![]()
![]()
![]()
![]()

Credit card fraud is when someone uses another person's credit card or account information to make unauthorized purchases or access funds through cash advances. Credit card fraud doesn’t just happen online; it happens in brick-and-mortar stores, too. As a business owner, you can avoid serious headaches – and unwanted publicity – by recognizing potentially fraudulent use of credit cards in your payment environment.
The Credit Card Fraud Detection Problem includes modeling past credit card transactions with the knowledge of the ones that turned out to be a fraud. This model is then used to identify whether a new transaction is fraudulent or not. Our aim here is to detect 100% of the fraudulent transactions while minimizing the incorrect fraud classifications.
The datasets contains transactions made by credit cards in September 2013 by european cardholders. This dataset presents transactions that occurred in two days, where we have 492 frauds out of 284,807 transactions. The dataset is highly unbalanced, the positive class (frauds) account for 0.172% of all transactions.
It contains only numerical input variables which are the result of a PCA transformation.
Due to confidentiality issues, there are not provided the original features and more background information about the data.
Features V1, V2, ... V28 are the principal components obtained with PCA; The only features which have not been transformed with PCA are Time and Amount. Feature Time contains the seconds elapsed between each transaction and the first transaction in the dataset. The feature Amount is the transaction Amount, this feature can be used for example-dependant cost-senstive learning. Feature Class is the response variable and it takes value 1 in case of fraud and 0 otherwise.
Libraries: NumPy pandas pylab matplotlib sklearn seaborn plotly
Only 492 (or 0.172%) of transaction are fraudulent. That means the data is highly unbalanced with respect with target variable Class.
Fraudulent transactions have a distribution more even than valid transactions - are equaly distributed in time, including the low real transaction times, during night in Europe timezone.
Let's look into more details to the time distribution of both classes transaction, as well as to aggregated values of transaction count and amount, per hour. We assume (based on observation of the time distribution of transactions) that the time unit is second.
Plot in red color is for Fraudulent transactions.
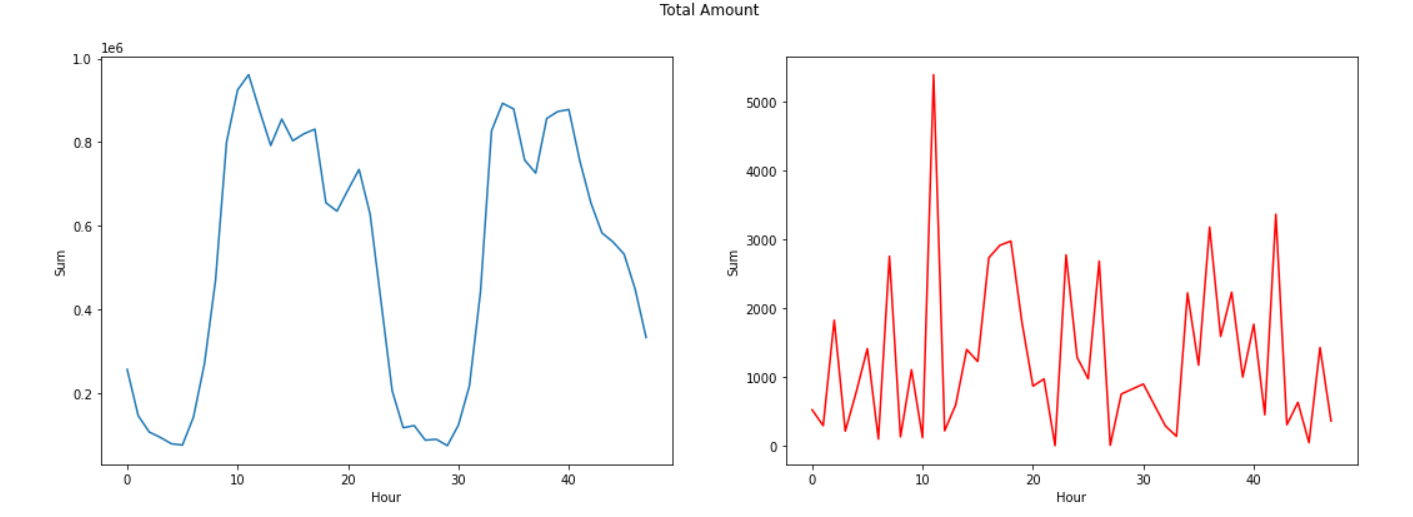
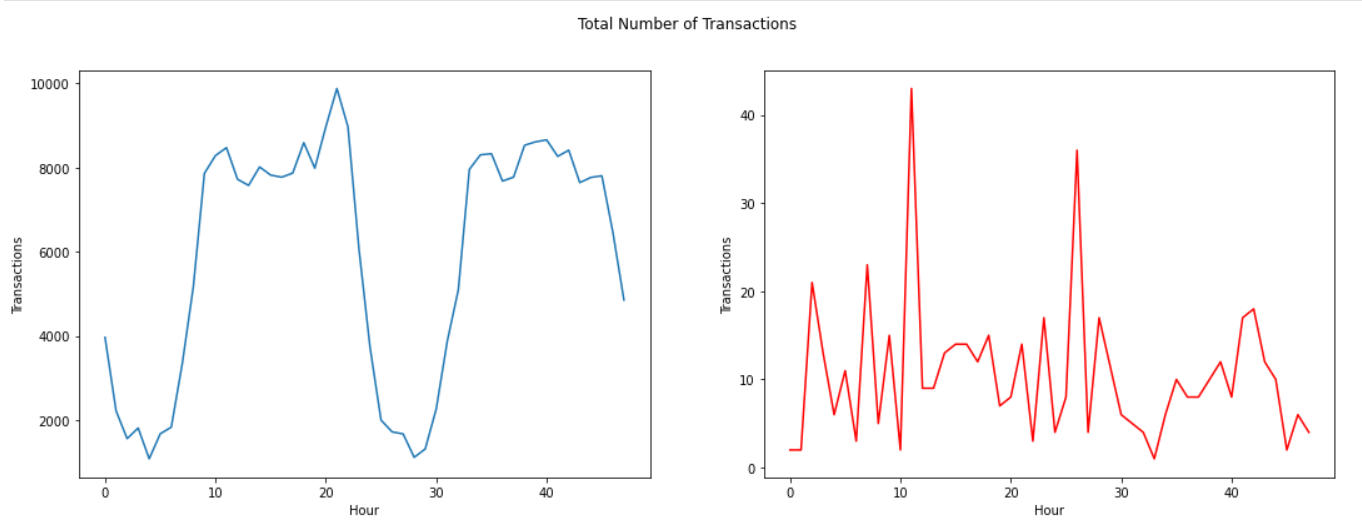

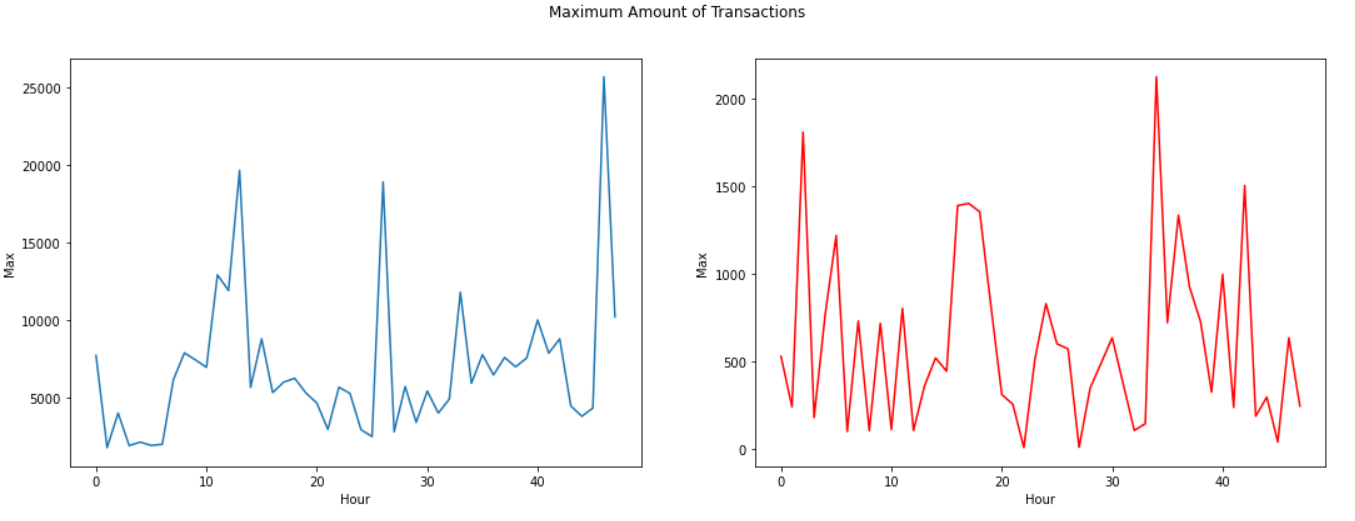
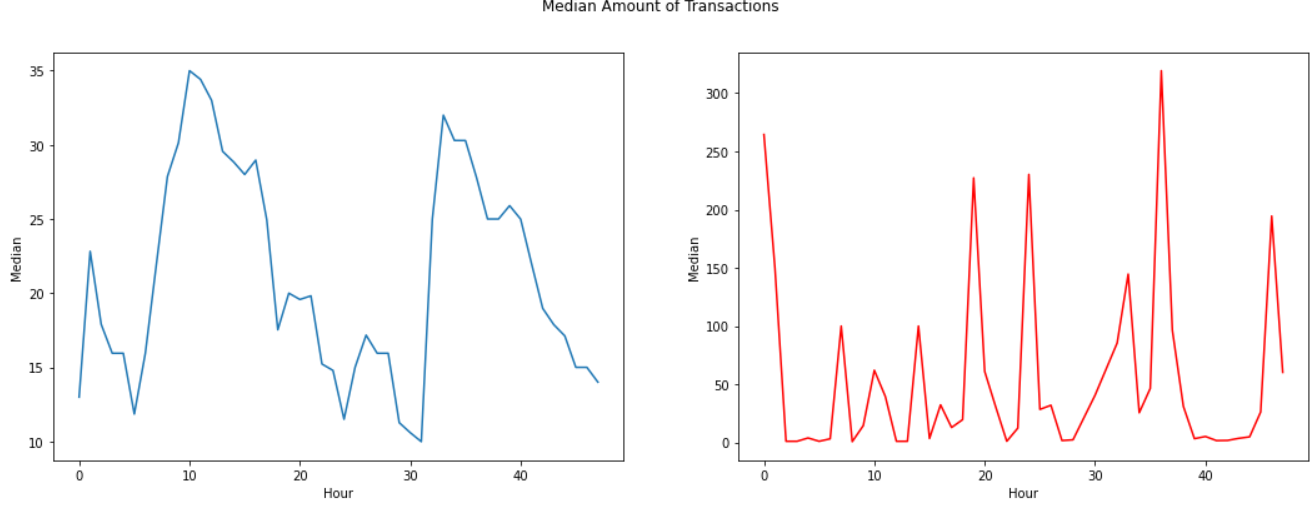
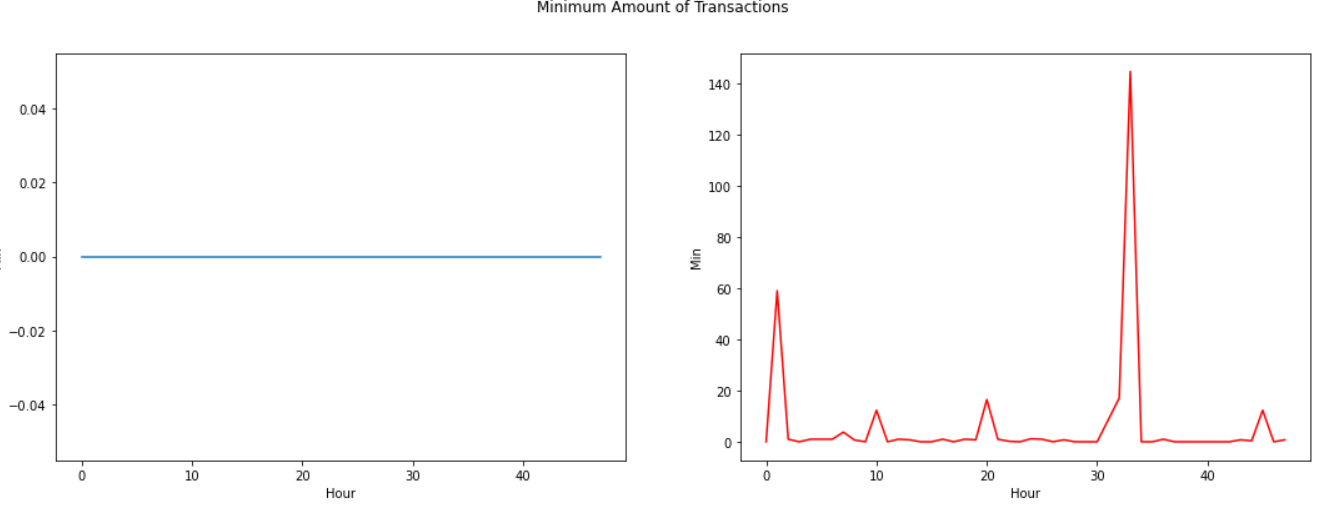

The real transaction have a larger mean value, larger Q1, smaller Q3 and Q4 and larger outliers; fraudulent transactions have a smaller Q1 and mean, larger Q4 and smaller outliers.
Let's plot the fraudulent transactions (amount) against time. The time is shown is seconds from the start of the time period (totaly 48h, over 2 days).
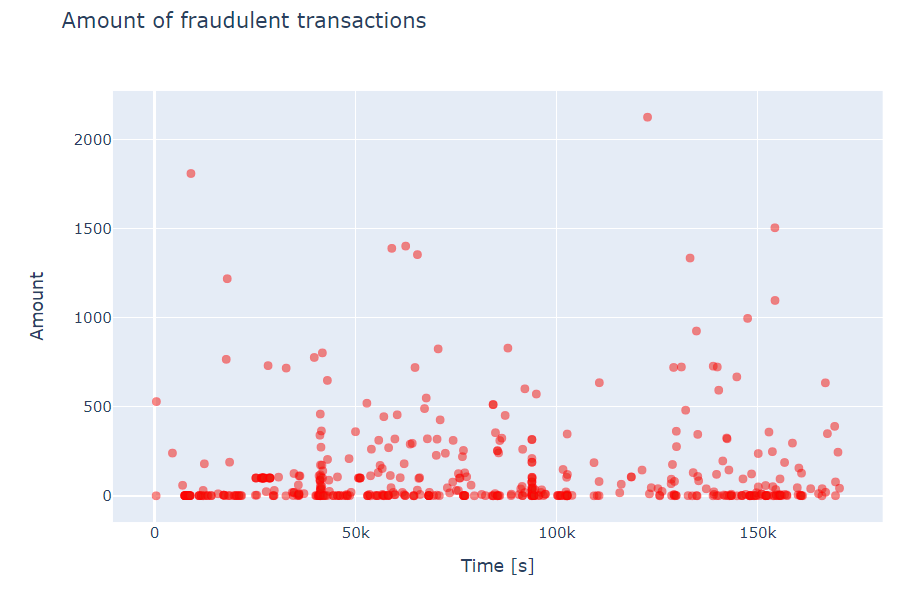
Checkout the Notebook for mor details.## Machine Learning Model Evaluation and Prediction:
clf = RandomForestClassifier(n_jobs=NO_JOBS,
random_state=RANDOM_STATE,
criterion=RFC_METRIC,
n_estimators=NUM_ESTIMATORS,
verbose=False)
Feature Importances:

Confusion Matrix:
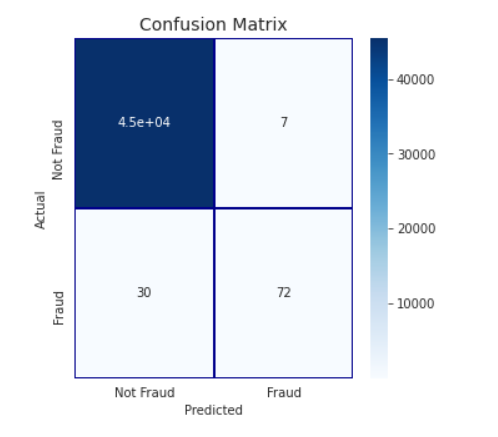
roc_auc_score(valid_df[target].values, preds)
= 0.8528641975628091
clf = AdaBoostClassifier(random_state=RANDOM_STATE,
algorithm='SAMME.R',
learning_rate=0.8,
n_estimators=NUM_ESTIMATORS)

clf = CatBoostClassifier(iterations=500,
learning_rate=0.02,
depth=12,
eval_metric='AUC',
random_seed = RANDOM_STATE,
bagging_temperature = 0.2,
od_type='Iter',
metric_period = VERBOSE_EVAL,
od_wait=100)
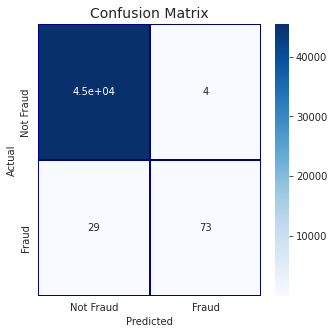
roc_auc_score(valid_df[target].values, preds)
= 0.8577991493075996
dtrain = xgb.DMatrix(train_df[predictors], train_df[target].values)
dvalid = xgb.DMatrix(valid_df[predictors], valid_df[target].values)
dtest = xgb.DMatrix(test_df[predictors], test_df[target].values)
#What to monitor (in this case, **train** and **valid**)
watchlist = [(dtrain, 'train'), (dvalid, 'valid')]
# Set xgboost parameters
params = {}
params['objective'] = 'binary:logistic'
params['eta'] = 0.039
params['silent'] = True
params['max_depth'] = 2
params['subsample'] = 0.8
params['colsample_bytree'] = 0.9
params['eval_metric'] = 'auc'
params['random_state'] = RANDOM_STATE
roc_auc_score(test_df[target].values, preds)
= 0.9777955400794907
The AUC score for the prediction of fresh data (test set) is 0.974.
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric':'auc',
'learning_rate': 0.05,
'num_leaves': 7, # we should let it be smaller than 2^(max_depth)
'max_depth': 4, # -1 means no limit
'min_child_samples': 100, # Minimum number of data need in a child(min_data_in_leaf)
'max_bin': 100, # Number of bucketed bin for feature values
'subsample': 0.9, # Subsample ratio of the training instance.
'subsample_freq': 1, # frequence of subsample, <=0 means no enable
'colsample_bytree': 0.7, # Subsample ratio of columns when constructing each tree.
'min_child_weight': 0, # Minimum sum of instance weight(hessian) needed in a child(leaf)
'min_split_gain': 0, # lambda_l1, lambda_l2 and min_gain_to_split to regularization
'nthread': 8,
'verbose': 0,
'scale_pos_weight':150, # because training data is extremely unbalanced
}
roc_auc_score(test_df[target].values, preds)
= 0.9473337202349548
Check out the complete implementation here: Notebook
Classification Algorithms
Feature importance
LightGBM Classifier
Credit card fraud detection using ANN
If you have any feedback, please reach out at pradnyapatil671@gmail.com
I am an AI Enthusiast and Data science & ML practitioner
![]()
![]()
![]()
![]()