A Simple Testing for AdaBoostPL
| CPU | Intel Xeon E5645 @ 2.40GHz * 2 |
| MEM | 32GB DDR3 ECC |
| DISK | 500GB SATA |
| CPU | Intel Xeon E5620 @ 2.40GHz |
| MEM | 16GB DDR3 ECC |
| DISK | 500GB SATA |
Gigabit Ethernet switches
| OS | CentOS 6.3 |
| MapReduce | Cloudera Hadoop CDH4 |
We generate our synthetic data sets randomly by our scripts.
| Data sets | No. of Instances | No. of Attribuates | Size on Disk |
|---|---|---|---|
| d1 | 500,000 | 100 | 688MB |
| d2 | 1,000,000 | 100 | 1.4GB |
| d3 | 1,500,000 | 100 | 2.1GB |
| d4 | 2,000,000 | 100 | 2.1GB |
| d5 | 1,000,000 | 500 | 9.4GB |
| d6 | 1,000,000 | 1000 | 14GB |
| d7 | 10,000,000 | 100 | 14GB |
The number of iterations for all AdaBoost testings are 100.
The most efficient way to use hadoop MapReduce is dividing the datasets automatic by HDFS, so the maximum size of splits is 64MB in our testing.
| Data sets | No. of map | total time(s) |
|---|---|---|
| d1 | 11 | 165 |
| d2 | 22 | 165 |
| d3 | 33 | 165 |
| d4 | 43 | 169 |
| d5 | 108 | 249 |
| d6 | 215 | 345 |
| d7 | 215 | 494 |
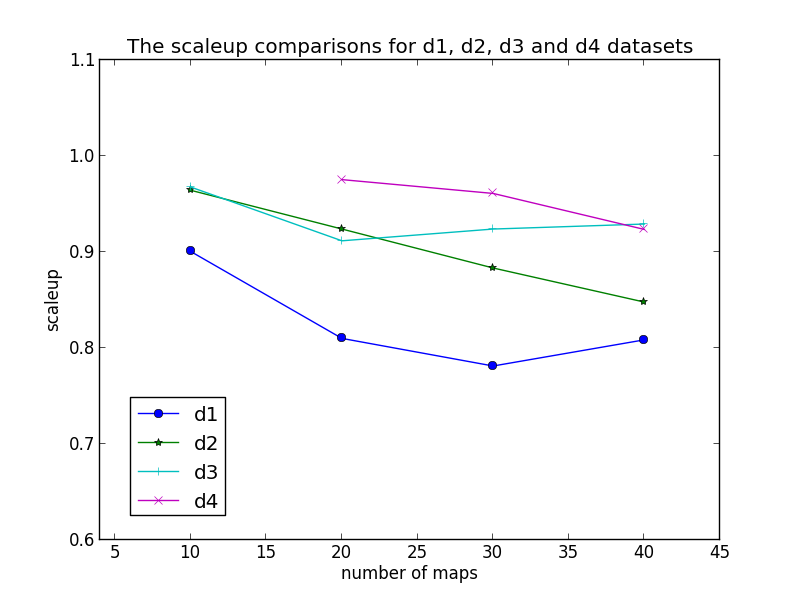
Next step we divide the d1, d2, d3 and d4 datasets into 10, 20, 30 and 40 splits(maps).
| No. of map | total map time(s) | per map time(s) | No. of reduce | reduce time(s) |
|---|---|---|---|---|
| 10 | 1718 | 172 | 1 | 19 |
| 20 | 1631 | 81 | 1 | 19 |
| 30 | 1514 | 50 | 1 | 14 |
| 40 | 1503 | 38 | 1 | 9 |
| No. of map | total map time(s) | per map time(s) | No. of reduce | reduce time(s) |
|---|---|---|---|---|
| 10 | 3781 | 378 | 1 | 14 |
| 20 | 3398 | 170 | 1 | 14 |
| 30 | 3181 | 106 | 1 | 14 |
| 40 | 3123 | 78 | 1 | 14 |
| No. of map | total map time(s) | per map time(s) | No. of reduce | reduce time(s) |
|---|---|---|---|---|
| 10 | 5675 | 568 | 1 | 19 |
| 20 | 5169 | 258 | 1 | 25 |
| 30 | 5091 | 170 | 1 | 14 |
| 40 | 4686 | 118 | 1 | 9 |
| No. of map | total map time(s) | per map time(s) | No. of reduce | reduce time(s) |
|---|---|---|---|---|
| 10 | timeout(*) | NaN | 1 | NaN |
| 20 | 7532 | 753 | 1 | 19 |
| 30 | 6893 | 345 | 1 | 14 |
| 40 | 6743 | 169 | 1 | 14 |
Running the whole d1, d2, d3 and d4 datasets on a single worker.
| Data sets | time(s) |
|---|---|
| d1 | 2133 |
| d2 | 5156 |
| d3 | 8457 |
| d4 | 11965 |
Speedup = Ts/Tp
Ts: execution time on a single worker for whole dataset
Tp: execution time on p workers for whole dataset
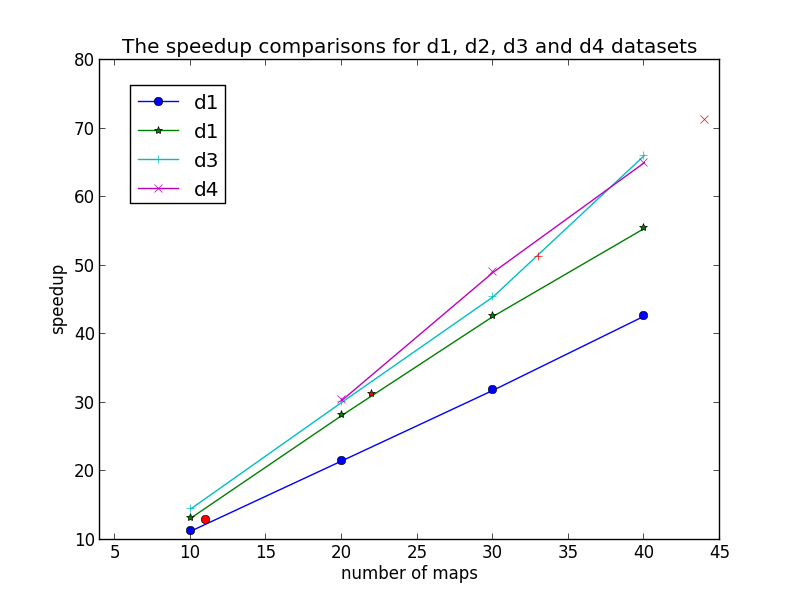
(*)The red points is speedups where datasets are divided automaticly by HDFS.
Scaleup = Ts/Tp
Ts: execution time on a single worker for a split
Tp: execution time on p workers for whole dataset