OLD Machine Learning Models
Since regex scanners are prone to produce a lot of false positive discoveries,
machine learning models can be used to reduce the number of discoveries to be manually analysed.
In particular, models automatically classify discoveries as false_positive.
Models need an implementation (in credentialdigger/models folder) and binaries (in credentialdigger/models_data folder).
THE CONTENT IN THIS SECTION IS VALID UNTIL v4.4, WHERE THESE MACHINE LEARNING MODELS WERE UPDATED IN FAVOUR OF MORE PRECISE ONES.
Every model needs its implementation class. This class must extend BaseModel.
Moreover, every model implementation needs a classifier that will be used by the class to classify the discoveries as false positive.
Refer to the PathModel for an example of model class implementation.
Please note that the models work with fasttext.
In the keras-models branch we supported also Keras.
Yet, this branch has not been actively maintained after v1.0.3.
Every model class implementation must appear in its own directory (e.g., credentialdigger/models/path_model). The class name must then be imported in credentialdigger/models/__init__.py, such that the model can be dynamically loaded by the ModelManager during the scan of a repository.
- Dedicate a new folder to the model, located in
credentialdigger/models(e.g.,credentialdigger/models/path_modelfor thePathModel)- The class files (i.e., the implementation) should appear in this folder
- The class must extend
BaseModel:- It is initialized with the name of the model and name of the binary files used for the classification of the discovery (e.g., the
PathModelclass requires the binary file calledpath_model.binin the binary folder modelpath_model) - It must override the
analyzemethod. This method receives a discovery (python dictionary) as input, and returns a boolean as output (i.e.,Trueif this discovery is classified as false positive)
- It is initialized with the name of the model and name of the binary files used for the classification of the discovery (e.g., the
-
Update the
__init__.pyfile (the same way done for thePathModel)
Refer to credentialdigger/models/path_model/path_model.py for an example.
The binaries for a model must be included in their own folder. This folder must be copied (or linked) in credentialdigger/models_data. All the folders with binaries have the following structure.
models_data
|- ...
`- model_name
|- __init__.py
|- meta.json
`- model_name-version
`- classifier.bin
After installing credentialdigger, export the path of a model in an environment variable run (not from the installation directory) the download.
- Publish the binary data files on some web server
- Models can be deployed as illustrated by this template example
- Export the url of the model as environment variable
export your_model=https://IP:PORT/your_model-1.0.0.tar.gz - Download the model (requires installing
credentialdiggerbefore)python -m credentialdigger download your_model
Otherwise, if the model is not available online, copy (or link) its folder into credentaldigger/models_data.
Every model needs an implementation class.
The tool supports the following models.
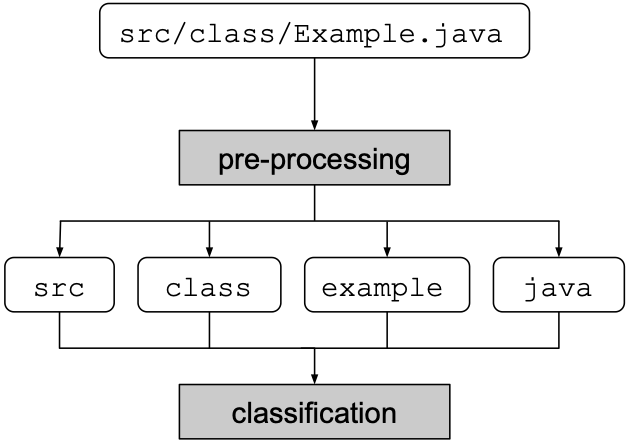
The Path Model classifies a discovery as false positive according to its file path.
The path is first processed in order to extract all the words contained in the path (the extension is not considered). Then, each word is converted into its root. Finally, the roots of the words are used for the ML classification.
A pre-trained Path Model is available here.
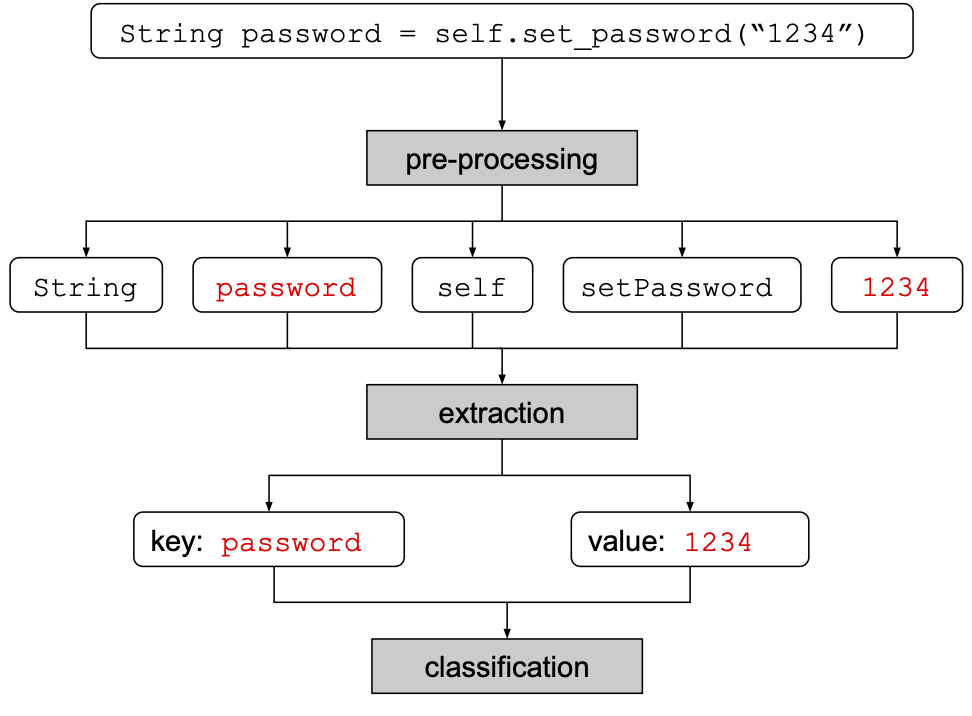
The snippet model classifies a discovery as false positive according to its code snippet, i.e., the line of code detected as a possible leak in the commit. The goal of the snippet model is to classify false positive passwords (it can be used also with tokens, but its precision is lower).
Before the actual machine learning, we have some heuristics to discard some obvious cases:
- First, during the preprocessing phase, we check the extension of the file. If this extension is a known programming language (e.g., .py, .java, etc.), then it checks whether there are quotes in the snippet or not. In fact, if the snippet does not contain quotes, then there is no hardcoded string (and thus, no hardcoded password). So, we assume that this leads to a false positive discovery.
- Second, we check the first word contained in the snippet. If this word is a known keyword (e.g., class, function, def, etc.) then we assume this snippet is a false positive.
Finally, in case the the snippet was not classified as false positive during heuristic phase, we apply the machine learning model. A first model, called extractor, extracts a pair of words (key; value) from the snippet. Then, a second model, called classifier, classifies these words.
The base snippet model binaries include both a pre-trained extractor and a pre-trained classifier. Yet, it is possible to improve the precision of the classifier by generating a ad-hoc extractor, based on the stylometry of the repository. More details are given in the extractor section.
A pre-trained Snippet Model is available here.
The snippet model extractor generator can be used to improve the precision of the pre-trained snippet model. Indeed, in the standard snippet model process, a key pair is extracted from the snippet, and it is then classified. Both the extraction phase and the classification phase need their own machine learning model. The standard snippet model offers pre-trained binaries for these two models.
In order to improve the precision of the extractor, an Extractor Generator can be triggered at scan time. This generator is in charge of extracting relevant features from the codebase of the repository, and train a machine learning model extractor adapted to the repository. The generated extractor model is language-agnostic, and depends only on stylometric features (e.g., average length of lines of code, variable name conventions, use of spaces, etc.).
The newly generated extractor model is dropped into the credentialdigger/models_data folder, with the name of snippet_model_AUTHOR. Indeed, since the extractor is language agnostic, and since the basic assumption is that the stylometry of a developer (repository owner) doesn't change from one repository to the other, only one extractor can be generated for repo owner. Even in case of GitHub organizations, we assume that the stylometry doesn't change. For example, only one adapted extractor can be generated for all the repositories belonging to https://github.com/SAP, and its name will be snippet_model_SAP.
The structure of the folder for this model is the same of the standard snippet model.
The extractor model generated this way depends on the snippet model pre-trained classifier. Therefore, it is needed to download the snippet model before using the extractor generator.