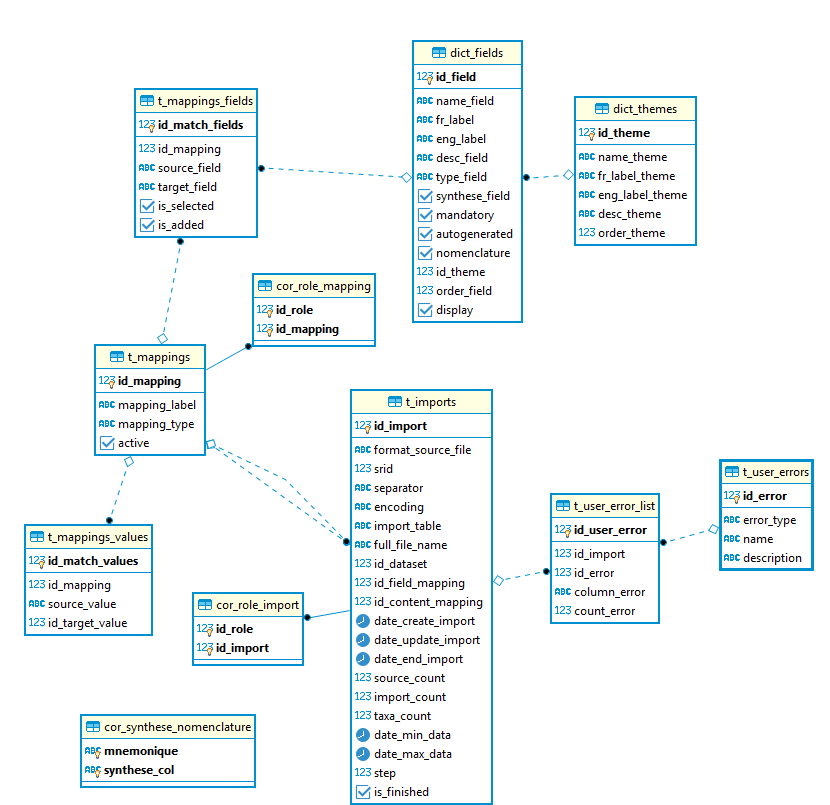
Modèle de données du schéma gn_imports du module (à adapter à la version 2.0.0) :
- J'ai un R d'au moins 1 sur le module Import : J'accède au module et je vois les imports en fonction de mon R.
- J'ai un C d'au moins 1 sur le module Import, je peux créer un import, ou terminer un import auquel j'ai accès.
- J'ai au moins un JDD actif associé au module Import.
- Je créé un nouvel Import. Le C sur le module Import permet de lister mes JDD actifs et associés au module Import, ceux de mon organisme ou tous les JDD actifs associés au module Import.
- Je choisis le JDD auquel je veux associer les données à importer.
- Etape 1 : J'uploade mon fichier CSV (GeoJSON n'est plus disponible dans la v2 pour le moment). Le contenu du CSV est stocké en binaire dans la table des imports (
gn_imports.t_imports.source_file). Cela permet d'analyser le fichier (encodage, séparateur...) et de télécharger les données sources. - Etape 2 : L'encodage, le format et le séparateur du fichier sont auto-détectés. Je peux les modifier si je le souhaite. Je renseigne le SRID parmi les SRID disponibles dans la configuration du module.
- Etape 3 : Je choisis un modèle d'Import existant et/ou je mets en correspondance les champs du fichier source avec ceux de la Synthèse de GeoNature. Les modèles d'import listés dépendent des permissions sur l'objet "MAPPING". La première ligne du fichier binaire est lue pour lister les champs du fichier source.
- Si je choisis un modèle et que je mappe un nouveau champs, ou une valeur différente pour un champs, je peux modifier le modèle existant, en créer un nouveau ou ne sauvegarder ces modifications dans aucun modèle.
- Si j'ai mappé une valeur source différente sur un champs déjà présent dans le modèle, il est écrasé par la nouvelle valeur si je mets à jour le modèle. Actuellement un champs de destination ne peut avoir qu'un seul champs source. Par contre un champs source peut avoir plusieurs champs de destination (
date→date_minetdate→date_max, par exemple). - Les correspondances des champs sont stockées dans tous les cas en json dans le champs
gn_imports.t_imports.fieldmapping. Cela permet de pouvoir reprendre les correspondances d'un import, même si le modèle a été modifié entre temps. - Quand on valide l'étape 3, les données sources des champs mappés sont chargées dans la table d'import temporaire (
gn_imports.t_imports_synthese) avec une colonne pour la valeur de la source et une pour la valeur de destination. Cela permet à l'application de faire des traitements de transformation et de contrôle sur les données. Les données sources dans des champs non mappées sont importées dans un champs json de cette table (extra_fields) - Etape 4 : Les valeurs des champs à nomenclature sont déterminées à partir du contenu de la table
gn_imports.t_imports_synthese. Une nomenclature de destination peut avoir plusieurs valeurs source. Pour chaque type de nomenclature on liste les valeurs trouvées dans le fichier source et on propose de les associer aux valeurs des nomenclatures présentes dans GeoNature. Si le fichier source comprend des lignes vides, on propose en plus de mapper le cas "Pas de valeur". La gestion des mappings est similaire à l'étape 3 (ils sont stockées cette fois-ci dans le champsgn_imports.t_imports.contentmapping). - Etape 5 : Il est proposé à l'utilisateur de lancer les contrôles. Ceux-ci sont exécutés en asynchrone dans tous les cas, et une barre de progression est affichée à l'utilisateur. Quand les contrôles sont terminés, le nombre d'erreurs est affiché, ainsi qu'une carte de l'étendue géographique des données et un tableau d'aperçu des données telles qu'elles seront importées.
Si il y a des erreurs, l'utilisateur peut télécharger le fichier des données sources invalides. Elles sont récupérées dans la table
gn_imports.t_imports.source_fileen ne prenant que les lignes qui ont une erreur, en se basant sur les données qui ont le champsvalid=falsedansgn_imports.t_imports_syntheseL'utilisateur peut alors lancer l'import des données dans la Synthèse. Il est lancée en asynchrone dans tous les cas, et un spinner de chargement est affiché tant que l'import est en cours. Si d'autres imports sont en cours, le mécanisme asynchrone gère un système de queue pour les faire les uns après les autres et ne pas saturer le serveur. - Il est possible de reprendre et modifier un import que celui-ci soit terminé ou non. Il est notamment possible d'uploader un nouveau fichier pour un import existant. En cas de modification d’un import existant, les données sont immédiatement supprimées de la synthèse. Les nouvelles données seront insérées lors de la nouvelle finalisation de l’import.
- Une fois les données importées, les données sont supprimées de la table temporaire (
gn_imports.t_imports_synthese) - Administration des modèles : Depuis le module ADMIN de GeoNature, il est possible de lister, afficher et modifier les modèles d'import.
Financement de la version 1.0.0 : DREAL et Conseil Régional Auvergne-Rhône-Alpes.
Financement de la version 2.0.0 : Ministère de la Transition écologique et UMS Patrinat.