![]()





![]()
Qolmat provides a convenient way to estimate optimal data imputation techniques by leveraging scikit-learn-compatible algorithms. Users can compare various methods based on different evaluation metrics.
Python 3.8+
Qolmat can be installed in different ways:
$ pip install qolmat # installation via `pip`
$ pip install qolmat[pytorch] # if you need ImputerDiffusion relying on pytorch
$ pip install git+https://github.com/Quantmetry/qolmat # or directly from the github repositoryLet us start with a basic imputation problem. We generate one-dimensional noisy time series with missing values. With just these few lines of code, you can see how easy it is to
- impute missing values with one particular imputer;
- benchmark multiple imputation methods with different metrics.
import numpy as np
import pandas as pd
from qolmat.benchmark import comparator, missing_patterns
from qolmat.imputations import imputers
from qolmat.utils import data
# load and prepare csv data
df_data = data.get_data("Beijing")
columns = ["TEMP", "PRES", "WSPM"]
df_data = df_data[columns]
df_with_nan = data.add_holes(df_data, ratio_masked=0.2, mean_size=120)
# impute and compare
imputer_mean = imputers.ImputerMean(groups=("station",))
imputer_interpol = imputers.ImputerInterpolation(method="linear", groups=("station",))
imputer_var1 = imputers.ImputerEM(model="VAR", groups=("station",), method="mle", max_iter_em=50, n_iter_ou=15, dt=1e-3, p=1)
dict_imputers = {
"mean": imputer_mean,
"interpolation": imputer_interpol,
"VAR(1) process": imputer_var1
}
generator_holes = missing_patterns.EmpiricalHoleGenerator(n_splits=4, ratio_masked=0.1)
comparison = comparator.Comparator(
dict_imputers,
columns,
generator_holes = generator_holes,
metrics = ["mae", "wmape", "KL_columnwise", "ks_test", "energy"],
)
results = comparison.compare(df_with_nan)
results.style.highlight_min(color="lightsteelblue", axis=1)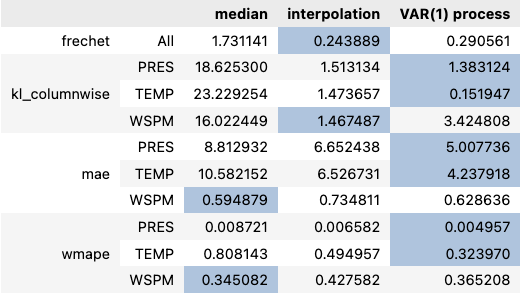
The full documentation can be found on this link.
How does Qolmat work ?
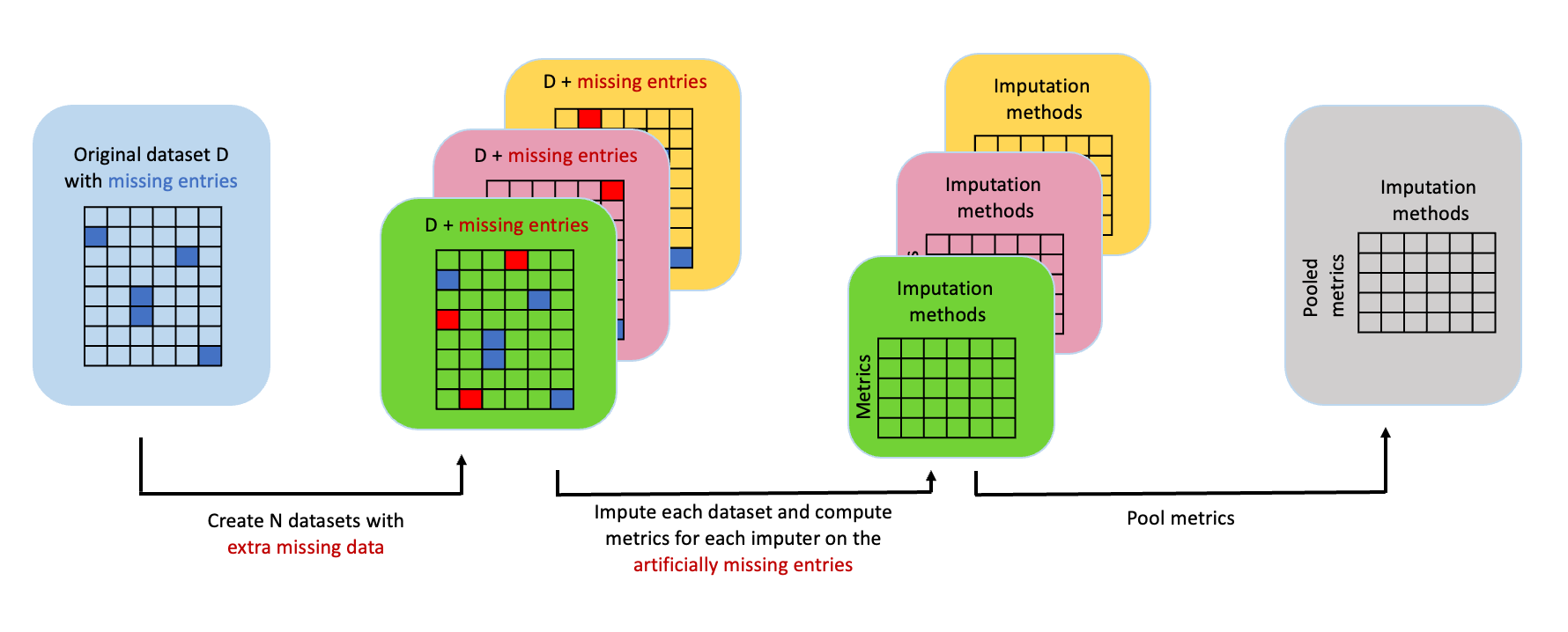
Qolmat allows model selection for scikit-learn compatible imputation algorithms, by performing three steps pictured below:
- For each of the K folds, Qolmat artificially masks a set of observed values using a default or user specified hole generator.
- For each fold and each compared imputation method, Qolmat fills both the missing and the masked values, then computes each of the default or user specified performance metrics.
- For each compared imputer, Qolmat pools the computed metrics from the K folds into a single value.
This is very similar in spirit to the cross_val_score function for scikit-learn.
Imputation methods
The following table contains the available imputation methods. We distinguish single imputation methods (aiming for pointwise accuracy, mostly deterministic) from multiple imputation methods (aiming for distribution similarity, mostly stochastic). For further details regarding the distinction between single and multiple imputation, you can refer to the Imputation article on Wikipedia.
| Method | Description | Tabular or Time series | Single or Multiple |
|---|---|---|---|
| mean | Imputes the missing values using the mean along each column | tabular | single |
| median | Imputes the missing values using the median along each column | tabular | single |
| LOCF | Imputes missing entries by carrying the last observation forward for each columns | time series | single |
| shuffle | Imputes missing entries with the random value of each column | tabular | multiple |
| interpolation | Imputes missing using some interpolation strategies supported by pd.Series.interpolate | time series | single |
| impute on residuals | The series are de-seasonalised, residuals are imputed via linear interpolation, then residuals are re-seasonalised | time series | single |
| MICE | Multiple Imputation by Chained Equation | tabular | both |
| RPCA | Robust Principal Component Analysis | both | single |
| SoftImpute | Iterative method for matrix completion that uses nuclear-norm regularization | tabular | single |
| KNN | K-nearest kneighbors | tabular | single |
| EM sampler | Imputes missing values via EM algorithm | both | both |
| MLP | Imputer based Multi-Layers Perceptron Model | both | both |
| Autoencoder | Imputer based Autoencoder Model with Variationel method | both | both |
| TabDDPM | Imputer based on Denoising Diffusion Probabilistic Models | both | both |
You are welcome to propose and contribute new ideas. We encourage you to open an issue so that we can align on the work to be done. It is generally a good idea to have a quick discussion before opening a pull request that is potentially out-of-scope. For more information on the contribution process, please go here.
Qolmat has been developed by Quantmetry.

[1] Candès, Emmanuel J., et al. “Robust principal component analysis?.” Journal of the ACM (JACM) 58.3 (2011): 1-37, (pdf)
[2] Wang, Xuehui, et al. “An improved robust principal component analysis model for anomalies detection of subway passenger flow.” Journal of advanced transportation 2018 (2018). (pdf)
[3] Chen, Yuxin, et al. “Bridging convex and nonconvex optimization in robust PCA: Noise, outliers, and missing data.” Annals of statistics, 49(5), 2948 (2021), (pdf)
[4] Shahid, Nauman, et al. “Fast robust PCA on graphs.” IEEE Journal of Selected Topics in Signal Processing 10.4 (2016): 740-756. (pdf)
[5] Jiashi Feng, et al. “Online robust pca via stochastic optimization.“ Advances in neural information processing systems, 26, 2013. (pdf)
[6] García, S., Luengo, J., & Herrera, F. "Data preprocessing in data mining". 2015. (pdf)
[7] Botterman, HL., Roussel, J., Morzadec, T., Jabbari, A., Brunel, N. "Robust PCA for Anomaly Detection and Data Imputation in Seasonal Time Series" (2022) in International Conference on Machine Learning, Optimization, and Data Science. Cham: Springer Nature Switzerland, (pdf)
Qolmat is free and open-source software licensed under the BSD 3-Clause license.