Portrait segmentation is task of segmenting a person in an image from the background. It is modeled as a semantic segmentation task to predict the label of every pixel (dense prediction) in an image.
Here we limit the prediction to binary classes (person or background) and use only plain portrait-selfie images for matting. Experimentations with the following architectures for implementing a real-time portrait segmentation are discussed below:
- Mobile-Unet
- Prisma-Net
- Portrait-Net
- Slim-Net
The models were trained with standard(& custom) portrait datasets and their performance was compared using standard evaluation metrics.
Setup with python venv:
python -m venv venv
source venv/bin/activate
pip install -r requirements.txtOr setup with conda environment:
./conda_install.sh
conda activate fastsegPretrained graphe-def, hdf5, onnx, pth, and tflite models can be downloaded from this Google Drive Link and unzipped under models or unzipped with the following commands.
pip install gdown
gdown 19lni0lm0qa0VPJPAs-8WbpMWwU77FmSp
unzip models.zip
rm models.zipTested with python 3.7, 3.8, 3.9
Use -h to get all possible arguments. It is recommended to use the --mt flag for multi-threading to speed inference and build Tensorflow locally with AVX and FMA enabled.
# Add necessary paths to env var
export TF_XLA_FLAGS="--tf_xla_enable_xla_devices --tf_xla_auto_jit=2 --tf_xla_cpu_global_jit"
export PYTHONPATH=${PYTHONPATH}:./
export PYTHONPATH=${PYTHONPATH}:./utils/python inference/run_openvino.py # 30 FPS, Run the model using openvino inference engine
python inference/run_graphdef_pb.py # 23 FPS, run model with tf v1 frozen graph inference
python inference/run_smoothed_with_slider.py # 10 FPS, run model with hdf5 inference & sliders for changing frame skip, smoothing
python inference/run_tflite.py # 25 FPS, Run the model using tflite interpreter
python inference/run_portrait_video_tflite.py # 8 FPS, Use portrait-net for video segmentation
python inference/run_mediapipe.py # 30 FPS, mediapipe person segmentation
python inference/run_seg_video.py # Apply blending filters on video
python inference/run_tflite_mult_channel_out.py # person segmentation with 2 channel tflite model, best perf-
It consists of 18698 human portrait 128x129 RGB images, along with their alpha masks. We augment the PFCN dataset with handpicked portrait images from supervisely dataset. Additionally, we downloaded random selfie images from web and generated their masks using the SOTA deeplab-xception semantic segmentation model.
We then perform augmentations like cropping, brightness alteration, flipping, curve filters, motion blur etc. to increase dataset size and model robustness. Since most of our images contain plain background, we create new synthetic images using random natural backgrounds using the default dataset.
Besides the above augmentations, we normalize & standardize the images and perform run-time augmentations like flip, shift and zoom using keras data generator and preprocessing module.
-
It is a human matting dataset for binary segmentation of humans and the background. It is currently the largest portrait matting dataset, with 34,427 images and corresponding matts. The dataset was marked by the Beijing Play Star Convergence Technology Co. Ltd., and the portrait soft segmentation model trained using this data has also been commercialized.
Supplemental Portrait Datasets
- Portseg_128
- Portrait_256
- PFCN
- AISegment
- Baidu_Aug
- Supervisely
- Pascal_Person
- Supervisely Portrait
- UCF Selfie
A good dataset is always the first step for coming up with a robust and and accurate model, especially for semantic segmentation. There are many datasets available for portrait(person) segmentation like PFCN, MSCOCO Person, PascalVOV Person, Supervisely etc. But it seems that either the quality or the quantity of these images are still insufficient for our use case. So, it is recommented to collect custom images for our training. unfortunately, semantic segmentation annotation requiries a lot of effort and time as compared to classification or detection.
Useful tools for data annotation and collection:
- Offline Image Editors - Pros: Free, High Accuracy; Cons: Manual Annotation Time; Eg: GIMP, Photoshop etc.
- Offline Image Annotation Tools - Pros: Free, Good Accuracy; Cons: Manual Annotation Time; Eg: cvat, etc.
- Pre-trained Models: Pros - Fast, Easy to Use; Cons: Limited Accuracy; Eg: Deeplab Xception, MaskRCNN etc.
- Online Annotation Tools - Pros: Automated, Easy to Use, Flexible; Cons: Price; Eg: Supervisely, Remove.bg.
- Crowd Sourcing Tools - Pros: Potential Size and Variety, Less Effort; Cons: Cost, Time, Quality; Eg: Amazon MTurk, Freelancers.
To use the model in mobile phones, it is important to include lots of portrait images captured using mobile phones in the dataset.
Tested with python 3.7
Download the dataset from the link above and put them in data folder. Then run the scripts in the following order:
python train.py # Train the model on data-set
python eval.py checkpoints/<CHECKPOINT_PATH.hdf5> # Evaluate the model on test-set
python export.py checkpoints/<CHECKPOINT_PATH.hdf5> # Export the model for deployment
python test.py <TEST_IMAGE_PATH.jpg> # Test the model on a single imageHere we use MobileNet-V2 with depth multiplier 0.5 as encoder (feature extractor).
For the decoder part, we have two variants. A upsampling block with either Transpose Convolution or Upsample2D+Convolution. The former has a stride of 2, whereas the later uses resize bilinear for upsampling, along with Conv2D. Encoder and decoder section must have proper skip connections for better results. Additionally, we use dropout regularization to prevent overfitting.It also helps our network to learn more robust features during training.
Since we are using a pretrained mobilenet-v2 as encoder for a head start, the training quickly converges to 90% accuracy within first couple of epochs. Also, we use a flexible learning rate schedule (ReduceLROnPlateau) for training the model.
Here the inputs and outputs are images of size 128x128.The backbone is mobilenet-v2 with depth multiplier 0.5. The first row represents the input and the second row shows the corresponding cropped image obtained by cropping the input image with the mask output of the model.

Accuracy: 96%, FPS: 10-15
Here the inputs and outputs are images of size 224x224. The backbone is mobilenetv3 with depth multiplier 1.0. The first row represents the input and the second row shows the corresponding cropped image obtained by cropping the input image with the mask output of the model.

Accuracy: 97%, FPS: 10-15
Here the inputs and outputs are images of size 256x256. The prisma-net architecture is based on unet and uses residual blocks with depthwise separable convolutions instead of regular convolutional blocks(Conv+BN+Relu). Also,it uses elementwise addition instead of feature concatenation in the decoder part.
The first row represents the input and the second row shows the corresponding cropped image obtained by cropping the input image with the mask output of the model.

Accuracy: 96%, FPS: 8-10
Note: Accuracy measured on a predefined test data-set and FPS on android application in a OnePlus3 device

When there are objects like clothes, bags etc. in the background the model fails to segment them properly as background, especially if they seem connected to the foreground person. Also if there are variations in lighting or illumination within the image, there seems to be a flickering effect on the video resulting in holes in the foreground object.
MobileNetV3 is the next generation of on-device deep vision model from Google. It is twice as fast as MobileNetV2 with equivalent accuracy, and advances the state-of-the-art for mobile computer vision networks. Here we use small version of mobilenetv3 with input size 256 as the encoder part of the network. In the decoder module we use transition blocks along with upsampling layers, similar to the decoder modules in the portrait-net architecture. There are two branches in this block: one branch contains two depthwise separable convolutions and the other contains a single 1×1 convolution to adjust the number of channels. For upsampling we use bilinear resize along with the transition blocks in the decoder module. In the case of skip connections between encoder and decoder, we use element-wise addition instead of concatenation for faster inference speed.
During training, initially we freeze all the layers of encoder and train it for 10 epochs. After that, we unfreeze all the layers and train the model for additional 10 epochs. Finally, we perform quantization aware training on the float model, and convert all of the the models to tflite format.
Observations:-
- Using the pretrained mobilenetv3 as the encoder during training greatly improved the convergence speed. Also, the input images were normalized to [-1.0, 1.0] range before passing to the model. The float model converged to 98% validation accuracy in the first 20 epochs.
- Using the latest Tensorflow built from source and AiSegment dataset with 68852 images, the training process took about 2 hours for 20 epochs, on a Tesla P100 GPU in Google Colaboratory.
- In the current Tensorflow 2.3 and tf model optimization library, some layers like Rescale, Upsampling2D, Conv2DTranspose are not supported by the tf.keras Quantization Aware Training API's. For this purpose you have to install the latest nightly version or build the same from source. Similarly the mobilenetv3 pretrained models are only available in tf-nightly(currently).
- Using elementwise additon instead of concatenation on skip connection bewteen encoder and decoder greatly helped us to decrease the model size and improve it's inference time.
- After quantization aware training, even though the model size was reduced by 3x, there was no considerable loss in model accuracy.
- On POCO X3 android phone, the float model takes around 17ms on CPU and 9ms on it's GPU (>100 FPS), whereas the quantized model takes around 15ms on CPU (2 threads). We were unable to run the fully quantized models(UINT8) using nnapi or hexagon delegate since some of the layers were not fully supported. However we can run them partially on such accelerators with decreased performance(comparatively).
Summary of model size and running time in android:
| Model Name | CPU Time (ms) | GPU Time (ms) | Parameters (M) | Size (MB) | Input Shape |
|---|---|---|---|---|---|
| deconv_fin_munet.tflite | 165 | 54 | 3.624 | 14.5 | 128 |
| bilinear_fin_munet.tflite | 542 | 115 | 3.620 | 14.5 | 128 |
| munet_mnv3_wm10.tflite | 167 | 59.5 | 2.552 | 10.2 | 224 |
| munet_mnv3_wm05.tflite | 75 | 30 | 1.192 | 4.8 | 224 |
| prisma-net.tflite | 426 | 107 | 0.923 | 3.7 | 256 |
The parameter 'wm' refers to the width multiplier (similar to depth multiplier). We can configure the number of filters of particular layers and adjust the speed-accuracy tradeoffs of the network using this parameter.
We can add filters to harmonize our output image with the background. Our aim is to give a natural blended feel to the output image i.e the edges should look smooth and the lighting(color) of foreground should match(or blend) with its background.
The first method is alpha blending, where the foreground images are blended with background using the blurred(gaussian) version of the mask.In the smooth-step filter, we clamp the blurred edges and apply a polynomial function to make the foreground image edges smoother. Next, we use the color transfer algorithm to transfer the global color to the foreground image. Also, OpenCV provides a function called seamless clone to blend an image onto a new background using an alpha mask. Finally, we use the OpenCV DNN module to load a color harmonization model(deep model) in caffe and transfer the background style to the foreground.
Sample results:

For live action, checkout the script seg_video.py to see the effects applied on a webcam video.
Also download the caffe model and put it inside models/caffe folder.
Hold down the following keys for filter selection.
- C- Color transfer
- S- Seamless clone
- M- Smooth step
- H- Color harmonize
Move the slider to change the background image.
To ensure that the application runs in a platform independent way(portable), the simplest way is to implement them as a web-application and run it on a browser. One can easily convert the trained model to tfjs format and run them in javascript using Tensorflowjs conversion tools. If one is familiar with React/Vuejs, one can easily incorporate the tfjs into the application.
This is a sample link to a portrait segmentation webapp: CVTRICKS
If you want to run it locally, start a local server using python SimpleHTTPServer. Initially configure the hostname, port and CORS permissions and then run it on your browser. Although, the application will be computationally intensive and resource heavy.
Intel's openVINO toolkit allows us to convert and optimize deep neural network models trained in popular frameworks like Tensorflow, Caffe, ONNX etc. on Intel CPU's, GPU's and Vision Accelerators(VPU), for efficient inferencing at the edge. Here, we will convert and optimize a pre-trained deeplab model in Tensorflow using OpenVINO toolkit, for person segmentation. As an additional step, we will see how we can send the output video to an external server using ffmpeg library and pipes.
- Download and install openvino toolkit.
- Download the Tensorflow deeplabv3_pascal_voc_model, for semantic segmentation.
- Download and install ant-media server.
Once you install and configure the openVINO inference engine and model optimizer, you can directly convert the Tensorflow deeplab model with a single command:
python3 /opt/intel/openvino/deployment_tools/model_optimizer/mo.py --input_model frozen_run_graph.pb --output SemanticPredictions --input ImageTensor --input_shape "(1,513,513,3)"
If we have a static background, we can easily obtain the mask of new objects appearing on the scene using the methods of background subtraction. Even though this seems straight-forward; there seems to be couple of challenges in this scenario. Firstly, even if objects does not move in the background, there will be small variations in corresponding pixel values due to changes in lighting, noise, camera quality etc. Secondly, if the new objects have color similar to that of the background, it becomes difficult to find the image difference.
Here is a simple algorithm for segmentation, using background subtraction. We assume that the background image or camera is static during the entire experiment.
- Capture the first 'N' background images and find the mean background image.
- Convert the background image to grayscale and apply gaussian blur.
- Capture the next frame in grayscale, with new objects and apply gaussian blur.
- Find the absolute difference between current frame and background image.
- Threshold the difference with a value 'T' and create the binary difference-mask.
- Apply morphological operations to fill up the holes in the mask.
- Find the largest contour and remove the smaller blobs in the mask.
- Apply alpha blend on the frame with any background image, using the mask.
- Display the output on screen.
- Repeat steps 3 to 9, until a keyboard interruption.
The algorithm works pretty well, if there is proper lighting and clear color difference between the foreground object and background. Another idea is to detect the face and exclude potential background regions based on some heuristics. Other classical methods include grabcut, active contours, feature based(HOG) detectors etc. But none of them seems to be robust, real-time and light-weight like our deep neural network models. Additionally, using trimap-masks and depth sensors(ToF) on phone could help us achieve better visual perception and accuracy on the mobile application eg. uDepth.
Also check-out this cool application: Virtual Stage Camera
Here are some advanced techniques to improve the accuracy, speed and robustness of the portrait segmentation model for videos. Most of them are inspired from the following two papers:-
- PortraitNet: Real-time portrait segmentation network for mobile device
- Real-time Hair Segmentation and Recoloring on Mobile GPUs
Boundary Loss: In order to improve the boundary accuracy and sharpness, we modify the last layer in the decoder module by adding a new convolution layer in parallel to generate a boundary detection map. We generate the boundary ground truth from manual labeled mask using traditional edge detection algorithm like canny or Sobel, on-the-fly. Also, we need to use focal loss instead of BCE, for training the network with boundary masks. Finally, we can remove this additional convolution layer for edges and export the model for inference.
Consistency Constraint Loss: A novel method to generate soft labels using the tiny network itself with data augmentation, where we use KL divergence between the heat-map outputs of the original image and texture enhanced image, for training the model. It further improves the accuracy and robustness of the model under various lighting conditions.
Refined Decoder Module: The decoder module consists of refined residual block with depthwise convolution and up-sampling blocks with transpose convolution. Even though it includes the skip connections similar to UNET architecture, they are added to the layers in decoder module channel-wise instead of usual concatenation. Overall, this improves the execution speed of the model.
Temporal Consistency: A video model should exhibit temporal redundancy across adjacent frames. Since the neighboring frames are similar, their corresponding segmentation masks should also be similar(ideally). Current methods that utilize LSTM, GRU(Deep) or Optical flow(Classic) to realize this are too computationally expensive for real-time applications on mobile phones. So, to leverage this temporal redundancy, we append the segmentation output of the previous frame as the fourth channel(prior) of the current input frame during inference. During training, we can apply techniques like affine transformations, thin plate spline smoothing, motion blur etc. on the annotated ground truth to use it as a previous-mask. Also, to make sure that the model robustly handles all the use cases, we must also train it using an empty previous mask.
High resolution Input: In our original pipeline, we downsample our full resolution image from mobile camera to a lower resolution(say 128 or 224) and finally after inference, we upsample the output mask to full resolution. Even though output results are satisfactory; there are couple of problems with this approach. Firstly, the resized mask edges will be coarse(stair-case) or rough and extra post-processing steps will be needed to smoothen the mask. Secondly, we loose lots of details in the input due to downsampling and thus it affects the output mask quality. If we use a larger input size, it would obviously increase the computation time of the model. The primary reason for this increase, is the increase in number of parameters. Also, on a mobile device the CPU-GPU data transfer takes considerable amount of time, especially when the inputs are large. To solve the latter problem, we can use techniques like SSBO(low level) or frameworks like mediapipe(high-level) which already comes with a optimized inference pipeline. As for the former one, we can slightly modify the architecture of the model such that, for most part convolutions happen at a lower spatial dimension. The idea is to rapidly downsample the input at the beginning of the network and work with a smaller resolution image throughout a deeper version of the network . Finally, upsample the result from the final layers to full scale, within-the model. Thus, it ensures that the model learns the upsampling or downsampling itself and eliminates the need for a separate post-inference resize or smoothing.
Advanced Activation Function: Newer activation functions like Swish(mobilenetv3) or PRelu(mediapipe hair segmentation) seems to give better accuracy with lower execution time. However, we may need to restructure our network and implement custom-layers for such operators to properly run on mobile GPU, using Tensorflow-lite.
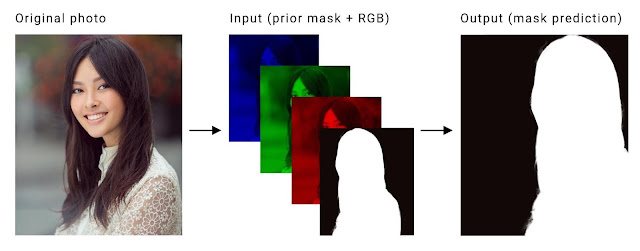
The portrait-net model for videos was successfully trained using pytorch and exported to tflite format. The new dataset consist of 60,000 images for training and 8852 images for testing.It includes portrait images from AISegment dataset and synthetic images with custom backgrounds. This model with input size of 256x256 took about 5 days for training on a GTX 1080 Ti with batch size of 48. Finally, an mIOU of 98% was obtained on the test-set after 500 epochs, using a minimal learning rate of 1e^-6(after decay). The new portrait dataset, conversion scripts, trained models and corresponding inference code in python are also available in the respective folders. It can be easily used with the current android application(SegMeV2) by slightly modifying the I/O handling steps. A frame rate of 30 FPS was achieved using this model.
Quantizing deep neural networks uses techniques that allow for reduced precision representations of weights and, optionally, activations for both storage and computation(for eg. UINT8 or FLOAT16). It can reduce model size while also improving CPU and hardware accelerator latency, with little degradation in model accuracy. Tensorflow lite supports two types of quantization viz. quantization aware training and post training quantization. Even though the former method produces better accuracy, it is only supported by a few subset of convolutional neural network architectures. Also, currently Tensorflow 2.0 and Keras does not support this technique. Therefore, we are left with only one option i.e Post-training quantization.
Again, there are two types of post-training quantization: weight quantization and full integer quantization(float also). In the weight quantization, only the weights are converted to 8 bit integer format. At inference, weights are converted from 8-bits of precision to floating point and computed using floating-point kernels. In full integer quantization, we use integer weights and integer computations on the model layers. For this purpose, you need to measure the dynamic range of activations and inputs by supplying a representative data set, during the conversion process. The potential advantages include faster inference, reduced memory usage and access to hardware accelerators like TPU, NPU etc. On the flip side, it can lead to accuracy degradation, especially in scenarios where high pixel accuracies or precise boundaries are desired.
The portrait-net and prisma-net models were successfully converted to quantized format. Their size was reduced by about 3x and their outputs were verified using a test dataset. We were able to convert the prisma-net model to TPU format; but unfortunately the portrait-net model failed in the conversion process(layer compatibility issue). The edge TPU model took only a mere 12.2 ms for inference, in comparison to the inference on CPU, which took about 4357.0ms with quantized model and 500ms with float model. The CPU(i7-3632QM CPU @ 2.20GHz) might mostly be using a single core for inference. But even if we include other possible overheads, this 40x speed-up seems to be worth the effort. Besides, it consumes 20 times less power than CPU.
- Repo forked from Anil Sathyan
- https://www.tensorflow.org/model_optimization
- https://www.tensorflow.org/lite/performance/gpu_advanced
- https://github.com/cainxx/image-segmenter-ios
- https://github.com/gallifilo/final-year-project
- https://github.com/dong-x16/PortraitNet
- https://github.com/ZHKKKe/MODNet
- https://github.com/clovaai/ext_portrait_segmentation
- https://github.com/tantara/JejuNet
- https://github.com/lizhengwei1992/mobile_phone_human_matting
- https://github.com/dailystudio/ml/tree/master/deeplab
- https://github.com/PINTO0309/TensorflowLite-UNet
- https://github.com/xiaochus/MobileNetV3
- https://github.com/yulu/GLtext
- https://github.com/berak/opencv_smallfry/blob/master/java_dnn
- https://github.com/HasnainRaz/SemSegPipeline
- https://github.com/onnx/tensorflow-onnx
- https://github.com/onnx/keras-onnx
- https://machinethink.net/blog/mobilenet-v2/
- On-Device Neural Net Inference with Mobile GPUs
- AI Benchmark: All About Deep Learning on Smartphones in 2019
- Searching for MobileNetV3
- Google AI Blog: MobilenetV3
- Youtube Stories: Mobile Real-time Video Segmentation
- Facebook SparkAR: Background Segmentation
- Learning to Predict Depth on the Pixel 3 Phones
- uDepth: Real-time 3D Depth Sensing on the Pixel 4
- iOS Video Depth Maps Tutorial
- Huawei: Portrait Segmentation
- Deeplab Image Segmentation
- Tensorflow - Image segmentation
- Official Tflite Segmentation Demo
- Tensorflowjs - Tutorials
- Hyperconnect - Tips for fast portrait segmentation
- Prismal Labs: Real-time Portrait Segmentation on Smartphones
- Keras Documentation
- Boundary-Aware Network for Fast and High-Accuracy Portrait Segmentation
- Fast Deep Matting for Portrait Animation on Mobile Phone
- Adjust Local Brightness for Image Augmentation
- Pyimagesearch - Super fast color transfer between images
- OpenCV with Python Blueprints
- Pysource - Background Subtraction
- Learn OpenCV - Seamless Cloning using OpenCV
- Deep Image Harmonization
- Opencv Samples: DNN-Classification
- Deep Learning In OpenCV
- BodyPix - Person Segmentation in the Browser
- High-Resolution Network for Photorealistic Style Transfer
- Udacity: Intel Edge AI Fundamentals Course
- Udacity: Introduction to TensorFlow Lite
- Converting Bitmap to ByteBuffer (float) in Tensorflow-lite Android
- Real-time Hair Segmentation and Recoloring on Mobile GPUs
- PortraitNet: Real-time portrait segmentation network for mobile device
- ONNX2Keras Converter
- Peter Warden's Blog: How to Quantize Neural Networks with TensorFlow
- Tensorflow: Post Training Quantization
- TF-TRT 2.0 Workflow With A SavedModel
- Awesome Tflite: Models, Samples, Tutorials, Tools & Learning Resources.
- Machinethink: New mobile neural network architectures
- Video gif in readme attributed to https://www.youtube.com/watch?v=RZP6uJtgM34